R 을 이용해 데이터분석, 통계처리, 시각화 작업을 위해서는 아래의 과정이 선행되어야 한다.
1. Data 생성 및 호출
- 분석을 필요로 하는 Sample data로 "exam.csv" 파일을 생성할 수 있다.
※ 확장자 csv는 exam.xlsx 파일을 csv 파일로 변환하여 저장이 가능함.
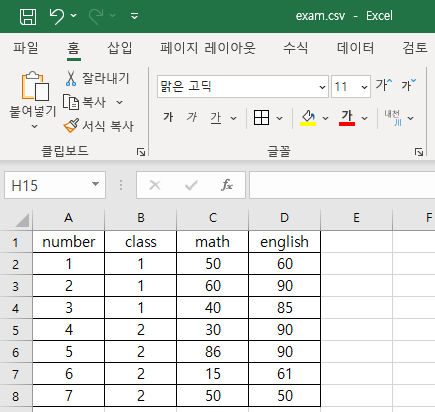
일반적으로 실험결과, 통계청자료 등 Raw 데이터를 제공받아 분석하게 된다. 이 경우에는 파일 포맷을 맞춰 R>>project>>R_Propgram과 같이 같은 위치에 예) exam.csv 파일로 저장한다.

2. Data 전처리
분석을 위해 저장된 데이터는 큰 틀에서의 맥락을 파악하는 작업을 수행 해야한다.
-
EDA(Exploratory Data Analsys, 탐색적 데이터 분석) 수행 : 수집한 데이터를 다양한 각도에서 관찰하고 이해하는 과정으로 데이터의 각 column과 row의 의미를 이해하는 절차로 아래의 과정을 통상 실시한다.
1) 결측치 처리 (N/A 값을 처리하는 방법 등)
2) 이상치 처리 (Box Plot 기준에서 Outlier 걸러내기 등)
3) 데이터 가시화(경향성 Review 등)
-
이후에는 독립변수와 종속변수에 대해 여러 단계로 나누어 통계/빅데이터 분석을 수행한다.
1) 기술적 통계(평균,표준편차 등)를 분석
2) 추론적 통계(t-검정, 카이제곱 검정 등)을 분석
3) 지도학습 (예측하고자 하는 변수(속성,차원,column)가 종속변수에 포함되어 있을 때)
4) 비지도학습 (예측하고자 하는 변수가 종속변수에 포함이 안되어 있을 때)
다시 각론으로 돌아와서 Raw Data를 불러와서 전처리 하는 방법을 정리하고자 한다.
- 데이터 전처리(Preprocessing) - dplyr 패키지를 로드 & 데이터 준비 한다.
library(dplyr)
exam <- read.csv("exam.csv")
exam # 수행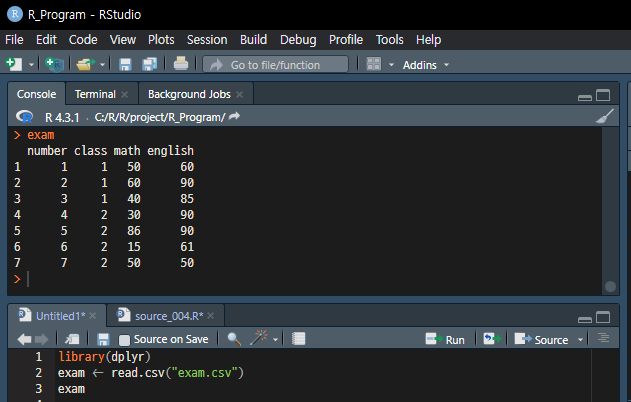
- 1 반 학생들의 데이터만 추출하고자 할 경우
exam %>% filter(class == 1)
- 2반 학생들 중 영어성적이 80점 이상인 데이터만 추출하고자 할 경우
exam %>% filter(class == 2 & english >= 80)
