
이번주 월요일에 들은 수업인데 화요일 밤이 되서야 작성하고 있다. 진짜 이게 TIL이라고 할 수 있는지 나도 모르겠다. 내일부터 프로젝트만 아니였다면 더 미뤘을 거 같은데 이거 정리 끝내야 내일부터 시작하는 프로젝트 Daily정리를 할 수 있을 거 같다...오늘은 몇시에 잘란가
이번 정리는 White Mode로 보자!
0. 학습목표
- 부분의존도그림(Partial dependence plot, PDP)을 시각화하고 해석할 수 있다.
- 개별 예측 사례를 SHAP value plots을 사용해 설명할 수 있다.
1. 주요개념
1. Partial Dependence Plots(PDP)
PDP 또는 PDP Plot은 부분의존도라고 하며 이 개념을 이해하기 위해서는 Marginal Effect와 Marginal Probabiliry(한계확률)에 대해서 알고 있어야한다.
💡 Marginal Effect
특정 Independent Variable에 변화가 발생했을 때 Dependent Variable이 어떻게 변하는가를 보여준다. 이때 다른 Independent Variable은 모두 상수로 고정 되어 있어야 한다.
쉽게 이야기 하면 다른 모든 설명변수의 조건이 일정하다고 할 때, 설명변수의 변화가 종속변수의 변화에 미치는 영향을 나타내는 것이다.
💡 Marginal probability
주변확률은 결합확률이 있다는 조건에서 존재한다. 여기서 결합확률은 두 확률변수의 교집합이 발생할 확률이다.
이산형 확률변수의 경우 두 개(혹은 그 이상)의 확률변수로 구성된 결합확률표에 존재한다. 위의 결합확률표에서 한 확률변수의 확률만을 고려하는 것이 주변확률(Marginal probability)이다.
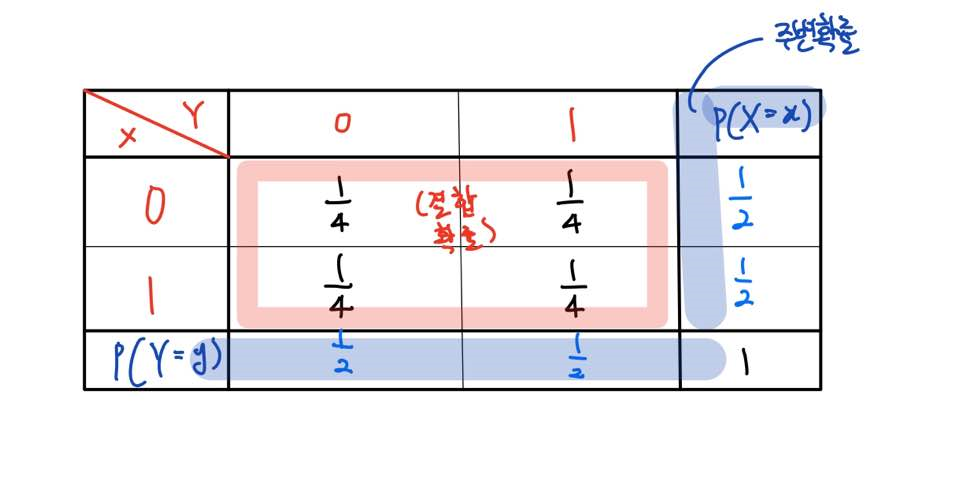
Partial Dependence Plot(PDP)는 Model-agnostic방법 중의 하나이다. PDP는 관심 대상인 변수와 Target간의 Marginal effect를 Plot으로 나타내어 확인하는 방법이다. 이 때, 관심 대상인 변수는 최대 2개까지 함께 확인할 수 있다. PDP는 매우 직관적이면서, 어느 모델이든 학습시킨 후에 적용할 수 있다는 점에서, 알아두면 좋은 방법이다.
이론적인 방법으로는 기본적으로 두 개의 랜덤 변수 가 존재할 때, 두 변수의 결합 분포(joint distribution)를 에 대해 기대값을 취하면, 의 Marginal Probabiliry를 얻게 된다.
PDP에서는 이를 이용한다. 관심있는 변수들을 , 그 외의 변수들을 라고 할 때, 의 Partial Dependence Function은 다음과 같이 계산된다.
즉, 관심 대상이 아닌 변수들의 분포에 대해서 주변화하는 작업을 통하여 관심 대상인 변수에만 의존하는 함수를 구하는 것이다. 위 함수는, 관심 대상인 변수의 각 값에 대해서, 평균 Marginal Effect가 어느정도 되는지를 나타내는 것으로 해석할 수 있다.
하지만 위의 이론적인 식은 현실에서 실제로 사용하기 어렵다. 주변분포를 구하기 위해서는, 결합분포, 관심대상이 아닌 변수들의 주변분포를 알아야 하는데, 그걸 알아내기는 거의 불가능하기 때문이다. 따라서 주어진 데이터를 가지고 이에 근사하는 함수를 추정한다.
추정하는 아이디어는 정말 간단하다. 먼저, 전체 샘플의 개수가 개라고 할 때, 근사함수는 다음과 같이 계산된다.
는 변수의 i번째 샘플값을 의미한다. 즉, 고정된 값에 대한 의 Partial Dependence Function의 함숫값으로, 변수의 모든 샘플값을 로 고정했을 때의 전체 예측값들의 평균값을 추정하는 것이다.
조금 더 직관적인 이해를 위해서 풀어서 말하자면 만일 성별이 관심변수라고 하자. 그러면 먼저 해당 특성의 모든 값을 "여성"으로 대체한 후에 예측값을 구하고 예측 값의 평균을 구한다. 다음으로는 "남성"으로 대체한 후 예측값을 구하고 예측값의 평균을 구한다. 그 후 이 평균 예측값이 어떻게 변화하는지 Plot하여 나타낸다. 이 때, 축은 (남성,여성)일 것이고, 축에 해당하는 값은 각각의 평균 예측값일 것이다.
하지만 이 PDP를 사용하기 전에 주의해야할 사항이 있다.
❗ 주의사항
1. 샘플 수가 굉장히 많거나 관심 변수가 High Cardinality인 경우
연산량이 방대해져서 연산 Cost가 높아진다.
2. 변수 간 상관성이 클 경우
PDP는 각 변수들이 서로 상관관계가 없다고 가정한다. 관심 대상인 변수들과 관심 대상이 아닌 변수들 간 상관관계가 없다고 가정하여, 관심 대상인 변수와 Target간의 순수한 관계를 보겠다는 것이기 때문에 상관관계가 강하다면 매우 비현실적인, 분포적으로 등장할 확률이 거의 없는
(Like 2m에 몸무게 15kg의 사람)샘플 경우들이 생성되어, 전체 예측값 평균 계산에 영향을 끼칠 수 있다.
3. 샘플 간 성질이 매우 다를 경우
이는 PDP뿐만 아니라 Global Method들의 한계라고 할 수 있다. 샘플들의 성질이 매우 다를 경우에는 PDP는 좋은 참고자료가 못된다. 예측값들을 평균낸 값들로 영향을 보는 것이라, 샘플들의 서로 다른 성질들이 반영되지 못한다. 예를 들어, 절반은 예측값이 100이고, 절반은 예측값이 -100일 때, 평균은 0이 된다.
2. SHAP
SHAP에 대해서 알아보기 전에 Shaplye Value를 먼저 알아야하고, Shapley Value를 설명하기 전에 게임이론에 대해서 알고 있어야 한다. 게임이론이란 상호 의존적인 의사 결정에 관한 내용을 다루는 이론이다. 여기서 말하는 게임은 컴퓨터게임이라기 보다는 앞서 말한 상호 의존적인 의사 결정 행위를 의미한다. 그리고 상호 의존적인 의사 결정은 참가자들이 서로 상호 관계가 있는 상황에서, 아니면 각 참가자들이 선택하는 선택지에 따라 다른 참가자들이 얻은 보상이 달라질 때 이루어지는 의사결정을 의미한다.
짧게 요약하자면 사람들이 합리적으로 판단할 때 어떻게 행동하는지, 그럴 때 상대방들은 어떻게 판단하고 행동하는지를 연구하는 이론이다.
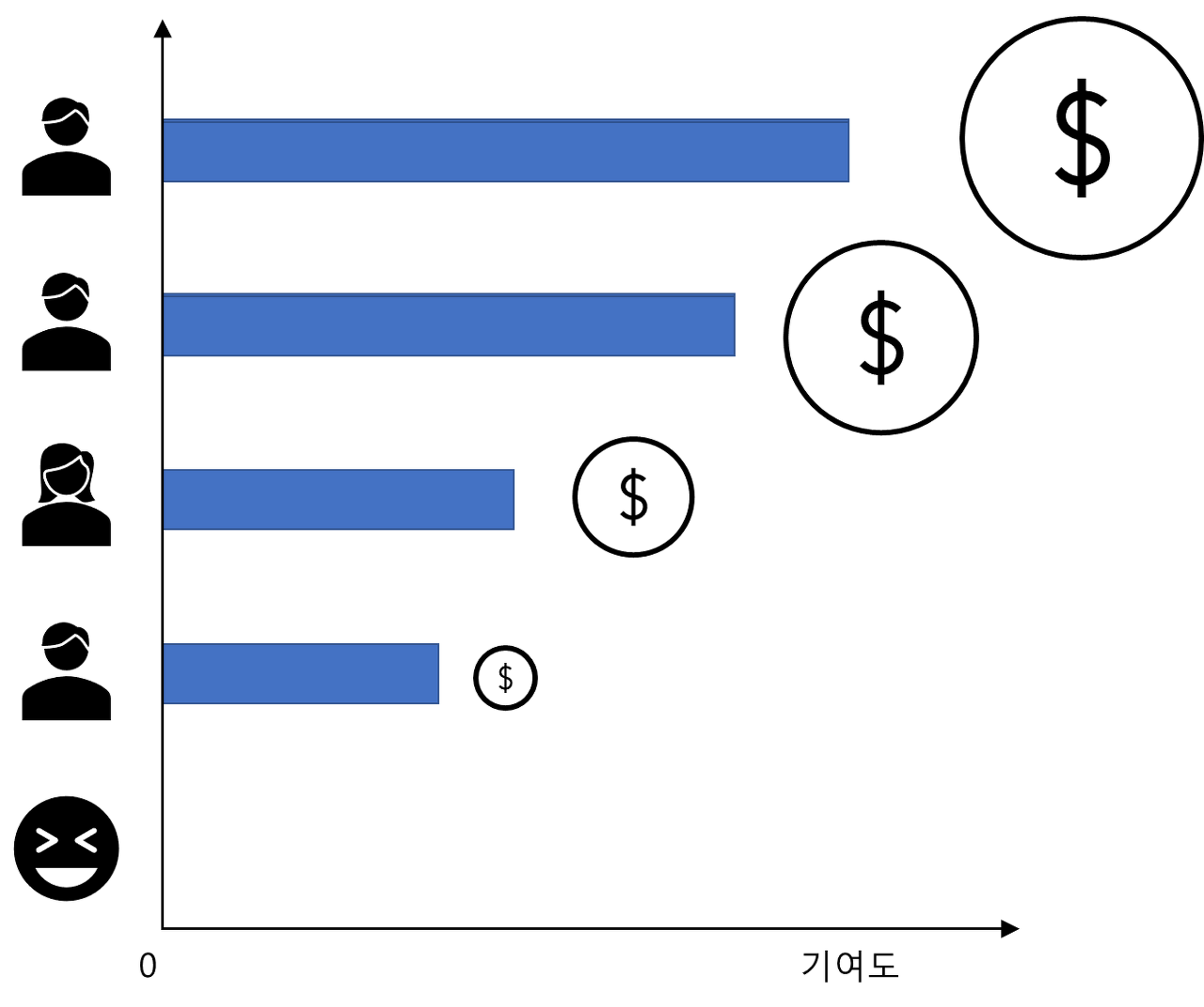
Shapley Value는 공정 분배 게임이론에서 나온 개념으로 주어진 게임에 참여한 플레이어들에게 기여도에 따라서 보상을 공정하게 배분하기 위한 하나의 방법론이다. 쉽게 말하면 게임에 얼만큼 기여했느냐를 계산하는 방법이다. 게임이론에서 말하는 공정 분배의 성질은 다음과 같다.
💡 공정분배 In 게임이론
1. 효율성(Efficiency)
보상은 해당 게임에 참여한 플레이어에게 남김없이 나눠줘야 한다.
2. 위장 플레이어(Dummy Player)
팀 플레이어에서 아무런 기여도 하지 않은 사람은 사람은 사실상 게임에 참여하지 않은 것이고, 따라서 상금을 주지 않는 것이 공정하다고 할 수 있다. 그런데 여기서 문제가 발생한다.
플레이어가 쓸모 있는지 없는지를 어떻게 측정하는가?이다. 여기서 기여도라는 개념이 등장한다. 플레이어의 기여도는 해당 플레이어의 플레이가 있고 없고에 따라서 생산해낼 수 있는 가치가 많이 달라지냐 아니냐로 정의 가능하다. 이런 방식으로 기여도를 계산하여 기여도가 0인 플레이어(위장 플레이어)에게 줄 상금이 없다는 것이다.
3. 대칭성(Symmetry)
두플레이어가 만들어내는 가치(기여도)가 동일하다면 보상 역시 동일해야 한다.
4. 강한 단조성(Strong Monotonicity)
더 많은 가치를 만들어낸 플레이어가 있다면 더 많은 보상을 받아야 한다.
5. 가산성(Additivity)
어떤 플레이어가 두 게임에 기여하여 얻은 총상금은 각 게임에서 기여함으로써 얻은 상금의 합과 일치해야 한다.

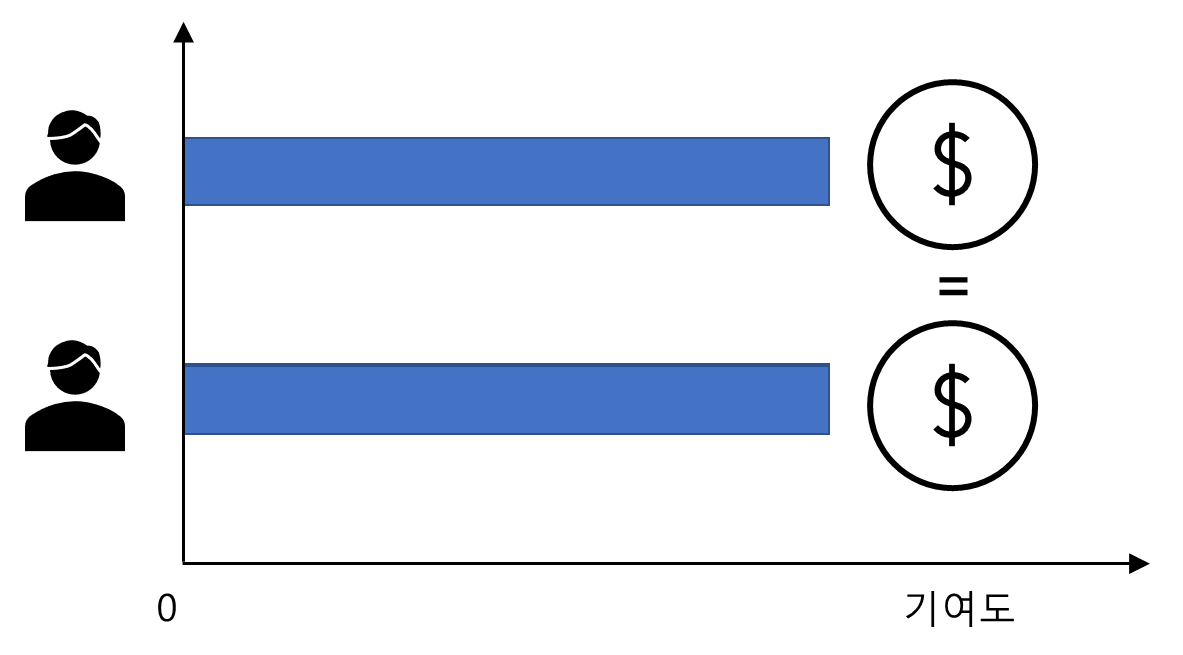
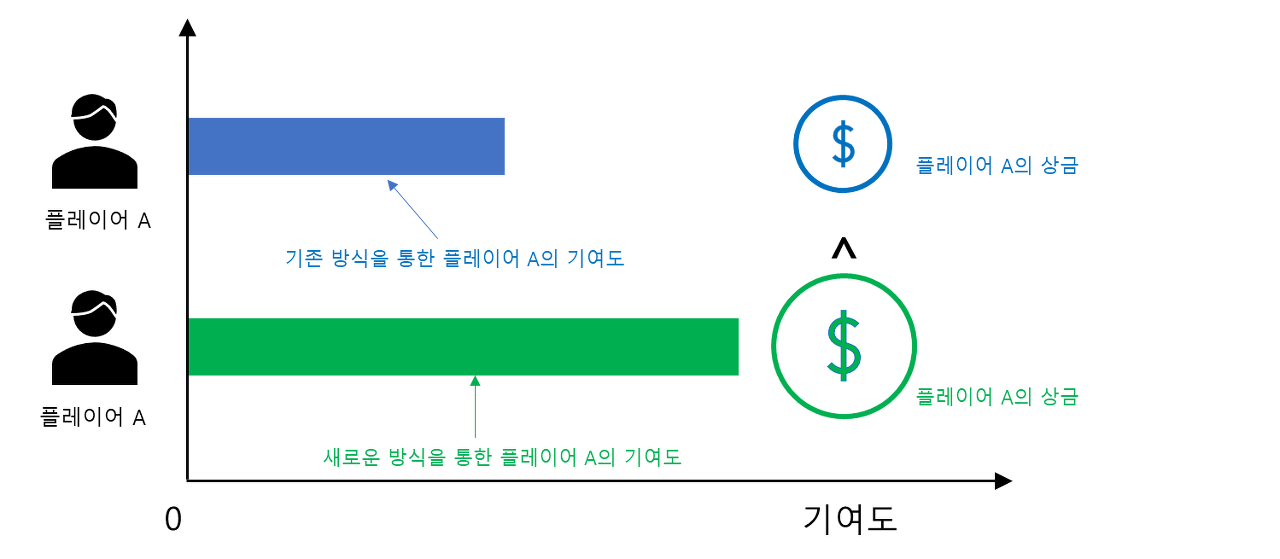
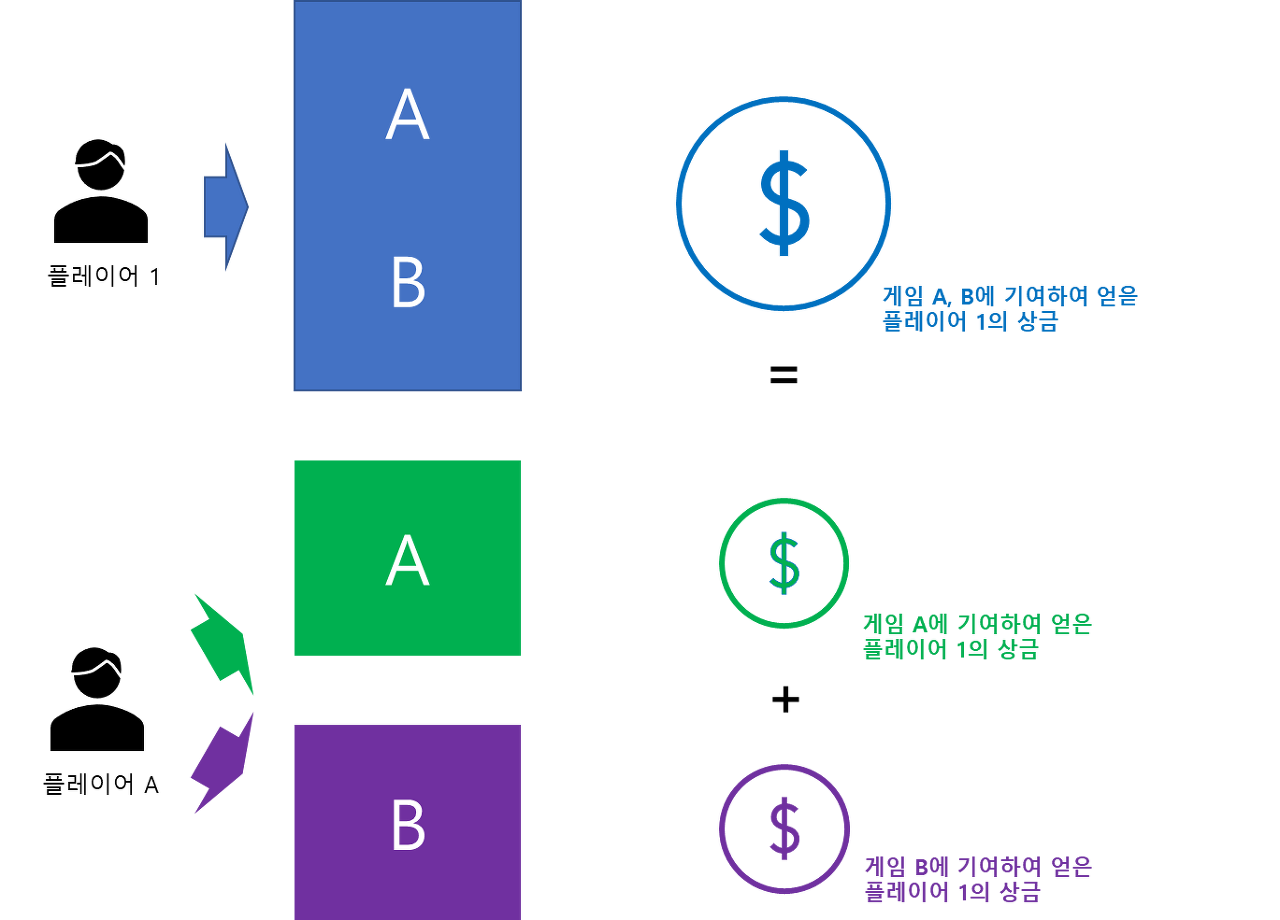
먼저 을 이 가질 수 있는 임의의 순열이라고 하자. 은 플레이어의 집합이다. 그리고 을 주어진 순열 R에 대하여 i 앞에 있는 원소들의 집합이라고 하자. 이때 i에 대한 Shapley Value의 수학적 정의는 다음과 같다.
여기서 이다. 그리고 의 안쪽 부분은 의 기여도를 나타낸다. 이 Shapley Value는 앞서 설명한 공정한 분배 성질을 모두 만족한다.
드디어 본론이다.
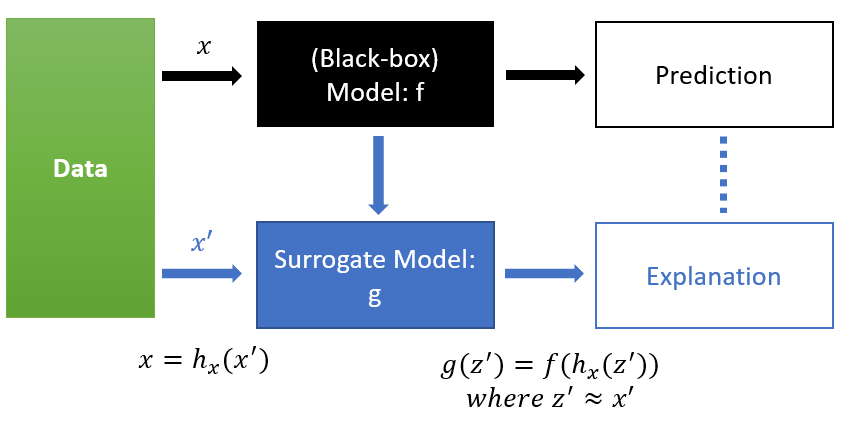
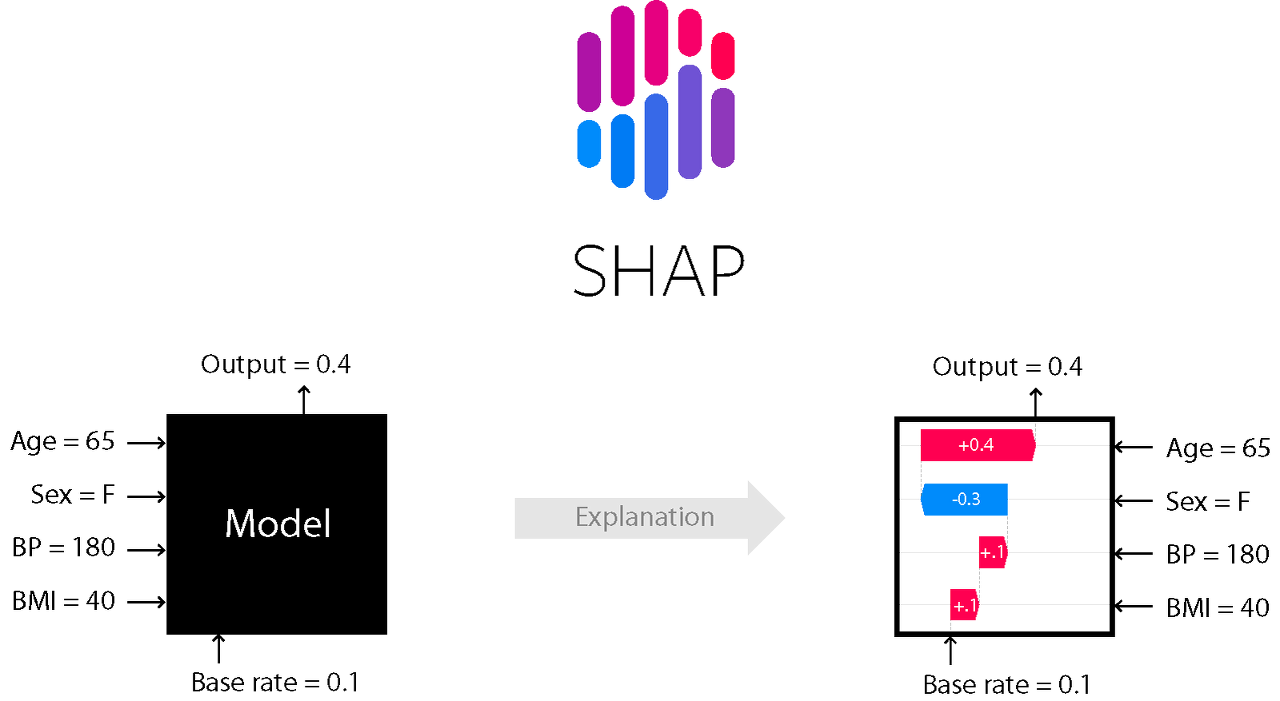
SHAP는 SHapley Additive exPlanation의 준말로 글로벌한 변수 중요도뿐만 아니라 개별 예측값에 대한 각 변수들의 영향력을 머신러닝 모델에 상관없이(Model-Agnostic) Additive하게 배분하는 방식이다. 이때 영향력을 측정하는 값으로 앞에서 열심히! 설명한 Shapley Value를 사용한다. (Shapley Value를 이용하여 SHAP value계산)
또한 변수 중요도로써 가져야 할 바람직한 성질을 갖고 있어 인간이 생각하는 것과 유사한 해석을 제공한다.
위의 사진은 SHAP의 전체과정을 나타낸다. 원래 Black Box모델을 바탕으로 한 예측이 있을 때, 단순화한 버전의 Input값을 넣어서 를 만족하는 g모델을 찾아서 모델의 예측을 설명는 것이다. 단순화된 변수를 사용하는 이유는 개별 예측값에 대한 변수들의 총영향력을 변수들의 결측 유무로 표현하여 단순하고 직관적인 해석 모형을 제공하기 위함이다.
기본적으로 SHAP는 Local Explanation(각 관측치에 대한 설명)을 기반으로 하여, 데이터의 전체적인 영역에 대한 해석이 가능하다.
❗ 변수 중요도로써 가져야 할 바람직한 성질?
1. Local Accuracy
효율성과 비슷한 개념이다.
2. Missingness
특정 변수가 결측되었다면 해당 변수 영향력은 없다는 것이다. 위장 플레이어와 같은 해석을 할 수 있다. (단, Tree SHAP은 Missingness를 만족하지 않는다.)
3. Consistency
Shapley Value의 강한 단조성과 정확히 일치한다.
💡 SHAP의 종류
1. Linear SHAP
2. Exact SHAP
3. Kernel SHAP
4. Tree SHAP
👍 SHAP의 장점
1. SHAP Value는 합리적인 성직 덕분에 개별 예측값에 대한 각 변수의 중요도를 상식적으로 제공한다.
2. Model Agnostic한 방법이다.
3. 특정 모형 클래스에 대해서는 계산이 빠르다.
4. 개별 예측값에 대한 변수 중요도뿐만 아니라 예측에 대한 전반적인 변수 중요도도 계산할 수 있다.
👎 SHAP의 단점
1. Kernel SHAP는 계산이 느리다.
2. Tree SHAP는 Missingness를 만족하지 않아서 때때로 해석이 직관적이지 않다.
복습할 때 상세한 수식은 아래의 블로그 참고하자...못적겠다.
2. 명령어
1. category_encoders: TargetEncoder
다양한 인코딩 방법 중 하나인 TargetEnCoding은 범주형 자료의 값들을 트레이닝 데이터에서 "Target"에 해당하는 변수로 바꿔주는 방식이다. 이 때 보통 같은 범주의 타겟값의 평균으로 반환한다.
타겟값의 평균을 사용하기 때문에 데이터 누수에 있어서 주의가 필요하며, 보통 High Cardinality를 가지는 범주형 특성에 대해서 주로 사용한다.
from category_encoders import TargetEncoder
encoder = TargetEncoder()
encoder.fit(X_train, y_train)
numeric_dataset = encoder.transform(X_train)❗ 공식문서
사이트 주소: https://contrib.scikit-learn.org/category_encoders/targetencoder.html
2. matplotlib.pyplot.rcParams
데이터 시각화를 위해 Matplotlib을 자주 사용한다. Matplotlib.pyplot으로 그래프를 그리면 다음과 같은 3단계를 거치게 된다.
- pyplot을 이용한 명령
- 객체들의 생성(Figure,Line,Axes)
- 그리기
그래프를 그리기 위한 모든 것을 담고 있는 것이 matplotlib이고, 호출을 위한 간단한 API를 제공하는 것이 matplotlib.pyplot이다. 그러므로 그래프를 그리는데 필요한 요소들은 matplotlib에서 다루면 된다. matplotlib은 그래프를 그리기 위해서 Runtime Configuration Parameters줄여서 rcParams라는 딕셔너리 값을 이용해서 그린다. 전체적인 구조는 아래와 같다.
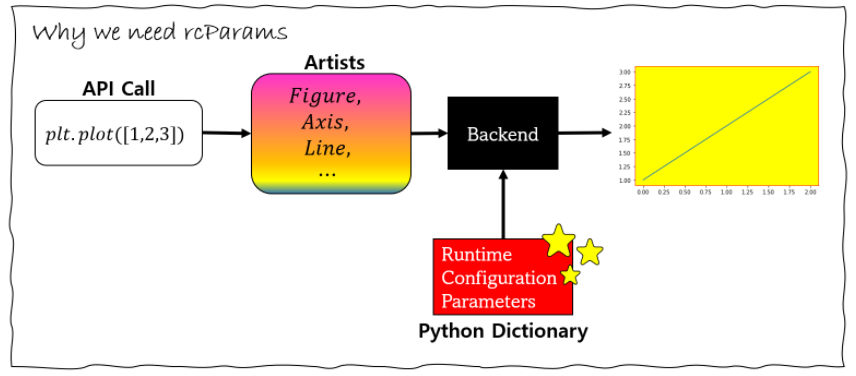
rcParams 딕셔너리의 값을 바꿔주면, Backend에서 그릴 때, 다른 방식으로 그리게 된다. 그래프의 폰트 사이즈, 크기, 바탕색 등 여러가지 성질들이 모두 matplotlib.rcParams딕셔너리에 담겨있다.
# 예시 - 그래프의 테두리와 면 색깔 변경
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['axes.edgecolor'] = "red"
matplotlib.rcParams['axes.facecolor'] = "yellow"
plt.plot([1,3,2])
❗ 공식문서
사이트 주소:https://matplotlib.org/stable/tutorials/introductory/customizing.html
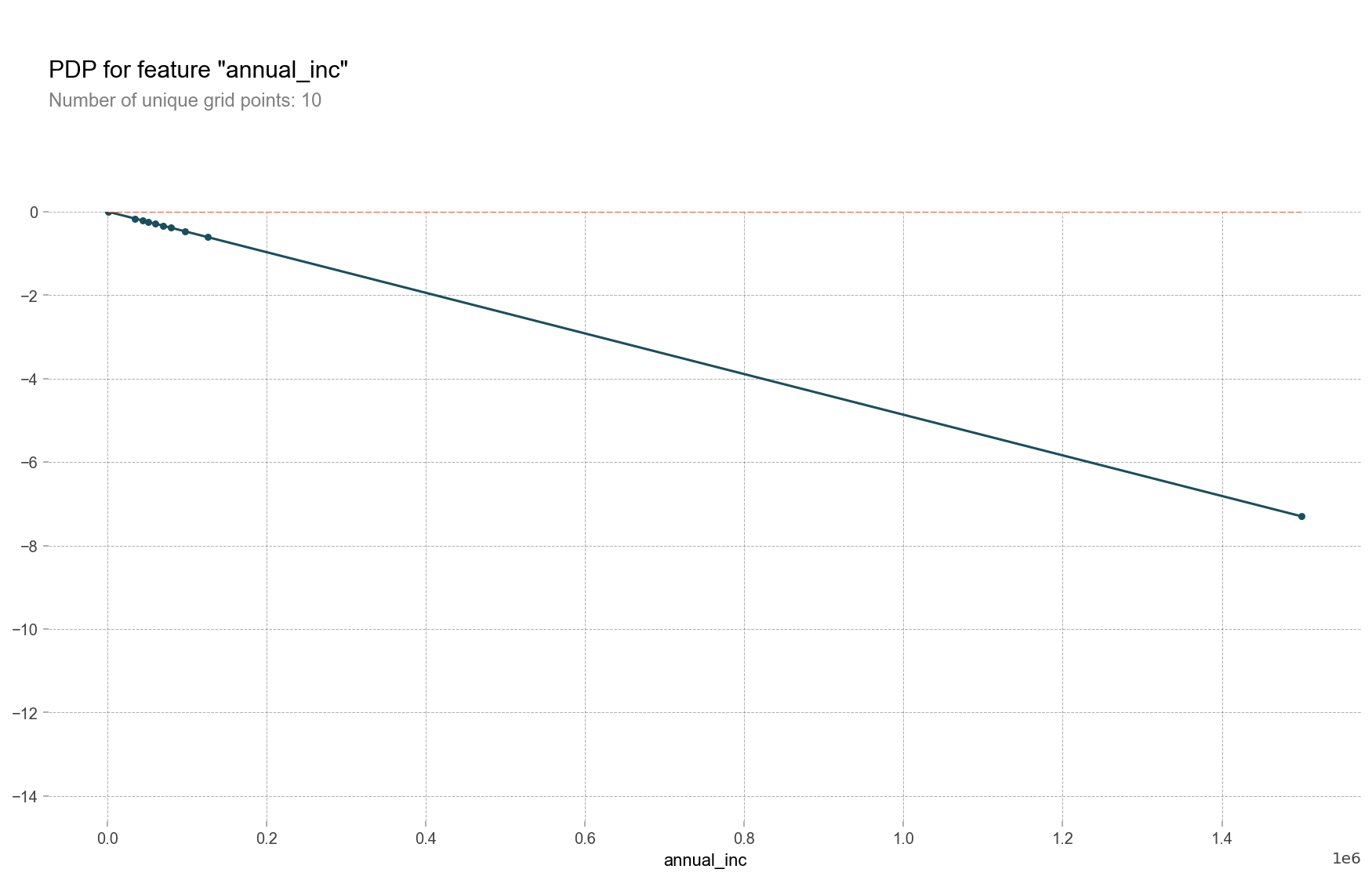
3. Library: pdpbox.pdp
pdpbox는 PDP 그리게 해주는 패키지이다.
3-1. pdp_isolate, pdp_plot
- pdp_isolate: 1개의 특성과 타겟에 대한 Partial denpendence function을 계산한다.
- pdp_plot: PDP를 출력하여 주는 함수이다.
from pdpbox.pdp import pdp_isolate
feature = 'annual_inc'
isolated = pdp_isolate(
model=linear,
dataset=X_val,
model_features=X_val.columns,
feature=feature,
grid_type='percentile', # default='percentile', or 'equal'
num_grid_points=10 # default=10
)
pdp_plot(isolated, feature_name=feature);<출력 결과>
3-2. pdp_interact, pdp_interact_plot
- pdp_interact: 2개의 특성과 타겟에 대한 PDP interact plot을 계산한다.
- pdp_interact_plot: 계산된 PDP interact를 출력하여 주는 명령어이다.
from pdpbox.pdp import pdp_interact
features = ['annual_inc', 'fico_range_high']
interaction = pdp_interact(
model=boosting,
dataset=X_val_encoded,
model_features=X_val.columns,
features=features
)
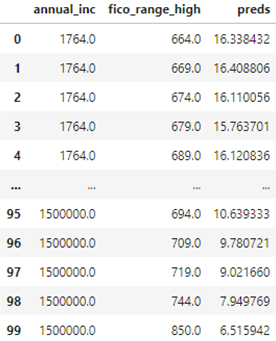
3-4. .pdp
계산된 주변 확률을 데이터 프레임 형식으로 반환하여 준다.
from pdpbox.pdp import pdp_interact
features = ['annual_inc', 'fico_range_high']
interaction = pdp_interact(
model=boosting,
dataset=X_val_encoded,
model_features=X_val.columns,
features=features
)
interaction.pdp<출력 결과>
4. pandas.pivot_table()
Pivot table이란 데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 말한다.
pivot_table은 pivot과 groupby명령의 중간 성격을 가지는 명령어이다. pivot_table은 groupby명령처럼 그룹분석을 하지만 최종적으로는 pivot명령처럼 Pivot table을 만든다. 즉 groupby명렁의 결과에 unstack을 자동 적용하여 2차원적인 형태로 변형한다.
만약 조건에 따른 데이터가 유일하게 선택되지 않으면 그룹연산을 하며, 이 때 aggfunc인수로 정의된 함수를 수행하여 대표값을 계산한다. 또한 pivot_table을 메서드로 사용할 때는 객체 자체가 데이터가 되므로 data인수가 필요하지 않다.
pdp = interaction.pdp.pivot_table(
values='preds', # interaction['preds']
columns=features[0],
index=features[1]
)[::-1]
pdp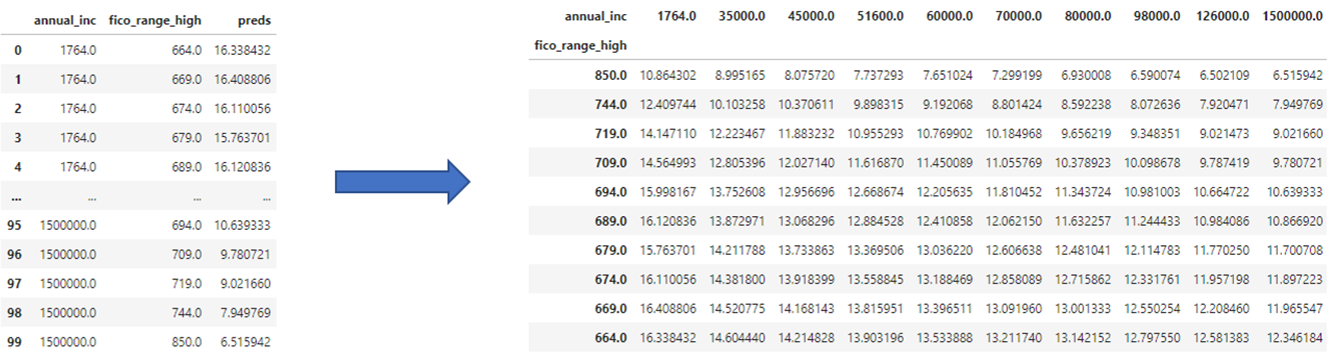
5. Plotly.graph_objs
5-1. .Surface
새로운 Surface객체를 생성한다.
import plotly.graph_objs as go
surface = go.Surface(
x=pdp.columns,
y=pdp.index,
z=pdp.values
)5-2. .Layout
새로운 layout객체를 생성한다. 축 이름, 그래프 이름 등 다양한 Layout을 설정할 수 있다.
import plotly.graph_objs as go
layout = go.Layout(
scene=dict(
xaxis=dict(title=features[0]),
yaxis=dict(title=features[1]),
zaxis=dict(title=target)
)
)5-3. .Figure
앞서 생성한 layout과 surface를 이용하여 그래프를 생성한다.
import plotly.graph_objs as go
surface = go.Surface(
x=pdp.columns,
y=pdp.index,
z=pdp.values
)
layout = go.Layout(
scene=dict(
xaxis=dict(title=features[0]),
yaxis=dict(title=features[1]),
zaxis=dict(title=target)
)
)
fig = go.Figure(surface, layout)6. Library: shap
6-1. .TreeExplainer
Tree SHAP알고리즘을 이용하여 앙상블 트리 모델의 출력을 설명하여 준다. Tree SHAP는 종속성에 대한 여러가지 가능한 가정 하에서 트리 모델 및 트리 앙상블에 대한 SHAP value를 추정하는 빠르고 정확한 방법이다.
import shap
model = RandomForestRegressor(random_state=2)
explainer = shap.TreeExplainer(model)❗ 공식문서
사이트 주소: https://shap-lrjball.readthedocs.io/en/latest/generated/shap.TreeExplainer.html
6-2. .TreeExplainer.expected_value
SHAP value의 기대값을 계산하여 준다. expected_value는 Random Forest를 모델로 사용할 때 사용되며, 보통 Target의 평균값으로 계산한다. 상세한 코드는 아래에서 함께 제시하도록 한다.
6-3. .shap_values
SHAP value를 계산하여 준다. 상세한 코드는 아래에서 함께 제시하도록 한다.
6-4. .initjs
.initjs는 그래프를 표시하기 위한 JAVAscript를 초기화하는 역할을 수행한다. 보통 SHAP그래프는 Js를 이용해서 출력하기 때문이다. 상세한 코드는 아래에서 함께 제시하도록 한다.
6-5. .force_plot
계산된 SHAP value를 시각화하여 준다.
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(row)
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value,
shap_values=shap_values,
features=row
)<출력 결과>

6-6. summary_plot
요약된 SHAP value그래프를 출력하여 준다. 이때 x축은 SHAP value를 나타내고, y축은 특성, 그리고 점의 색은 각 특성의 값의 크기를 나타낸다.
shap_values = explainer.shap_values(X_test.iloc[:300])
shap.summary_plot(shap_values, X_test.iloc[:300])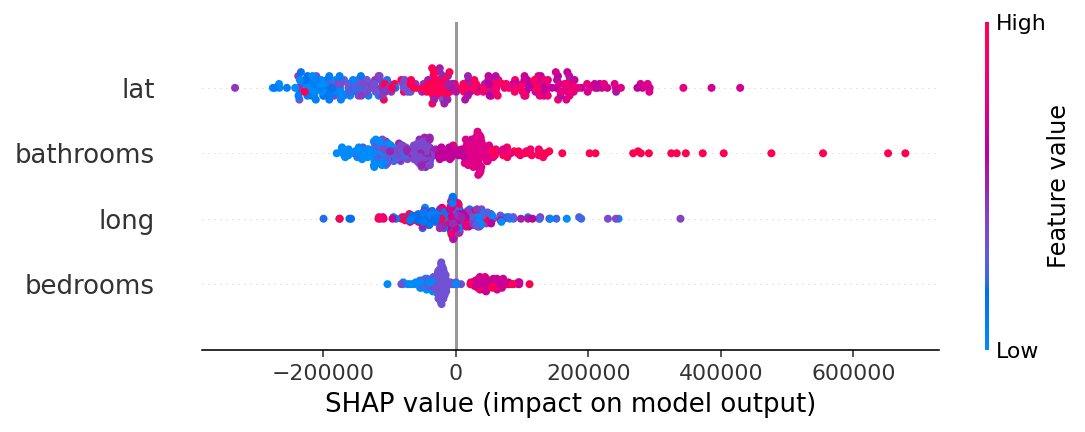
7. to_string()
to_string메서드는 데이터 객체를 단순 String형태로 변환하는 메서드이다.
data = [[1,np.NaN],['A',4.179],['<&>',32000]]
df = pd.DataFrame(data,columns=['col1','col2'])
df=df.rename_axis(columns='index')
print(df)
>>
index col1 col2
0 1 NaN
1 A 4.179
2 <&> 32000.000
print(df.to_string())
>>
index col1 col2
0 1 NaN
1 A 4.179
2 <&> 32000.000
print(type(df))
>>
<class 'pandas.core.frame.DataFrame'> # 기본 type
print(type(df.to_string()))
>>
<class 'str'> # str 객체로 type이 변경됨.3. 회고
응애
❗ 참고자료
1. Marginal Effect
2. Shapley Value 1
3. Shaplye Value 2
4. Matplotlib rcParams
