0. 학습목표
- 훈련/검증/테스트(train/validate/test) 데이터를 분리하는 이유를 명확히 이해하고 사용한다.
- 분류(Classification)문제와 회귀문제의 차이점을 파악하고 문제에 맞는 모델을 사용할 수 있다.
- 로지스틱회귀(Logistic Regression)를 이해하고 모델을 학습할 수 있다.
1. 주요개념
1. 훈련/검증/테스트(train/validate/test) 데이터
💡 데이터 분할에 대해서 이전 포스트(N212)에 다루었다. 자세한 내용은 그곳 참조.
👉사이트 주소:https://velog.io/@sea_panda/N212-TIL-%EB%B0%8F-%ED%9A%8C%EA%B3%A0
- 훈련 데이터(Train data): 훈련데이터는 모델을 Fit(학습)하는데 사용한다.
- 검증 데이터(Validation data): 예측모델을 선택하기 위해서 예측의 오류를 측정할 때 사용한다.
- 테스트 데이터(Test data): 일반화 오류를 평가하기 위해 선택된 모델에 한하여 마지막에 한 번 사용한다. 테스트 세트는 훈련이나 검증과정에서 사용하지 않도록 주의해야 한다.
만일 데이터가 너무 적다면 교차검증 방식을 이용할 수 있다. 교차검증에 대한 내용은 이전 포스트에 정리하였다.(N213일수도?)그 곳 참조 바람.
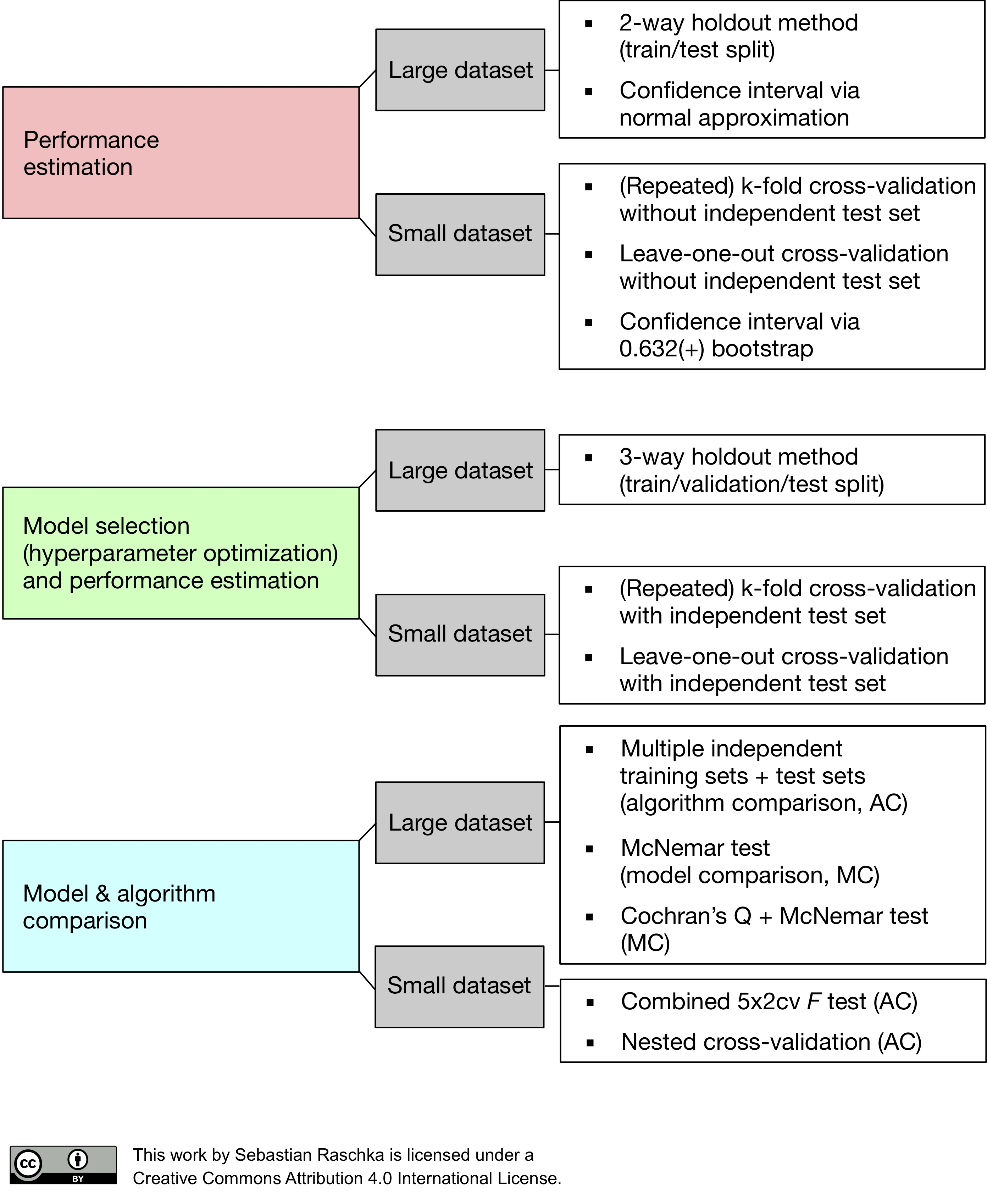
위 사진은 모델 검정 방법을 요약한 모식도(?)이다.
2. Classification(분류)
머신러닝의 지도학습에 대표적인 유형 중 하나이다. 주어진 데이터를 클래스 별로 구별해 내는 과정으로 다양한 분류 알고리즘을 통해 데이터와 데이터의 레이블 값을 학습시키고 모델을 생성한다. 데이터가 주어졌을 때 학습된 모델을 통해 어느 범주에 속한 데이터인지 판단하고 예측하게 된다.
분류 해야할 범주가 이진범주일 경우는 단일 분류라 하며, 여러가지일 경우는 다중 분류라고 한다. 다중분류는 비지도학습의 Clustering과 비슷하지만, 가장 큰 차이점은 "Category의 도메인이 정의되어있는가?"이다.
분류를 위한 다양한 알고리즘이 존재하며 대표적인 분류 알고리즘은 다음과 같다.
💡 분류(Classification)
1. KNN(K-nearest neighbor)
다양한 레이블의 데이터 중에서, 자신과 가까운 데이터를 찾아 자신의 레이블을 결정하는 방식이다. 데이터를 분류하고 새로운 데이터 포인트의 카테고리를 결정할 때 K개의 가장 가까운 포인트를 선점하고 그중 가장 많이 선택된 포인트의 카테고리로 새로운 데이터를 분류한다.
2. Decision Tree(의사결정트리)
가장 단순한 Classifier 중 하나로, decision tree와 같은 도구를 활용하여 모델을 그래프로 그리는 매우 단순한 구조로 되어 있다. 이 방식은 root에서부터 적절한 node를 선택하면서 진행하다가 최종 결정을 내리게 되는 Model이다.
3. Logistic Regression(로지스틱 회귀)
로지스틱 회귀는 일반적이고 효과적인 분류 알고리즘이다. 이름에 회귀라는 단어가 종종 회귀분석에만 사용될 것처럼 헷갈리곤 하지만 범주형 자료를 분류하는데 매우 강력한 알고리즘이다. 독립변수와 종속변수의 선형관계성을 기반으로 만들어졌다.
4. Random Forest
Decision tree가 여러 개 모여 Forest를 이룬 것이다. Decision tree보다 작은 tree가 여러 개 모이게 되어, 모든 트리의 결과들을 합하여 더 많은 값을 최종 결과로 본다.
5. Navie Bayes(나이브 베이즈)
나이브 베이즈 알고리즘은 베이즈 정리를 기반으로 만들어진 분류 알고리즘이다. 나이브 베이즈 알고리즘은 미리 발생한 사건들을 학습시킨 모델을 만든 후 새로운 데이터가 들어오면 이전의 사건들을 기반으로 이 데이터가 어떤 행동을 할 것인지 예측하는 원리이다.
6. SVM(Support Vector Machine)
서포트 벡터 머신은 딥러닝이 대두하기 전까지 가장 많이 활용되던 머신러닝 알고리즘이다. 클래스를 분류할 수 있는 다양한 경계선이 존재하는데 그 중 최적의 라인을 찾아내는 원리앋. 명확하게 분류할 수 있는 데이터 집단에서 뛰어난 성능을 나타내며 고차원 공간에서도 효과적으로 사용 가능하다.
7. Ensemble Learning
앙상블 학습은 여러 개의 분류기에서 각각 예측을 수행하고 그 예측을 결합해서 더 나은 예측 결과를 도출해내는 방법이다. 머리를 맞대고 문제를 풀면 쉽게 정답에 도달할 수 있다는 생각에서 비롯되었으며, 대부분의 정형 데이터를 분류해 낼 때 뛰어난 효과를 나타낸다.
3. Logistic Regression
영국의 통계학자인 D.R. Cox가 1958년에 제안한 확률 모델로서 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용된다.
로지스틱 회귀의 목적은 일반적인 회귀분석의 목표와 동일하게 종속변수와 독립변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다. 이는 독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀분석과 유사하다. 하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류기법으로 볼 수 있다.
일반적으로 로지스틱 회귀의 명칭은 다음과 같이 나타낼 수 있다.
💡 로지스틱 회귀
1. 로지스틱 회귀: 종속변수가 이항형 문제를 지칭할 경우.
2. 다항 로지스틱 회귀: 종속변수가 두 개 이상의 범주를 가지는 문제가 대상인 경우.
3. 서수 로지스틱 회귀: 종속변수가 복수의 범주이면서 순서가 존재하는 경우.
로지스틱 모형 식은 독립 변수가 의 어느 숫자이든 상관 없이 종속 변수 또는 결과값이 항상 사이에 있도록 한다. 이는 Odds를 Logit변환을 수행함으로써 얻어진다. 함수 식은 다음과 같다.
위 오즈 수식에 로지스틱 반응 함수를 적용하면 다음과 같은 수식을 얻을 수 있다.
이 오즈에 로그를 취하여 주는 것을 Logit 변환이라고 한다. 이 Logit변환을 시켜줄 경우 출력의 범위가 (0,-1)에서 로 조정하며 선형 방정식으로 변하게 된다.
이렇게 Logit변환을 시켜주는 이유는 로지스틱 회귀는 비선형 함수라 회귀 계수의 의미를 해석하기가 어렵다. 이 때 로짓 변환을 통해 비선형 형태인 로지스틱 함수 형태를 선형 형태로 만들어 회귀 계수의 의미를 해석하기 쉽게 할 수 있다.
2. 명령어
1. Sklearn.metrics.accuracy_score
분류모델에서는 성능평가를 위해서 일반적으로 Accuracy(정확도)를 평가한다. 이 정확도는 실제 데이터 중 맞게 예측한 데이터의 비율을 의미한다.
from sklearn.metrics import accuracy_score
accuracy_score("실측값", "예측값")2. Library: Sklearn.impute
데이터를 분석함에 있어서 결측치는 분석 시 Error를 발생시킬 위험이 있기 때문에 처리를 해주어야 한다. Sklearn의 impute모듈은 이런 결측치를 어떤 다른 값으로 대체하여 채워넣는 방식으로 처리해준다.
1. SimplemIputer()
imputer = SimpleImputer(strategy = 'mean')
X_train_imputed = imputer.fit_transform(X_train)간단하게 중앙값, 최빈값, 평균값 등의 상수 값을 이용하여 누락된 값을 바꿔준다. strategy인자에 인자를 할당하여 어떤 값으로 채울지 결정할 수 있다.
💡 strategy인자
1. mean: 평균값 대치
2. median: 중앙값 대치
3. most_frequent: 최빈값 대치
4. constant: 이 인자를 사용할 때는fill_value라는 인자를 같이 사용해야한다. 이fill_value에 입력된 값으로 결측값을 대치한다.
3. Sklearn.linear_model.LogisticRegression
Logistic Regression 모델을 생성하여 준다.
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression()
logistic.fit(X_train_imputed, y_train)이때 LogisticRegression()에 다양한 인자들을 설정함으로써 모델을 다양하게 변경해 볼 수 있다. 어떤 penalty를 부여할 지 결정하는 penalty인자부터, 회귀계수를 어떤 방식으로 구할지 정하는 Solver까지 다양한 설정이 가능하다. 자세한 내용은 역시 킹식문서
💡 Sklearn.linear_model.LogisticRegression
사이트 주소: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
또한 Logistic Regression Hyperparameter 사이트를 참조하여도 다양한 인자 설정에 따른 모델의 예측도 차이를 확인할 수 있다.
3. 회고
우선 오늘배운 내용의 목차를 정리했다. 내일 스챌하는 날이니까 스챌끝나고 시간이 널널할테니까 내일 그 시간에 TIL 정상화 완료시킨다는 마인드!
<11월 15>
하 드디어 정상화 됐다.. 이제 밀리지말자 TIL할 것도 많은데 밀리니까 답도 없는 것 같다.
💡 참고 사이트
1. Logistic Regression Hyperparameter
2. 분류(Classification)
