0. 학습목표
- 예측 모델을 위한 타겟을 올바르게 선택하고 그 분포를 확인할 수 있다.
- 테스트/학습 데이터 사이 or 타겟과 특성들간 일어나는 정보의 누출(leakage)을 피할 수 있다.
- 상황에 맞는 검증 지표(metrics)를 사용할 수 있다.
1. 주요개념
1. Data Leakage(데이터 누출)
데이터에 대해서 완전히 이해하고 있지 못할 때, 모델을 만들고 평가를 진행했는데 예측을 100% 가깝게 잘 하는 경우를 종종 볼 수 있을 것이다. 이때 좋은 모델을 만들어 냈다고 만족하거나 좋아하면 안된다. Data Leakage(정보 누수)가 존재할 가능성이 매우 크기 때문이다.
Data Leakage는 우리가 모른다고 가정된 정보가 누설된 경우를 의미한다. 대체로 다음과 같은 경우에 발생한다.
💡 Data Leakage의 발생 경우
1. 타겟변수 외에 예측 시점에 사용할 수 없는 데이터가 포함되어 학습이 이루어질 경우
2. 훈련데이터와 검증데이터를 완전히 분리하지 못했을 경우
첫 번째 경우의 예시는 과거의 전 1시간 단위로 기록된 train,test data에 "일 평균 온도"라는 Feature를 만들었다고 하자. 과연 일 평균 온도라는 특성이 예측 시점에 사용할 수 있을까? 답은 "불가능하다" 이다. 당장 한시간 뒤의 온도도 예측하지 못하는데 "일 평균 온도"라는 feature를 만들 수 없는 것이다. 즉, 모델을 사용하여 예측을 수행하려는 시점에 실제 값을 실제로 사용할 수 없는 Feature가 포함되었다는 의미이다.
두 번째 경우는 쉽게 말하자면 분리가 제대로 되지 않아서 예측하려는 검증 데이터에 대한 정보를 가지고 학습했다는 의미이다.
Data leakage가 일어나면 과적합이 일어나고 실제 테스트 데이터에 대해서는 성능이 급격하게 떨어지기 때문에 항상 Data를 분석함에 있어서 Leakage를 조심해야 한다.
2. 불균형 데이터의 해결방안
불균형 데이터란 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이가 나는 데이터를 의미한다. 예를 들어서 암 발생 환자가 암에 걸리지 않은 사람보다 현저히 적고, 신용카드 사기 거래인 경우가 정상 경우보다 현저히 적다. 이런 경우 각 클래스의 비율의 차이가 엄청날 것이다. 이런 데이터를 불균형 데이터라고 한다.이런 불균형한 데이터 세트는 불균형한 데이터를 그대로 예측하기 때문에 과적합 문제가 발생할 가능성이 높다.
데이터가 불균형하다면 분포도가 높은 클래스에 모델이 가중치를 많이 두기 때문에 모델 자체에서는 "분포가 높은 것으로 예측하게 된다면 어느정도 맞힐 수 있겠지?"라고 생각한다. 따라서 모델은 가중치가 높은 클래스를 더 예측하려고 하기 때문에 Accuracy는 높아질 수 있지만, 분포가 작은 클래스의 재현율이 낮아지는 문제가 발생할 수 있다. 그리고 과적합이 발생하여 Test data에 대해서는 예측 성능이 확 떨어지게 된다.
항상 모델을 만들 때는 일반화 정도가 높은 모델을 만드는 것이 중요하다. 그렇기 때문에 예측시 이러한 과적합 문제를 해결하기 위해서는 다양한 방법론이 있지만 기본적으로 데이터가 불균형하다면 불균형 문제를 해결한 뒤 문제에 접근을 해야한다. 이러한 문제를 해결하기 위한 방법론으로 크게 2가지가 존재한다
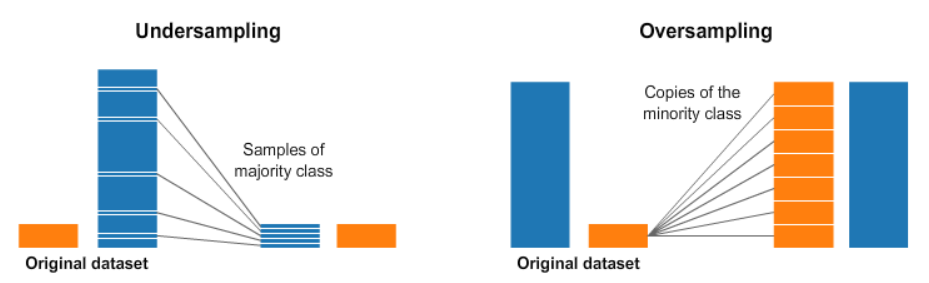
2-1. Under Sampling
Down sampling라고도 불리며 데이터의 분포가 높은 값을 낮은 값으로 맞춰주는 작업을 거치는 것을 말한다. 위의 그림처럼 데이터 분포를 확인한 후 분포가 높은 Class를 낮은 분포의 Class크기에 맞춰주는 작업을 거치게 된다.
- 장점
- 다수 범주 데이터의 제거로 계산시간이 감소할 수 있다.
- 유의마한 데이터만을 남길 수 있다.
- 단점
- 데이터의 제거로 인한 정보 손실이 발생할 수 있다는 단점이 존재한다.
- 종류
- Random Under Sampling
- Tomek link
- CNN(Condensed Nearest Neighbour)
- Edited Nearest Neighbours
2-2. Over Sampling
Up Sampling라고도 불리며 분포가 작은 클래스의 값을 분포가 큰 클래스로 맞춰주는 샘플링 방법이다. 위의 그림처럼 분포가 작은 클래스 값을 일련의 과정을 거쳐 생성하는 방법이다.
- 장점
- 정보의 손실을 막을 수 있다.
- 대부분의 경우 언더 샘플링에 비하여 높은 분류 정확도를 보인다.
- 단점
- 데이터의 증가로 인해 계산 시간이 증가할 수 있다.
- 여러 유형의 관측치를 다수 추가하기 때문에 오히려 과적합을 야기할 수 있다.
- 종류
- Random Over Sampling
- ADASYN(Adaptive Synthetic Sampling)
- SMTOE
- Combine Sampling
- SMOTE + ENN
- SMOTE + TOMEK
Python에서는 Classifier의 하이퍼 파라미터class_weight를 설정하여 가중치를 주어서 불균형 데이터를 해결할 수 있다.
3. 로그 스케일링
데이터 분석에 있어서 log 스케일링을 하는 이유는 한마디로 정규성을 높이고 분석에서 정확한 값을 얻기 위함이다. 데이터 간 편차를 줄여 왜도(Skewness)와 첨도(Kurtosis)를 줄일 수 있기 때문에 정규성이 높아진다.
log변환은 크게 두가지의 경우 사용된다.
💡 사용 경우
1. 큰 수를 작게 만들 경우
2. 복잡한 계산을 간편하게 위할 경우
로그를 취하는 순간 그 수는 진수가 되어버리니, 값이 작아지고 로그의 성질에 따라 곱셈은 진수의 덧셈으로 나누기는 뺄셈으로 바뀐다. 결론적으로 식에 log를 취하는 이유는 큰 수는 작게 만들고, 복잡한 계산을 쉽게 만들고, 왜도와 첨도를 줄여 데이터 분석 시 의미 있는 결과를 도출하기 위함이다.
그렇다면 언제 이런 log변환을 적용할지 고민이 들 수 있다. 결론만 말하자면 그런 법칙은 없다. 분석가의 마음이다. 다만 로그를 쓰는게 더 나은 경우는 있다.
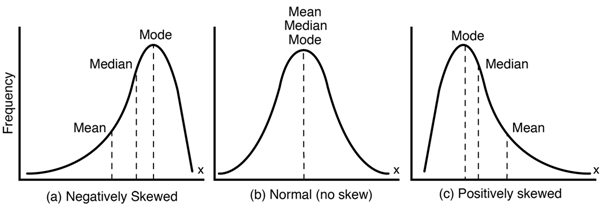
예를 들어 위의 사진에서 Positively skewed일 경우 log 변환을 취해주면 큰 수를 가지는 이상치의 수의 크기가 작아지기 때문에 Normal한 형태에 가깝게 변하게 된다. 이런 경우는 log 변환을 취해주면 좋은 경우이다. 이것 외에도 다음과 같은 이유들로 log변환을 취하기도 한다.
💡 log변환
1. 단위(Scale)에 문제가 있을 경우
2. 모형(Model)에 문제가 있을 경우
3. 데이터 생성 과정(Data Generating Process)의 문제
2. 명령어
1. Library: Numpy
1-1. numpy.logical_or()
각 요소에 대해서 입력된 두가지 조건(X1, X2)에 대해서 X1 or X2의 Boolean값을 계산한다.
x = np.arange(5)
np.logical_or(x < 1, x > 3)
>>> array([ True, False, False, False, True])1-2. numpy.bincount()
배열에서 각 값이 발생한 횟수를 계산하여 배열의 형태로 출력해준다.
np.bincount(np.array([0, 1, 1, 3, 2, 1, 7]))
array([1, 3, 1, 1, 0, 0, 0, 1])즉, 첫 번째 자리는 0의 발생 횟수, 두 번째는 1의 발생 횟수...을 의미한다.
1-3. numpy.percentile()
지정된 축을 따라서 데이터의 q번째 백분위수를 계산하여 준다. 이때 q는 계산할 백분위수 또는 백분위수 시퀀스로, 0~100사이여야 한다.
a = np.array([[10, 7, 4], [3, 2, 1]])
np.percentile(a, 50)
>>> 3.5
np.percentile(a, 50, axis=0)
>>> array([6.5, 4.5, 2.5])1-4. numpy.quantile()
지정된 축을 따라서 q번째 분위수를 계산한다. q는 계산할 분위수 또는 분위수 시퀀스로, 0과 1사이여야 한다.
a = np.array([[10, 7, 4], [3, 2, 1]])
np.quantile(a, 0.5)
>>> 3.5
np.quantile(a, 0.5, axis=0)
>>> array([6.5, 4.5, 2.5])1-5. numpy.log1p()
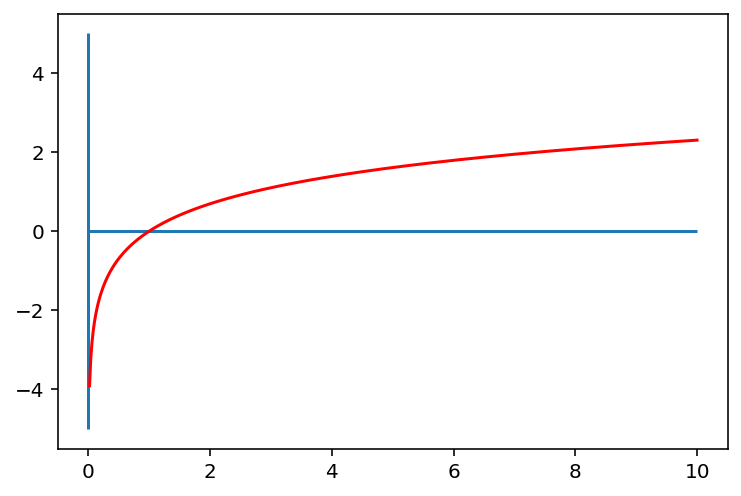
요소별로 입력 배열에 1을 더한 자연로그를 반환한다. 이때 1을 굳이 더하는 이유는 log그래프를 살펴보면 알 수 있다. 그래프를 살펴보면 범위에서는 기울기가 매우 가파른 것을 볼 수 있다. 즉, 의 구간은 (0,1)로 매우 짧은 반면, y의 구간은 으로 매우 크다.
따라서 0에 가깝게 모여있는 값들이 x로 입력되면, 그 함수값인 값들은 매우 큰 범위로 벌이지게 된다. 반면, x값이 점점 커짐에 따라서 로그함수의 기울기는 급격히 작아진다. 이에 따라서 넓은 범위를 가지는 를 비교적 작은 값의 구간 내에 모이게 하는 특징을 가진다. 그렇기에 결과적으로는 데이터 분포를 모았을 때 밀집되어 있는 부분은 퍼지게 퍼져있는 부분은 모아지게 만들 수 있는 것이다. 이는 위의 Log변환에서도 살펴본 특성이다.(오히려 여기서 더 자세히 설명한 거 같은데?)
그렇다면 왜 1을 더할까? 위에서도 말했듯이 인 경우 가 값을 가지기 때문에 Code에서 이를 실행하게 되면 warning 메세지가 출력되며 가 포함된 배열을 반한환다. 이런 문제를 해결하기 위해서 1을 더해주는 것이다. np.log(1+x)는 결과적으로 np.log1p(x)와 같은 값을 출력한다. 굳이 np.log1p를 사용하는 이유는 변환 전의 값이 너무 작으면 컴퓨터 계산의 오류가 생기기 때문에 직접 +1을 해주는 것이 아니라 np.log1p를 사용한다.
np.log1p(np.exp(1)-1)
>>> 1.01-6. numpy.expm1()
np.log1p의 역함수로 배열의 모든 요소에 대해서 exp(x)-1연산을 수행한다.
np.expm1(np.log(1))
>>> 0.02. .notna()
누락값은 False를 반환하고, 기존값은 True를 반환한다. 즉, 값이 결측치인지 아닌지를 나타내는 입력 배열과 동일한 크기의 Bool객체를 반환한다.
ser = pd.Series([5, 6, np.NaN])
ser
>>>
0 5.0
1 6.0
2 NaN
dtype: float64
ser.notna()
>>> 0 True
1 True
2 False
dtype: bool3. module: sklearn.compose
3-1. TransformedTargetRegressor
func에 입력된 명령어를 사용하여 데이터를 변형한 후 회귀문제를 푼다. 그 후 invers_func에 입력된 명령어를 이용하여 원래 Train데이터의 공간과 동일한 공간으로 예측을 반환한다.
# 사용 예시
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
Ridge(alpha=0.01)
)
tt = TransformedTargetRegressor(regressor=pipe,
func=np.log1p, inverse_func=np.expm1)
tt.fit(X_train, y_train)
tt.score(X_val, y_val)3. 회고
월드컵이 너~~무 재미있다. 아니 이거 결과를 들고 과거로 가면 아무도 안믿어줄 결과들이 나오니까 너무 재미있다. 그래서 오늘은 공부를 많이 하지는 못했다. 요즘 그리고 공부를 어떻게 해야하는지 뭔가 붕 뜬 느낌이라고 해야하나 할 것들은 많은데, 다른 분들이 하는거 보면 내가 뭔가 잘못하고 있는게 아닐까 걱정되고 그렇다..그래도 이게 끝나도 복학해서 학교 졸업할때까지 약간의 시간이 있으니까 천천히 꾸준히 해야겠다 생각은 하는데 조바심이 나는건 어쩔 수 없는 거 같다.
❗ 참고자료
1. Data Leakage1
2. Data Leakage2
3. Data Leakage3
4. 불균형 데이터1
5. 불균형 데이터2
6. log 변환
7. np.log1p
