
**The above picture is from Sesame Street.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (a.k.a. BERT)
This paper was published by Google AI Language, and was the best the state-of-the-art(sota) until the next (sota) comes out. The current citation count is 54720 as of December 16, 2022.
Abstract
Pre-training
Fine-tuning

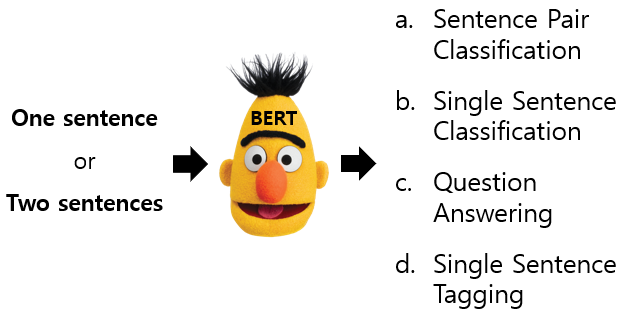
Introduction
ELMo
OpenAI GPT
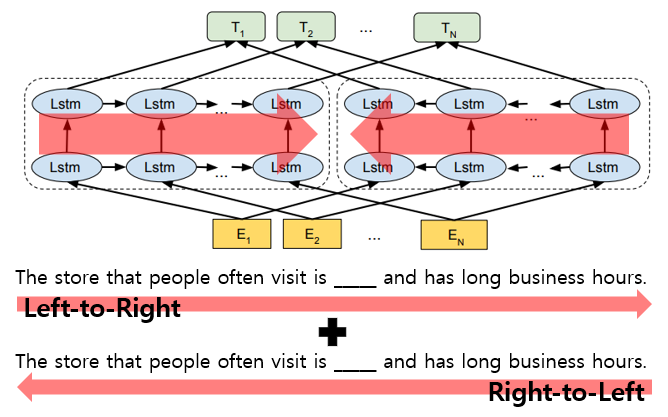
As a result, ELMo and OpenAI GPT use ‘Unidirectional language models’ to learn general language representations.
Fault:
1) ELMo uses shallow concatenation of LTR and RTL LMs (not deeply bidirectional).
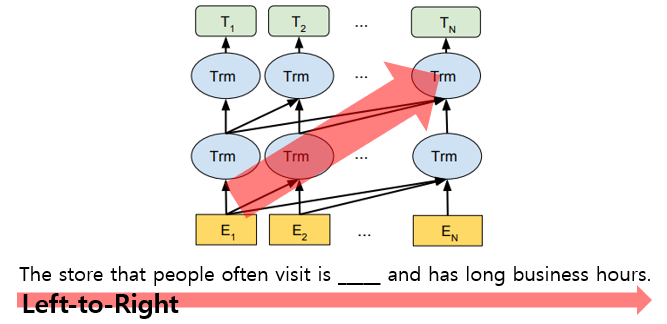
2) OpenAI GPT’s every token can only attend to previous tokens in the self-attention layers of the Transformer.
3) Restrict the power of pre-trained representations.
⇒ It is important to incorporate context from both directions. (B idirectional E ncoder R epresentations from T ransformers; BERT)
Related work
1. Pre-trained language representations to downstream tasks
(1) Unsupervised Feature-based Approaches
1) Word representation learning
- Non-neural and neural methods
2) Pre-trained word embeddings
- Left-to-right language modeling, discriminate correct from incorrect words in left and right context
3) Sentence embeddings, paragraph embeddings
- Rank candidate next sentences, left-to-right generation, denoising auto-encoder derived objectives
4) ELMo (left-to-right(LTR) and right-to-left(RTL) language model(LM))
- Question answering, sentiment analysis, named entity recognition
5) Learning contextual representations using LSTMs, robustness of text generation models
(2) Unsupervised Fine-tuning Approaches
1) Pre-trained from unlabeled text
- word embedding, contextual token representations, OpenAI GPT
2) Left-to-right language modeling, auto-encoder
2. (3) Transfer Learning from Supervised Data
Natural language inference, machine translation, ImageNet (Computer Vision)
BERT
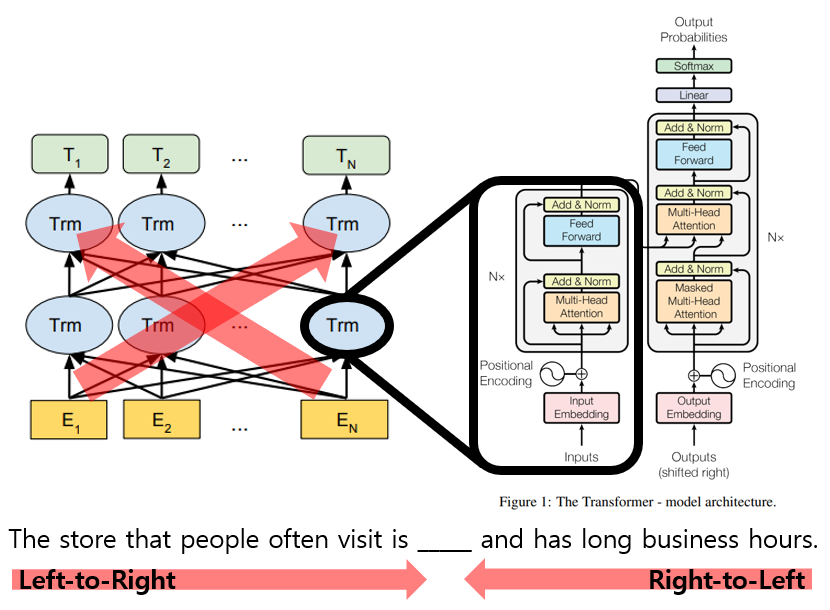
1. BERT (B idirectional E ncoder R epresentations from T ransformer)
BERT is a multi-layer bidirectional transformer encoder.
The architecture of BERT allows that model knows all contexts.
BERT representations are jointly conditioned on both left and right contexts in all layers.
2. Model Architecture
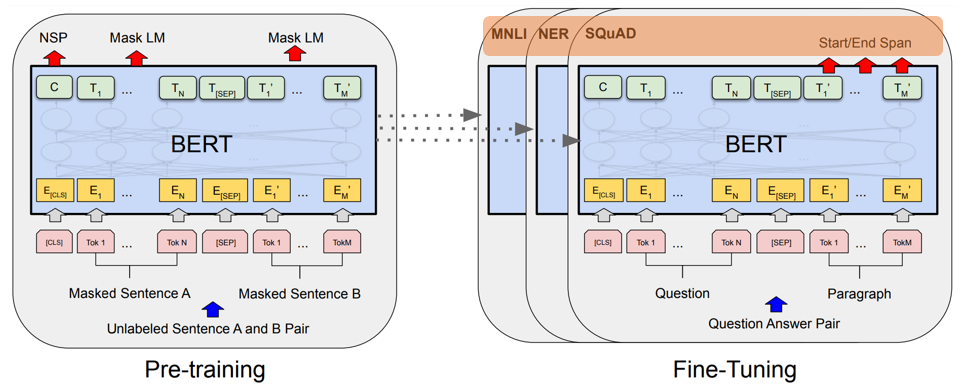
(1) Pre-Training / Fine-Tuning
1) BERT consists of two steps: pre-training and fine-tuning.
- Pre-training) BERT is trained on unlabeled data over different pre-training tasks.
- Fine-tuning) BERT is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks.
- Apart from output layers, the same architectures are used in both pre-training and fine-tuning.
2) Pre-trained BERT model can be fine-tuned with just one additional output layer without substantial task-specific architecture modifications.
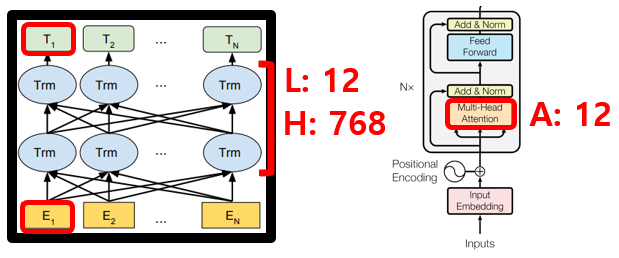
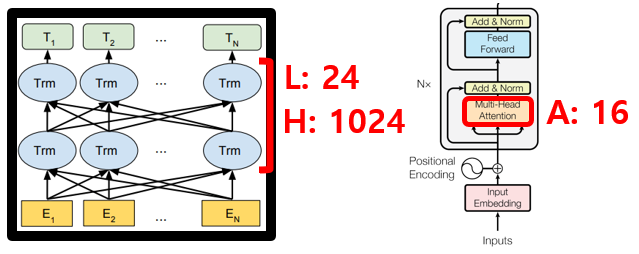
(2) BERT BASE / BERT LARGE
- L: number of layers(i.e., Transformer blocks)
- H: hidden size
- A: number of self-attention heads
1) BERT_BASE (Total parameters=110M)
- the same model size as OpenAI GPT
2) BERT_LARGE (Total parameters=340M)
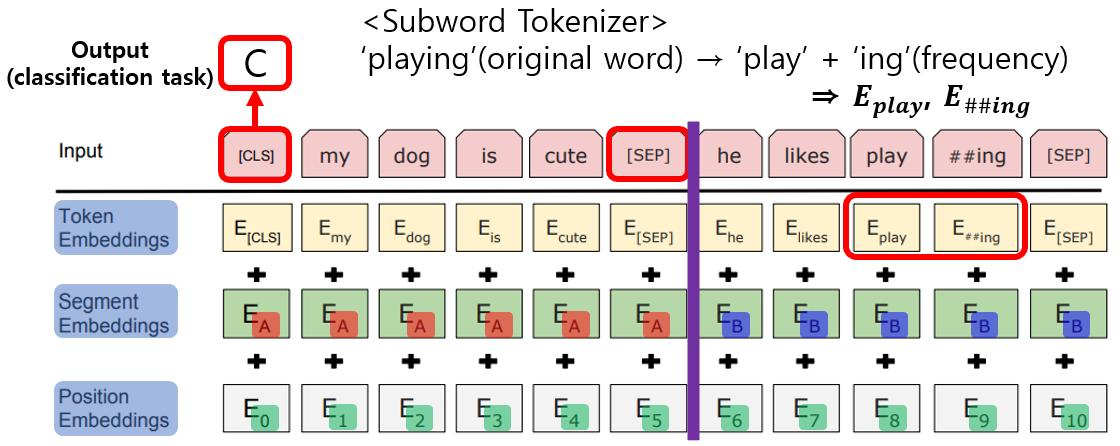
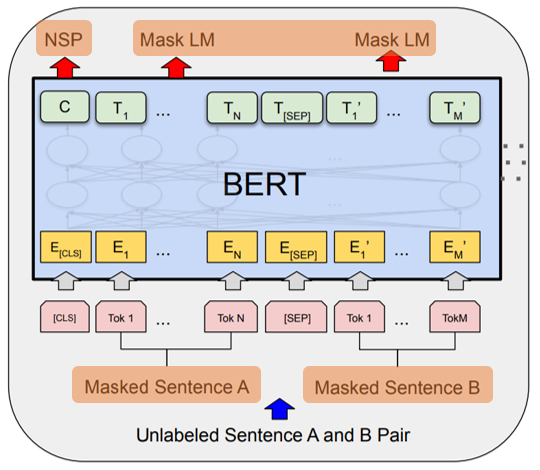
(3) Input/Ouput Representations
- “sentence”: an arbitrary span of contiguous text, rather than an actual linguistic sentence.
- “sequence”: input token sequence to BERT, a single sentence or two packed sentences.
- Word Embedding: WordPiece embeddings with a vocabulary contains 30,000 tokens. (E : input embedding)
- [CLS]
First token of every sequence.
Final hidden state, representation for classification task (𝑪 ∈ ℝ^𝐻)- [SEP]
Separate sequence A and sequence B- 𝑻𝒊 : Final hidden vector for 𝑖^𝑡ℎ input token (𝑻𝒊 ∈ ℝ^𝐻)
3. Pre-training BERT
(1) Task #1. Masked LM (MLM)
- Constraint unidirectionality.
- Enables the representation to fuse the left and the right context, which allows us to pre-train a deep bidirectional transformer.
- Understand the relationship within sentence.
(2) Task #2. Next Sentence Prediction (NSP)
- Jointly pre-trains text-pair representations for understanding the relationship between two sentences.
(3) Data
- BooksCopus (800M words), English Wikipedia (2,500 words).

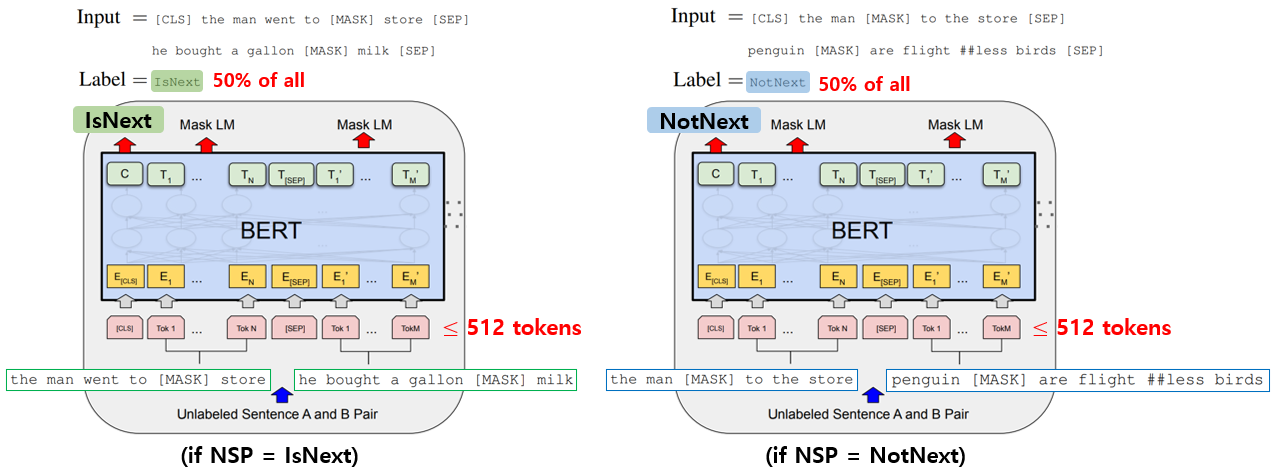
4. Task #1. Masked NM (MLM)
(1) How to
1) mask 15% of all token in each sequence at random
2) predict input sentences’ [MASK]
3)
thefinal hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM.(2) Mismatch between pre-training and fine-tuning occurs since the [MASK] tokens doesn't appear
duringin fine-tuning.⇒ To mitigate this, instead of [masked] token, replace "masked" word in pre-trinaing.

5. Task #2. Next Sentence Prediction (NSP)
How to
1) half of sentences B is the actual next sentence that follow A (labeled as IsNext), and half of sentences it is a random sentence from the corpus (labeled as NotNext).
2) predict a ‘binary classification of next sentence prediction(NSP)’
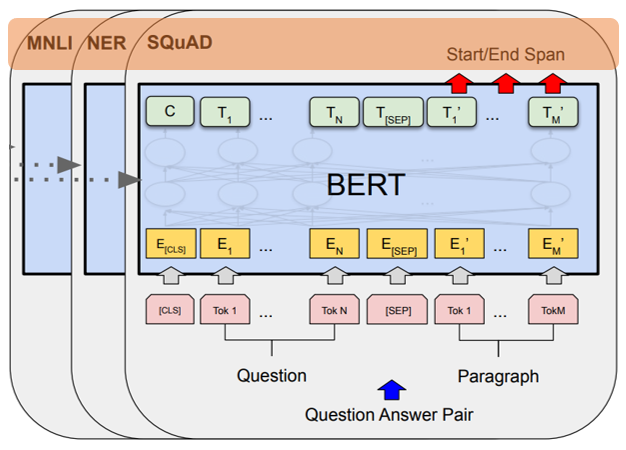
6. Fine-tuning BERT
(1) BERT is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks.
(2) Input
- 1) sentence pairs in paraphrasing
- 2) hypothesis-premise pairs in entailment
- 3) question-passage pairs in question answering
- 4) a degenerate text-∅ pairs in text classification or sequence tagging
(3) Output
- Token-level tasks(sequence tagging, question answering) by token representations
- Classification result (entailment, sentiment analysis) by [CLS] representation
Experiments
1. 11 NLP tasks
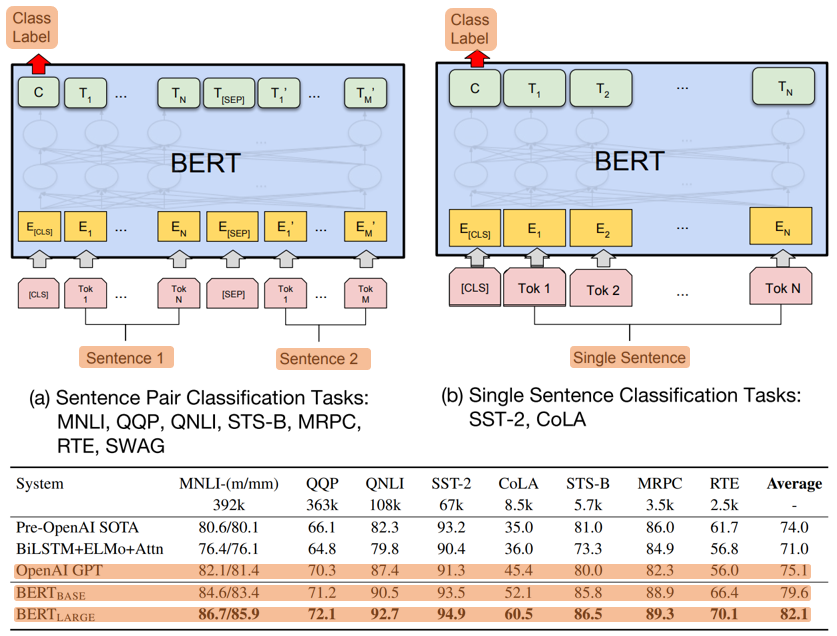
(1) GLUE (General Language Understanding Evaluation)
1) Single text
- SST-2 (Stanford Sentiment Treebank) – binary single-sentence classification task (movie reviews) ----- (1)
- CoLA (Corpus of Linguistic Acceptability) – binary single-sentence classification task (acceptable or not) ----- (2)
2) Text pair
- MNLI (Multi-Genre Natural Language Inference) – entailment / contradiction/ neutral classification task ----- (3)
- QQP (Quora Question Pairs) – binary classification ----- (4)
- QNLI (Question Natural Language Inference) – binary classification task ----- (5)
- Positive examples – question and correct answer
- Negative examples – not contain the answer- STS-B (Semantic Textual Similarity Benchmark) – sentence pairs drawn from news headlines and other sources (similar 5 scores) ----- (6)
- MRPC (Microsoft Research Paraphrase Corpus) – sentence pairs automatically extracted from online news sources ----- (7)
- RTE (Recognizing Textual Entailment) – binary entailment task ----- (8)
- WNLI (Winograd) – exclude
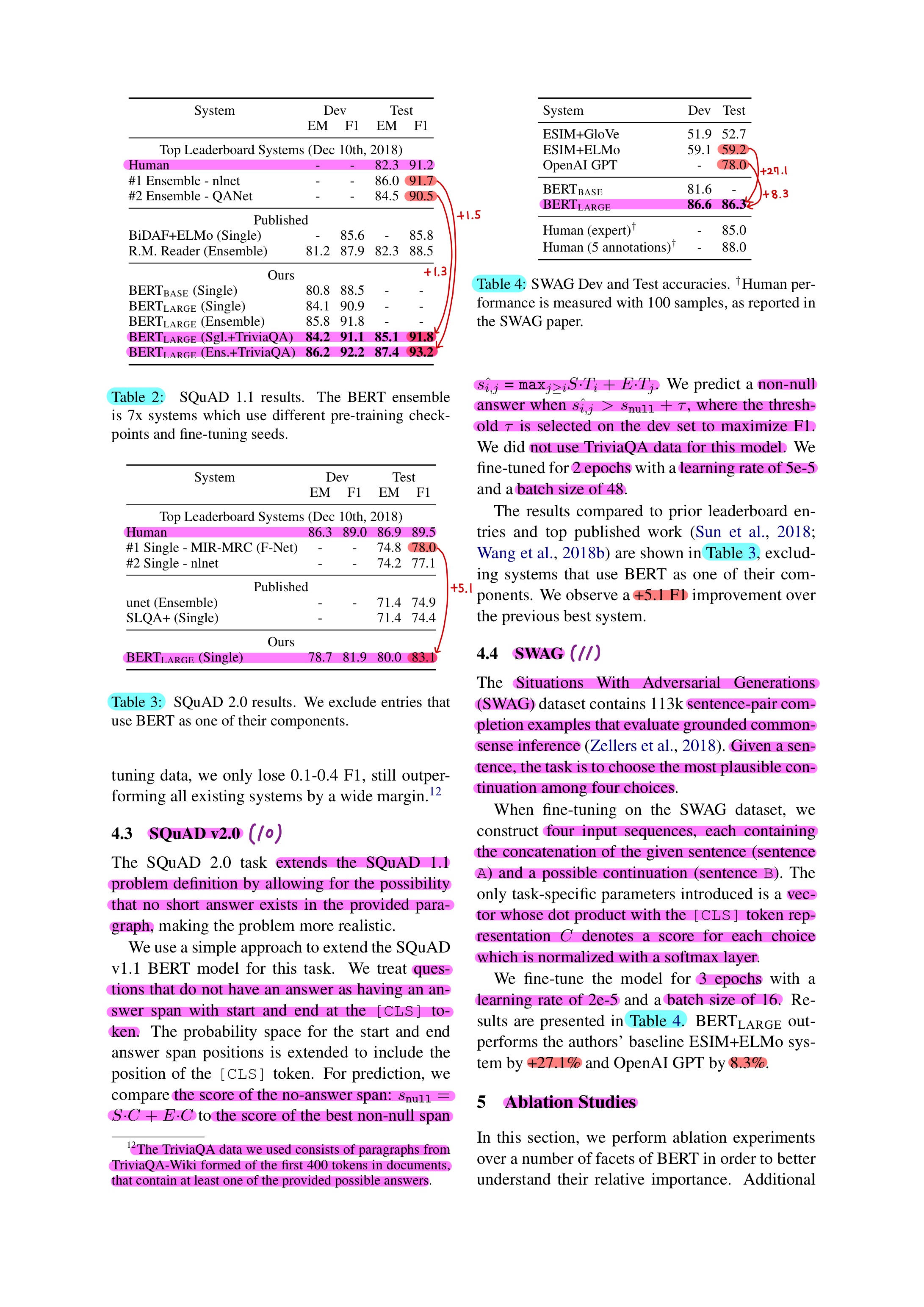
(2) SQuAD (Stanford Question Answering Dataset)v1.1 / v2.0 ----- (9), (10)
- 100K crowedsourced question/answer pairs
- Question + A passage from Wikipedia containing the answer -> the task is to predict the answer text span
(3) SWAG (Situations With Adversarial Generations) ----- (11)
- Sentence pair completion
- Sentence -> choose the most plausible continuation four choices
2. GLUE
- Classification layer weights 𝑊 ∈ ℝ^(𝐾 𝑥 𝐻), where 𝐾 is the number of labels
- A standard classification loss with 𝐶 and 𝑊, i.e., log(𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝐶𝑊^𝑇))
- Batch size : 32
- 3 epochs
- The best tuning learning rate(among 5e-5, 4e-5, 3e-5, and 2e-5)
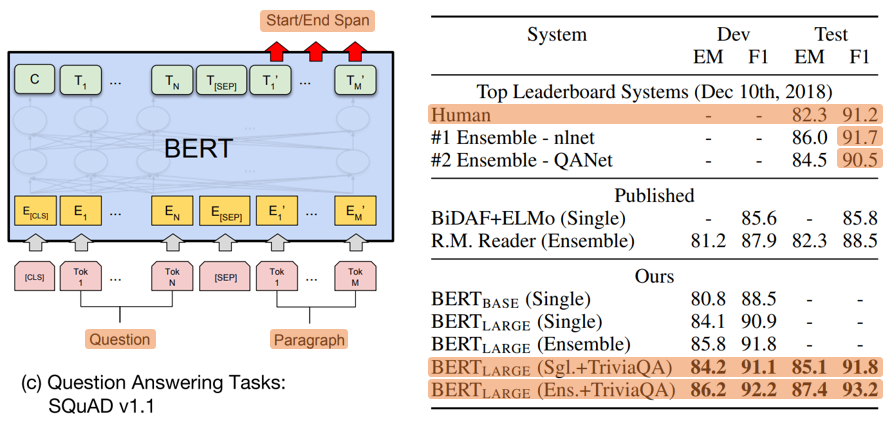
3. SQuAD v1.1
- Start vector = 𝑆 ∈ ℝ^𝐻
- End vector = 𝐸 ∈ ℝ^𝐻
- Probability of word 𝑖
- Start span = 𝑃𝑖 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑆⋅𝑇𝑖) = 𝑒^(𝑆⋅𝑇𝑖)/(∑𝑗 𝑒^(𝑆⋅𝑇_𝑗))
- End span = 𝑃𝑖 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝐸⋅𝑇𝑖) = 𝑒^(𝐸⋅𝑇𝑖)/(∑𝑗 𝑒^(𝐸⋅𝑇𝑗))
Score of a candidate span from position 𝑖 to position 𝑗 = 𝑆⋅𝑇𝑖 + E⋅𝑇_𝑗, the maximum scoring span where 𝑗 ≥ 𝑖- The training objective is the sum of the log-likelihoods of the correct start and end position
- 3 epochs
- Learning rate: 5e-5
- Batch size: 32
- Use modest data augmentation in our system by first fine-tuning on TriviaQA
- TriviaQA consists of paragraphs from TriviaQA-Wiki formed of the first 400 tokens in documents.
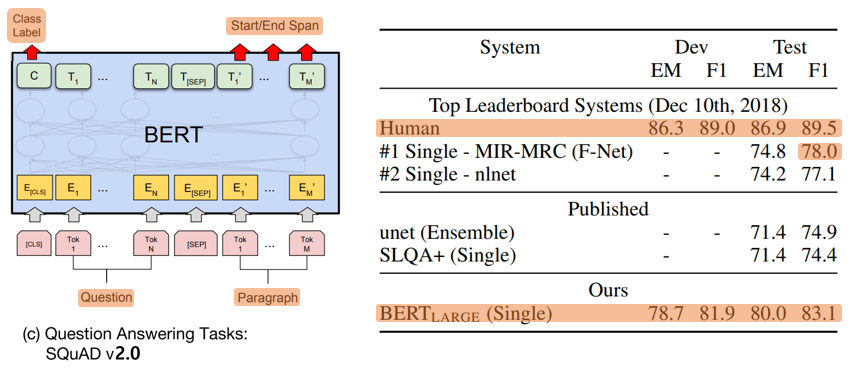
4. SQuAD v2.0
- Extends SQuAD v1.1
- Questions that do not have an answer as having an answer span with start and end at the [CLS] token
- Start vector = 𝑆 ∈ ℝ^𝐻
- End vector = 𝐸 ∈ ℝ^𝐻
- Probability of word 𝑖
- Start span = 𝑃𝑖 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑆⋅𝑇𝑖) = 𝑒^(𝑆⋅𝑇𝑖)/(∑𝑗 𝑒^(𝑆⋅𝑇_𝑗))
- End span = 𝑃𝑖 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝐸⋅𝑇𝑖) = 𝑒^(𝐸⋅𝑇𝑖)/(∑𝑗 𝑒^(𝐸⋅𝑇_𝑗))
- Score of the no-answer span: 𝑠_𝑛𝑢𝑙𝑙 = 𝑆⋅𝐶 + 𝐸⋅𝐶
- Score of the best non-null span: 𝑠(𝑖 ̂, 𝑗)=〖𝑚𝑎𝑥〗(𝑗≥𝑖) 𝑆⋅𝑇𝑖 + 𝐸⋅𝑇𝑖
- Predict non-null answer when 𝑠(𝑖 ̂, 𝑗) > 𝑠𝑛𝑢𝑙𝑙 + 𝜏, where the threshold 𝜏 is selected on the dev set to maximize F1.
- TriviaQA data is not used for this model
- 2 epochs
- Learning rate: 5e-5
- Batch size: 48
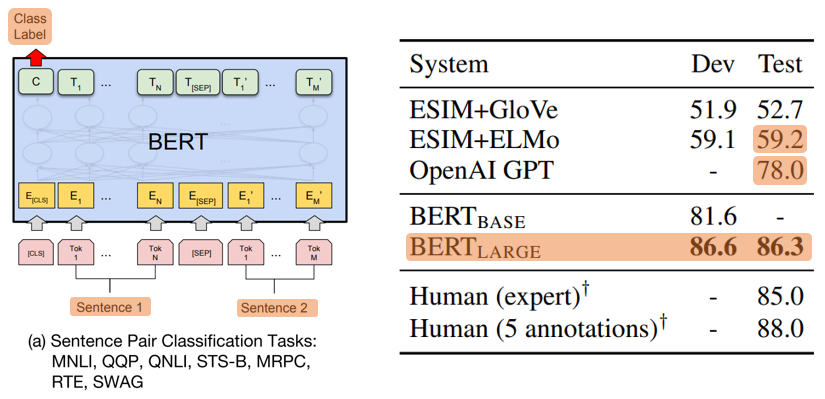
5. SWAG
- Given sentence, the task is to choose the most plausible continuation among four choice
- Vector whose dot product with the [CLS] token representation 𝐶 denotes a score for each choice which is normalized with a softmax layer
- 3 epochs
- Learning rate: 2e-5
- Batch size: 16
6. Parameters & Performance, etc.
(1) Pre-training
- Batch size = 256
- 1,000,000 steps
- 40 epochs
- Adam with learning rate of 1e-4, 𝛽_1= 0.9, 𝛽_2= 0.999
- L2 = decay of 0.01
- Learning rate warmup over the first 10,000 steps, and linear decay of the learning rate
- Dropout probability of 0.1
- Gelu activation
- Loss = sum of the mean masked LM likelihood + the next sentence prediction likelihood
(2) Fine-Tuning
- All of the settings are same with pre-training step except for batch size, learning rate and epochs.
- Batch size = 16, 32
- Learning rate (Adam) = 5e-5, 3e-5, 2e-5
- 2, 3, 4 epochs
(3) Performance
- Training of BERT_BASE : 4 Cloud TPUs (16 TPU chips) took 4 days to complete
- Training of BERT_LARGE : 16 Cloud TPUs (64 TPU chips) took 4 days to complete
(4) etc. Pre-train the model with sequence length of 128 for 90% of steps. Train the rest 10% of steps of sequence of 512 to learn the positional embeddings
Ablation studies
What is 'Ablation Study' ?
Experiment except one method or change one method among purpose methods
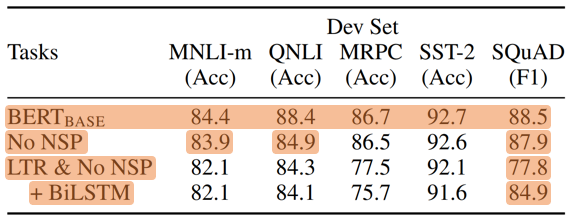
1. Effect of Pre-training Tasks
- No NSP: without the “next sentence prediction” (NSP) task.
- LTR & No NSP: Left-to-Right (LTR) LM without the NSP task.
- LTR model will perform poorly at token predictions, since the token-level hidden states have no right side context.
- Train separate LTR and RTL models and represent each token as the concatenation of the two models, as ELMo dose.
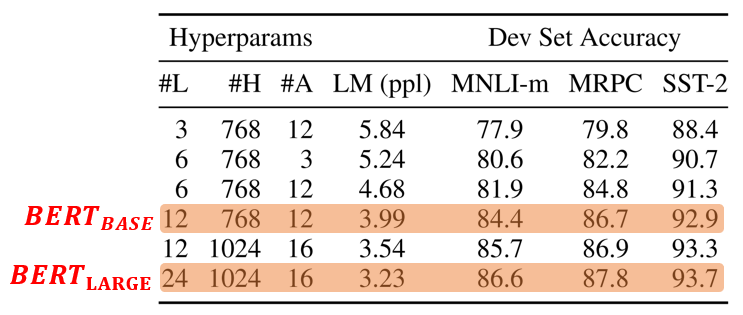
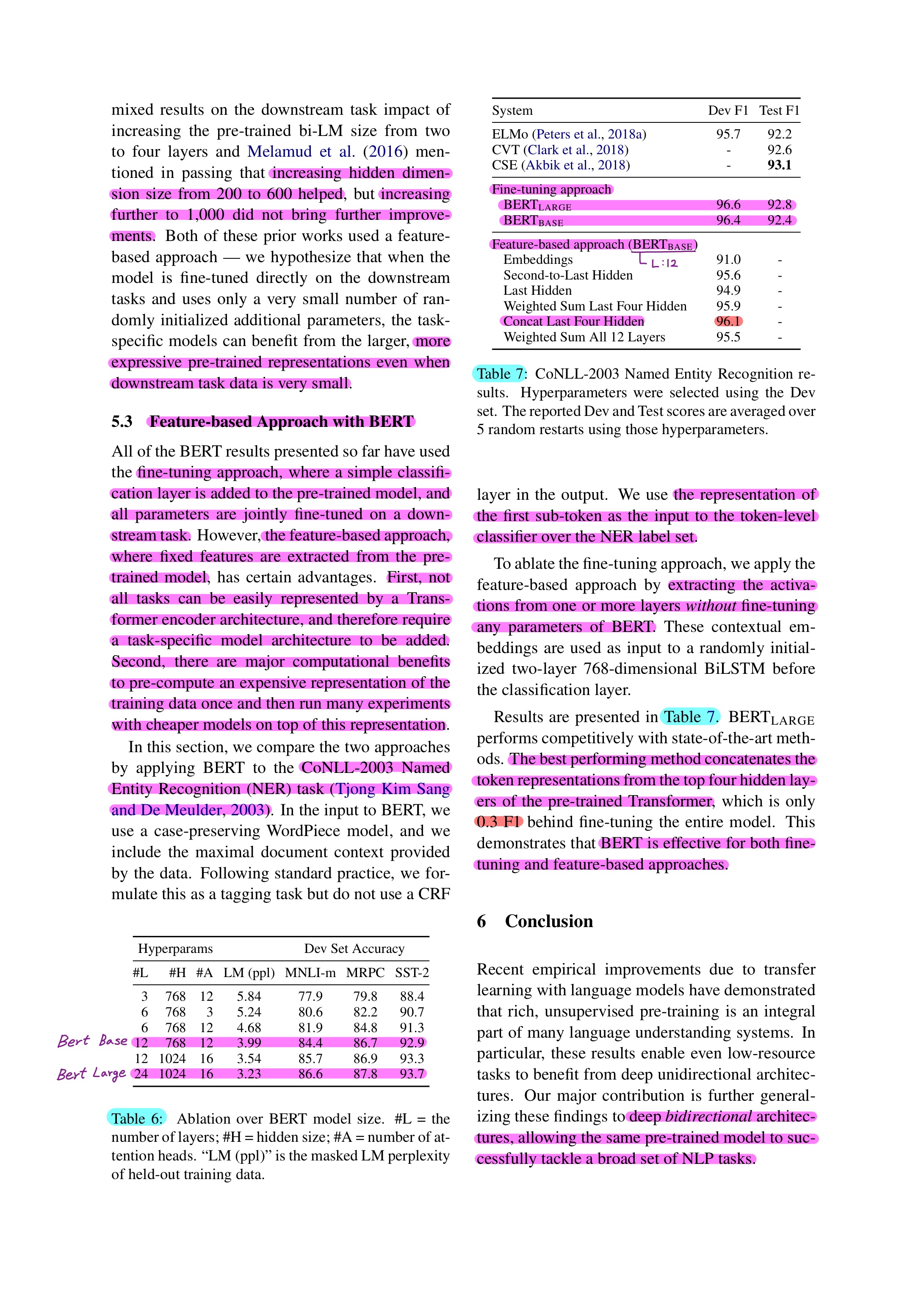
2. Effect of Model Size
- Scaling to extreme model sizes also leads to large improvements on very small scale tasks, provided that the model has been sufficiently pre-trained.
- Increasing hidden dimension size from 200 to 600 helped, but increasing further to 1,000 did not bring further improvements.
- More expressive pre-trained representations even when downstream task data is very small.
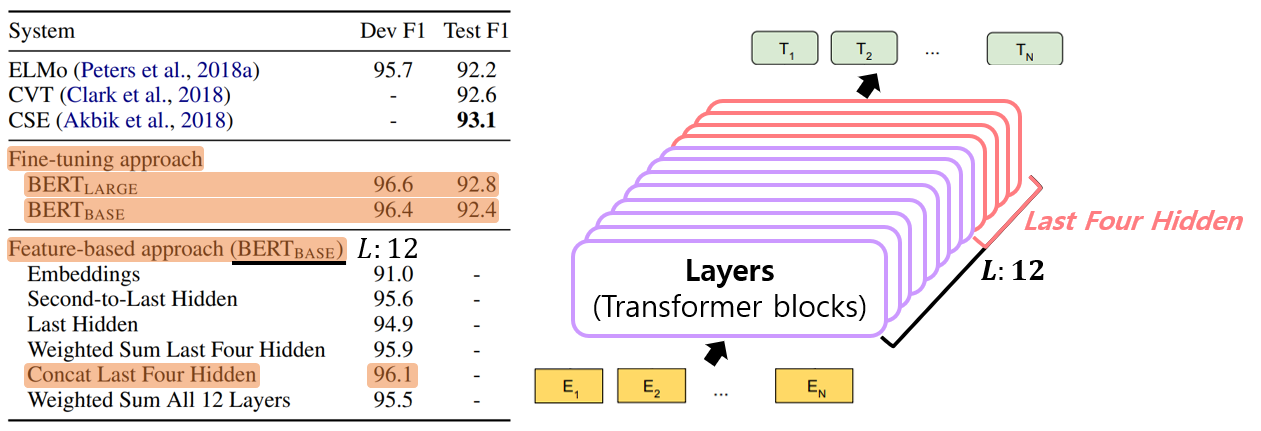
3. Feature-based Approach with BERT
- Advantages
- First, All of the tasks could not be represented easily by a Transformer encoder architecture, and therefore require a task-specific model architecture to be added.
- Second, there are major computational benefits to pre-compute an expensive representation of the training data once and then run many experiments with cheaper models on top of this representation.
- Use CoNLL-2003 Named Entity Recognition(NER) task
- Extracting the activations from one or more layers without fine-tuning any parameters of BERT
- BERT paper author said, “BERT is effective for both fine-tuning and feature-based approaches.”
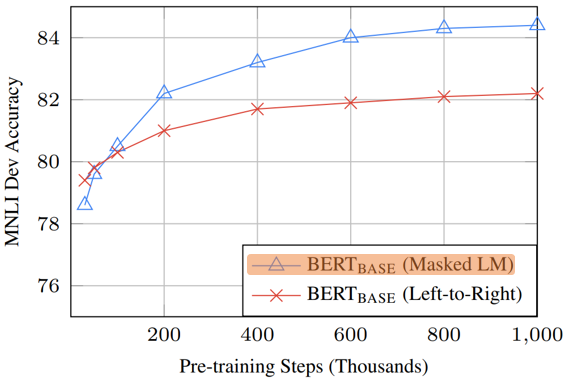
4. Effect 0f Number of Training Steps
- Masked vs. Unmasked
- The empirical improvements of the MLM model far outweigh the increased training cost.
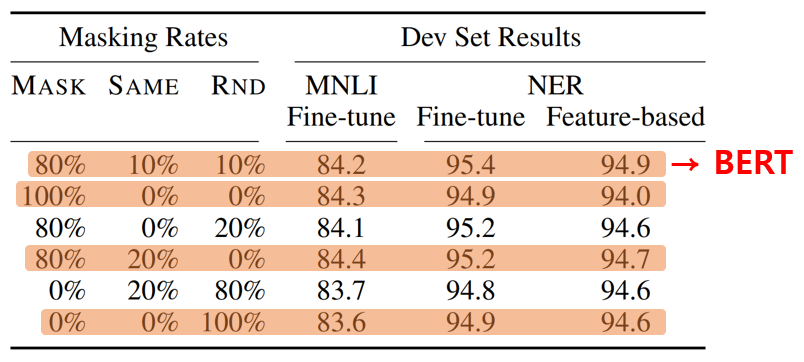
5. Different Masking Procedures
- Optimal masking rate
Conclusion
- BERT is the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.
- Also, Deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
- BERT advanced the state of the art at that time(2019~before the next the state of the art comes out).
References
1. Related works References
(1) Unsupervised Feature-based Approaches
1) Word representation learning
- Non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014) methods
2) Pre-trained word embeddings (Turian et al., 2010)
- Left-to-right language modeling (Mnih and Hinton, 2009), discriminate correct from incorrect words in left and right conte-xt (Mikolov et al., 2013)
3) Sentence embeddings (Kiros et al., 2015; Logeswaran and Lee, 2018), paragraph embeddings (Le and Mikolov, 2014)
- Rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation (Kiros et al., 2015), denoising auto-encoder derived objectives (Hill et al., 2016)
4) ELMo (Peters et al., 2017, 2018a)
- Question answering (Rajpurkar et al., 2016), sentiment analysis (Socher et al., 2013), named entity recognition (Tjong Kim Sang and De Meulder, 2003)
5) Learning contextual representations using LSTMs (Melamud et al., 2016), robustness of text generation models (Fedus et al., 2018)
(2) Unsupervised Fine-tuning Approaches
1) Pre-trained from unlabeled text
- word embedding (Collobert and Weston, 2008), contextual token representations (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018), OpenAI GPT (Radford et al., 2018)
2) Left-to-right language modeling, auto-encoder (Howard and Ruder, 2018; Radford et al., 2018; Dai and Le, 2015)
(3) Transfer Learning from Supervised Data
- Natural language inference (Conneau et al., 2017), Machine translation (McCann et al., 2017), ImageNet (Deng et al., 2009; Yosinski et al., 2014)
2. Data References
(1) Embedding
- WordPiece Embeddings (Go to Site)
(2) Pre-training
- BooksCorpus (Go to Site)
- English Wikipedia (Go to Site)
(3) Fine-tuning
1) GLUE (Go to Site)
- MNLI (Go to Site)
- QQP (Go to Site)
- QNLI (Go to Site)
- SST-2 (Go to Site)
- CoLA (Go to Site)
- STS-B (Go to Site)
- MRPC (Go to Site)
- RTE (Go to Site)
- WNLI (Go to Site)
2) SQuAD v1.1 / v2.0 (Go to Site)
3) TriviaQA (Go to Site)
4) SWAG (Go to Site)
(4) Ablation Studies
- CoNLL-2003 NER (Go to Site)
3. Review References
- BERT paper (Go to Site)
- KU DSBA LAB (Go to Site)
- 집현전 자연어처리 모임 (Go to Site)















Generative AI