0. 학습목표
- 머신러닝 모델을 만들 때 학습과 Test data를 분리 해야 하는 이유를 설명할 수 있다.
- 다중선형회귀를 이해하고 사용할 수 있다.
- 과적합/과소적합을 일반화 관점에서 설명할 수 있다.
- 평향(Bias)/분산(Variance)의 Trade-off 개념을 이해하고 일반화 관점에서 설명할 수 있다.
1. 주요개념
1. Train data, Test data
머신러닝 알고리즘을 학습시키기 위해서는 입력값과 결괏값(정답)이 쌍으로 된 학습데이터(train data)가 필요하다.
이 학습데이터를 이용하여 머신러닝 알고리즘을 학습시키고 이 알고리즘의 성능을 정확하게 평가하려면 알고리즘이 학습하지 않은 새로운 데이터를 사용해야 한다. 이미 학습을 완료한 데이터로 알고리즘의 성능을 평가할 경우, 더 높게 평가되기 때문에 알고리즘이 학습하지 않은 새로운 Test data를 사용해 알고리즘의 일반적인 성능을 평가하는 것이다.
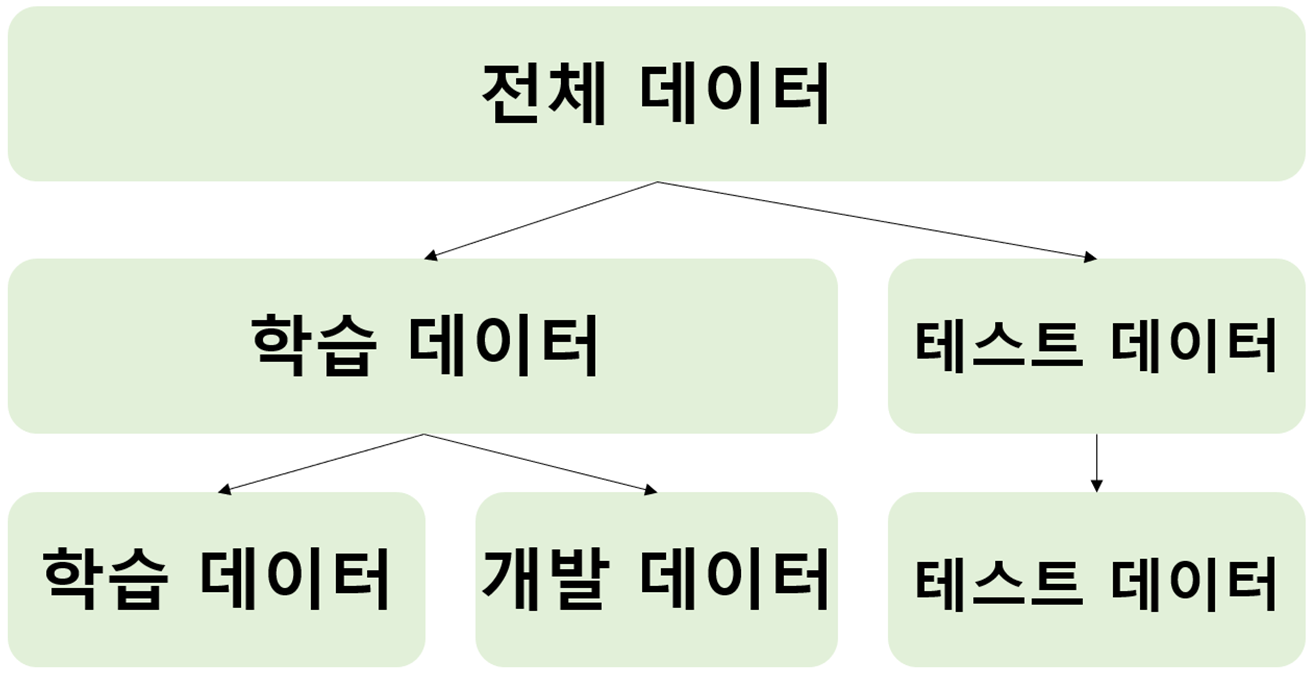
실제 머신러닝 알고리즘을 학습시킬 때는 Data를 3가지로 구분한다. 앞서 설명한 학습데이터와 Test data 외에 개발 데이터(Validation data)도 있다. 개발 데이터는 알고리즘을 학습시킨 후 성능을 평가할 때 사용되며, 성능 평가 결과가 나쁠 경우 하이퍼파라미터(Hyperparameter)를 조정하는 등 알고리즘의 성능을 향상시키기 위해 모델을 재구성하게 된다.
💡 하이퍼파라미터(Hyperparameter)
인공지능 모델을 구성하는 각각의 요소를 어떻게 구성할 것인지를 결정하는 것을 말한다.
인공 신경망을 이용해 여러 가지 문제를 해결하기 위해서는 먼저 인공 신경망의 구조를 설계해야 한다.
여기서 인공 신경망의 구조는 입력층, 은닉층, 출력층을 몇 개로 할 것인지, 각 층의 유닛은 어떻게 구성할 것인지 등을 결정하는 것을 말하는데, 이 정보를 '하이퍼파라미터(Hpyerparameter)'라고 한다.
만약 개발 데이터 없이 Test data로만 성능을 평가하고 하이퍼파라미터를 조정한다면 테스트 데이터의 특성이 알고리즘에 반영되기 때문에 실제 성능보다 더 높게 평가되는데, 이렇게 성능이 높게 나오는 것은 바람직하지 않다.
일반적으로 프로그램 개발 과정에는 학습 데이터나 개발 데이터로 측정한 정확도를 이용한다. 하지만 이를 실제 이용자에게 홍보하거나 외부의 다른 프로그램과 비교를 하는 등과 같이 공식적으로 사용하면 안 된다. 공식적으로 사용하는 프로그램의 정확도는 Test data로 측정한 것이어야 한다.
2. 다중선형회귀
단순선형회귀와 다르게 다중 선형회귀분석은 여러 개의 독립변수(X)들을 가지고 종속변수(y)를 예측하기 위한 분석방법이다.
독립변수 X가 여러개 = 특성(Feature)이 여러 개라는 뜻이다. 이를 제외하면 단순선형회귀와 동일하기 때문에 자세한 내용은 앞의 내용을 참고하길 바란다.
👉 선형회귀 정리
Velog주소: https://velog.io/@sea_panda/N211-TIL-%EB%B0%8F-%ED%9A%8C%EA%B3%A0#2-%EC%84%A0%ED%98%95%ED%9A%8C%EA%B7%80
3. 일반화
지도학습에서 훈련 데이터로 학습한 모델이 훈련 데이터와 특성이 같다면 처음 보는 새로운 데이터가 주어져도 정확히 예측할 거라 기대한다. 모델이 처음보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화(Generalization)되었다고 한다. 그래서 모델을 만들 때는 가능한 한 정확하게 일반화되도록 해야 한다.
다른 말로 정리하여 보자면 학습에 사용되는 데이터에는 조금 손실이 발생하더라도 새로운 데이터에 대해 올바른 예측을 수행하는 능력을 일반화라고 하기도 한다.
머신러닝의 목표는 이전에 보지 못한 새 데이터를 예측하는 것이다. 즉, 학습에 사용되눈 데이터에서 조금 손실을 보더라도 일반화를 통해 모델을 단순화시켜 새로운 데이터에 대한 예측 정확도를 높인다면 더 좋은 모델이라고 할 수 있다.
4. 편향과 분산
"예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(Bias)이 높다고 말하고, 예측값들이 자기들끼리 대체로 멀리 흩어져있으면 분산(Variance)이 높다고 말한다."
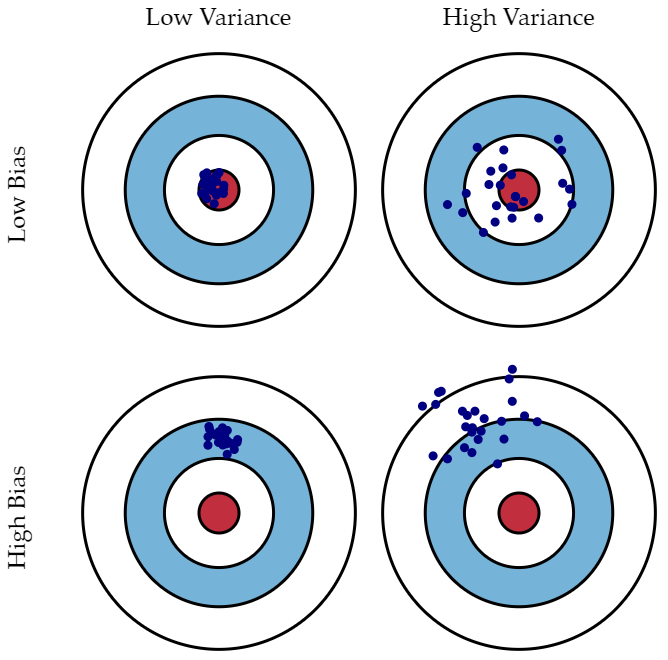
편향은 지나치게 단순한 모델로 인한 Error이다. 편향이 크면 과소적합(under-fitting)을 야기한다. 모델의 편향이 크다는 것은 그 모델이 어떤 주요 요소를 놓치고 있다는 것을 의미한다. 위의 과녁 사진에서 왼쪽 밑에 있는 사진이 높은 편향을 의미한다. 목표지점인 빨간점에서 멀리 떨어져 있는 것이다.
분산은 지나치게 복잡한 model로 인한 Error이다. 또한 데이터셋에 의해서 발생하기도 한다. 훈련데이터에 지나치게 적합시켜 과대적합이 발생할 경우 훈련 데이터셋에서의 편향과 테스트 데이터셋에서의 편향의 차이가 크게(High Variance) 발생된다. 이런 분산이 큰 모델은 일반화가 되지 않았다고 표현할 수 있다.
편향과 분산은 Trade-off관계로 편향이 커지면 분산은 작아지고, 분산이 커지면 편향이 작아진다.
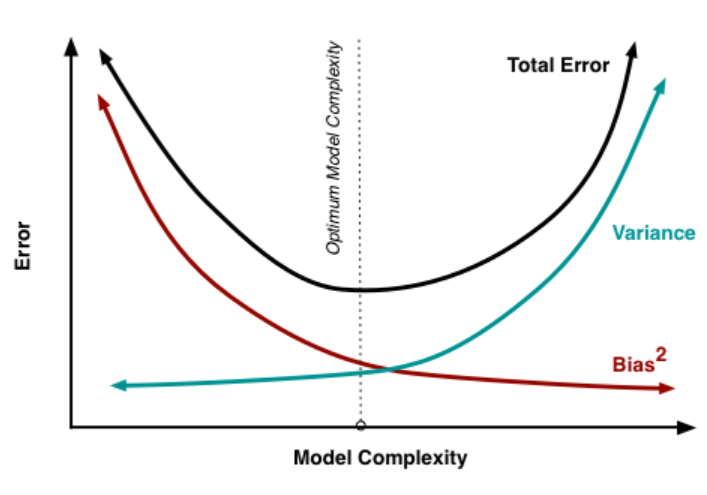
전체 모델의 Error는 위와 같다.위 공식에서 첫 번째 Term은 편향의 제곱을 의미하고, 두 번째 Term은 분산을, 세 번째 Term은 줄일 수 없는 불가피한 Error를 의미한다. 모델이 복잡해질 수록 편향은 작아지고, 분산은 커진다. 즉 과대적합이 일어난다. 모델이 단순해질수록 편향이 커지고, 분산은 작아진다. 즉, 과소적합이 일어난다. 무조건 편향만 줄일 수도, 무조건 분산만 줄일 수도 없다. 오류를 최소화하기 위해서는 편향과 분산의 합이 최소가 되는 적당한 지점을 찾아야한다.
5. 과대적합과 과소적합
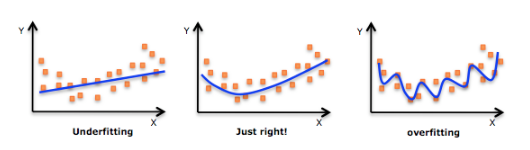
과적합이란 머신러닝 모델이 학습이 학습데이터에 대하여 과도하게 이루어지거나, 반대로 입력 데이터와 출력 데이터 간의 유의미한 관계를 확인할 수 없을 때 발생한다. 각각 경우에 따라서 과대적합, 과소적합이라고 한다.
5-1. 과대적합
과대적합은 모델이 훈련 데이터 세트에 대하여 과도하게 학습하여서 데이터 세트를 일반화하지 못하고 너무 근접하게 적합할 때 발생한다. 이러한 과대적합이 발생하는 이유는 다음과 같은 이유들이 있다.
💡 과대적합의 발생원인 예시
1. 훈련 데이터의 크기가 너무 작고 가능한 모든 입력 데이터 값을 정확하게 나타내기에 충분한 데이터 샘플을 포함하지 않았을 경우.
2. 훈련 데이터에 노이즈 데이터라는 훈련 시에 불필요한 정보가 많이 포함되어 있을 경우.
3. 모델이 단일 샘플 데이터 세트에 대해서 너무 오랫동안 훈련을 수행할 경우.
4. 모델 복잡도가 과도하게 높을 경우.
이러한 과대적합이 발생했는지 탐지할 수 있는 가장 좋은 방법은 테스트 데이터 세트를 이용하여 테스트를 진행하여 보면 된다. 일반적으로 테스트 데이터에서 오차가 높게 측정된다면 이는 과대적합을 의미한다.
이러한 과적합을 방지하기 위한 방법으로는 조기 중지, 프루닝, 정규화, 앙상블링, 데이터 증강 등이 있다. 이 중 정규화를 통한 과대적합 방지 방법은 후에 다룰 릿지회귀,랏쏘회귀 등에서 다루는 방식이다.
5-2. 과소적합
과소적합은 모델이 입력 데이터와 출력 데이터 간의 유의미한 관계를 확인할 수 없을 때, 즉 학습이 제대로 이루어지지 않았을 때 발생한다. 적절한 기간 동안에 많은 데이터 포인트에 대해 훈련하지 않으면 과소적합 모델이 된다.
과소적합의 원인은 다음과 같은 이유들이 있다.
💡 과소적합의 발생원인 예시
1. 모델의 복잡도가 너무 낮은 경우.
2. 모델에 너무 많은 규제가 적용된 경우.
3. 충분하지 못한 epoch로 학습하는 경우.
(epoch: 훈련데이터 세트에 포함된 모든 데이터들이 한 번씩 모델을 통과한 횟수로, 모든 학습 데이터 세트를 학습하는 횟수를 의미.)
이러한 과소적합을 해결하기 위한 방법은 각 상황에 따라 조금 더 복잡한 모델을 적용하여 훈련 데이터 세트의 규칙을 잘 찾아내도록 하거나, 너무 많은 규제가 적용되었을 경우는 이 규제를 줄어준다. 마지막으로는 epoch의 수를 증가시켜 모델이 충분한 학습을 하여 훈련데이터 세트의 규칙을 찾을 수 있도록 만들어 준다.
과소적합 모델은 훈련 데이터와 테스트 데이터 세트 모두에 대해 부정확한 결과를 제공하기 때문에 높은 Bias(편향)을 가진다. 반면, 과대적합 모델은 높은 Variance(분산)을 가진다. 즉, 훈련 세트에 대해서는 정확한 결과를 제공하지만 테스트 세트에 대해서는 정확한 결과를 제공하지 않는 것이다.
모델 훈련이 많을수록 편향은 줄어들지만 분산은 증가할 수 있다. 앞서 다룬 Trade-off관계란 것이다. 데이터 사이언스에서는 모델을 피팅할 때 과소적합과 과대적합 사이의 최적점을 찾는 것을 목표료 한다.
6. 회귀모델을 평가하는 평가지표
6-1. MSE(Mean Squared Error)
잔차제곱의 평균을 의미한다. 따라서 MSE가 낮은 모델일수록 정답을 올바르게 예측한 것이기 때문에 정확도가 높다고할 수 있다. 이는 예측값과 실제값 차이의 면적의 평균이라고 할 수 있다.
잔차제곱의 평균을 이용하면 식에서 미분을 이용할 수 있다는 이점이 존재한다.
단점으로는 평균이라는 것의 특성상 이상치의 영향을 많이 받고 Scale에 영향을 크게 받는다. 또한 잔차를 제곱하는 과정에서 0~1사이의 값은 원래보다 더 작게 반영되고, 1보다 큰 값은 보다 더 많이 반영된다.
6-2. RMSE
MSE의 제곱근이다. MSE에서 루트를 취하기 때문에 MSE가 가지는 단점이 어느정도 해소가 된다. 하지만 루트를 씌운다는 점 때문에 미분이 불가능한 지점을 가진다. 또한 오류지표가 실제 예측값과의 단위와 동일해져 해석에 용이하다는 장점도 존재한다.
6-3. MAE
모델의 예측값과 실제값의 차이(잔차)의 절대값의 평균이다. 절대값을 취하기 때문에 가장 직관적으로 알 수 있는 지표로 해석에 용이하다. 하지만 절대값을 취하기 때문에 모델이 Underperformance인지 Overperformance인지 알 수 없다. 이는 제곱을 취하는 위의 성능지표들도 동일한 단점을 지닌다. 또한 절대값을 취하기 때문에 미분이 불가능한 지점이 생긴다. 위의 MSE와 RMSE와 다른 점은 모든 오차에 대하여 동일한 가중치를 부여한다는 것이다.
말만 들어보면 가중치를 동일하게 부여하는 것이 좋다고 생각할 수 있으나 머신러닝의 학습이라는 관점에서는 특이값에 휘둘리지 않는 것을 굉장히 중요하게 생각한다. 따라서 직관적인 MAE보다 큰 잔차가 발생했을 때 패널티를 주는 이점이 존재하는 RMSE를 더 선호한다.
정리하면, RMSE는 MAE에 비하여 직관성은 떨어지지만 이상치에 의해서 변하는 값의 양이 크지 않다는 점(Robust하다)에서 강점을 보인다.
6-4. R-squared(Coefficient of determination)
R-squared는 현재 사용하고 있는 X변수가 Y변수의 분산을 얼마나 줄였는지에 대한 것이다. 즉, 분산기반으로 예측 성능을 평가하는 성능지표로 결정지수라고도 불린다. 위의 말을 다르게 설명하여 보면, 실제 값의 분산 대비 예측값의 분산 비율을 지표로 한다고 볼 수 있으며, 1에 가까울수록 예측 정확도가 높다.
하지만 의 경우 학습 모델의 특징의 수를 늘리면 그 값이 커진다는 특성이 존재하기 때문에 이러한 특징의 수의 영향을 줄이기 위해서 조정된 결정계수를 사용하기도 한다.
2. 추가개념
1. 모델복잡도
모델복잡도는 말 그대로 모델이 복잡한 정도를 나타내는 지표이다. 그렇다면 복잡한 모델이란 무엇일까? 비선형 모델은 모두 복잡한 모델이라 할 수 있을까? 모델의 독립변수의 종류와 개수가 많으면 복잡한 것일까? 훈련 데이터에 과대적합이 발생하면 복잡한 모델인 것일까? 아니면 여러 모델들을 앙상블하면 복잡한 모델이라 할 수 있을까? 등의 여러 질문들이 떠오를 수 있다.
이러한 질문들을 종합하여 보면 복잡한 모델이란 이해하기 어려운 모델을 의미한다. 개념적으로는 이해되지만 구체적으로 어떻게 구성되고 작동하는지 파악하기 극히 어렵거나 또는 파악 불가능한 모델을 복잡도가 높은 모델이라고 할 수 있다. 보통 머신 러닝의에 의해 생성된 예측 모델을 블랙박스라 표현하는 것도 그 속을 이해할 수 없기 때문이다.
정말 극단적으로 모델복잡도를 간단하게 정리하면 어떤 예측 모델을 정의하기 위해 필요한 파라미터의 수라고도 요약할 수 있다.
만일 동일한 성능의 모델이 존재한다면 모델복잡도가 더 낮은 모델을 선택하는 것이 좋다. 즉, 선형 모델이 우선이고, 더 적은 변수를 사용한 모델, 적당히 학습한 모델, 앙상블 모델보다는 단일 모델을 선택하는 것이 더 좋다는 것이다. 가능하면 이해하기 쉽고 설명 가능한 모델을 사용하라는 것이다. 하지만 이는 성능이 비슷하다는 전제조건 하에서의 이야기이다.
2. 다항회귀
다항회귀는 이름 그대로 독립변수가 다항식으로 구성되는 회귀모델이다.(독립변수의 차수를 높이는 형태)항은 제곱근이나 2차항, 3차항 등 다양하게 있으며 함수의 형태가 비선형이라는 특징이 있다. 하지만 이것이 모든 다항회귀가 비선형 회귀라는 것을 의미하는 것은 아니다! 회귀모델에서 선형성은 회귀계수가 Point이다. 이 점을 잊으면 안된다.
다항 회귀를 활용하는 방법으로는 서로 다른 두 특징을 하나의 특징으로 만들어서 해당 특징을 입력으로 2차 이상의 함수를 예측하는 방법이 있다. 예를 들어 부동산에서 집값 예측 시 땅의 가로/세로 길이가 주어졌을 때 면적으로 만들어서 면적에 따른 결과를 예측하는 등의 방식으로 활용할 수 있는 것이다.
보통 다항회귀에서 2차함수는 중간에 하강하는 그래프 개형이기 때문에 3차 함수, 아니면 단조증가하는 제곱근이나 로그함수를 많이 사용한다.
선형회귀에서 선형성이라는 것이 무엇을 의미하는지 아래의 영상을 참고하자.
💡 유튜브(역펜하임: 선형회귀에서 "선형"의 찐의미
주소:https://www.youtube.com/watch?v=qvLOauLWsfo
3. 명령어
1. Library: sklearn.metrics
예측 모델의 성능을 평가하는 평가지표를 사용할 수 있는 Sklearn의 Package이다.
1. .mean_absolute_error
from sklearn.metrics import mean_absolute_error
MAE = mean_absolute_error('실측값', '예측값')실측값과 예측값을 인수로 받아서 MAE값을 출력하여 준다.
2. .mean_squared_error
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error('실측값', '예측값')실측값과 예측값을 인수로 입력받아 MSE값을 출력하여 준다.
3. .r2_score
from sklearn.metrics import r2_score
R2 = r2_score('실측값','예측값')실측값과 예측값을 인수로 입력받아서 결정계수R2를 출력하여 준다.
2. Library: sklearn.preprocessing
원래의 데이터를 학습에 Downstream estimators에 적합한 형식으로 변경하여 주는 Package이다. 전처리를 해주는 것이라고 보면 된다. Downstream estimator의 예시로는 PCA, 경사하강법, 계층적 클러스터링 등이 있다.
1. .PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = n, include_bias = 'Boolean')
X_poly = poly.fit_transform(X)degree옵션으로 차수를 조절한다. include_bias 옵션은 True로 할 경우 0차항(1)도 함께 만든다.
Sklearn의 PolynomialFeatures는 다항회귀모델을 쉽게 구현하도록 도와준다. 이름에서도 알 수 있듯이 다항 특성(Polynomial Features)을 방정식에 추가하는 것이다. 다항 특성은 특성들의 상호작용을 보여줄 수 있기 때문에 상호작용특성(interaction Features)라고도 부른다.
예를 들어 두 특성을 가진 데이터가 입력으로 들어오면 이것을 기준으로 degree=2인 새로운 특성을 만들어 내는데 즉 특성이 다음과 같이 변한다. 👉
3. Library: sklearn.pipeline
기본적인 Pipeline의 개념은 데이터 전처리에서 학습까지의 과정을 하나로 연결해주는 것이라고 보면 된다.
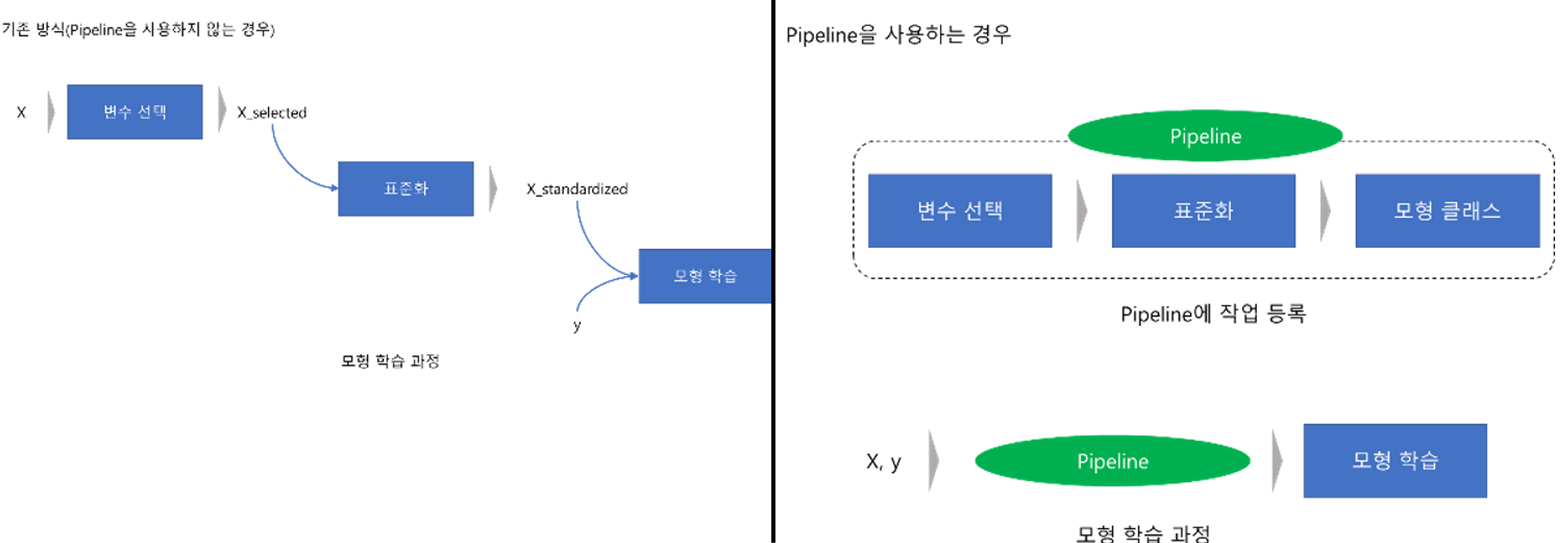
왼쪽 그림은 Pipeline을 사용하지 않은 경우이다. 즉, 기존 방식의 모형 학습과정이다. 기존 방식은 변수 선택 과정을 코딩하고 선택된 변수를 다시 표준화 한 다음 이를 가지고 모형을 학습하게 된다.
하지만 오른쪽 같이 Pipeline을 사용하는 경우 Pipeline에 작업을 등록만 해주면 기존 과정을 한 번에 처리할 수 있다. Pipeline에 작업을 등록하는 것은 어렵지 않기 때문에 모형학습에 있어서 여러가지 과정을 거쳐야 한다면 pipline을 사용하는 것이 유리하다.
Sklearn.pipeline은 이러한 pipeline을 생성할 수 있는 package이다.
Pipeline의 이점
1. Train과 Test데이터의 손실을 피할 수 있다. 👉 왜 그런지는 아직 잘...
2. 교차검증 및 기타 모델 선택 유형을 쉽게 만든다.(무슨 소리고...?)
3. 재현성이 증가된다.
1. .make_pipeline
pipeline을 생성하는 명령어이다. 사용 예시는 다음과 같다.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(degree),LinearRegression(**kwargs))위 pipeline의 경우 다항특성을 방정식에 추가한 후 이를 이용하여 선형회귀 모델을 생성하는 pipe라인을 구축한 것이다. 이외에도 다양한 조합으로, 원하는 방식대로 pipeline을 생성할 수 있다.
4. matplotlib.pyplot.gca()
현재 축을 가져온다. 만약 이 Figure에 Axes가 존재하지 않으면 Figure.add_subplot을 이용하여 새로운 축을 생성한다. 말로는 잘 이해가 가지 않으니 다음과 같은 예시로 알아보자.
import matplotlib.pyplot as plt
from matplotlib import style
style.use('seaborn-talk')
fig = plt.figure()
# for 3d plot
ax = fig.gca(projection='3d')위 코드를 실행하면 생성된 축이 존재하지 않았기 때문에 새로운 축을 생성하는데, 이때, projection에 입력된 3d 축을 생성한다.(근데 2d로는 안된다. 안에 담기는 변수는 추가적으로 나중에 찾아보자.) 실행 결과는 다음 사진과 같다.
5. Library: Plotly
plotly역시 matplotlib, seaborn과 같은 시각화 라이브러리이다. 비교적 matplotlib보다 최근에 만들어졌으며, 반응적인 그래프를 그리기 유용하다.
Matplotlib과 Plotly 둘 중 무엇이 더 좋은 시각화 라이브러리인가에 대해서 많은 논쟁이 있는 것 같다.
❗ 참고 사이트
사이트 주소:https://towardsdatascience.com/matplotlib-vs-plotly-lets-decide-once-and-for-all-dc3eca9aa011
1. plotly.express.scatter_3d
3차원 산점도를 출력하여 준다.
import plotly.express as px
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)opacity는 마커의 불투명도를 조절하는 인자이다.
2. plotly.express.scatter_3d.add_trace
정확히는 .add_trace 명령어이다. 이를 사용하게 되면 원하는 흔적(평면, 선 등..)을 그래프에 추가할 수 있다.
import plotly.express as px
import plotly.graph_objs as go
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)
plot.add_trace(go.Surface(x=x_axis, y=y_axis, z=z_axis, colorscale='Viridis'))위에서 add_trace를 사용하여 add_trace안에 들어있는 도형을 원래의 산점도에 추가하여 출력해준다.
3. plotly.graph_objs
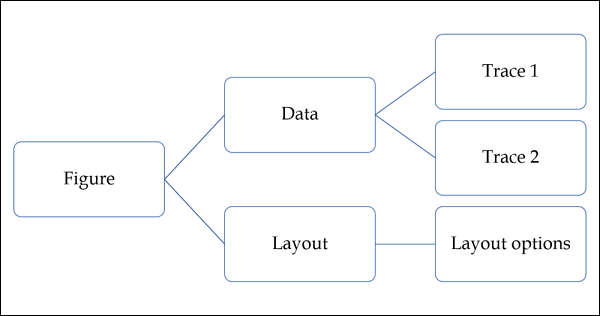
출력되는 Plot을 구성하는 객체애 대한 모든 클래스 정의를 포함하는 모듈이다. 다음과 같은 그래프 개체가 정의된다.
1.Figure
2. Data
3. layout
4. Diferemt graph traces like scatter, Box, Histogram etc.
사용예시는 위의 코드를 참조하자.
6. Module: itertools
itertools는 Python의 모듈로 for 루프를 사용하여 단계별로 넘어갈 수 있는 데이터의 구조를 반복하는데 사용한다. 이러한 반복 가능한 데이터 구조를 iterable이라고 한다. 이 모듈은 반복자 대수를 형성하기 위해서 단독 또는 조합하여 사용된다. 이를 사용하면 코드이 가독성 및 유지 관리 가능성이 향상된다는 장점이 있다.
라이브러리의 다양한 사용법은 다음의 공식 문서를 참고하자.
❗ 참고사이트
사이트 주소: https://docs.python.org/ko/3/library/itertools.html
4. 회고
11월 10일인데 웬만하면 오늘 안에 하려했는데 사랑니 뽑고오니까 너무 아파서 다른거 할 엄두가 안난다 내일 해야겠다. 아 지난번에 위아래 한 번에 뽑을 때는 안아팠는데 이번엔 죽을 거 같이 아프다....
<11월 13일>
분명 금요일에 끝내려했는데 어쩌다 보니 월요일 새벽이다...메운디 맛만보자는 친구의 말에 시작했다가 그 게임 때문에 미쳐서 하다가 주말이 사라졌다. 그래도 즐거웠으니 이번주는 스스로 좀 벌받아야겠다.
❗ 참고자료
1. 한규동,AI 상식사전, 서울:도서출판 길벗, 2022.
2. 성능평가지표
3. 모델복잡도
4. Pipeline
