0. 학습목표
Level 1.
- 퍼셉트론(Perceptron)의 개념과 구조에 대해 설명할 수 있다.
- 신경망을 왜 다층으로 구성해야 하는 지와 신경망 각 층(입력층, 은닉층, 출력층)의 역할에 대해 설명할 수 있다.
- MINIST 예제 코드를 이해하고 재현할 수 있다.
Level 2.
- 가중치 행렬의 Shape과 신경망 구조에 대해서 이해하고 설명할 수 있다.
- 활성화 함수의 공통점과 신경망의 특징인 표현 학습에 대해 이해한다.
Level 3.
- 시그모이드 함수의 단점인 기울기 소실 문제와 ReLU함수를 쓰는 이유에 대해 이해할 수 있다.
- 파이썬 기본 코드로 퍼셉트론을 구현할 수 있다.
1. 퍼셉트론(Perceptron)과 인공신경망(Artificial Neural Networks)
인공신경망(Artificial Neural Networks)는 1943년 워렌 맥컬록(Warren McCulloch)이라는 신경생리학자가 처음 제시한 개념으로 기계를 학습시키는데 있어서 인간의 신경세포인 뉴런을 모방하는 수학적인 모델을 제시하였다.
이후 1958년 프랑크 로젠블랫(Frank Rosenblatt)은 이런 인공신경망의 최소 단위를 퍼셉트론(Perceptron)으로 정의하고 이들의 연결로 인지과정을 이해할 수 있을 것이라고 기대했다.
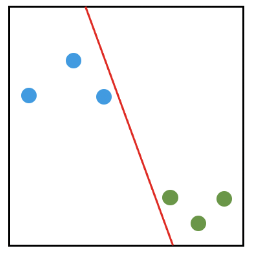
퍼셉트론은 이진 분류(binary Classification)모델을 학습하기 위한 지도학습(Supervised Learing)기반의 알고리즘이다. 수학적인 측면에서 2가지 클래스를 특정 기준 하에 구분하는 방법이다. 그리고 클래스를 구분하는 기준(아래 그림에서는 빨간선)을 Decision Boundary라고 부른다.
퍼셉트론은 뉴런이 다른 뉴런으로부터 신호를 입력받듯이 다수의 값 를 입력받고, 입력된 값마다 가중치()를 곱한다. 여기서 가중치는 생물학 뉴련에서 뉴런 간 시냅스를 통한 결합의 세기와 같은 역할이며 가중치가 클수록 입력값이 중요하다는 것을 의미한다.
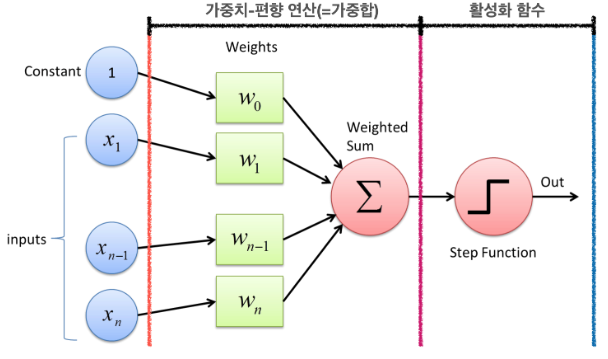
이때 위 그림을 살펴보면 입력값에 1과 가중치에 가 있는 것을 볼 수 있다. 이것을 편향(,b)이라고 한다. 이는 딥러닝 모델 최적화의 중요 변수 중 하나이다. 일반적으로 입력값을 1로 고정하고 편향 b를 곱한 변수로 표현한다. 입력값과 가중치의 곱, 편향은 퍼셉트론으로 전달된다. 퍼셉트론은 입력받은 값을 모두 합산하는데, 합산된 결괏값을 가중합이라고 부른다. 퍼셉트론은 이 가중합의 크기를 임계값과 비교하는 활성화 함수(Activation Function)을 거쳐 최종 출력값을 결정한다. 활성화 함수는 다시 말해서 계산된 가중합을 얼마 만큼의 신호로 출력할지 결정하는 출력과 관련이 있는 함수이다. 다양한 활성화 함수가 존재하며 이는 아래에서 다루도록 한다.
이러한 퍼셉트론이 처음 수행한 작업은 논리연산이다. 자동제어 시간에 들은 AND, OR, NAND Gate가 이런 논리연산의 예시로, 적절한 매개변수(가중치와 편향)를 선택하여 논리연산을 수행할 수 있다. 이러한 사실은 당시 과학자 들을 매우 흥분시켰다. 하지만 1969년 MIT 인공지능 연구소의 마빈 민스키(Marvin Minsky)와 페퍼트 세이모어(Papert Seymour)는 이런 퍼셉트론이 XOR Gate(배타적 논리합, 비선형 연산자)을 표현할 수 없다는 당시 퍼셉트론의 한계이자 맹점을 지적하였다.
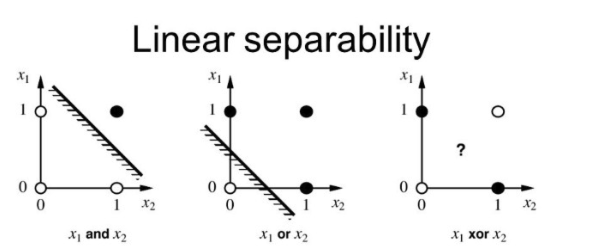
한 개의 퍼셉트론은 2차원 공간을 나누는 1차원 직선으로 해석할 수 있다. 입력이 2차원 이상인 n차원 초공간에서 퍼셉트론은 (n-1)차원 초평면에 해당한다. 이런 기하학적 해석에 따르면 위의 그림에서 보듯이 XOR은 퍼셉트론 한 개로 검은 점과 흰 점을 나눌 수 없음이 자명하다. 이런 퍼셉트론의 한계는 머신러닝의 첫 어둠의 시기를 촉발했다.
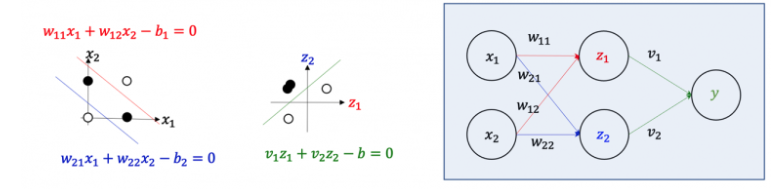
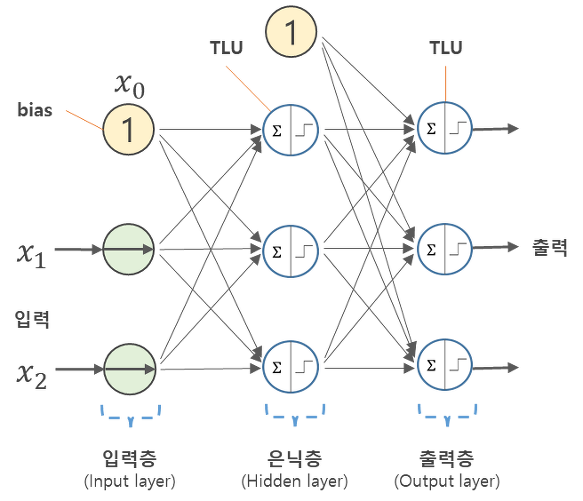
이러한 문제를 해결하기 위하여 은닉층을 이용하여 여러 개의 퍼셉트론을 쌓는 방법이 제시되었다. 배타적 논리합 문제에서 직선 2개를 이용하면 검은 점과 흰 점을 구분할 수 있다. 이 직선을 수직으로 표현하면 다음과 같다.
여기서 입력 의 좌표변환 과 를 통해 좌표계를 변환하여 주면 에서는 검은 점과 흰 점을 비로소 한 개의 직선으로 나룰 수 있다. 이를 신경망의 신호흐름으로 나타내면 위의 그림에서처럼 입력 신호가 은닉층(Hidden layer)의 숨은 뉴런의 활성화 상태로 변환되고 이는 최종적으로 출력신호 로 변환된다. 즉 은닉층을 추가함으로써 단일 퍼셉트론으로 구성된 신경망에서는 표현할 수 없는 XOR을 표현할 수 있게 된 것이다.
이 결론을 일반화 한 것이 보편적 어림정리(Universal Approximation Theorem)정리이다. 충분히 많은 뉴런들로 구성된 은닉층을 가진 신경망은 임의의 입력 와 출력 사이의 함수관계 를 표현할 수 있다는 정리이다. 이는 임의의 입력 와 출력 사이의 관계를 표현할 수 있는 신경망이 반드시 존재함을 보장한다. 그렇다고 이 정리가 신경망 구성을 위한 최소한의 은닉 뉴런 수, 신경망의 매개변수 값들을 구체적으로 알려주진 않는다.
즉 주어진 문제를 풀 수 있는 매개변수의 최적값을 알 수 없다. 배타적 논리합과 같은 간단한 문제는 2차원 좌표 위의 기하학적 모습을 토대로 매개변수 값을 쉽게 정할 수 있지만, 다차원의 입력과 출력 사이의 관계를 다루는 일반적인 문제에서는 간단하지 않다. 이러한 문제를 해결하기 위하여 제시된 방법이 바로 역전파(Backpropagation) 알고리즘이다.
역전파 알고리즘은 지도학습 문제에서 신경망을 학습시키는 방법이다. 결과를 알고 있기 때문에 Output에 대한 오차값을 이용하여 경사하강법(Gradient Descent Method)을 이용하여 매개변수를 갱신한다. 이를 사용하여 순전파와 역전파를 반복해나아가면 이론적으로는 오차가 0에 가까워진다. 하지만 경사하강법의 한계로 인하여 항상 Global minimum을 찾는다고 보장할 수 없다. 또한 극소값이 두 개 이상 존재하는 함수에 대해서 가장 작은 최솟값을 가진다고 할 수 없고, 알고리즘 자체가 단순히 기울기가 작아지는 방향으로 나아가기 때문에, 출발지점에 따라서 결과가 달라질 수 있다.
다시 처음으로 돌아와서 인공신경망을 다시 설명하여 보자면 퍼셉트론으로 구성된 인간의 신경세포를 모방한 구조를 이용하여 컴퓨터를 가르치는 인공지능 방식이라고 할 수 있으며 줄여서 뉴럴넷(Neural-Net)으로 부르기도 한다. 그 구조는 입력층, 은닉층, 출력층으로 구성되어 있다.
신경망은 퍼셉트론을 여러 층으로 쌓아서 만들게 된다. 1개 층으로 이루어진 신경망은 단층 퍼셉트론 신경망이라고 한다. 그리고 1개 층으로는 해결할 수 없는 문제(ex. XOR)를 해결하기 위해서 2개 이상의 층으로 구성하여 여러 개의 층으로 쌓아 구축한 신경망을 다층 퍼셉트론 신경망(Multi-Layer Perceptron, MLP)라고 한다.
1. 신경망의 각 층
1-1. 입력층(Input Layer)
- 데이터가 입력되는 층이다.
- 데이터의 특징의 수에 따라서 입력층의 노드수가 결정된다.
- 그냥 값들을 전달하기만 하는 층이기 때문에 신경망의 층수를 셀 때 입력층은 포함되지 않는다.
1-2. 은닉층(Hidden Layers)
- 입력층으로부터 입력된 신호가 가중치, 편향을 이용하여 연산되는 층
- 입력층과 출력층 사이에 존재하는 층을 의미한다.
- 계산 결과를 사용자가 볼 수 없기 때문에 은닉층(Hidden Layer)라고 한다.
- 입력층의 노드수와 관계없이 노드수를 구성할 수 있다.
- Deep-Learing 알고리즘은 이런 은닉층이 2개 이상인 신경망을 의미한다.
1-3. 출력층(Output Layer)
- 가장 마지막에 위치한 층이며 은닉층 연산을 마친 값이 출력되는 층이다.
- 다중 분류 문제에서는 활성화 함수로 Softmax를 주로 사용하고, 노드 수는 레이블의 Class 수가 된다.
- 이진 분류의 경우 sigmoid 함수를 활성화 함수로 사용하면 1개의 노드, Softmax를 사용하면 2개의 노드를 가지게 된다. 둘의 차이는 사실상 없기 때문에 굳이 노드의 수를 증가시키는 Softmax보다는 sigmoid함수를 사용한다.
- 회귀 문제는 일반적으로는 활성화 함수를 지정해주지 않으며 출력층의 노드 수는 출력값의 특성(Feature)수와 동일하게 설정한다.
2. 가중치 행렬
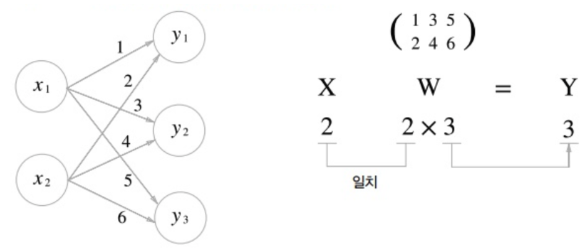
신경망에서 실제로 학습되는 부분이다. 위 그림에서 화살표 하나마다 각각의 가중치가 주어진다. 입력층에 3개의 노드, 은닉층에 4개의 노드가 있기 때문에 12개의 가중치가 존재한다. 이 12개의 가중치가 연산되는 과정을 컴퓨터에서 잘 연산하기 위해서는 행렬의 형태로 만들어주어야 한다.
퍼셉트론에 있는 가중치-편향 연산은 행렬 곱으로 연산이 된다. 입력 벡터의 형태에 따라서 가중치 행렬의 Shape가 결정된다. 관습적으로 표기할 때는 가중치 행렬을 , 입력 벡터를 라 하고, 연산의 결과로 출력되는 벡터는 라 하면 다음과 같이 나타낸다.
하지만 실제 연산에서 위의 식을 그대로 이용하지는 않는다. 실제로는 아래의 그림과 같이 이루어진다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=100), # 은닉층
tf.keras.layers.Dense(1, activation='sigmoid') # 출력층
])위의 코드로 생성한 신경망의 경우 입력층의 노드수가 100개, 은닉층의 노드 개수가 10개이므로 두 층 사이에 생성되는 가중치 행렬의 Shape는 (100,10)이 된다. 은닉층과 출력층의 경우 출력층의 노드 개수가 1개 이므로 두 층 사이에 가중치 행렬의 Shape은 (10,1)이 된다.
3. MINIST 예제(손글씨 분류)
### 패키지 & 라이브러리
import pandas as pd
!pip install tensorflow-gpu==2.0.0-rc1
import tensorflow as tf
# 라이브러리 데이터셋을 불러온다.
mnist = tf.keras.datasets.mnist
# Training Set, Test Set 분류.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Value normalization(정규화) 수행
# 픽셀값이 0~255사이의 값을 가지기 때문에 255로 나누어 준다.
# 이를 수행하지 않을 시 모델의 정확도가 매우 낮게 출력된다.
x_train, x_test = x_train / 255.0, x_test / 255.0
# 레이블의 구성 형태 확인
pd.unique(y_train)
------------------------------------------------------
-> array([5, 0, 4, 1, 9, 2, 3, 6, 7, 8], dtype=uint8)
# 신경망 모델 구축
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 전체 원소 개수를 유지하면서 다차원 자료를 전결합층에 전달하기 위해 1차원 자료로 바꿔주는 Layer이다.
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dropout(0.2), # 과적합(Overfitting) 방지 역할
tf.keras.layers.Dense(10, activation='softmax')
])
# 구축한 모델을 컴파일하며, 옵티마이저, loss function 등을 설정.
# 컴파일 : 모델을 학습시키기 위한 학습과정 설정 단계
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델이 학습 하는 부분
model.fit(x_train, y_train, epochs=5) # epoch의 수를 변화시키면 더 많이 학습하거나 적게 학습할 수 있다.
# 만들어진 모델을 이용하여 예측하는 부분
model.evaluate(x_test, y_test, verbose=2)4. 신경망 종류 그림
2. 활성화 함수(Activation function)
딥러닝에서 사용하는 인공신경망들은 일반적으로 이전 레이어로부터 값을 입력받아 활성화 함수를 통과시킨 후 그 결과를 다음 레이어로 출력한다. 활성화 함수의 종류는 다음과 같다.
- 이진 활성화 함수 (Binary step activation function)
- 선형 활성화 함수(Linear activation function)
- 비선형 활성화 함수(Non-linear activation function)
3가지 종류가 존재하지만 일반적으로 비선형 활성화 함수를 사용한다. 은닉층에서 이진 활성화 함수를 활성화 함수로 사용하면, 다중 출력이 불가능하다는 문제가 발생하고, 은닉층에서 선형 활성화 함수를 활성화 함수로 사용할 경우, 역전파가 불가능하며 Layer를 깊게 쌓는 의미가 사라진다는 문제가 생기기 때문이다.
이런 비선형 활성화 함수는 다양한 종류가 존재하지만 크게 4가지를 다뤄보도록 하겠다.
1. Step function(계단 함수)
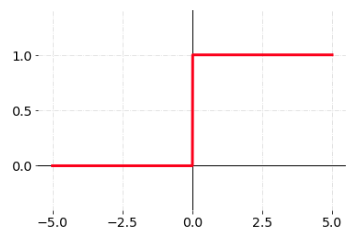
가장 간단한 활성화 함수로 임계값을 넘으면 1 그렇지 않으면 0을 출력하는 함수이다. 하지만 신경망에서는 역전파를 통해 매개변수들을 수정하며 학습하게 되고 이 과정에서 경사하강법이 사용되어 미분 과정이 필요하기 때문에 임계값에서 미분 불가능한 지점을 가지는 Step function은 적합하지 않다.
2. Sigmoid function(시그모이드 함수)
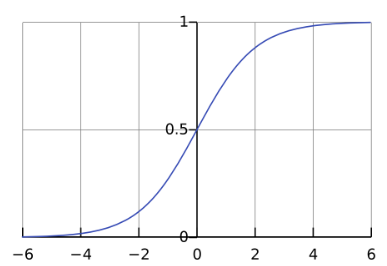
미분 불가능한 점을 가지는 Step function의 단점을 해결하기 위하여 사용되는 함수이다. 계단 함수처럼 임계값보다 작은 부분은 0에 가까워지고, 큰 부분은 1에 가까워진다. 그리고 임계값에서 부드럽게 연결되어 있기 때문에 모든 지점에서 미분 가능하며, 미분값도 0이 아니다.
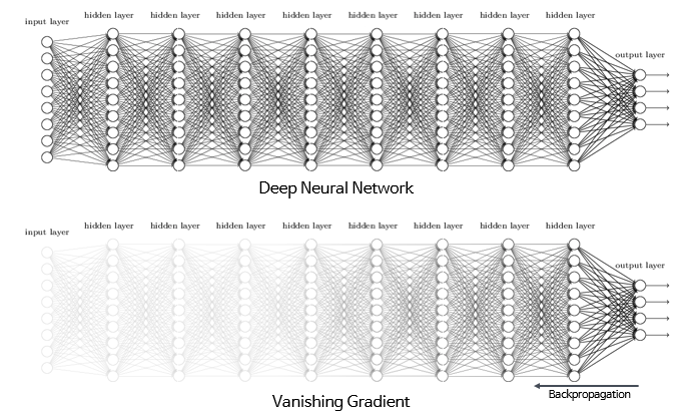
하지만 Sigmoid를 중복하여 사용하면 Vanishing Gradient(기울기 소실)문제가 발생하게 된다.
❗️ Vanishing Gradient(기울기 소실)
딥러닝 분야에서 Layer를 많이 쌓을수록 데이터 표현력이 증가하기 때문에 학습이 잘 될 것 같지만, 실제로는 Layer가 많아질수록 학습이 잘 되지 않는다. 바로 기울기 소실현상 때문이다. 기울기 소실이란 역전파 과정에서 출력층에서 멀어질수록 Gradient값이 매우 작아지는 현상을 말한다.
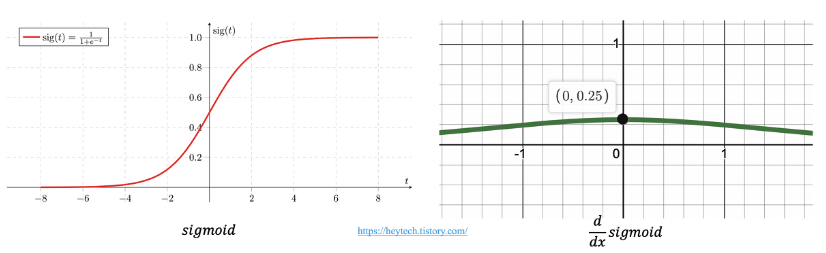
그 원인은 활성화 함수(Activation function)의 기울기와 관련이 깊다. Sigmoid함수를 예로 들어보면 아래의 그림에서 볼 수 있듯이, sigmoid함수의 미분 값은 입력값이 0일 때 가장 크지만 0.25에 불과하고 값이 크거나 작아짐에 따라 기울기는 거의 0에 수렴하는 것을 볼 수 있다.
따라서, 역전파 과정에서 미분값이 거듭 곱해지면 출력층과 멀어질수록 Gradient값이 매우 작아질 수밖에 없다.(이는 역전파 수식을 찾아보자.) 더불어 는 컴퓨터가 계산할 때 정확한 값이 아닌 근사값으로 계산해야 되기 때문에 역전파 과정에서 점차 학습 오차까지 증가하게 된다. 결국 Sigmoid함수를 활용하면 모델 학습이 제대로 이루어지지 않게 된다. 이를 해결하기 위한 방법 중 하나로 tanh함수가 제안되었다.
출력값의 범위를 2배 늘렸지만, 여전히 가울기 소실 문제를 방지하는데 어려움이 있었고, 이를 또 해결하기 위해 ReLU 함수가 제안된다. 그리고 이 함수는 기울기 소실 문제를 잘 해결하였다고 평가받는다.
3. ReLU function(렐루 함수)
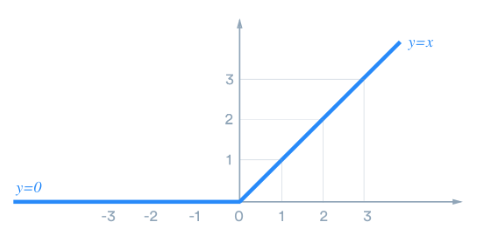
ReLU function는 신경망 발전에 큰 영향을 미친 활성화 함수이다. 시그모이드 함수를 중복하여 사용하게 되면 기울기 소실문제가 발생하게 되는데, 기울기 소실 문제를 해결하기 위해서 등장한 것이 ReLU이다.
ReLU function는 양의 값이 입력되면 그 값을 그대로 출력하고 음의 값이 입력되면 0을 반환한다. 식으로 나타내면 다음과 같다.
함수의 특성상 층이 깊어지더라도 1의 값이 계속 곱해지기 때문에 기울기 값이 과도하게 커지거나 작아지는 문제가 발생하지 않게 된다.
ReLU함수의 등장 이전까지는 은닉층을 깊게 쌓을 수가 없었기 때문에 복잡한 문제를 푸는 데에 딥러닝을 사용할 수 없었다. 하지만 ReLU함수가 고안되고 사용되면서 딥러닝은 더욱 더 발전할 수 이었다.
4. Softmax function(소프트맥스 함수)
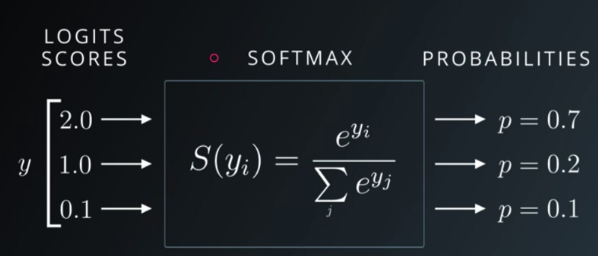
Softmax function는 다중 분류(Multi-classification)문제에 적용할 수 있도록 시그모이드 함수를 일반화한 활성화 함수이다. 가중값을 소프트맥스 함수에 통과시키면 모든 클래스의 값의 합이 1이 되는 확률값으로 변환된다.
3. 표현학습(Representation Learing)
기계 학습에서 특징 학습 또는 표현 학습(Representation)은 시스템이 원시 데이터에서 특징 탐지 또는 분류에 필요한 표현을 자동으로 검색할 수 있도록 하는 일련의 기술을 의미한다.
우리는 보통 어떤 Task를 해결하기 위해 Task와 관련된 정보들을 이용한다. 예를 들어, 나누기(=Task)를 하려고 하면 수(=numeric)라는 정보를 이용한다. 하지만 이러한 수라는 정보들은 다양하게 표현(=Representation)될 수 있다. 로마숫자표기, 아라비아숫자표기 등이 그 예시이다.
보통 Task들의 난이도는 정보들을 어떻게 표현해주느냐에 따라서 결정된다. 즉 정보들을 특정 Task에 맞게 잘 표현해주면 해당 Task를 풀 수 있는 확률이 높아지는 것이다.
결국 어떤 Task를 해결할 때, 정보를 어떻게 가공하여 표현해줄지에 따라서 Task의 난이도가 결정되는 것이다. 그렇다면 딥러닝 모델에서 representation이란 개념은 어떻게 이해해야 할까?
딥러닝에서는 최종 Task의 유형에 따라서 new representation에 해당하는 new feature를 출력하게 된다. 이러한 new representation을 뽑게 학습하는 것을 representation learing이라고 부른다.
사실 너무 방대한 양의 글이라 완벽히 이해는 못했다. 표현학습에 대해서는 나중에 다시 아래의 참고자료를 읽어보자.
4. Tensorflow 신경망 예제 - Iris데이터 분류하기
전체 특성 중 2개의 특성만 선택하여 사용하고, 150개의 데이터 중 Setosa 50개, Versicolor 50개만 추출하여 100개의 데이터에 대해서 이진분류를 진행한다.
# 필요한 패키지와 라이브러리를 불러온다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# 시드(Seed)를 고정한다.
np.random.seed(42)
tf.random.set_seed(42)
# Iris 데이터셋을 Dataframe 형태로 불러온다.
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
# 데이터를 살펴보는 과정의 코드는 생략한다.
# Setosa, Versicolor 데이터만 추출하여 전처리 하여준다.
label = df.iloc[0:100, 4].values
# 타겟 레이블을 Setosa=0, Versicolor=1로 변경해준다.
label = np.where(label == 'Iris-setosa', 0, 1)데이터가 어떤 분포를 가지고 있는지 시각화를 통해 알아볼 수 있다.
features = df.iloc[0:100, [0,2]].values
plt.scatter(features[:50, 0], features[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(features[50:100, 0], features[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.legend(loc='upper left')
plt.show()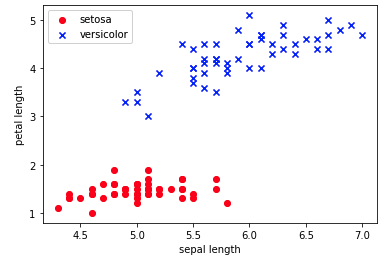
Train dataset과 Test dataset으로 나누어준다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, label, test_size=0.2, random_state=42)다음으로는 신경망 모델을 구축하고 Complie한 후 학습한다. 이번 예제에서는 단층, 즉 은닉층이 없이 출력층으로만 모델을 구성해본다.
먼저 Sequential API를 사용하여 모델을 구축하여 보겠다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, activation='sigmoid')
])위의 코드를 다음과 같이 다른 방식으로도 나타낼 수 있다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))Sequential API말고도 Keras에는 또 다른 방법인 Functional API도 존재한다. 사용법은 다음과 같다.
input = tf.keras.layers.Input(shape=(2,))
output = tf.keras.layers.Dense(1, activation='sigmoid')(input) # <- 새로 추가
model = tf.keras.models.Model(inputs=input, outputs=output)함수형 API에서는 달라지는 점은 다음과 같다.
- Input()함수에 입력의 크기를 정의한다.
- 이전층을 다음층 함수의 입력으로 사용하고, 변수에 할당한다.
- Model()함수에 입력과 출력을 정의한다.
.compile에서는 신경망에서 사용할 optimizer, loss, metrics를 설정한다.
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy'])각 파라미터를 설정함에 있어서 주로 다음과 같이 설정한다.
💡 신경망 설계 - 이진분류
- 활성화 함수: Sigmoid function
- 출력층 노드 수: 1개 (0 또는 1로 라벨링)
- 손실함수: binary_crossentropy(이항 교차 엔트로피)
💡 신경망 설계 - 다중분류
- 활성화 함수: Softmax function
- 출력층 노드 수: Label의 Class 수
- 손실함수
- categorical_crossentropy(범주형 교차 엔트로피, label이 One-Hot Encoding된 형태)
- sparse_categorical_crossentropy(label이 정수 인코딩 된 형태, 즉, label이 class index를 값으로 가질 때 사용)
💡 신경망 설계 - 회귀
- 활성화 함수: 사용하지 않음
- 출력층 노드 수: 출력값의 특성(feature) 수
- 손실함수: MSE(Mean_Squared_error, MSE)
.fit은 실제로 신경망 학습이 진행되는 부분이다. epochs를 조정하면 학습 횟수를 조정할 수 있다.
model.fit(X_train, y_train, epochs=30)
# 학습한 신경망 모델을 사용하여 평가한다.
model.evaluate(X_test, y_test, verbose=2)5. 회고
진짜 진짜 진짜 너무 오랜만에 TIL을 작성하는 것 같다. 아직 N331~N334까지는 작성도 못했는데 밀린 거 하는 것 보다는 일단 Section4 배운 내용을 정리해나가면서 남는 시간에 정리하려고 한다. 후 그래도 뭔가 DE에 대해서 배우다가 다시 인공지능 쪽으로 넘어오니까 뭔가 훨씬 재미있는 것 같다. 일단 진짜로 이번 섹션은 안밀리고 복습하는 것이 목표다.
❗️ 참고자료
1. 퍼셉트론
2. 퍼셉트론2
3. 신경망의 각 층
4. 활성화 함수
5. 기울기 소실
6. 표현학습
