
과거 몇몇 글에서 언급한 적이 있었지만, 필자는 회사에서 오너십을 가지고 담당하던 프로덕트의 레거시 페이지를 Vue(Nuxt) 기반으로 처음부터 다시 구현하는 리라이팅(또는 '그린필드') 프로젝트를 진행한 바 있습니다.
이번 글에서는, 과거 프로젝트를 처음 계획하고 시작하던 시기에서부터 어떠한 고민들을 했었고 무슨 의도로 의사결정을 했었는지 등을 이야기해 보고자 합니다. 어떤 정제된 지식을 공유한다기보단 과거의 경험이나 생각들을 개인적으로 다시금 복기하고 새겨보는 차원에서 쓰는 회고이지만, 이 글을 읽는 분들에게도 어떤 유의미한 간접 경험을 제공할 수 있었으면 합니다.
무엇이 문제였나

보통의 주니어들이 그러하듯(?) 의욕은 넘쳤지만 처음부터 무작정 새로 만들어야겠다는 생각이 들었던 것은 아니었습니다. 입사 이후 꽤 오랜 시간 동안 수많은 비즈니스 피처들을 개발하고 이런저런 개선 작업들을 수행하다 보니, 자연스럽게 변화가 필요하겠다는 생각에 미치게 되었습니다.
서비스 런칭 이후 한 번도 리팩토링된 적이 없었고, 과거 소위 'LAMP 스택'이 한창 대세이던 시절 개발된 전형적인 레거시였지만, 단순히 '코드 퀄리티가 너무 나빠서'라는 불만보다도 '이제는 뭔가를 더 하기가 어렵겠다'는 판단이 섰기 때문이었습니다.
일단 가장 피부에 와닿았던 문제는, 업무 효율성의 측면에서 악영향이 적지 않다는 것이었습니다. 가령 코드가 지나치게 스파게티인 탓에 쉽게 인지 부하가 발생하여 섣불리 손을 대지 못하는가 하면, 어렵게 수정해도 미처 영향도를 파악하지 못하고 놓치는 부분이 생겨 꼭 어딘가가 망가지는 경우가 빈번했습니다.
구조화된 테스팅도 어렵다 보니 애초에 그런 문제가 잘 발견되지도 못했고, Cypress나 Puppeteer 같은 도구를 사용해 E2E 테스트라도 어떻게 엉성하게나마 시도해 보기는 했지만 결과적으로 크게 의미가 있진 않았습니다. 사내에 명확한 QA 프로세스가 있는 것도 아니었어서, 버그가 그대로 릴리즈되는 경우도 있었습니다.
종종 기획자들이 제안하는 어떤 아이디어를 검증하기 위해 프로토타이핑을 하려는 경우에도, 현재 환경에서는 구현이 어렵다거나 불필요하게 과도한 공수가 소요된다는 이유로 검토 단계에서 반려해야 하는 상황이 있는가 하면, 한창 진행하던 업무도 중도에 기술적인 문제로 인해 좌초되는 상황이 있기도 했습니다.
이는 필자가 속한 프론트엔드 챕터 전반에 걸친 문제였기 때문에, 모두가 문제의식은 공유하고 있기는 했지만 막상 누구도 이렇다 할 시도는 하지 못하는 답답한 상황이었습니다. 게다가 그런 와중에도 비즈니스적인 필요로 인해 업무는 쏟아지다 보니 부하와 스트레스가 가중되면서 생산성은 더 떨어지고, 도전적인 난도의 개발은 거의 시도하지 못하니 비슷한 수준의 업무만을 처리하게 되어 개인적인 성장에도 한계가 존재했습니다. 그야말로 전형적인 악순환의 상황이었던 것입니다.
컨센서스(합의) 형성하기

하지만 그런 문제에도 불구하고, 회사에서 하는 일이었기 때문에 당장 의욕만 앞서서는 프로젝트를 시작할 수 없었습니다. 주변의 동료들은 물론, 그보다 상위의 결정권자들을 포함해 프로젝트의 당위성에 대한 전반적인 공감이 선행되어야만 했습니다.
만성적인 리소스 부족 상황에서, 어떤 프로젝트를 진행한다는 것은 그만큼 기존의 루틴 업무에는 차질이 빚어진다는 것을 의미합니다. 흔히 레거시 극복과 같은 일을 두고 '달리는 기차의 바퀴를 갈아 끼운다'고 비유하는데, 말 그대로 기차는 계속 달려야 하는 상황에서 슬쩍 빠져나와(?) 다른 일을 하려면 전사적으로 그에 대한 합의와 지원이 필요했습니다.
이미 조직 차원에서 확고한 의지가 있어서 별도의 스쿼드를 구성한다던지, CTO 같은 리더가 존재해서 리드하는 경우였다면 한결 수월한 일이었을 수도 있겠지만, 아쉽게도 필자의 경우에는 해당하지 않았기 때문에 이 과정에서 꽤 많은 시간이 소요되었습니다. 나중에서야 든 생각이지만, 이 과정이 개발보다도 더 어렵고 지지부진했으며 프로젝트 과정에서 가장 큰 걸림돌이었습니다.
적어도 같은 개발자, 엔지니어들은 잠시 멈추고 재정비하는 '피트 스탑(pit stop)'의 시간이 왜 필요한지, 상환이 불가할 정도로 부채가 쌓이기 전에 언젠가 누군가는 '갈아 엎어야' 하는 때가 오는지를 경험적으로 알고 있거나 쉽게 공감하는 편이었지만, 그 이외에는 필요성을 잘 이해하지 못하거나, 혹은 이해하지 않으려는 경우도 있었습니다.
그래서 무언가 실질적인 증명이 선행되어야겠다는 생각이 들었는데, 소위 말하는 'Proof of Concept(PoC)', 혹은 파일럿 프로젝트를 진행해보기로 했습니다.
일단은 당장 빠른 구현을 위해 Vue 2 및 Nuxt 2를 선택했는데, 이는 추후 React와 Next, 그리고 Vue 3 및 Nuxt 3와 비교해보기 위해 의도적으로 레거시를 선택한 것이었습니다. 그리고 담당하던 서비스의 특정 페이지를 선정해 핵심 기능만을 간단히 구현하여 데모를 만들고, 의사결정과 관련된 이해 관계자들에게 시연했습니다.
주로 SPA 특유의 자연스러운 화면 전환이나, 프레임워크의 최적화에 의한 렌더링 퍼포먼스의 향상, 적절한 애니메이션 사용으로 소위 '모던'한 룩앤필을 구현하여 사용자 경험(UX) 측면에서의 개선 가능성을 어필했습니다.
다만 정량적인 개선을 증명할 필요도 있었기 때문에, 데모 페이지인 만큼 정확한 비교는 어렵지만 Lighthouse를 활용하여 Web Vitals 스코어를 측정하기도 했습니다. 특히 기존에 가장 문제가 많았던 인터랙션 퍼포먼스 측면에서 향상되었음을 확인할 수 있도록 했고, 특히 패러다임의 전환(선언형)으로 이전 대비 코드가 눈에 띄게 간결해진 부분이나, 같은 기능이더라도 훨씬 더 적은 공수로 개발이 가능함을 직접적으로 보여줌으로써 '무리가 있더라도 바퀴를 갈아 끼우긴 해야 한다'는 컨센서스가 형성될 수 있도록 유도했습니다.
Vue 3, Nuxt 3
앞서 언급했듯, Vue를 굳이 2 버전으로 선택했던 것은 다른 프레임워크와 비교해보기 위한 의도였습니다.
애초에 Vue를 사용한다 한들 2 버전은 아니라고 본 것인데, 이미 Vue 생태계는 3 버전을 중심으로 완전히 재편된 상태였기 때문입니다(공식적으로 22년 2월을 기점으로 default version으로 전환되었습니다). 레거시 청산을 위한 프로젝트인 만큼 같은 문제를 반복한다는 것은 어불성설이었고, 미래의 유지보수 문제를 고려한다면 Vue 3를 채택하는 것이 당연했습니다.
다만 한 가지 걸리는 문제는 Nuxt 3가 아직 RC 버전이었다는 것이었습니다. 곧 Stable 버전이 출시된다는 발표가 나와 있는 상태이긴 했지만, 아직 안정화되지 않은 프레임워크를 프로덕션 레벨에 사용한다는 것은 분명 적절한 판단이 아닌 듯했고, 그마저도 코로나 이슈 때문이었는지 당초 공표한 날짜보다 계속 늦어지기까지 하는 상황이었습니다.
Nuxt를 사용하지 않고 그냥 Vue 만으로 개발한다는 선택지도 물론 존재했습니다만, 구태여 그렇게 하기에는 비효율적이거니와 그동안의 경험과 환경으로 판단하기에 아래와 같은 이유들로 인해 가급적이면 프레임워크에 더 의존할 필요가 있다고 보았습니다.
- 평소에도 팀원들의 코드 스타일, 컨벤션이 일관되게 합의되지 않는 편이었습니다. 규칙을 어떻게 협의하더라도, 그것을 준수해야 한다는 의지가 옅어 결국 엄격하게 지켜지지는 않는 경우가 많았는데, 이런 경우에는 시스템으로 강제하는 것이 바람직할 수 있습니다.
프레임워크는 기본적으로 정형화된 틀에서 규격화된 애플리케이션을 만드는 데 활용하는 도구입니다. 그동안은 개발자들 각각 자신의 스타일로 느슨하게 개발해 왔다는 문제가 있었기 때문에, 코드 퀄리티의 균일성, 유지보수성의 문제는 중요한 판단 기준이었습니다.- 필자가 담당하는 이커머스 도메인의 특성상
SEO는 핵심적인 가치 중 하나였고, 사용자들이 빈 화면을 보면서 기다리는 시간이 없도록 초기 페이지를SSR로 빠르게 서빙하고FCP타이밍을 최대한 당기는 방식이 사용자 경험에 더 긍정적이라는 내부적인 판단이 이미 존재하는 상황이었습니다. 이는Nuxt와 같은 렌더링 프레임워크의 대표적인 강점이기도 하므로 채택할 만한 이유가 될 수 있었습니다.- 이외에도 번들러 설정이나, 라우팅 시스템 구현, 코드 스플리팅/트리 쉐이킹 등에서 비교적 신경 쓸 부분이 적어지고, 자동화되는 부분이 많아 편리해진다는 점에서 개발자 경험(DX)에도 긍정적이었습니다.
때문에 일단은 RC 버전으로 개발을 진행했고, 다행히 이렇다 할 크리티컬한 이슈가 발생하지는 않았습니다. 특히 Stable 버전 출시 이후로는 굉장히 빠른 속도로 개발되며 안정화되었기 때문에, 결과적으로 특별히 문제가 되지 않았습니다.
(23년 1월에 공식 릴리즈되었지만, 글 작성 시점 현재는 3.9.0 버전입니다)
Vue는 2 버전과 3 버전 간의 차이가 꽤 크다는 점 때문에라도, Vue 3를 선택할 수밖에 없기도 합니다.
대표적으로 TypeScript 지원 여부에서 차이가 있는데, 2 버전에서도 사용이 가능하기는 하지만 불완전합니다. 공식 문서에 의하면, TypeScript를 억지로 지원하기 위해 매우 비효율적인 방법으로 타입 시스템을 구현했기 때문에 오버헤드가 수반되어 성능상 손해가 있다고 설명하고 있습니다.
반면 3 버전에서는 TypeScript 지원을 위해 코드베이스를 크게 개선했기 때문에 완전히 네이티브로 도입할 수 있게 되었으며, 컴패니언/서포트 플러그인인 Volar 또한 TypeScript 지원 및 성능 측면에서 진보해 Vetur 대비 전반적인 개발 환경이 개선되었습니다.
그러는 한편 Composition API를 사용해야 한다는 이유도 있었습니다. 컴포넌트 작성에 활용되는 일련의 API 집합으로, React의 Hook과 유사한 개념입니다. Vue 3를 대표하는 특징이자 변경점이기도 한데, 코드 스타일 및 개발 패러다임 레벨에서 중대한 영향을 미치는 부분이므로 구태여 과거를 답습할 필요는 없었습니다.
Vue 2의 경우 Options API로 컴포넌트를 작성했는데(Vue 3에서도 계속 사용이 가능하긴 합니다), 코드가 장황하고 파편화되기 쉬우며 재사용성이 떨어지는 문제가 있어 유지보수성을 중요한 판단 기준으로 삼았던 만큼 중대한 결점이라고 보았습니다. React에서 더 이상 클래스 컴포넌트를 사용하지 않고 함수 컴포넌트를 사용하게 된 것과 거의 같은 맥락이라고도 할 수 있는데, 과거 버전의 React 개발 경험이 있다면 조금 더 직접적으로 이해하실 수 있을 것입니다.
마찬가지로
Vue 3에서 공통 함수의 형태로 캡슐화를 구현하는Composables역시React의Custom Hooks에 빗댈 수 있습니다.
그밖에도Portal과Teleport,<Suspense>와<Suspense>,Context API와Provide/Inject등, 사실상 서로 거의 동일한 범주에 속하는 경우가 많습니다.
이외에도 번들러로 webpack이 아닌 Vite를 공식 채택하고 있다는 점도 중요한 부분이었습니다(다만 역시 webpack도 사용하려면 할 수는 있습니다). 많은 개선이 이루어졌다고는 하지만, webpack의 빌드 퍼포먼스 문제는 항상 언급되는 문제이거니와 Vite가 이러한 부분에서 확실한 비교 우위를 점하고 있기에, 실제로 마이그레이션 사례나 사용량이 증가하고 있는 상황이기도 합니다.
프로젝트의 코드베이스 규모가 작은 편이었기 때문에 드라마틱한 정도는 아니었지만, 실제로 webpack 대비 Vite가 빌드나 HMR 퍼포먼스가 더 뛰어나다는 것은 체감상으로나, 실제 측정 결과로나 명확하게 증명이 가능한 부분이었습니다.

렌더링 성능(Virtual DOM) 또한 향상되었는데, 이전에는 거의 최적화가 이루어지지 못했지만 3 버전에서는 오버헤드를 줄이고 컴파일 타임 최적화를 적극 수행한다고 알려져 있습니다.
마지막으로는 장점이나 단점으로 보기엔 모호한 부분이긴 합니다만, 상태 관리 라이브러리의 선택 문제에서 React 대비 단순하다는 점이 있습니다. Vue 3 프로젝트에서는 Pinia라는 라이브러리를 사용하는데, store를 정의하는 것이 Composition API의 setup() 함수를 작성하는 것과 동일한 형태여서 직관적이고 간결합니다.
전신인 Vuex와 대비해서도 보일러플레이트 코드가 대폭 감소한데다, 중앙화된 단일 store 구조가 아니라 여러 store를 정의하고 필요한 것만 컴포넌트에서 가져와 사용하는 방식이어서 코드 스플리팅에서도 유리하게 작용하는 등의 강점이 있습니다.
반면 React에서는, 상태 관리라는 담론에 접근함에 있어 Redux를 위시한 다양한 수단과 방법이 존재합니다. 잘 알려진 도구들이 많이 있어 선택의 여지가 많고 여러 패러다임을 구현해볼 수 있습니다만, 아무래도 미숙한 개발자 입장에서는 복잡하다는 측면도 있기 때문에 Vue와 비교한다면 약간의 진입장벽 차이는 존재한다고 볼 수 있습니다.
React(Next) vs Vue(Nuxt)

하지만 근본적으로 이런 의문이 들 수도 있을 것입니다. '왜 React 놔두고 Vue를 쓰냐'는 것입니다.
많은 사람들이 소위 'VS 놀이'를 좋아하는 것처럼 개발자들 역시 기술과 도구를 두고 어느 것이 더 우월하네 아니네 논쟁하는 경우가 흔합니다만, 사실 이러한 논쟁은 의외로 그다지 생산적이지 않거나 소모적인 경우도 많습니다. 실제로 이는 개발자, 엔지니어들이 기술에 매몰된 나머지 정작 비즈니스를 간과하는 경우가 많다는 식으로 비판적인 담론이 발생하는 지점이기도 합니다.
닳고 닳은 이야기지만, 여하튼 중요한 것은 현재 처한 환경에서 무엇이 필요하고 어떠한 문제를 해결할 수 있는지를 고려하면서 기술을 선택하는 것이 바람직하다는 사실입니다.
다만, 필자 역시 이 지점에서 여러모로 많은 고민이 되었던 것은 사실이어서, 동료들과 많은 논의를 거쳤고 결국 아래와 같은 이유에서 Vue를 선택할 수 있겠다는 판단을 할 수 있었습니다.
- 개발 조직의 특성상 마크업 개발자(퍼블리셔) 포지션이 존재하는 환경이었습니다. 완성된 HTML을 넘겨받으면 이를 프론트엔드 개발자가 컴포넌트로 재작성하는 식으로 작업이 이루어지는데, 이때
React의JSX보다는Vue의Single File Component, 즉SFC구문이 아무래도 포팅에 더 유리한 형태입니다.
Vue의SFC는 이미 익숙한HTML을 기반으로 한 확장 구문의 형태로 템플릿을 작성하고 컴파일하는 식입니다. 반면JSX는 템플릿 언어가 아닌JavaScript이므로, 상대적으로 조금 더 번거롭게 작용하는 측면이 있습니다. Vue의 코드는React에 비해 상대적으로 Right way, 하나의 올바른 답을 제시하는 성향을 띱니다. 조금 더 예측 가능하고 균일한 품질의 코드를 작성할 수 있다는 것은 팀원들의 역량이나 숙련도 격차를 보정할 수 있음을 의미했고, 그동안 코드 퀄리티가 엄격하게 통제되지 않는 경향이 있었기 때문에 상대적으로 나쁜 코드를 작성하기 쉬운React는 문제를 재생산할 수 있겠다는 합의가 있었습니다.- 반응성(Reactivity)을 구현하는 패러다임의 차이로 인한 코드의 직관성의 차이가 존재합니다.
React는 엄격한 불변성을 전제로 한 비교로 반응성을 구현하는 반면,Vue는JavaScript의Proxy를 통해 객체의 변경을 감지하고 작업을 가로채(인터셉트) 동작을 재정의하여 반응성을 구현합니다.
불변성 패러다임은 코드를 다소 장황하고 복잡하게 만드는 측면이 있습니다.Immer같은 도구를 활용하여 문제를 한결 개선할 수는 있긴 하지만, 어쨌든React에서 유독 부각되는 부분이기도 합니다.
또한useMemo와useCallback으로 대표되는, 렌더링 최적화에서 인지 부하를 발생시키고 실수의 여지를 만든다는 문제도 있습니다. 언제 사용하고 사용하지 않아야 하는지조차 모호한 측면이 있는데, 많은 개발자들은 이를 적재적소에 사용하지 못했다는 이유로 '최적화도 못 하는 실력 없는 개발자'라며 자책하는 촌극까지 벌어지기도 합니다.
하지만 이러한 문제 - 렌더링 사이클의 마이크로 컨트롤 이슈 같은 것은 애초에 다른 프론트엔드 프레임워크들에서는 고민할 필요조차 없거나 사소한 문제고, 그나마도 더 간단한 규칙과 더 적은 코드로, 심지어 더 나은 성능으로 잘 처리되고 있는 것이 사실입니다.
그래서React에서도React Compiler(React Forget)를 개발하여 이러한 메모이제이션을 컴파일 단계에서 자동화하여 DX의 개선을 꾀하려고 하는 것인데, 이는 이 문제가 실제로React의 대표적인 결점으로 지적되어 왔던 것이기 때문이기도 합니다.
한편Vue는 종속성을 자체적으로 추적, 최적화하여 필요한 경우에만 컴포넌트가 리렌더링되도록 제어합니다.Composition API에서setup()함수는 한 번만 호출되기 때문에 리렌더링 이슈가 차단되고, 명시적으로 종속성 배열을 정확하게 선언하고 전달하지 않으면 문제가 되는React의useEffect와 대비해 코드도 조금 더 유연하고 단순해집니다.
Vue가 굳이 불변성을 고집하지 않는다는 것은, 곧 함수형 프로그래밍 패러다임 측면에서도React와는 스탠스가 다르다고 볼 수 있는 부분입니다. 물론 불변성은 함수형 프로그래밍의 필요조건이 아니고,Vue역시 의도하기에 따라 불변성을 구현할 수는 있습니다만, 일단Vue의 공식 문서에서도 반응성에 대해 이야기할 때 이러한 토픽을 함께 언급하고 있습니다. - 개발 조직 내 다른 팀들의 경우에도, 대개 비슷한 비율로
React와Vue를 환경과 필요에 따라 취사선택하여 사용하고 있었기 때문에 굳이 어떠한 통일성이 요구되었던 것도 아니었습니다. - 당연한 이야기이지만, 프론트엔드 프레임워크가
React와Vue만 존재하는 것은 아닙니다. 가령 개인적인 취향이나 DX를 고려했다면Svelte도 훌륭한 선택지였을 것입니다. 그러나 처음부터 마치React와Vue만 존재하는 것처럼 전제하고 이야기하고 있는 것은, 이것이 개인 프로젝트가 아닌 회사의 프로젝트였기 때문입니다. 실제로 조직 차원에서는 '개발자 수급'과 같은 채용의 문제를 고려하기도 했으므로, 현실적인 차원에서도 고민이 필요했습니다.
생태계 문제
이후 본격적으로 개발을 진행하는 과정에서 종종 문제를 겪은 사례도 있었습니다. 대체로는 Vue의 생태계 규모나 Nuxt의 안정성의 차이에서 비롯되는 문제였습니다.
- 트러블슈팅시 관련 사례나 정보를 찾다 보면
React나Next에 비해서는 레퍼런스를 찾기가 상대적으로 어려운 편이었습니다.Vue문제라면 괜찮은데,Nuxt같은 경우는 이제 막 Stable 버전을 출시하던 시기였기 때문에, GitHub 저장소의 이슈 섹션 정도가 거의 유일한 창구였습니다. - 프레임워크의 릴리즈가 워낙 빠른 호흡으로 진행되다 보니 간혹 알 수 없는 부분에서 충돌이 발생하거나, 다른 라이브러리가 이를 제때 따라가지 못해 에러가 나는 경우도 있었습니다. 일례로
eslint-plugin-nuxt의 경우에는 빌드 에러를 유발하는 문제가 있었어서 해결될 때까지 잠시 비활성화해야 했던 적이 있었습니다. 대부분 마이너한 문제이긴 했지만 흐름을 방해하는 원인이 되었습니다. - 지엽적인 문제이긴 하지만,
Composition API에서props를 선언할 때 사용하는defineProps()함수에서 외부에서 import한 타입을 참조할 수 없는 문제가 있었던 것인데,Vue의 내부적인 매커니즘에 따른 문제였어서 3.3 버전에서 해결되긴 했습니다만 그 전까지는props에 한해 타입 선언을 컴포넌트 내부(로컬)에서 해야 한다는 불편함이 있었습니다. Nuxt 3에서는 기본적으로 데이터 페칭에ohmyfetch(ofetch)라는 라이브러리를 사용합니다. 기본적으로 네이티브Fetch API스펙을 확장하는 형태이긴 하지만 약간 어색하게 다가올 수 있는 부분입니다.Next에서는 이미지 최적화에 아주 유용하게 활용되는next/image빌트인 컴포넌트가 제공되지만,Nuxt에서는 한동안 이런 것이 없다가 비교적 최근 3.8.0 버전에서Nuxt Image라는 유사한 컴포넌트가 제공되기 시작했습니다.
이외에도 웹폰트 등 프레임워크 최적화 기능들은 대부분Next에 있으면Nuxt에도 있거나 금방 개발되는 식이기는 하지만, 아무래도 약간의 간극은 존재합니다.- 포팅이 불완전하다거나 지원이 더딘 도구가 소수 존재했습니다. 가령
GraphQL과 연동하기 위한Nuxt Apollo같은 경우는 문서의 정보가 다소 부족하고 유지보수도 활발하진 않은데, 사용엔 문제가 없으나 여전히 alpha(v5), rc(v4) 버전에 머물러 있는 상황입니다.
한편 이번 프로젝트에서는 사용되지 않았지만,Vue생태계에서의 대표적인 UI 프레임워크인Vuetify의 경우Vue 3와Nuxt 3를 공식적으로 지원하는 시기가 상당히 더뎠는데(22년 10월), 이러한 코어 라이브러리/플러그인의 지원조차 불안정하다는 점에서Vue생태계가 부실한 것이 아니냐는 우려가 제기되기도 하였습니다.
당연한 말이기는 하지만, 결과적으로 통상적으로 개발에 필요한, 널리 알려진 도구는 대부분 문제 없이 사용이 가능했습니다. 따지고 보면 어떤 쪽이든 그렇게 대단한 차이가 있는 것도 아니어서, 피처 구현에 있어 걸림돌이 된다거나 불편함을 겪지는 않았습니다. 아래 이미지처럼 웬만한 도구들은 프레임워크 레벨에서 내장 모듈로도 지원하고 있고, 심리스한 활용에 문제가 없었습니다.
특히 관용적인 유틸리티 개발 공수를 극적으로 줄여주는 VueUse 같은 경우 Vue 프로젝트에서는 거의 Lodash와 같은 위상과 활용성을 가지는데, 이 역시 별다른 이슈 없이 유용하게 활용할 수 있었습니다.
참고로
React에서도 거의 비슷한 라이브러리인useHooks가 존재하니, 꼭 사용해보시길 추천드립니다.
프로젝트의 확장, 고민의 지점들
사실 개발하는 페이지 자체만 놓고 본다면, 그다지 복잡하다거나 특이할 건 없었어서 특별히 난도가 높다거나 어려운 기술이 필요한 것은 아니었습니다. 하지만 프로젝트 전체를 놓고 보면 그 과정이 지난했는데, 프로젝트가 진행되면서 점점 규모가 확장되었던 것도 있고, 궁극적으로는 이것이 단순히 한두 명의 개발자가 열심히 개발만 한다고 해서 되는 일이 아니었기 때문이었습니다.
Backend For Frontend, BFF
기존의 프로젝트는 먼 과거에 개발된 것이었던 만큼, 아직 백엔드 관심사가 완전히 분리되지 않은 형태였습니다. 정확하게는 서버 사이드 템플릿 엔진, PHP와 JSP 기반의 프로젝트였으므로 백엔드 로직이 병존하고 있었습니다.
때문에 기존의 비즈니스 로직들을 어떤 방식으로 다시 구현하느냐를 결정해야 했는데, Nuxt는 풀스택 프레임워크인 만큼 자체 웹 서버에서 구현되는 Server API를 활용하면 과거의 코드를 비슷하게 이식하는 식으로 기존의 매커니즘을 재현할 수 있었습니다.
하지만, 이래서야 결국 근본적으로 이전과 달라진 것이 무엇이냐는 생각이 들었습니다. 백엔드 관심사를 완전히 분리해내 순수히 프론트엔드 포지션의 역할을 재정립할 필요가 있었습니다.
그래서 결국 Backend For Frontend(BFF) API 서버를 구축하는 프로젝트까지 확장/연계하기에 이르렀는데, 문제는 그동안 수많은 정책들과 요구사항들이 복잡하게 얽히고설킨 비즈니스 로직을 다시 풀어내어 해석하고, 이것을 BFF로 옮겨내는 일이 굉장히 어려웠다는 것입니다.
처음의 생각대로 필자가 직접 Server API를 구현하는 경우였다면, 도메인에 대한 이해나 기반 지식이 있으니 그렇게까지 난감한 일이 아니었을지도 모릅니다. 하지만 BFF는 다른 챕터의 백엔드 개발자에게 도메인 지식을 설명하고 맥락의 전반을 완전히 이해시키는 과정이 선행되어야만 했고, 협업이라는 것은 어쨌든 커뮤니케이션이라는 비용이 발생하는 행위여서 개발 속도가 크게 더뎌지게 되었습니다.
게다가 이렇게 API가 병렬적으로 개발되는 경우 프론트엔드에서는 필연적으로 겪게 되는 이슈가 있는데, 바로 'API 언제 나와요?' 입니다. 이렇게 되면 API 개발 작업에 대한 종속성/의존성을 낮추기 위해, API가 실제로 존재하는 것처럼 가장하여 데이터를 받는 Mocking의 필요성이 두드러지게 됩니다. 다만 이 역시 추가적인 공수가 소요되는 일이고, Mock 데이터를 하드코딩하다 보면 소스가 지저분해지고 관리가 어렵게 되기도 합니다. 그러다 API 개발이 완료되면 다시 그 스펙에 맞게 일정 부분 로직을 수정해야 하는 등, 여러모로 DX에는 악영향이 발생하게 됩니다.

때문에 이 문제를 효율적으로 해결할 방법이 없을까 고민했고, 타사의 테크 블로그 아티클 등을 참고하다가 Mock Service Worker(MSW) 라이브러리를 활용하는 방법에 대한 인사이트를 얻어 이를 활용하였습니다. MSW는 Service Worker를 통해 네트워크 레벨에서 HTTP 요청을 가로채 Mocking을 구현하므로, 로직의 수정이나 별도의 서버가 필요하지 않은 장점이 있고 사용법도 크게 어렵지 않아 유용하게 활용할 수 있었습니다.
한편, BFF도 새롭게 시작하는 프로젝트였던 만큼 많은 개선이 있었습니다. 현재 서비스를 구성하는 여러 API 서버들 역시 많은 부채가 누적된 레거시 Spring 프로젝트였으나, 이번 BFF는 완전히 새로운 아키텍처로 재설계하여 Spring Boot로 다시 개발되었습니다. 또한 여기에 GraphQL이 더해지면서, 프론트엔드의 입장에서는 Over/Under Fetching 문제를 완화하여 이전 대비 '화면에 필요한 데이터만 받기'에 용이해졌다거나, 굳이 Swagger를 매개로 커뮤니케이션할 필요가 없어졌다는 점(상대적으로 더 직관적이므로)도 큰 성과였습니다.
Storybook

한편, 이왕이면 Storybook도 도입하자는 의견이 모아지기도 하였습니다. 문제는 이 역시 또 하나의 프로젝트로 분리해야 할 정도로 간단하지는 않은 작업이었다는 것입니다.
위에서 잠깐 언급한 바 있듯, 필자의 개발 조직은 마크업 개발자(퍼블리셔)가 독립 분리되어 있는 환경이었으므로 자연스럽게 협업을 통해 프로젝트를 연계하게 되었습니다.
핵심 목적은 체계적으로 컴포넌트를 문서화하여 생산성을 향상시키자는 것이었으며, 여기에 더해 가능하면 기존의 마크업도 다 갈아엎어서 그동안 다소 미진했던 웹 접근성을 고려한 형태로 다시 작성하는 것까지 고려되었습니다.
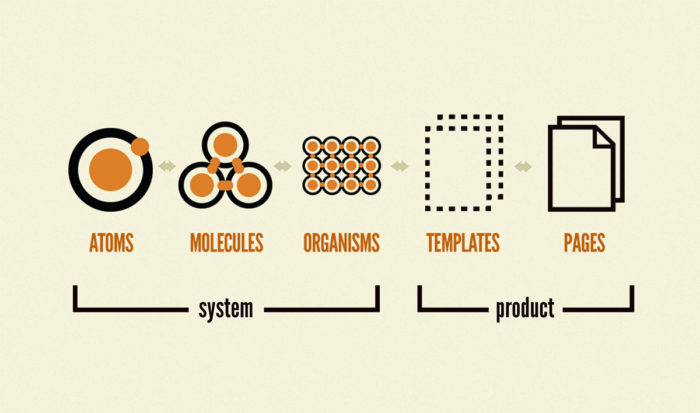
이 과정에서 주로 고민이 되었던 지점은 아무래도 역시 '어떤 기준으로 컴포넌트를 분리할 것인가?' 였습니다. 많은 경우 Atomic Design이라는 방법론을 따른다곤 하지만, 막상 일반적인 기대처럼 어느 상황에서나 적확한 가이드라인이 되어 주는 것은 아닌데, 이 역시 어디까지나 추상적인 측면이 있는 멘탈 모델이기 때문입니다. 그렇기에 결국은 그 때마다 고민과 합의가 필요하게 됩니다.
개발자 각자가 생각하기에 컴포넌트를 분리하는 '의미 있는 기준'이 같을 수 없고, '성격이 비슷한' 컴포넌트끼리 묶으면 된다고 하지만 이는 어디까지나 직감일 뿐입니다. 그래서 명확한 기준을 정립하고자 Atom, Molecule, Organism, Template, Page 라는 요소를 도입하는 것입니다만, 그럼에도 불구하고 '얘는 어디에 들어가야 하지?' 같은 의문은 여전히 발생하게 됩니다.
이것이 경험의 부족이나 미숙함에서 비롯된 것일 수 있지만, 어쨌든 결국 추가적인 커뮤니케이션 비용으로 개발 속도가 또 다시 느려지게 되는 원인이 됩니다. 의견을 모으고 기준을 확립하는 시간이 필요하기 때문입니다. 그렇다고 이렇게 모호함이 발생하는 포인트에서 명확한 협의 없이 적당히 넘어가서 아무렇게나 작업하게 될 경우, 컴포넌트의 의미가 무색해질 만큼 재사용성이나 확장성이 낮아지는 문제가 발생해서 부채로 되돌아오고, 나아가서는 Storybook을 도입한 메리트 자체가 희석될 수 있습니다.
그래서 이 시점에 이르렀을 즈음에는, 무조건 원칙대로 구현하고 계획한 것을 전부 다 실행하려는 '욕심'을 조금 덜어낼 필요가 있겠다는 생각도 들었습니다. 즉, '할 수 있는 것과 할 수 없는 것'을 명확히 구분하고, 유연하게 변주하고 타협하는 능력도 중요하다는 것을 알게 되었습니다.
Deployment

어느 정도 구현이 진행된 이후에는, 나중에 실제 운영되는 상황을 고려해 배포를 고민해야 했습니다. 당시 사내에 일종의 테스트베드 성격으로 구축된 k8s 플랫폼이 존재했는데, Deployment를 구성하는 과정에서 일단은 설정을 간단하게 가져갔기 때문에 Default 배포 전략인 RollingUpdate 방식으로 배포되도록 했습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: search
name: nuxt-search-deployment
labels:
app: nuxt-search
spec:
replicas: 4
selector:
matchLabels:
app: nuxt-search
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 50%
maxUnavailable: 25%
template:
# ...다만 역시 RollingUpdate 방식은 순차적으로 새로운 버전으로 하나씩 교체되는 방식이기 때문에, 만약 이전 서버에 요청이 전달되었고 이때 어떤 중대한 변경사항(API 스펙이 변경되었다거나)이 있었다면 에러가 발생할 것이므로 문제가 될 수 있겠다고 보았습니다.
게다가 이때, 이전 서버를 다운시키려는 순간 아직 사용자의 요청을 처리하고 있는 도중이었다면 모든 작업이 완전히 마무리될 때까지 기다린 다음에 다운되어야 하는데, 이것을 구체적으로 어떻게 구현해야 할지 방법이 마땅치 않았습니다. Pod가 종료되기 전 일정 시간만큼 대기하는 terminationGracePeriodSeconds 같은 옵션이 있긴 하지만, 단순히 일정 시간을 유예한다고 되는 것이 아니라 지금 종료되어도 완벽히 안전한지 여부를 확인하는 것이 중요한 문제이기 때문입니다. 또 만약 이슈가 있어 롤백이라도 해야 하는 경우까지 고려하면 문제가 더 복잡해졌습니다.
결국 완전한 zero-downtime, 무중단 배포 구현의 문제였던 것인데, 핵심은 쿠버네티스로부터 SIGTERM/SIGINT 시그널을 받았을 때 Nuxt 인스턴스에서 이를 후킹하고, 이미 인입된 요청들은 정상적으로 모두 완료하여 커넥션 등의 정리가 완전히 끝난 다음에 종료되도록 하는 destroy/termination 로직으로 Graceful Shutdown을 구현하는 것이었습니다. 이러한 토픽 자체는 꽤나 흔한 것이어서 관련 자료는 많이 찾아볼 수 있었지만(가령 SvelteKit의 공식 문서에서는 이에 대해 잘 설명하고 있습니다), 필자의 경우에는 프로세스 매니저인 PM2 문서와 Nuxt의 공식 문서 등을 참고해 보아도 직접 커스텀으로 구현하려니 잘 되지 않아 어려움을 겪었습니다.
그러다 이후 내부적인 문제로 k8s 플랫폼을 내리게 되어 더 이상 활용할 수 없게 되었는데, 이에 따라 Docker로 다시 배포를 구성하는 과정에서 RollingUpdate 전략을 폐기하고 Blue/Green 방식을 구현해보기로 하였습니다.
docker compose를 활용한 무중단 배포는 Graceful Shutdown 이라는 토픽에 접근하기가 상대적으로 용이했습니다. 사내 DevOps 플랫폼으로 GitLab을 사용하고 있었기 때문에, 여기에서 사용할 CI 스크립트와 배포 스크립트를 새로 작성해야 하기는 했지만 딱히 많은 작업이 필요하지는 않았습니다. 배포 과정이나 방법까지 이 글에서 구체적으로 설명하기에는 부적절하니, 프로세스만 간단히 나열해 보자면 아래와 같습니다.
- GitLab(Runner)에서는 Docker 이미지를 빌드 및 태그하고, 레지스트리에 푸시합니다.
- SSH로 원격 서버에 접근하여 배포 스크립트를 실행합니다.
- 레지스트리에서 최신 이미지를 가져오고, 새로운 컨테이너(
Green)를 생성합니다.- 헬스 체크를 수행합니다. 사전에
Nuxt의Server API에서 헬스 체크 API 엔드포인트를 구현해 놓은 상태입니다.- 헬스 체크에 성공하면 웹 서버인
nginx의 conf를 수정하여service_url이 새로운 컨테이너(Green)를 바라보게 한 다음,reload를 통해 변경된 설정을 반영하면서 트래픽을 스위칭합니다.- 이전 컨테이너(
Blue)는 롤백에 대비하여 대기하고, 문제가 없으면 제거합니다.- 빌드 과정에서 생성된 이전 컨테이너의
dangling이미지를 정리합니다.
nginx의 공식 문서에 따르면, 설정 파일을 다시 읽고 reload 동작을 통해 변경 사항을 반영할 때 Graceful Shutdown을 구현한다고 설명하고 있습니다.
Changing Configuration
In order for nginx to re-read the configuration file, a HUP signal should be sent to the master process. The master process first checks the syntax validity, then tries to apply new configuration, that is, to open log files and new listen sockets. If this fails, it rolls back changes and continues to work with old configuration. If this succeeds, it starts new worker processes, and sends messages to old worker processes requesting them to shut down gracefully. Old worker processes close listen sockets and continue to service old clients. After all clients are serviced, old worker processes are shut down.
그래서 정말 그런지 확인해보기 위해 Server API에 약간 시간이 소요되는 작업을 만들고, 이 엔드포인트에 요청을 지속적으로 다수 발생시키는 상황에서 배포를 실행해보는 식으로 간단히 검증해 보았는데, 특별히 문제가 발생하지 않음을 확인할 수 있었습니다.
다만 이와 관련하여 다른 개발자 분들의 사례 등을 통해 파악해 본 바에 따르면, 이러한 방식 또한 완벽히 안전하지는 않을 수 있다고 하여 추가적인 검증 및 연구가 필요한 부분으로 남았습니다.
마치며
무엇을 얻었나
가장 큰 성과는 회사의 코어 프로덕트 영역에서 기술 부채를 청산하는 프로젝트를 주도적으로 수행했다는 것입니다. 그동안은 '업무가 너무 많아서', '개발자가 없어서', '회사가 의지가 부족해서' 같은 이유로 누구도 달리는 기차의 바퀴를 갈아끼울 엄두를 내지 못했던 상황이었습니다.
비록 많은 시간이 소요되었고 이후로도 막대한 리소스가 투입되어야 하겠지만, 더 늦기 전에 변화를 시도했다는 점에서 엔지니어로서의 성취감을 얻을 수 있었습니다.
가령 BFF 서버 같은 경우, 당장은 이번 프로젝트와 관련해서만 기능할 목적으로 작게 개발되었지만, 장기적으로는 프로덕트 전반에 걸쳐 활용될 것이므로 아키텍처 개선에 기여할 수 있을 것입니다.
개인적인 성장의 측면에서도 긍정적인데, 아무래도 단편적으로 비즈니스 피처를 루틴하게 개발해 왔던 유지보수 업무와 비교하면, 다시 원점에서부터 프로덕트를 온전히 다시 개발하는 데에서 비롯되는 경험의 수준이 더 높았습니다.
서비스의 엔드포인트에 위치하는 프론트엔드 포지션의 특성상 그동안의 업무 과정에서도 다양한 직군과의 협업이 이루어지긴 했었지만, 이번 프로젝트에서는 특히 개발자들과 밀접한 커뮤니케이션이 이루어지면서 순수하고 심도 있는 기술 논의를 할 수 있는 기회가 많았기 때문에 지적 충족감을 얻을 수 있었습니다.
한편, 새로운 개발자의 유입에도 긍정적인 영향이 있을 것입니다. 분명 레거시는 무조건 '악'은 아니지만, 그럼에도 불구하고 많은 개발자들이 레거시를 기피하거나 달가워하지 않는 것은, 그것이 동시대를 살아가지 못함을 의미하고, 많은 경우 개인의 커리어 성장에도 악영향을 미치기 때문일 것입니다.
다만, 이렇게 '레거시'에 대해 논할 때는 소모적인 논쟁을 방지하기 위해 정확한 기준이 필요할 수 있습니다. 구체적인 기준점을 어떻게 정하느냐에 따라 당장 어제 작성한 코드도 레거시가 될 수 있기 때문입니다. 이미 문맥상 드러나고 있었긴 하지만, 이 글에서는 레거시를 '과거
jQuery시절의 프로젝트'와 '모던 프론트엔드 스택을 주요하게 활용한 프로젝트'를 구분하는 맥락에서 사용하였습니다.
온보딩에 대한 우려도 한결 줄어들었습니다. 기존의 레거시에 비하면 코드의 가독성이 드라마틱하게 개선되었고, 여러 유용한 도구들이 많이 도입된 만큼 업무 효율성이나 생산성이 높아질 수 있게 되었으며, 그동안 유실된 히스토리를 복원하고 기획자와의 협의를 통해 기능 및 정책을 재설계, 재검토하여 일정 부분 문서화하였기 때문에 새로운 동료가 합류하더라도 더 쉽게 적응할 수 있을 것입니다.
무엇이 부족했나
경험의 부족에서 온 문제이자 부끄러운 부분이기도 한데, 테스트에는 많은 신경을 쓰지 못했습니다. 환경이 개선되면서(가령 Storybook을 테스팅 도구로 활용할 수 있었다던가) 그동안 구상만 하던 수단과 방법을 이전보다 쉽게 시도할 수 있게 되었지만, 막상 그다지 테스트 코드를 작성하거나 활용하지는 못했습니다.
일정 관리에 미숙했다는 점도 부족한 점으로 꼽을 수 있을 것입니다. 사실 이번 프로젝트는 특이하게도 명시적인 데드라인이 존재하지 않았습니다. 상위 조직에서도 특별히 언제까지 결과물을 산출해야 한다는 지시나 요구, 합의가 없었던 것입니다. 그렇기 때문에 내부적으로 마일스톤을 설정하고 느슨한 템포로 진행했던 데다, 그마저도 수시로 변경되거나 홀드 상태가 되기도 했습니다.
이는 필자를 포함해 프로젝트를 전담하는 인원들을 별도로 분리, 리소스를 할당하여 진행한 것이 아니라, 여전히 기존의 프로덕트를 위한 루틴 업무를 병행하면서 프로젝트를 진행해야 했던 조직의 상황/환경의 특성에서 비롯된 것이기도 합니다. 게다가 그런 와중에도 기존 프로덕트에서는 끊임없이 스펙이 추가되고 있다 보니, 이것을 똑같이 새로 구현해야 해서 결과적으로는 이중 작업이 수반되었습니다. 그로 인해 컨텍스트 스위칭도 빈번하게 발생한 것은 물론 효율도 크게 낮아졌습니다.
또한 '새로 만드는 김에 우리도...' 같은 식으로 다른 챕터의 프로젝트와 중도에 연계되고 확장되면서, 일정과 리소스가 얼마나 필요한지를 점점 예측하기에 어려워졌다는 점도 일정이 불분명하게 늘어지는 데 영향을 미쳤습니다.
그래서 결과적으로는 프로젝트의 규모나 애플리케이션의 복잡도 등에 비해서는 과도한 시간이 소요되었고, 일부는 중도에 흐지부지된 작업도 있어 여러모로 큰 아쉬움으로 남게 되었습니다.
