0. 학습목표
- 모델선택을 위한 교차검증 방법을 이해하고 활용할 수 있다.
- 하이퍼파라미터를 최적화하여 모델의 성능을 향상시킬 수 있다.
1. 주요개념
1. 교차검증
머신러닝에서 사용하는 데이터 세트는 알고리즘을 학습시키는 학습 데이터와 이에 대한 예측 성능을 평가하기 위한 별도의 테스트용 데이터가 필요하다. 하지만 이런 데이터 분할 방법 역시 과적합(Overfittion)에 취약한 약점을 가질 수 있다. 이러한 문제점을 개선하기 위해 교차 검증(Cross Validation)을 이용하여 더 다양한 학습과 평가를 수행한다.
교차 검증을 좀 더 간략히 설명하자면 본고사를 치르기 전 모의고사를 여러 번 보는 것이다. 즉, 본고사가 테스트 데이터 세트에 대해서 평가흐는 거라면 모의고사는 교차 검증에서 많은 학습과 검증세트에서 알고리즘 학습과 평가를 수행하는 것이다. 머신러닝은 데이터에 기반한다. 그리고 데이터는 이상치, 분포도, 다양한 속성값, 피처 중요도 등 여러 가지 ML에 영향을 미치는 요소를 가지고 있다. 특정 ML 알고리즘에서 최적으로 동작할 수 있도록 데이터를 선별해 학습한다면 실제 데이터 양식과는 많은 차이가 있을 것이고 결국 성능 저하로 이어질 것이다. 교차 검증은 이런 데이터 편중을 막기 위해서 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것이다. 그리고 각 세트에서 수행한 평가 결과에 따라 하이퍼 파라미터 튜닝 등의 모델 최적화를 더욱 손쉽게 할 수 있다.
대부분의 머신러닝 모델의 성능 평가는 교차 검증 기반으로 1차 평가를 한 뒤에 최종적으로 테스트 데이터 세트에 적용해 평가하는 프로세스이다. 테스트 데이터 세트 외에 별도의 검증 데이터 세트를 둬서 최종 평가 이전에 학습된 모델을 다양하게 평가하는데 사용한다.

지금까지 노트를 진행하면서 써왔던 위의 사진과 같이 데이터 세트를 분류하는 검증방법은 Hold Out CV이다.
1-1. K-fold CV
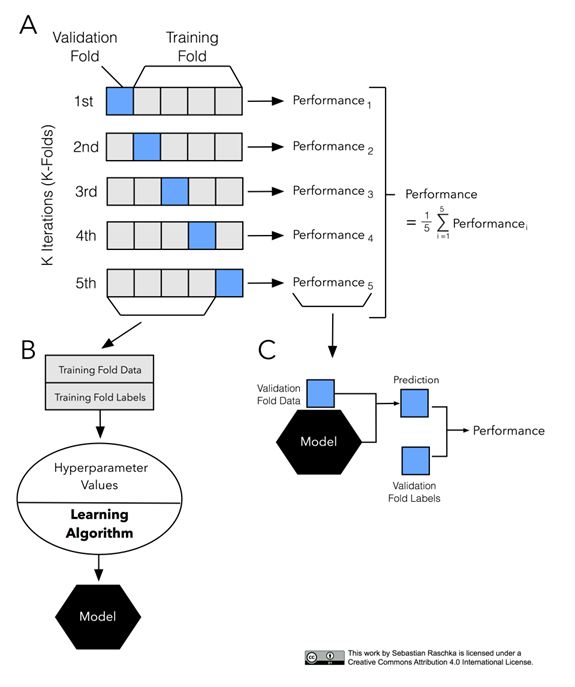
K-fold 교차검증은 가장 보편적으로 사용되는 교차 검증 기법이다. 먼저 K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴트 세트에 학습과 검증 평가를 반복적으로 수행하는 방법이다.
💡 K-fold CV 알고리즘
1. 데이터 세트를 K개로 분할 후, 1개의 데이터 세트를 홀드아웃 샘플로 따로 떼어 놓는다.
2. 남아 있는 데이터로 모델을 훈련한다.
3. 모델을 홀드아웃 샘플에 적용하고 필요한 모델 평가 지표를 기록한다.
4. 처음 추출한 홀드아웃을 복원하고 다른 1개의 데이터 세트를 따로 홀드아웃 샘플로 떼어 놓는다.
5. 2~3단계를 반복한다.
6. K번까지 반복을 끝내면 평가 지표 기록을 이용하여 성능 평가 지표의 평균을 계산한다.
sklearn에서는 K-fold 교차 검증 프로세스를 구현하기 위해서 KFold와 StratifiedKFold클래스를 제공한다.
1-2. Stratified K-fold CV
Stratified K-fold 교차 검증은 불균형한 분포도를 가진 레이블 데이터 집합을 위한 K-fold방식이다. 불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것을 말한다.
대출 사기 데이터를 예측한다고 가정해 보자. 이 데이터 세트는 1억 건이고, 수십 개의 피처와 대출 사기 여부를 뜻하는 레이블(대출 사기: 1, 정상 대출:0)로 구성돼 있다. 그런데 대부분의 데이터는 정상 대출일 것이다. 그리고 대출 사기가 약 1000건이 있다고 한다면 전체의 0.0001%의 아주 작은 확률로 대출 사기 레이블이 존재한다. 이렇게 작은 비율로 1 레이블 값이 있다면 K 폴드로 랜덤히게 학습 및 테스트 세트의 인덱스를 고르더라도 레이블 값인 0과 1의 비율을 제대로 반영하지 못하는 경우가 쉽게 발생한다. 즉, 레이블 값으로 1이 특정 개별 반복별 학습/테스트 데이터에는 상대적으로 많이 들어 있고, 다른 반복 학습/테스트 데이터 세트에는 그렇지 못한 결과가 발생한다. 대출 사기 레이블이 1인 레코드는 비록 건수는 작지만 알고리즘이 대출 사기를 예측하기 위한 중요한 피처 값을 가지고 있기 때문에 매우 중요한 데이터 세트이다. 따라서 원본 데이터와 유사한 대출 사기 레이블 값의 분포를 학습/ 테스트 세트에도 유지하는게 매우 중요하다.
Stratified K-fold는 이처럼 K-fold가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습 및 테스트 세트에 제대로 분배하지 못하는 경우의 문제를 해결해 준다. 이를 위해 Stratified K-fold는 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분해한다.
이외에도 다양한 방식의 교차 검증 방법이 존재한다. 이거는 나중에 또 기회가 있겠지?
2. 하이퍼퍼라미터 튜닝
학습 알고리즘을 위한 최적의 하이퍼 파라미터 세트를 선택하는 것이다. 여기서 하이퍼 파라미터에 대해서는 N212에 정리하였다. 참고바람.
2. 명령어
1. numpy.seterr
부동소수점 오류 처리 방법을 설정하는 명령어이다. 나눗셈(divide),오버플로우(over), 언더플로우(under), 유효하지 않은 소수점(invalid)에 대해서 각각 처리가 가능하며 처리 방법으로 ignore(무시), warn(경고), raise(에러발생), call(함수호출), print(경고출력),log(log객체에 기록)가 있다.
numpy.seterr(all='ignore')
numpy.seterr(divide='ignore',over='call')2. Library: category_encoders
2-1. TargetEncoder
범주형 Features에 대해서 사용할 수 있는 Encoding방법 중 하나인 TargetEncoding을 수행하는 명령어이다. Target Encoding의 일반적인 아이디어는 target 변수의 더 큰 값에 해당하는 범주가 더 큰 숫자로 인코딩 되게 하는 것이다. 하지만 이렇게 Target 변수의 확률을 이용해 더 큰 값에 해당하는 범주가 더 큰 숫자로 인코딩 되는 과정에서 다른 범주에서 동일한 값이 출력되는 등 문제가 발생할 수 있다. 이러한 원치 않는 효과를 줄이기 위해서 smoothing파라미터를 설정하여 줄 수 있다.
# 예시
from category_encoders import TargetEncoder
target_enc=TargetEncoder(min_samples_leaf=1, smoothing=1)
target_enc.fit_transform(X_train,y_train)3. Library: sklearn.model_selection
3-1. validation_curve
Train 및 Test data setd에 대한 다양한 하이퍼 파라미터 값을 이용한 점수를 출력하여 준다.
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
DecisionTreeRegressor()
)
from sklearn.model_selection import validation_curve
depth = range(1, 30, 2)
ts, vs = validation_curve(
pipe, X_train, y_train
, param_name='decisiontreeregressor__max_depth'
, param_range=depth, scoring='neg_mean_absolute_error'
, cv=3
, n_jobs=-1
)
train_scores_mean = np.mean(-ts, axis=1)
validation_scores_mean = np.mean(-vs, axis=1)위 코드를 실행하면 cv=3이기 때문에 1번의 depth에 대해서 3번 검증을 실시하므로 출력(ts,vs)은 15 by 3 행렬이 된다. 이때 검증을 통해 얻은 값을 평균을 내어 대푯값으로 사용하기 때문에 평균을 구해주는 것이다.
💡 중요 Point!
위의 Code를 자세히 살펴보게 되면scoring이라는 모델 성능 평가 지표를 계산하는 하이퍼파라미터인데 일반적인MAE가 아닌 앞에neg가 붙어있다는 사실을 알 수 있다. 이렇게 음수를 만들어 주는 이유는Validation_curve나 앞으로 나올GridSeach,RandomozedSearchCV와 같은 경우 숫자가 클수록 "좋은 것"이라고 인식하기 때문에 낮을수록 좋은 지표는 앞에 를 붙혀주는 것이다!
3-2. RandomizedSearchCV
지정된 범위에서 각 하이퍼 파라미터들을 "Random"하게 조합하여 검증을 실시한다. 이를 통해서 Random으로 이루어진 검증에서 원하는 평가지표에서 최고의 값을 기록하는 모델을 뽑아낼 수 있다. 말그대로 범위 내에서 정해진 수만큼 랜덤하게 조합을 추출하여 사용하기 때문에 범위 안의 모든 조합을 탐색하는 GridSearchCV방식보다 Cost가 적다는 장점이 있다.
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);3-3. GridSearchCV
지정한 하이퍼파라미터의 가능한 모든 조합을 이용하여 최적점을 찾아낸다.
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(
OrdinalEncoder(cols=cols_enc,mapping=mapping_enc,handle_unknown='return_nan'),
SimpleImputer(),
RandomForestClassifier(oob_score=True)
)
dists = {
'randomforestclassifier__n_estimators': [300,400,500,600,700,800,900,1000],
'randomforestclassifier__max_depth': [3,4,5,6],
'randomforestclassifier__criterion': ['gini','entropy']
}
clf = GridSearchCV(
pipe,
param_grid=dists,
cv=3,
scoring='roc_auc',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);4. Library: scipy.stats
4-1. randint()
scipy.stats.randint()이 코드가 솔직히 어떤 기능을 하는지 잘 모르겠다. numpy의 randint와 비슷한 역할로 보이고, scipy.stats의 randint는 학률분포를 지정해서 그릴 수 있다고 하는데 솔직히 무슨 말인지 모르겠다.... 나중에 아래 두 사이트를 보면서 이해가 되는지 복습해보자.
💡 참고사이트
1. StackOverflow
2. 공식문서
4-2. uniform()
균일한 연속 확률 변수라고 한다. 또 무슨 소린지 모르겠다.보면 대충 입력된 값의 범위에서 모두 동일한 확률로 뽑아낸다는거 같은데 봐도 모르겠다....
from scipy.stats import uniform
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
mean, var, skew, kurt = uniform.stats(moments='mvsk')위의 randint도 그렇고 이쪽은 사실 numpy가 설명이 더 직관적인거 같은데 잘 모르겠다. 실행 모습을 확인하고 싶어도 랜덤으로 숫자를 뽑아주는게 아니라 어떤 클래스(?)안에서 호출될 때 숫자를 뱉어내는 것 같다....
3. 회고
개인적인 공부를 해야하는데 사실상 개인적인 공부는 진행하지 못한 것 같다. 저녁에 시간이 있는데 항상 게으른 내 잘못이지...괜히 돈주고 산 비싼책만 썩어가고 있다. 오늘은 정리가 빨리 끝났으니 책을 좀 보려고한다. 그리고 아 kaggle과제 score 0.6점만 넘고 싶은데 아직 못넘어서 답답하다. 내일 스챌 끝나고 시간이 남으면 그때 한 번 성능 개선 진행해보고 오늘은 일단 책을 좀 보자 아까운 내돈...

❗ 참고 자료
1. 권철민, 파이썬 머신러닝 완벽 가이드(개정 2판), 파주:위키북스, 2022
2. HyperParameter
3. TargetEncoding
