
TIL이라 적고 3일이나 지나서 쓰는게 양심에 찔리긴 하지만 그렇다고 시리즈 이름을 바꾸기엔 좀 많이 불편해서 그대로 작성한다.
0. 학습목표
- 특성 중요도를 계산하는 다양한 방법들을 이해하고 사용하여 모델을 해석하고 특성 선택시 활용할 수 있다.
- Gradient Boosting을 이해하고 XGBoost를 사용하여 모델을 만들 수 있다.
1. 주요개념
1. 특성중요도
💡 특성중요도에 대해 정리한 내 Velog: N221
특성중요도에 대해서는 이전 글에서 정리한 내용이 있다. 하지만 이는 MDI 방식의 특성중요도에 대해서 요약한 것이기 때문에, 이번에는 MDA기반의 순열중요도, Drop-Column Importance 방식을 통한 특성중요도를 계산하는 방식에 대해서 알아보겠다.
기본적으로 선형회귀에서는 회귀계수(표준화된)또는 결정계수의 변화량을 통해서 특성이 예측에 미치는 영향을 파악할 수 있지만, Tree 기반 모델에서는 특성중요도라는 개념을 통해서 특성이 예측에 미치는 영향을 파악할 수 있다.
단, 그렇다고 특성중요도 개념을 회귀모델에서 사용하지 못하는 것은 아니다. 실제로 Scikit-learn의 공식문서를 보면 회귀 모델에 대해서도 feature_importances_속성을 지원하고 있다.
1-1. Mean Decrease Impurity(MDI) Feature Importances
N221 내용을 그대로 가져왔다.
랜덤 포레스트 모델의 경우는 학습 후에 특성들의 중요도 정보를 기본으로 제공한다. 이때 이 중요도는 노드들의 불순도를 가지고 계산하는데, 노드가 중요할수록 불순도가 크게 감소한다는 사실을 이용한다. 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성의 중요도가 올라가게 된다.
이때 특성 중요도를 계산할 때 사용하는 방식이 Mean decrease impurity(MDI)라는 방식을 사용한다.
MDI는 각 변수가 Split 될 때 불순도 감소분의 평균을 중요도로 정의하는 것이다.
이 방식은 빠르고 직관적이라는 장점이 존재한다. 하지만 High-cardinality 범주형 변수에 대해서 Bias가 나타난다. 범주가 많은 특성은 트리가 나뉠 때 이용될 확률이 높고, 따라서 전체적인 일반화보단 범주가 많은 특성에 편향되어 과적합을 일으키기 쉽고, 정보획득이 높게 측정되는 오류를 발생시켜 잘못된 해석으로 귀결될 수 있다.
Sklearn은 feature_importances_ 속성에 대해서 이 MDI방식을 사용하지만 XGBoost 경우 MDI방식 외에도 Importance types하이퍼 파라미터를 Cover,Weight로 설정해서 다른 방식으로도 계산할 수 있다. defalut는 Gain으로 MDI방식이라고 생각하면 된다.
1-2. Drop-Column Importance
# Pseudo Code
df = 원래의 DataFrame
target = 예측변수
train, val = df를 학습데이터와 검증데이터로 분리
X_train = train.drop(columns=Target)
y_train = train[target]
X_val = val.drop(columns=Target)
y_val = val[target]
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier()
) # 머신러닝 모델생성 Pipeline
score_without =[]
for i in df_columns:
pipe.fit(X_train.drop(columns=i), y_train)
score_without.append(pipe.score(X_val.drop(columns=column), y_val))
score = pipe.score(X_val,y_val)
Drop_column_Importance = score - score_without
# 각 특성의 중요도가 산출된다.이름에서도 알 수 있듯이 Column 하나 하나를 "Drop"해가면서 평가지표(대체로 Accuracy)가 얼만큼 변하는지를 이용하여 특성의 중요도를 측정하는 방법이다. 가장 직관적이고, 이론적으로 가장 좋아 보이는 방법이다.
하지만 매번 각 Column을 drop하기 때문에 특성의 수가 줄어들어 차원이 달라지기 때문에 매번 모델을 다시 학습시켜야 한다. 만약 특성이 n개가 있다면 n+1번 학습을 진행해야 하는 것이다. 이에 따라서 특성의 수가 많다면 시간이 오래걸린다는 단점이 존재한다.
1-3. Permutation Importance(Mean Derease Accuracy,MDA)
앞서 설명한 Drop-Column Importance는 특성을 제거하기 때문에 매번 학습을 다시 진행해야하고, 이로 인해서 시간이 많이 소요된다고 했다. 그렇다면 "특성이 없는 것처럼 할 수 없을까?"라는 Idea에서 나온 것이 바로 Permutation Importance(순열중요도)이다.
각각의 특성을 무작위로 배열하여서 제 기능을 하지 못하게 만든 뒤에 결과를 비교하여 각 특성의 중요도를 계산하는 방식이다. 무작위로 배열하는 것을 "특성에 Noise를 준다" 또는 "Feature를 Noise로 만든다"라고 한다. 특성을 무작위로 배열할 뿐이지 특성의 차원이 변하는 것은 아니기 때문에 모델을 재학습할 필요가 없어서 Drop-column방식보다 시간이 절약된다는 장점이 존재한다.
또한, MDI방식의 Feature Importance는 사실 해당 피쳐가 예측결과에 있어서 긍정적인 영향을 주는지 부정적인 영향을 주는지 판단할 수 없다. 즉, 특성공학 관점에서 별 의미가 없는 것이다. 하지만 순열중요도는 긍정적인 영향을 주는지, 부정적인 영향을 주는지 계산할 수 있다.
하지만 무작위로 섞는다는 점으로 인해서, 실행할 때마다 결과가 달라질 수 있다. 물론 이점은 섞는 횟루를 늘림으로써 예측 에러의 분산을 감소시킬 수 있지만, Feature의 수가 많다면 이에 따라서 연산량이 증가할 것이다. 따라서 적절한 횟수를 설정하여 분석을 진행하여야 한다.
또한 무작위로 섞다보면 비현실적인 데이터 인스턴스(Instance)를 생성할 가능성이 높아진다. 특히, 변수들 간 상관관계가 높다면 이러한 문제점이 발생하기 쉽다. 대표적인 예로 키와 몸무게를 들 수 있다. 이 두변수들은 상식정으로 상당한 연관이 있다. 그런데 키와 몸무게를 랜덤으로 섞다보면 키 2m에 몸무게는 30kg인 비현실적인 인스턴스가 만들어지는 경우도 나올 것이다. 이는 현실에서 존재한다고 보기 어렵다. 이런 비현실적인 데이터 인스턴스가 많이 만들어지면 예측값에 지대한 영향을 미칠 가능성이 있고, 이렇게 해서 중요도가 높게 나온다 해도 원하던 특성중요도는 아닐 것이다. 따라서, 미리 변수들 간 상관관계를 파악하는 것이 중요하다.
변수들 간 상관관계를 파악하는 방식 중 하나는 Clustering을 통해서 연관이 있는 것들끼리 묶어서 각 집단에서 하나의 특성만 선택하는 방식이 있다고 한다.
💡 데이터 인스턴스?
머신러닝에 있어서 Instance는 예측하려는 대상물(Object)를 의미한다. 즉 다양한 특성들에 대해서 조사한 관측치라고 생각하면 편할 것 같다. 위 글에서 비현실적인 데이터 인스턴스란 말을 쉽게 풀어쓰면 현실에서 볼 수 없는 관측대상이 나온다는 것이다. 키가 2m에 몸무게는 30kg인...
2. Boosting 기법
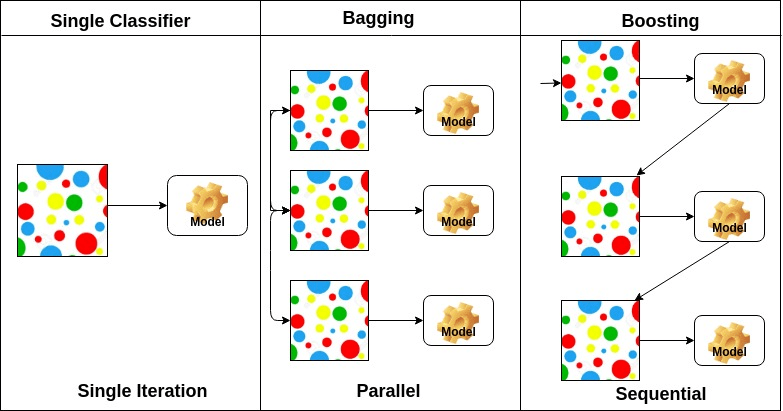
Boosting은 모델들을 앙상블 형태로 만드는 일반적인 기법이다. 이는 Bagging(N222참조)과 비슷한 시기에 개발되었다. 배깅과 마찬가지로 Boosting 역시 결정 트리에 가장 많이 사용된다. 비슷한 면도 있지만, 부스팅은 훨씬 많은 부가 기능을 가진 전혀 다른 방법이다. 배깅은 상대적으로 튜닝이 거의 필요 없지만 부스팅은 적용하고자 하는 문제에 따라서 주의가 필요하다.
선형회귀모형에서 피팅이 더 개선될 수 있는지 알아보기 위해 잔차를 종종 사용했다. 부스팅은 이러한 개념을 더 발전시켜서, 이전 모델이 갖는 오차를 줄이는 방향으로 다음 모델을 연속적으로 생성한다. 잘못 분류된 관측 데이터에 가중치를 증가시킴으로써, 현재 성능이 제일 떨어지는 데이터에 대해 더 집중해서 학습하도록 하는 것이다.
AdaBoost, Gradient Boosting, Stochastic Gradient Boosting(확률적 그레디언트 부스팅)은 가장 자주 사용되는 변형된 행태의 부스팅 알고리즘이다. 이 중에서도 확률적 그레디언트 부스팅이 일반적으로 가정 널리 사용된다. 실제로 파라미터만 올바르게 잘 선택한다면 이 알고리즘은 랜덤 포레스트를 그대로 emulation할 수 있다.
💡 Emulation: 하나의 시스템이 다른 시스템을 흉내내도록 하는 것이다.
그레디언트 부스팅은 에이다부스팅과 거의 비슷하지만, 비용함수를 최적화하는 접근법을 사용했다는 점에서 차이가 있다. 그레디언트 부스팅에서는 가중치를 조정하는 대신에 모델이 유사잔차를 학습하도록 한다. 이는 잔차가 큰 데이터를 더 집중적으로 학습하는 효과를 가져온다. 확률적 그레디언트 부스팅에서는 랜덤 포레스트에서와 유사하게, 매 단계마다 데이터와 예측변수를 샘플링하는 식으로 그레디언트 부스팅에 랜덤한 요소를 추가한다.
2-1. Boosting과 Bagging
배깅은 기본 모델이 서로 독립적으로 만들어지고 모든 모델의 결과를 종합하는 방법인 반면, 부스팅은 이전 모델의 결과가 다음 모델에 영향을 주면서 순차적으로 모델을 개선하여 결과를 도출하는 방법이다.
기본적으로 줄이고자 하는 오차의 방향도 다르다. 배깅의 경우는 과적합(low Bias, High Variance)이 된 기본 모델을 합치는 과정에서 에러가 상쇄되어 분산을 줄이는 방향으로 학습한다.
반면, 부스팅은 이전 기본 모델(weak learner: High Bias, low variance)의 오류를 계속 고쳐나가면서 학습 세트에 더 적합한 모델을 만들어나가기 때문에 편향을 줄이는 방향으로 학습한다.
2-2. AdaBoost
간단한 Weak learner들이 상호보완 하도록 다량 구축 및 조합하여 가중치 수정을 통해 좀 더 나은 성능을 발휘하는 하나의 강한 분류기(Strong Classifier)를 합성하는 방법의 알고리즘이다. Adaboost 모형은 약한 분류기의 실수를 통해 가중치를 반복적으로 수정하고 결합하여 정확도를 높일 수 있으며 학습 데이터에 과적합현상이 적게 발생하여 예측 성능을 저하하지 않는 장점이 있다.
💡 AdaBoost의 알고리즘
1. 먼저 피팅할 모델의 개수 을 설정한다. 그리고 반복 횟수를 의미하는 로 초기화한다. 관측 가중치 으로 초기화한다(. 앙상블 모델을 으로 초기화한다.
2. 관측 가중치 을 이용해 모델 을 학습한다. 이때 잘못 분류된 관측치에 대해 가중치를 적용한 합을 의미하는 가중 오차 이 최소화되도록 학습한다.
3. 앙상블 모델에 다음 모델을 추가한다. 여기서 이다.
4. 잘못 분류된 입력 데이터에 대한 가중치를 증가하는 방향으로 가중치 을 업데이트한다. 이 클수록 가중치가 더 커진다.
5. 모델 반복 횟수를 을 증가시키고 이면 다시 2단계로 돌아간다.
위의 알고리즘 보다는 StaQuest의 설명이 더 쉬운 것 같다. 다만 좀 길다...아래 영상과 영상을 정리해둔 블로그 링크를 남겨두니까 복습할 때 참조하자.
대충 설명하자면 트리 기반 모델에서 노드 하나에 두 개의 Leaf를 지닌 트리를 Stump라고 하는데, AdaBoost는 여러 개의 Stump로 구성되어 있다. 이를 Forest of Stumps라고 한다.
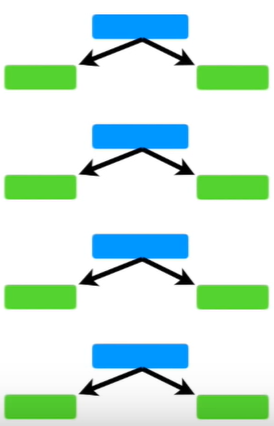
트리와 다르게 Stump는 정확한 분류를 하지 못한다. 여러 질문을 통해 데이터를 분류하는 트리와 다르게, Stump는 단 하나의 질문으로 데이터를 분류해야하기 때문이다. 따라서 Stump는 Weak learner이다.
AdaBoost에서는 특정 Stump가 다른 Stump보다 더 중요하다. 또한, 첫번째 Stump에서 발생한 Erro는 두번째 Stump의 결과에 영향을 준다. 이런 방식으로 마지막 Stump까지 줄줄이 영향을 준다. 더 상세한 설명은 정말 아래 블로그 참고하자...
💡 AdaBoost관련 링크
1. StaQuest
2. StaQuest 정리블로그
2-3. Gradient Boost
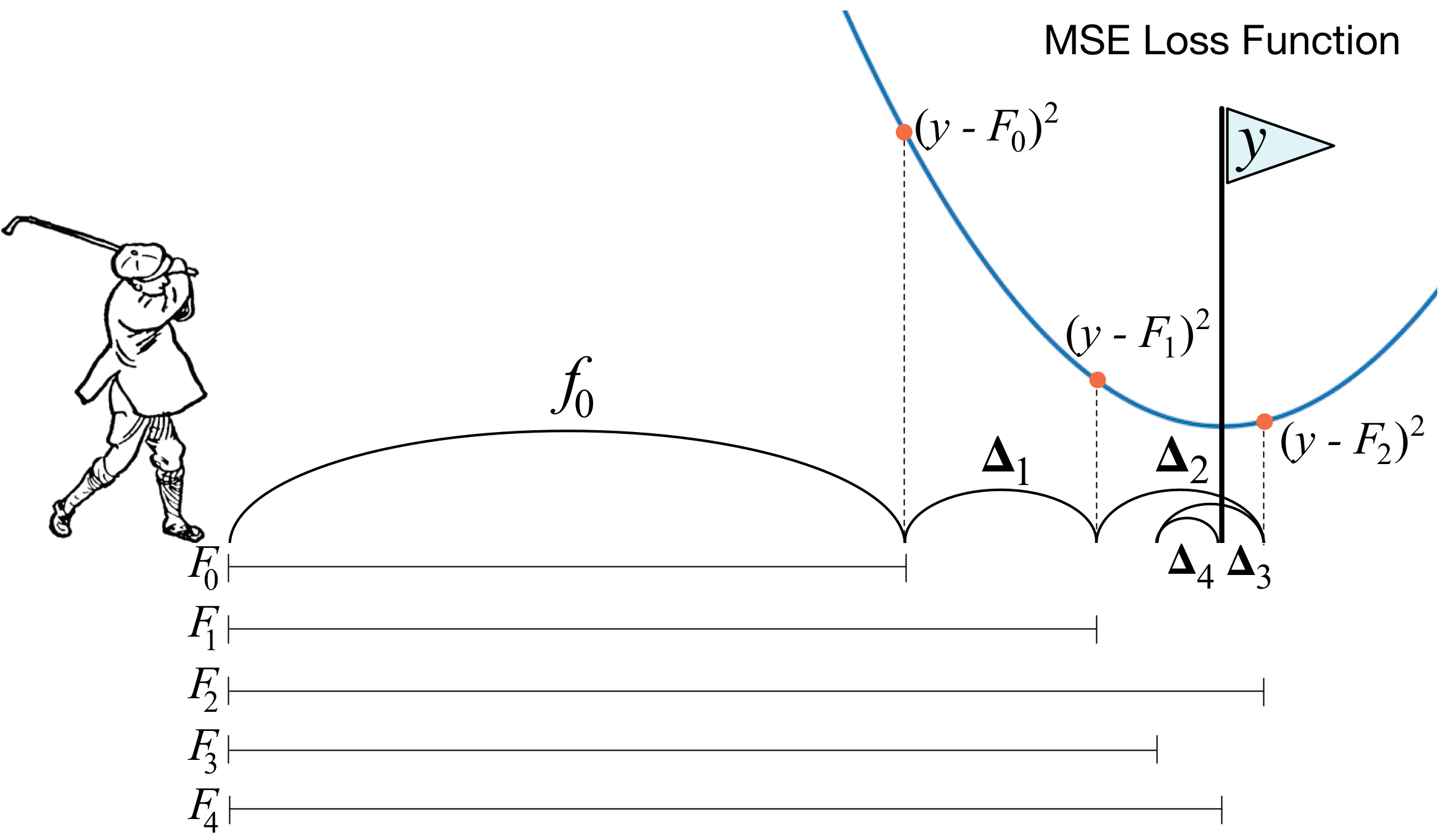
Gradient Boost는 AdaBoost와 유사하나, 가중치 업데이트를 경사 하강법을 이용하는 것이 큰 차이이다. 오류 값은 이다. 분류의 실제 결괏값을 , 피처를 , 그리고 피처에 기반한 예측 함수를 함수라고 하면 오류식 이 된다. 이 오류식 를 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것이 경사 하강법이다. (아마 이것도 앞에서 다뤘는데 어딘지...)
Gradient Boost Algorithm은 회귀분석 또는 분류 분석을 수행 할 수 있는 예측모형이다. Tabular format데이터 에 대한 예측에서 엄청난 성능을 보여주고, 머신러닝 알고리즘 중에서도 예측 성능이 높다고 알려진 알고리즘이다.
Gradient Boosting Model을 이해하는 가장 쉬운 방법은 Residual fitting으로 이해하는 것이다. 아주 간단한 모델 A를 통해 y를 예측하고 남은 잔차(Residual)을 다시 B라는 모델을 통해 예측하고 A+B 모델을 통해 y를 예측한다면 A 보다 나은 B 모델을 만들 수 있게 된다. 이러한 방법을 계속하면 잔차는 계속해서 줄어들게 되고, Training Set을 잘 설명하는 예측 모형을 만들 수 있게 된다. 하지만 이러한 방식은 Bias를 상당히 감소시키기 때문에 과적합이 발생할 확률이 높다는 단점이 있다. 따라서 실제로 Gradient Boost을 사용할 때는 Sampling, Penalizing 등의 Regularization테크닉을 이용하여 더 Advanced된 모델을 이용하는 것이 보편적이다.
2-4. XGBoost
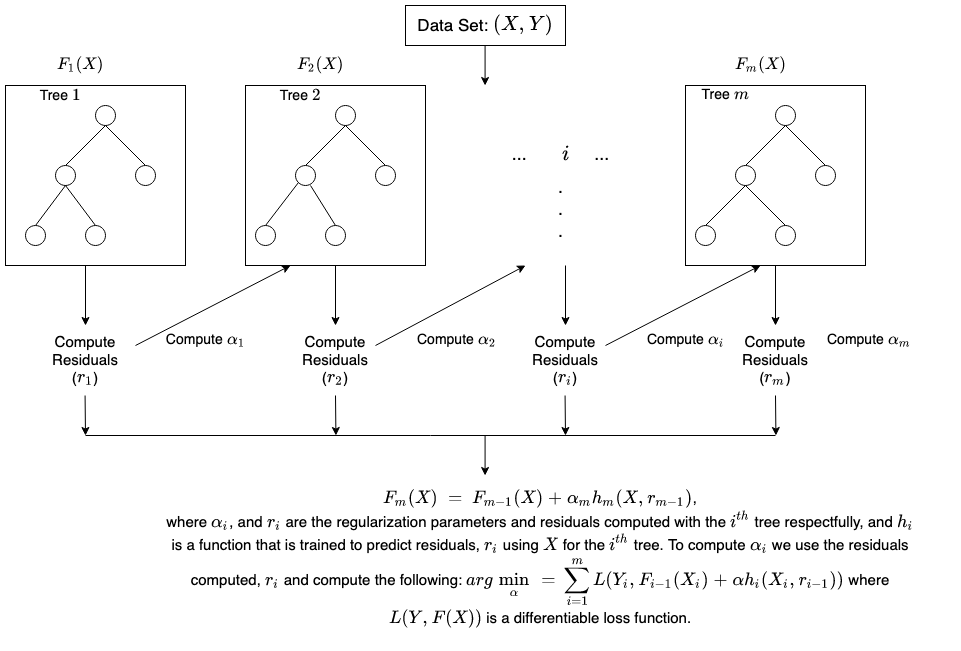
XGBoost는 eXtra Gradient Boost의 약자로 Gradient Boost기반의 모델이다. 유명한 케글 경연 대회에서 상위를 차지한 많은 데이터 과학자가 XGBoost를 이용하면서 널리 알려졌다. 압도적인 수치의 차이는 아니지만, 분류에 있어서 일반적으로 다른 머신러닝보다 뛰어난 예측 성능을 나타낸다. Gradient Boosting의 단점인 느린 수행 시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결(학습율을 이용)해서 매우 각광을 받고 있다. 특히 XGBoost는 병렬 CPU환경에서 병렬 학습이 가능해 기존 GBM보다 빠르게 학습을 완료할 수 있다.
💡 XGBoost 주요 장점
1. 뛰어난 예측 성능
2. GBM대비 빠른 수행 시간
3. 과적합 규제(Regularization)
4. Tree pruning(나무 가지치기)
일반적으로 GBM은 분할 시 부정 손실이 발생하면 분할을 더 이상 수행하지 않지만, 이러한 방식도 자칫 지나치게 많은 분할을 발생할 수 있다. 다른 GBM과 마찬가지로 XGBoost도 max_depth파라미터로 분할 깊이를 조정하기도 하지만,Tree Pruning으로 더 이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄이는 추가적인 장점을 가지고 있다.
5. 자체 내장된 교차검증
6. 결손값 자체 처리
3. Model-Agnostic Methods
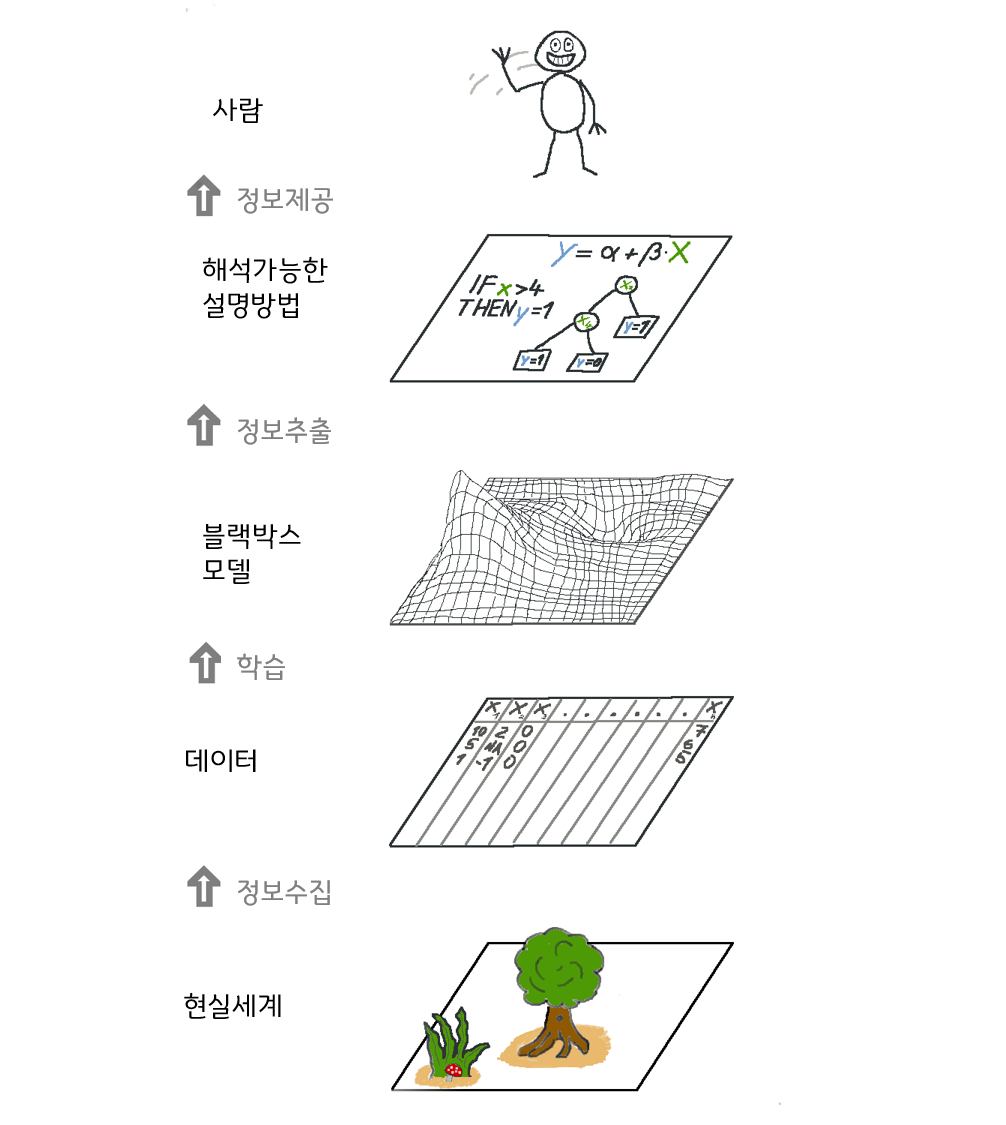
Model-Agnostic하다는 것은 학습에 사용된 Model이 무엇인지에 구애받지 않고 독립적으로 모델을 해석할 수 있다는 의미이다.모델 불특정 해석 방법이라고도 한다. 즉, 학습에 사용되는 모델과 설명에 사용되는 모델을 분리하겠다는 것이다. 학습 모델과 설명 모델을 분리하는 것의 가장 큰 장점은 자율성이다. 분석가들은 기존에 자신들이 사용하던 모델들을 그대로 사용할 수 있으며, 어떤 모델을 사용했더라도 동일한 방식으로 해석할 수 있다. 특히 비슷한 성능을 가지는 여러 모델 중 하나를 선택해야하는 상황이 발생했을 때, 모델을 해석한 결과를 동일한 기준으로 비교하여 객관적으로 더 나은 모델을 택할 수 있게 한다.
Model-Agnostic한 방법 외에 기존에 많이 활용되던 방법은 크게 두 가지이다. 첫째로는 해석 가능한 모델(ex.선형회귀)를 활용하는 것이다. 하지만 이러한 방법들은 보통 예측력이 매우 낮으며, 이는 결국 이 해석에 대한 신뢰성의 문제로까지 이어진다. 두번째로는 Model-Specific한 해석방법(Random Forest의 특성중요도)을 활용하는 것이다. 하지만 이는 같은 모델끼리는 비교가 가능할지 몰라도 서로 다른 모델과의 비교가 힘들어진다는 단점이 있다.
모델에 구속받지 않는 해석 방법은 크게 세 가지 지향점을 가지고 있다.
💡 지향점 세 가지
1. Model Flexibility
해석 방식이 해석하고자 하는 모델의 종류에 상관없이 동일하게 동작해야 한다.
2. Explanation Flexibility
해석의 형태가 자유로워야한다. 즉, 해석 결과를 다양한 방식으로 받을 수 있어야 한다. 즉 "모델 해석은 해줄게, 대신 Bar plot형태로만 볼 수 있고 넌 그냥 받기만 해"라고 말하는 모델은 쓰지 않겠다는 의미와 같다.
3. Representation Flexibility
Feature representation을 다르게 활용할 수 있어야 한다. 예를 들어, 단어 분류기를 뜯어보는 과정에서 해석의 결과가 추상적인 word Embedding Vector라면 해석이 힘들 것이므로, 이를 다시 인간이 이해할 수 있는 단어로 보여줄 수 있어야 한다.
2. 명령어
1. numpy.random.permutation()
입력된 리스트를 무작위로 섞어서 배열 순서가 다른 순열을 출력하는 함수이다. 대체로 순열중요도를 eil5 라이브러리를 사용하지 않고 계산할 때 사용한다.
np.random.permutation([1, 4, 9, 12, 15])
>>> array([15, 1, 9, 4, 12])💡 공식문서
사이트 주소: https://numpy.org/doc/stable/reference/random/generated/numpy.random.permutation.html
2. Library: eli5
eli5라이브러리는 머신러닝의 분류모델을 디버깅하고 모델의 예측값을 설명하는데 도움이되는 도구들을 모아둔 Python 패키지이다. Scikit-learn뿐만 아니라 Keras, XGBoost, LightGBM 등 다양한 머신러닝 프레임워크 및 패키지에 대해서 사용할 수 있다.
2-1. .sklearn
Scikit-learn라이브러리의 많은 estimators, transformers를 지원하게 해주는 패키지이다.
2-2. sklearn.PermutationImportance()
순열중요도를 계산하여주는 명령어이다. 다양한 파라미터 설정이 가능하며, 사용 방법은 아래의 예제 코드를 참고하고, 자세한 파라미터는 공식문서를 참조하자.
# 사용예제
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2
)
# permuter 계산은 preprocessing 된 X_val을 사용합니다.
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val_transformed, y_val);💡 공식문서
사이트 주소: https://eli5.readthedocs.io/en/latest/autodocs/sklearn.html?highlight=PermutationImportance#module-eli5.sklearn.permutation_importance
2-3. show_weights()
모델의 특성에 대한 순열중요도 결과값을 IPython.display.HTML객체로 반환한다. 이 함수를 사용하여 IPython에서 모델의 순열 중요도를 확인할 수 있다.
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로 넣어야 합니다
)<출력결과>
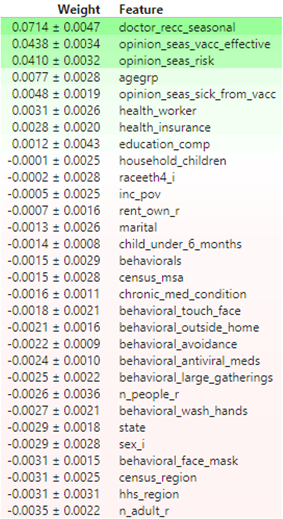
💡공식문서
사이트 주소:https://eli5.readthedocs.io/en/latest/autodocs/eli5.html?highlight=show_#eli5.show_weights
3. Libaray: warnings
파이썬에서 경고(Error message)를 제어할 수 있는 파이썬 내장 Class이다.
3-1. simplefilter()
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)파라미터에 지정된 방식으로 지정된 오류를 처리하여 준다.
사실 이 클래스와 라이브러리는 아직 잘 모르겠다. 단지 버전이 업데이트 되면 사라지는 명령어나 파라미터에 대해서 파이썬이 경고메세지를 출력하는데 이런 것을 출력하지 않기 위해서 사용하는 것만 봤다.
4. Libaray: Ipython.display
이에 대해서는 바로 이전 N232에서 설명했다. 참조하자.
4-1. HTML
이 객체가 표현식에 의해서 반환되거나 디스플레이 함수에 전달되면 화면(ex.colab)에 데이터가 표시된다.이걸 내가 자주 사용할까 의문이긴 하다.
데이터의 MIME유형은 사용된 하위 클래스와 일치해야 하기 때문에 'image/png'데이터에는 Png하위 클래스를 사용해야 한다. 데이터가 만일 URL인 경우에는 데이터가 먼저 다운로드 된 다음에 표시된다.
위의 그림에서처럼 사진 파일을 그대로 입력할 수도 있다.
MIME??
"Multipurpose Internet Mail Extensions의 약자로 간단하게 파일변환을 뜻한다고 할 수 있다.
MIME는 이메이로가 함께 동봉할 파일을 텍스트 문자로 전환해서 이메일 시스템을 통해서 전달하기 위해서 개발되었다고 한다. 그래서 그런지 이름에 Internet Mail Extension이라고 되어있다. 현재는 웹을 통해서 여러 형태의 파일을 전달하는데 사용되고 있다.
상세한 설명은 다음 블로그를 참고하자
블로그 주소:https://zzandoli.tistory.com/60
5. Library: xgboost
XGBoost모델을 사용할 수 있게 해주는 오픈소스 소프트웨어 라이브러리이다.
참고하면 좋은 사이트 주소를 밑에 참고자료에 적어두었으니 나중에 복습할 때 꼭 한 번 보자...
5-1. XGBClassifier()
XGBoost 분류를 위한 Scikit-leaarn API이다. 정말 많은 파라미터를 가지고 있으며, 이런 매개변수 조정을 통해서 좋은 성능을 가지는 모델을 만들어 낼 수 있다.
from xgboost import XGBClassifier
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median'),
XGBClassifier(n_estimators=200
, random_state=2
, n_jobs=-1
, max_depth=7
, learning_rate=0.2
)
)
pipe.fit(X_train, y_train);💡 공식문서
사이트 주소:https://xgboost.readthedocs.io/en/stable/python/python_api.html#xgboost.XGBClassifier
6. eval_set, eval_metric, early_stopping_rounds
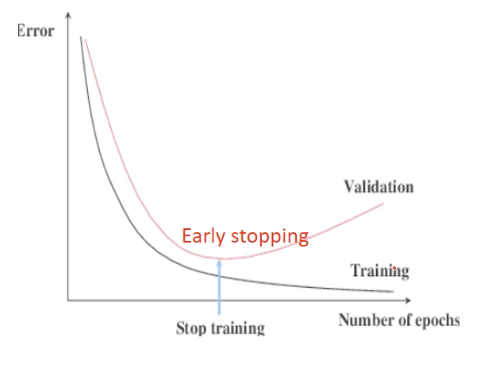
XGBoost에서 사용할 수 있는 파라미터들로 성능을 평가하여 모델의 학습을 중지시켜버릴 때 사용한다.
early_stopping_rounds: 더 이상 비용평가지표가 감소하지 않는 최대 반복횟수eval_set: 평가를 수행하는 별도의 검증 데이터 세트, 일반적으로 검증 데이터 세트에서 반복적으로 비용감소 성능을 평가한다.eval_metric: 반복 수행 시 사용하는 비용평가지표이다.
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric='error', # #(wrong cases)/#(all cases)
early_stopping_rounds=50
) # 50 rounds 동안 스코어의 개선이 없으면 멈춤3. 회고
양심상 회고는....
❗ 참고자료
1. 특성중요도 Velog
2. 순열중요도
3. GBM
4. 보면 좋을듯?
5. Model-Agnostic
6. XGBoost설명
