
TIL이라고 했지만, 오늘은 월요일 새벽이고 난 N213을 지난주 금요일에 배웠다. 맞다. 시원하게 놀아버렸다. 미래에 이거 읽는 나 자신은 반성하고 또 반성하길 바란다. 사실 난 오늘도 미래의 나에게 미룰거다. 오늘 아침에 눈뜨면 이거 알아서 끝내라...
-월요일 새벽의 내가 아침의 나한테...
0. 학습목표
- 범주형(Categorical)자료를 다루기 위한 원핫인코딩(One-hot encoding)기법을 이해한다.
- 일변량 통계 기반 특성선택(Feature Selection)과정을 이해한다.
- 정규화(Regularization)을 위한 Ridge회귀모델을 이해하고 사용할 수 있다.
1. 주요개념
1. One-Hot Encoding
컴퓨터 또는 기계는 문자보다는 숫자를 더 잘 처리한다. 이를 위해 자연어 처리에서는 문자를 숫자로 바꾸는 여러가지 기법들이 있는데, One-hot encoding은 그 많은 기법 중에서 단어를 표현하는 가장 기본적인 표현방법이며, 머신러닝, 딥러닝을 하기 위해서는 반드시 배워야 하는 표현 방법이다.
One-hot encoding에 대해서 배우기 앞서 단어집합(vocabulary)에 대해서 이해해야 한다. 단어집합은 서로 다른 단어들의 집합이다. 여기서 혼동이 없도록 "서로 다른" 단어라는 정의에 대해서 좀 더 주목할 필요가 있다. 단어집합에서는 기본적으로 book과 books와 같이 단어의 변형 형태도 다른 단어로 간주한다.
One-hot encoding을 위해서 먼저 해야할 일은 단어 집합을 만드는 일이다. 텍스트의 모든 단어를 중복을 허용하지 않고 모아놓으면 이를 단어 집합이라고 한다. 그리고 이 단어 집합에 고유한 정수를 부여하는 인코딩을 진행한다. 만일 5000개의 단어가 존재하면 단어의 집합의 크기는 5000이다. 이 단어 집합의 단어들마다 인덱스를 부여할 수 있다. 이렇게 각 단어에 고유한 정수 인덱스를 부여했다면, 이 숫자로 바뀐 단어들을 벡터로 다루고 싶다면 어떻게 해야할까?
One-hot encoding에서는 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현방식이다. 이렇게 표현된 벡터를 One-hot Vector라고 한다.
이 One-hot encoding을 두 가지 과정으로 정리하면 다음과 같다.
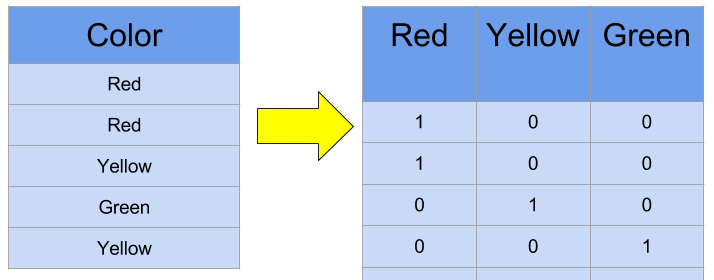
💡 One-hot encoding의 과정
1. 정수 인코딩을 수행한다.
2. 표현하고 싶은 단어의 고유한 정수를 인덱스로 간주하고 해당 위치에 1을 부여하고, 다른 단어의 인덱스의 위치에는 0을 부여한다.
One-hot encoding을 수행하면 각 카테고리에 해당하는 변수들이 모두 차원에 더해지게 된다. 그러므로 카테고리가 너무 많은 경우(High Cardinality)에는 사용하기 적합하지 않다.
수학에서 Cardinality는 요소의 수를 의미한다. 예를들어 은 3개의 요소를 포함하기 때문에 A의 Cardinality는 3이 된다.
데이터의 관점에서는 High Cardinality는 중복 수치를 의미하기도 한다. 중복되는 값이 없을수록 Cardinality가 높다고 표현한다. 즉, One-hot encoding을 진행하면 유일값이 많을수록 표현해야할 특징들이 그만큼 늘어나기 때문이다.
2. Ridge Regression(능형회귀)
회귀분석 시 회귀계수 추정량의 분산이 크다면 모형의 신뢰도가 떨어진다. 이때 고려해 볼 수 있는 방법이 Ridge Regression(능형회귀)이 있다. Ridge Regression은 회귀계수 추정량의 Bias가 발생하지만 분산을 줄여주는 방법으로, 특히 변수들 간에 다중공선성이 존재할 경우 Ridge Regression모형을 사용할 수 있다.
Ridge regression은 기존의 잔차제곱합에 L2벌점항(Penalty term)을 추가한 목적함수를 최소화시켜 회귀계수를 추정하는 방법이다.
이때 절편항 는 벌점항에 포함되지 않는다. 만약 포함시킨다면 인 경우에는 이 되어야 하므로 이 되고 이때에는 절편항만을 가진 회귀모형을 구하게 되기 때문에 만약 포함시킨다면 회귀계수가 오차제곱항에 포함되지 않기 때문에 식이 의미가 없어지기 때문이다.
Ridge Regression을 사용하는 이유는 기본 선형 모델을 사용하다 보면 Overfitting이 발생할 수 있다. Overfitting된 경우 데이터에 매우 적합되어 선형회귀계수의 값이 매우 크게 나타난다. 이렇게 Variance가 큰 상황을 막기 위해서, 계수 자체가 크면 페널티를 주는 수식을 적용함으로써 보다 부드럽게 계수를 선택할 수 있다는 장점으로 인해서 사용한다. 즉, Bias를 조금 더 하고, Variance를 줄이는 방법으로 정규화(Regularization)을 수행한다.
3. 정규화
모델을 변형하여 과적합을 완화하여 일반화 성능을 높여주기 위한 기법을 말한다. 분석 시에 사용된 데이터가 달라져도 계수가 크게 달라지지 않도록 하는 방법을 의미한다.
데이터를 정규화하는 것과 모델을 정규화한다는 표현에 혼동하지 않도록 조심하여야 한다.
4. 교차검증(CV)
교차검증이란 모델 학습 시 데이터를 훈련용과 검증용으로 교차하여 선택하는 방법이다. 크게 3가지 종류로 나눌 수 있다.
💡 교차검증의 종류
1. Hold-out Cross-Validation
특정 비율로 Train/test data를 1회 분할하는 방법론
2. K-Fold Cross-Validation
전체 데이터 셋을 K개의 fold로 나누어 K번 다른 fold 1개를 Test data로, 나머지 (K-1)개이 fold를 train data로 분할하는 과정을 반복함으로써 train 및 test data를 교차 변경하는 방법론
3. Leave-p-Out Cross-Validation(LpOCV)
전체 데이터 N개 중에서 p개의 샘플을 선택하여 모델 검증에 활용하는 방법론
4. Leave-One-Out CV(LOOCV)
LpOCV에서 p=1인 경우에 해당하며, K-fold CV의 경우 K=N인 경우에 해당하는 교차검증 방법이다.
교차 검증을 실행할 경우 특정 데이터 세트에 대한 과적합을 방지할 수 있고, 더욱 일반화된 모델을 생성할 수 있다는 장점이 있다. 또한 데이터 세트의 규모가 적을 시 과소적합을 방지할 수 있다. 하지만 교차검증을 시행함에 따라서 모델 훈련 및 평가 소요시간이 증가한다는 단점이 있다.
2. 명령어
1. Library: Category_encoders
다양한 방법을 사용하여 범주형 변수를 숫자로 인코딩하기 위한 Scikit-learn의 스타일 변환기이다.
1. OneHotEncoder()
from category_encoders import OneHotEncoder
encoder = OneHotEncoder(use_cat_names=True,cols='Column명')
X_train_encoded = encoder.fit_transform(X_train)입력된 데이터세트에 대해서 One-Hot encoding방법을 학습하여 encoding을 진행한다. use_cat_names인자를 True로 설정하면 원래의 Column명을 가진채로 One-hot encoding이 진행된다.
2. Pandas.get_dummies
pandas.get_dummies(data,prefix=['Column명'],drop_first=True)pandas의 One-hot encoding을 진행해주는 모듈이다. prefix는 one-hot encoding을 진행할 column의 명을 입력하여 주고, drop_fist는 True로 설정하여 주면 불필요한 요소를 제거하고 출력하여 준다. 예를들어 3개의 범주를 가지는 범주형 데이터를 이용해 one-hot encoding을 진행하면 1도 아니고, 2도 아니면 당연히 3이기 때문에 3이라는 column을 따로 표시하지 않게 된다.
3. math.factorial()
factorial 값을 계산해주는 명령어이다.
import math
math.factorial(5)위 코드를 실행하면 을 계산해준다.
4. Library: Sklearn.feature_selection
데이터 분석에 있어서 대규모 데이터를 기반으로 분류예측 모형을 만들어야 하는 경우가 많다. 대규모의 데이터라고 하면 표본의 갯수가 많거나 아니면 독립변수 즉, 특징데이터의 종류가 많거나 혹은 이 두가지 모두인 경우가 있다. 따라서 모델을 생성할 때 중요하다고 생각되는 특징 데이터만 선택하여 데이터의 종류를 줄인다.
feature_selection 모듈은 다양한 특징 선택 방법을 제공한다.
1. SelectKBest()
Target변수와 그 외 변수 사이의 상관관계를 계산하여 가장 상관관계가 높은 변수 K개를 선정할 수 있는 모듈이다. 상관관계를 분석하는 방법은 f-regression방식과 chi2(카이제곱) 방식, f-classif 등이 있다.
from sklearn.feature_selection import f_regression, SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_train_selected = selector.fit_transform(X_train, y_train)score_func는 상관관계를 분석하는 방식을 정의한다. k는 상관관계가 높은 변수를 몇 개 사용할 것인지를 결정하는 인자이다.
2. f_regression
상관관계를 계산하는 f_regression 방식을 import해준다. 자세한 공식 및 세부 내용은 아래의 공식 문서를 참고하자.
❗ f_regression 공식문서: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.f_regression.html
3. get_support()
from sklearn.feature_selection import f_regression, SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
selected_mask = selector.get_support()
## 선택된 특성들
selected_names = all_names[selected_mask]이번 코드에서 get_support()는 선택된 column에 대해서 Boolean값을 반환한다. 이를 이용해서 선택된 특징들이 무엇인지 확인할 수 있다.
5. Library: Sklearn.linear_model
1. Ridge()
L2 정규화를 사용한 Ridge regression을 학습 및 생성한다.
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=alpha, normalize=True)
ridge.fit(ans[['x']], ans['y'])
ans['y_pred'] = ridge.predict(ans[['x']])nomalize인자는 fit_intercept가 False로 설정된 경우는 무시된다. 그것이 아닐 경우에는 데이터를 정규화 시킨다.
2. RidgeCV()
교차검증이 내장된 Ridge regressin의 모델을 학습 및 생성하는 명령어이다.
from sklearn.linear_model import RidgeCV
alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0]
ridge = RidgeCV(alphas=alphas, normalize=True, cv=3)
ridge.fit(ans[['x']], ans['y'])
print("alpha: ", ridge.alpha_)
print("best score: ", ridge.best_score_)CV인자는 교차검증에서 사용할 방법을 결정한다. 정수가 입력될 경우에 예측값이 binary 또는 multiclass일 경우에는 Stratified K-Fold방식이 사용된다. 그것이 아니라면 K-fold방법이 사용된다. 반드시 정수가 아니라도 다른 입력을 받을 수 있지만 그건 킹식문서를 참고하자.
3. 회고
<11월 14>
의미가 있나?
<11월 14>
새벽의 나에게 전달받아서 오늘 정리는 끝냈다. 내일은 스첼을 하는 날인데 스첼 끝내고 남은 시간동안 N214를 정리해야겠다. 글 목록은 TIL로 하고는 있는데 진짜 TIL이 다시 되도록 내일을 기점으로 정상화 시켜야겠다.
