
60만건의 유실물 데이터를 내용으로 검색할 때, 프론트에서 가끔 응답 시간이 너무 오래 걸린다는 피드백을 받고 성능을 올려보기로 했다.
1. 성능 하락 원인 파악
기존 쿼리 성능
select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%' # 4.7
order by created_at desc
limit 10 offset 10000; // 4.7MySQl 책을 읽기전에는, limit 과 offset 를 걸었지만 실행계획을 봤을 때 테이블 풀 스캔이 일어난 이유가 무엇인지 이해가 안됐었다.
우선, 60만건 기준으로 아래 방법으로 각 조건에 대해 측정해보자.
측정하는 방법
SET PROFILING=1;
SET PROFILING_HISTORY_SIZE=30;
SHOW profiles;1. 아무런 조건이 없을 때
select * from tb_lost_post;특정 범위가 주어진 것도 아니기 때문에 클러스터링 인덱스로 조회되지 못하고, 풀 테이블 스캔이 일어난다. 풀 테이블 스캔은 랜덤 I/O 가 아닌 순차 I/O 방식이므로, 디스크 헤더를 한번만 움직이고 쭉 읽으면 되므로 생각보다 많은 데이터에도 빠른 성능을 보여준다.
실제로 테스트해보면 0.02s 정도로 측정되었다.


🫧 풀 테이블 스캔이 일어나는 조건
- 테이블 레코드 건수가 너무 작아 페이지
1개로 구성되는 경우, 인덱스를 통해 읽는 것보다 풀 테이블 스캔이 빠르다. WHERE절이나ON절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우- 인덱스 레인지 스캔을 사용할 수 있어도, 조건이 일치하는 레코드 건수가 너무 많다면 풀 테이블 스캔이 빠르다. 1개 기준으로 인덱스가
4-5배 정도 느리기 때문이다.
따라서 위에서는 2 번 조건에 의해 풀 테이블 스캔이 일어났을 것이다.
추가적으로 만약에 * 가 아니고 count(*) 를 쓴다면, 인덱스가 사용되므로 훨씬 더 높은 성능을 보여준다.
select count(*) from tb_lost_post;
2. 아무런 조건이 없을 때 + 페이징 적용
다음으로 페이징을 적용해보자.
select * from tb_lost_post
limit 10 offset 0;
성능이 갑자기 엄청 빨라졌다! 왜 이런 현상이 발생한 것일까?
MYSQL은 두 가지 방식으로 쿼리가 처리되는데, 스트리밍과 버퍼링 방식이다.
스트리밍 처리 방식
서버 쪽에서 처리할 데이터가 어느정도 되는지에 관계없이, 조건에 일치하는 레코드가 검색될 때 마다 바로 클라이언트로 전송하므로 매우 빠른 응답 시간을 보장한다.
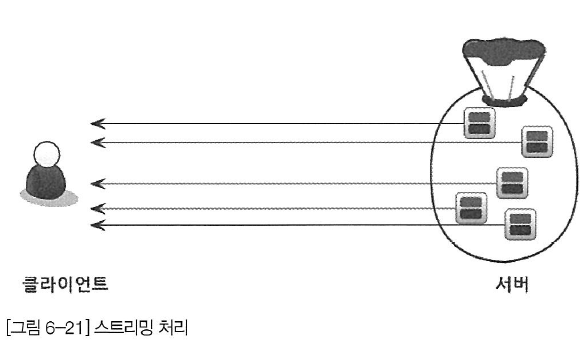
주로 인덱스를 사용해 정렬을 할 때 스트리밍 방식으로 처리된다. limit 가 없어도 스캔의 결과가 아무런 버퍼링 처리나 필터링 과정 없이 바로 클라이언트로 전송되기에 빠르다.
하지만 여기에 limit 까지 붙이면 클라이언트에 바로바로 반환을 하기에 개수를 충족하는 순간 바로 동작을 멈추기 때문에 매우 빨라진다.
버퍼링 처링 방식
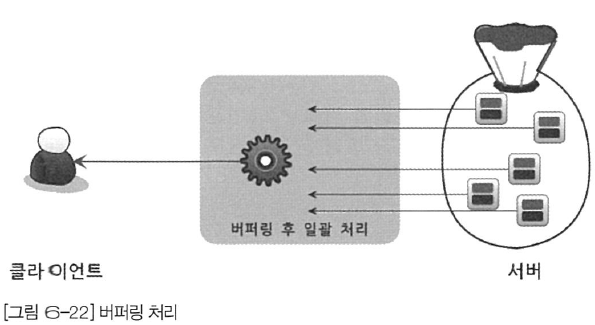
ORDER BY 나 GROUP BY 조건이 들어가있다면 스트리밍 방식을 사용할 수 없다.
우선 WHERE 조건에 일치하는 레코드를 모두 가져온 이후 정렬하거나 그루핑하는 과정이 일어나야 하기 때문인데, 결국 클라이언트로 응답 속도가 매우 늦어진다.
따라서 해당 방식은
limit로 결과 건수를 제한해도, 네트워크로 전송되는 레코드의 건수만 줄일 뿐 MySQL 작업의 성능 향상에는 효과가 크지 않다.
결론적으로 앞에서는 정렬이나 그룹핑 조건이 없었고, 이로 인해 스트리밍 처리 방식이 적용되어서 속도가 엄청 빨라진것으로 볼 수 있다.
3. WHERE 조건 + 페이징 적용
where 조건이 인덱스를 타기만 한다면, 위에서와 큰 차이는 없다.
select * from tb_lost_post
where lost_post_id < 10000; 
select * from tb_lost_post
where lost_post_id < 10000
limit 10 offset 0;
3. 정렬 조건이 붙을 경우
그렇다면 실제로 이제 정렬 조건을 붙여보자. 현재 created_at 필드에는 인덱스를 생성하지 않았다.
select * from tb_lost_post
order by created_at desc;정렬 조건이 붙었더니, 시간이 5 초대로 매우 느려진 것을 볼 수 있다.

select * from tb_lost_post
order by created_at desc
limit 10 offset 0;앞에서 얘기했듯이, 혹시나 해서 페이징을 적용해도 4 초대로 큰 차이로 성능 개선 효과가 존재하지 않는다.
🫧 정렬 조건과 페이징 적용
페이징을 적용해서 레코드 건수를 줄여도, 조건에 해당하는 모든 데이터를 대상으로 최신순으로 정렬이 일어나야 하기 때문에 버퍼링 방식이 선택된다.
따라서 실행계획을 분석해보았더니, 처음 보는 Filesort 라는 방식이 사용되었다.


Q.
FileSort가 뭐지?
MySQL에서 정렬을 처리하는 방법은 크게 두가지이다.
1. 인덱스를 통해 정렬하는 방법
INSERT, UPDATE, DELETE 쿼리가 실행될 때 이미 인덱스가 정렬이 되어있으므로 별도의 작업이 필요 없이 순서대로 읽기만 하면 되서 성능이 매우 빠르다. 하지만 당연히 조회 말고 다른 변경 쿼리에 대해서는 느리고, 인덱스가 저장될 때 디스크 공간과 InnoDB 버퍼 풀을 위한 메모리가 많이 필요하다는 단점도 있다.
select * from tb_lost_post
order by lost_post_id desc
limit 10 offset 0;
위와 같은 쿼리에 대해서는, 클러스터링 인덱스에 대한 역방향 스캔이 정상적으로 적용된다. 해당 포스팅에서 말했듯이 인덱스는 정방향 스캔이 역방향 스캔보다 빠르다. 이런 경우, 아예 내림차순 인덱스 를 만드는게 나을 수도 있다.
2. FileSort를 이용하는 방법
인덱스를 이용하지 않고 MySQL 서버가 별도의 정렬 처리를 수행했다는 것을 나타낸다. 문제는 정렬을 수행하기 위해, 소트 버퍼(Sort buffer) 라고 하는 별도의 메모리 공간을 할당받는다.
하지만 할당된 범위를 벗어날 만큼 많은 데이터가 들어오는 경우 MySQL 는 정렬 레코드를 여러 조각으로 나누고, 임시 저장을 위해 디스크 공간을 사용해버린다. 결국 디스크를 왔다갔다 하면서 정렬을 하기 때문에 수많은 디스크 I/O 가 발생하고, 마지막에 각 정렬된 레코드들을 다시 병합하면서 정렬이 완료되므로 성능이 매우 느려진다.
아래는 11초가 걸리고, 그 이후에 같은 연산에 대해 이미 캐싱된 데이터로 인해 속도가 줄어들기는 한다. (하지만 여전히 너무 느리다)

4. %@% 형식의 LIKE 비교 조건이 붙을 때
select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%'
order by created_at desc
limit 10 offset 0;이제, 처음으로 돌아와서 왜 해당 쿼리가 시간이 오래 걸리는지 다시 분석해보자.
-
내용이나 제목에서 포함되는 단어를 검색해야 하는 조건이기 때문에,
%%형식의like이다. 당연히 인덱스를 사용할 수 없고 데이터를 찾기 위해 풀 테이블 스캔이 일어났다. -
1호선이 포함된 데이터만 해도10만개 정도인데 데이터가 너무 많으므로, 디스크 까지 사용해서 정렬하는fileSort가 발생했다. 따라서limit과offset은 아무 소용이 없어진다.
어떻게 해결하지?
따라서 limit 의 효과를 보려면, 정렬 기준이 인덱스를 타야 한다. 따라서 우리는
createdAt 에 인덱스를 걸던가, 정렬 기준 자체를 바꿔야 한다.
2. 해결을 위한 다양한 시도들
select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%' # 4.7
order by created_at desc
limit 10 offset = 10000; LIKE 쿼리 개선
like 을 사용하지 않고 전문 검색 인덱스, ElasticSearch 는 현재 단계에서는 오버엔지니어링이라 생각되어 제외했다.
정렬 필드에 인덱스를 도입
create INDEX idx ON tb_lost_post (created_at desc);createdAt 필드에 내림차순 인덱스를 생성해보았다.
1. offset + limit 제거
explain select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%'
order by created_at desclimit + offset 조건을 빼면, 당연히 인덱스를 사용하지 못하고 전체 데이터에서 where 조건인 1호선에 일치하는 데이터가 너무 많아 다시 filesort 가 일어나게 된다.

2. offset + limit 다시 추가
explain select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%'
order by created_at desc
limit 10 offset 10;

오! offset 과 limit 조건을 다시 넣으면 더이상 filesort 는 발생하지 않는다. 단순히 인덱스 하나 걸었을 뿐인데 성능이 무지막지하게 빨라졌으니, 왜 외부 정렬이 일어나는 것을 반드시 피해야 하는지 알겠는가?
하지만 이러한 방식은 offset 이 뒤로 갈 수록 읽는 행의 개수가 증가되어 성능이 나빠진다. 쿼리를 다음과 같이 바꿔보면 총 읽은 행이 30010 개나 되며 2 초 정도로 느려지는 것을 볼 수 있다.
오프셋은 PK 가 아니고 말그대로 몇번째 레코드인지를 나타낸다. MySQL 입장에서는 해당 몇 번째 레코드인지 줘도 실제 위치를 모르니 다시 처음부터 읽은 행을 중복으로 읽게 된다. 따라서
100000번째 데이터부터 시작해서 실제 가져올 값이10개라면,1000010개의 모든 데이터를 읽고 앞에100000개는 버리는 비효율적인 방식으로 동작한다.
explain select * from tb_lost_post
where title like '%1호선%' or content like '%1호선%'
order by created_at desc
limit 10 offset 30000;

문제는 현재 기획이 무한 스크롤 방식이 아니라 페이지 번호를 클릭해서 들어가는 방식이라, 사용자가 뒤에 있는 페이지를 클릭할수록 이처럼 성능이 느려질 수 있었다.
만약 사용자가 맨 뒤에 페이지를 클릭해버린다면? 옵티마이저는 조건의 대상이 너무 많아지게 되면 더 이상 인덱스를 사용하는 것이 효율적이라고 생각하지 않고, 그냥 풀 테이블 스캔을 하고 정렬 방법으로 FileSort 을 선택해버리는 상황이 발생할 수 있다.
따라서 오프셋 기반이 아닌, 커서 기반(no-offset) 페이지네이션을 고려해보았다.
3. no-offset 페이지네이션
select * from tb_lost_post
where created_at < timestamp('2024-01-30 21:00:00') and title like '%1호선%' or content like '%1호선%'
order by created_at desc
limit 10;결론부터 말하자면 no-offset 페이징 방식을 사용했을 때 가장 빠르고, 총 읽는 데이터가 10 개로 offset 방식 보다 훨씬 적다. 왜 limit 로 건 개수만큼만 읽을 수 있는 것일까?


페이지네이션 컬럼이 PK인 경우는 평균 4ms 정도, PK가 아닌 날짜로 바꾸면 아래와 같이 40ms 정도로 측정이 된다.

No-Offset 방식은 이미 읽은 행을 매번 중복으로 읽는 상황이 발생하지 않도록, 조회하려는 시작 부분을 인덱스로 빠르게 찾아서 매번 첫 페이지만 읽도록 하는 방식이다.
전체 레코드를 다시 읽는게 아니고, B+ Tree 를 읽기 때문에(클러스터, 넌클러스터 인덱스) 시작 지점을 바로 찾을 수 있는 것이다. 따라서 조건에 인덱스를 걸지 않는다면 커서 기반 페이지네이션을 사용하지 않는거나 마찬가지가 된다.
하지만 이는 조건이 유니크한 칼럼일 때 이야기이고, 나와 같이 조건 칼럼이 중복될 가능성이 높다면? 우리는 조건에 해당하는 온전한 데이터를 받지 못할 가능성이 높다.
조건 칼럼이 Unique 하지 않을 때
아래와 같이 우선 최신순으로 정렬된 레코드에서 1호선이 포함된 레코드만 3개씩 가져오고 싶다고 하자. 마지막으로 받은 데이터의 날짜(id = 1인 레코드 )가 2023-03-01 이므로, 다음 쿼리는 where created_at < timestamp('2023-03-01') 형태로 나가게 된다.
id = 5 created_at = 2023.03.04 1호선
id = 4 created_at = 2023.03.03 2호선 (X)
id = 2 created_at = 2023.03.02 1호선
id = 1 created_at = 2023.03.01 1호선
id = 3 created_at = 2023.03.01 1호선
id = 6 created_at = 2023.02.29 1호선
id = 7 created_at = 2023.02.29 1호선
id = 7 created_at = 2023.02.29 1호선하지만 이러면 데이터베이스 입장에서는 id=3 인 데이터를 건너뛰고 2023-02-09 날짜를 가진 id=6 부터 3개를 가져오게 된다.
물론 예시에서는 중복을 보여주기 위해 저렇게 잡았고, created_at 를 밀리초까지 기록되게 하면 중복을 피할 수 있긴 하다. 하지만 지금 내 상황과 같이 created_at 가 이미 외부에서 시간이 정해진 데이터였고, 그렇기에 중복을 피할 수가 없었다.
따라서 이런 경우, 해당 레코드를 함께 판별할 수 있는 다른 유니크한 기준이 있는지 확인해야 한다.
id = 5 unique_id = 1 created_at = 2023.03.04 1호선
id = 4 unique_id = 2 created_at = 2023.03.03 2호선 (X)
id = 2 unique_id = 3 created_at = 2023.03.02 1호선
id = 1 unique_id = 4 created_at = 2023.03.01 1호선
id = 3 unique_id = 5 created_at = 2023.03.01 1호선
id = 6 unique_id = 6 created_at = 2023.02.29 1호선
id = 7 unique_id = 7 created_at = 2023.02.29 1호선
id = 8 unique_id = 8 created_at = 2023.02.29 1호선pk인 id 나 unique_id 와 같이 또 다른 유니크 칼럼이 있다면, 조인 을 통해 위와 같은 형태를 만들어 준 이후 아래 쿼리와 같이 조회해주면 된다. 여기서는 pk를 사용해보자.
CREATE INDEX received_date_desc_idx
ON tb_lost_post (received_date DESC);explain select * from tb_lost_post
where
(received_date < timestamp('2023-11-30 09:00:00')) or
(received_date = timestamp('2023-11-30 09:00:00') and lost_post_id > 53979)
order by received_date desc, lost_post_id
limit 10;첫 번째 조건으로 인해 이전에는 누락된 id=3 레코드를 조회할 수 있고, 두 번째 조건으로 인해 2023-03-01 이전의 데이터 들까지 성공적으로 가져올 수가 있어진다. 실제 쿼리를 수행해보면 아래처럼 index를 잘 타게 되는걸 볼 수 있다.


반대로 오프셋이라면? 오프셋이 앞번호면 인덱스를 잘 타지만 뒤로 가면filesort 가 일어나게 된다.
explain select * from tb_lost_post
order by received_date desc, lost_post_id
limit 10 offset 53979; // 똑같이 53979번 부터 탐색하도록 설정
QueryDSL 구현
@Repository
class CustomLostPostRepository(
private val queryFactory: JPAQueryFactory,
private val jdbcTemplate: JdbcTemplate
) {
fun searchLostPosts(command: GetSliceLostPostsCommand): Slice<LostPostEntity> {
val response = queryFactory.selectFrom(lostPostEntity)
.where(
subwayLineEq(command.subwayLine),
lostTypeEq(command.lostType),
categoryEq(command.category),
titleAndContentLike(command.keyword),
createdAtBeforeOrEqual(command.receivedDate, command.lostPostId)
)
.orderBy(lostPostEntity.receivedDate.desc(), lostPostEntity.id.asc())
.limit((command.pageSize + 1).toLong())
.fetch()
return SliceImpl(response, Pageable.unpaged(), hasNext(response, command.pageSize))
}
...
private fun createdAtBeforeOrEqual(receivedDate: LocalDateTime?, id: Long?) =
lostPostEntity.receivedDate.lt(receivedDate).or(
lostPostEntity.receivedDate.eq(receivedDate).and(lostPostEntity.id.gt(id))
)☁️ 참고 자료
RealMySQL 1편
https://jojoldu.tistory.com/529?category=637935

처음 테이블 풀스캔 실행시간이 0.02ms가 아니라 0.02s인 것 같네여