
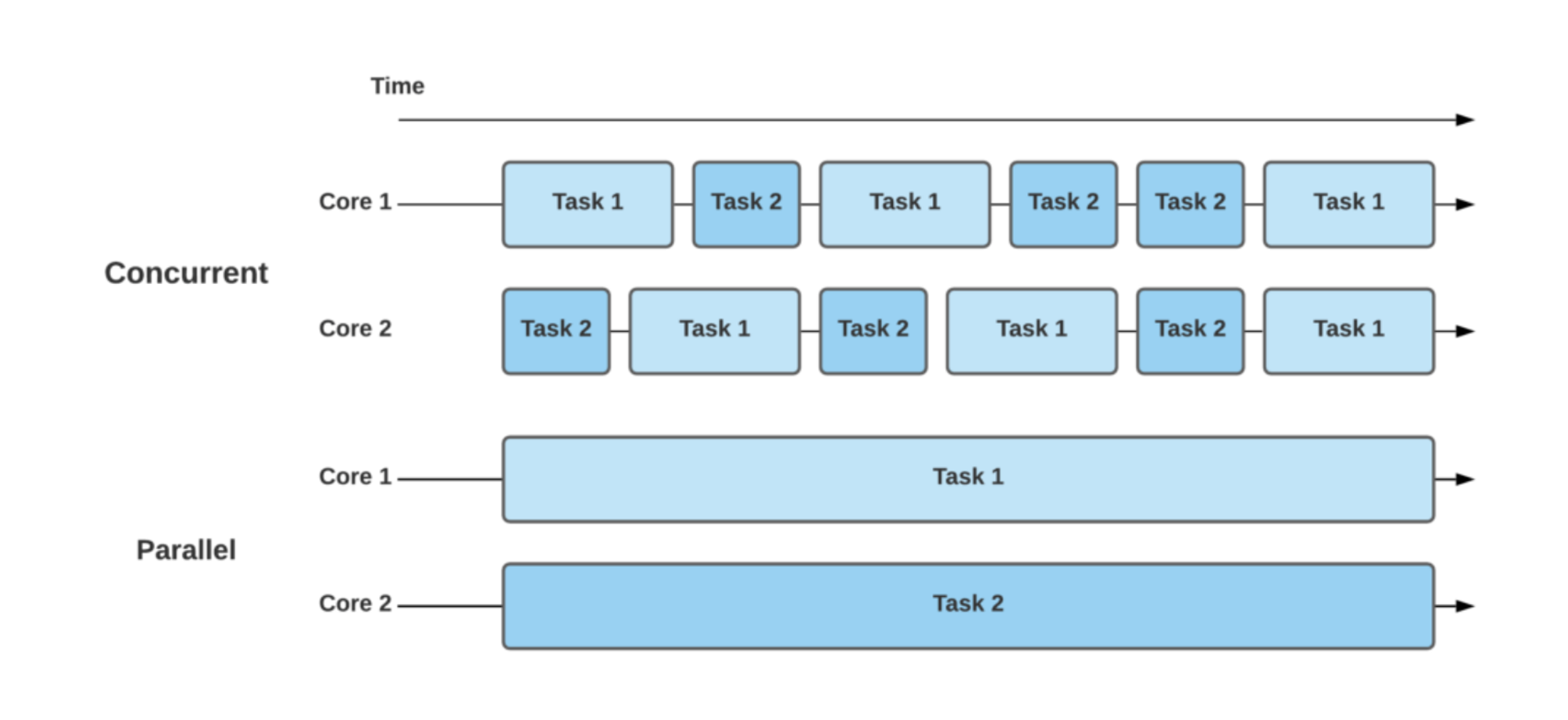
Redis는 싱글 스레드인데, 어떻게 수많은 요청을 동시에 처리할 수 있는걸까?
라는 궁금증에서 해당 포스팅을 작성해보았다. 결론부터 말하자면, Redis 를 제외하고도 Node.js 나 JavaScript 는 싱글 스레드면서 이벤트 루프를 통해 동시성을 보장한다.
참고로 현재 Redis 6.0 버전부터는 다른 부가적인 처리를 위해 부분적으로 Multi Thread 이지만, 명령의 실행 자체는 Single Thread 로 동작한다. 즉, read / write 에 대한 작업을 메인 스레드가 각 I/O 전용 스레드에 할당한다.
우선은 I/O 를 별도 스레드로 처리하는 기능을 사용하지 않는다고 했을 때(스레드=1)를 먼저 살펴보자.

이벤트 루프를 알려면, 먼저 동기 및 비동기의 개념 부터 시작해서 I/O MultiPlexing 이 무엇인지 알아야 한다.
Blocking I/O
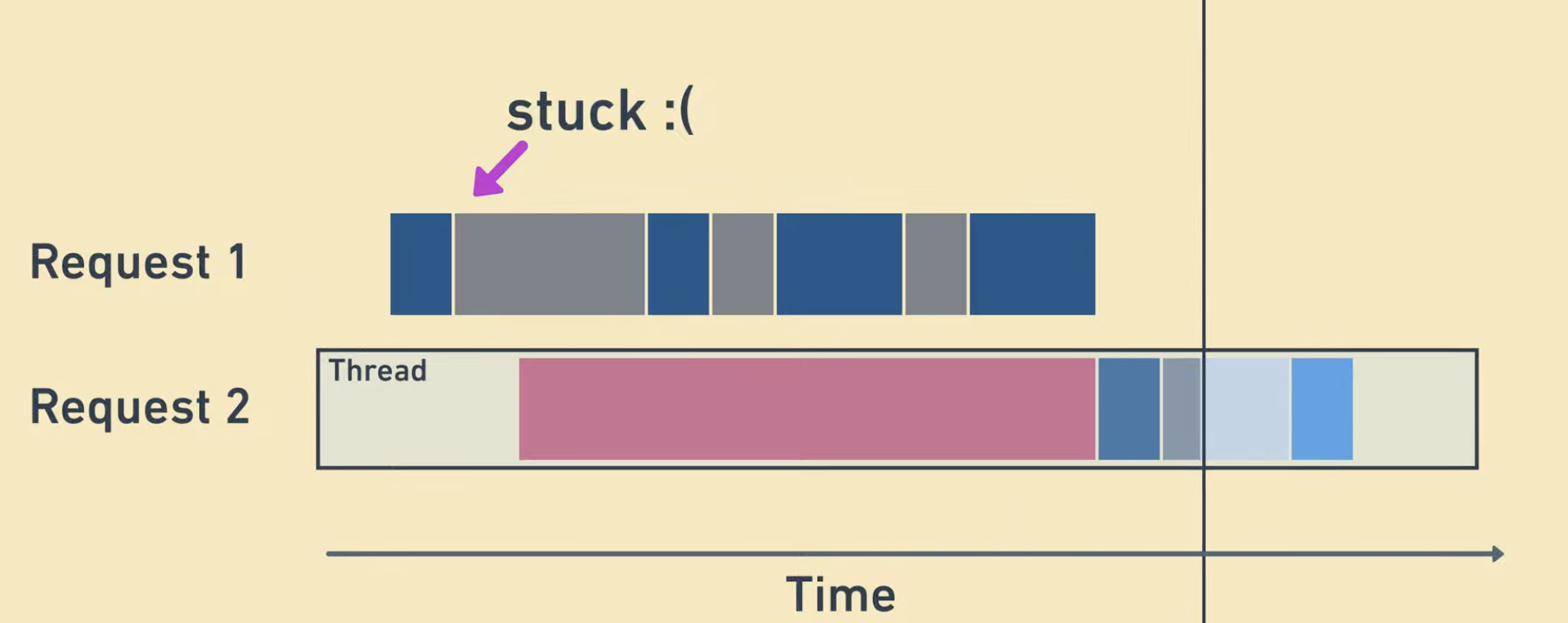
Blocking I/O 란, I/O 요청이 수행될 동안 호출한 스레드가 멈추거나 블락되고 끝나기를 기다리는 것을 의미한다.
기본적으로 Synchronous 방식이며, 즉 파일과 같은 입출력이 일어났을 때 시스템 콜 함수가 완료될 때 까지 다른 일을 하지 못하고 언제 끝나나 계속 확인을 하면서 기다리게 된다. 글만 봐도 매우 비효율적일 것 같지 않는가?
- 호출된 함수가 바로 리턴해서 제어권을 넘겨주지 않는다.(
Blocking) - 호출한 함수가 작업 완료 여부를 계속 확인한다.(
Synchronous)
그렇다면 스레드를 여러개로 늘려서, 병렬적으로 처리할 수 있도록 해보자.
멀티스레드 + Blocking I/O 문제점
물론 처리 속도는 빨라지겠지만, 여전히 문제가 발생한다.
-
여러 스레드가 트리거되어 대규모 컨텍스트 전환과 높은 메모리 사용량으로 인해 성능 문제가 발생한다. 이 경우
CPU는 전환, 예약, 스레드 수명주기 유지 등에 대부분의 시간을 소비하게 된다. -
각 스레드는 클라이언트가 데이터를 보내고 디스크
I/O작업을 수행하기 위한 연결을 기다리느라 블락 상태가 되어버린다.
이렇듯
Blocking I/O접근을 사용하는thread per connection방식은 많은 동시 연결 상황에 적합하지 않다.
Non-Blocking I/O Model
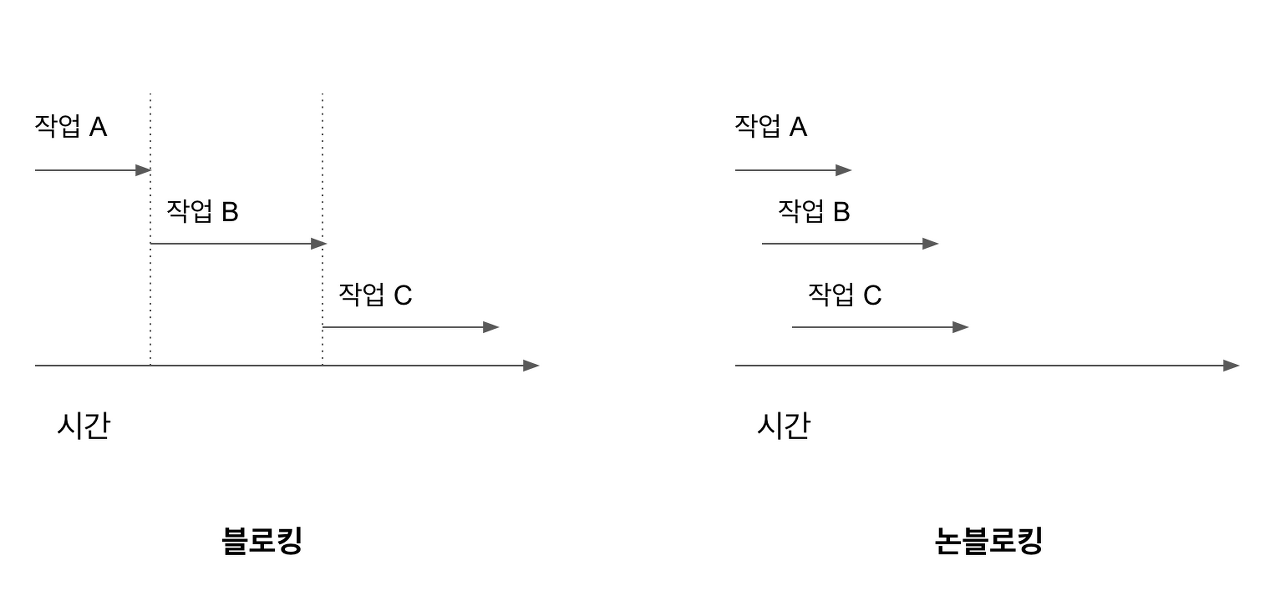
이제 연결당 하나의 스레드 대신, Non-Blocking 방식으로 연결을 허용하는 단일 스레드를 사용해보자. Non-Blocking I/O 란 I/O 요청이 수행될 동안 스레드가 멈추거나 블락되지 않는 것을 의미한다.
기본적으로 Non-Blocking + Asynchronous 방식으로 동작한다.
- 호출된 함수가 바로 리턴해서 제어권을 넘겨준다. (
Non-Blocking) - 호출한 함수가 작업 완료 여부를 확인하며 기다리지 않는다.(
Asynchronous)
바로 제어권을 넘겨주는 상황에서 데이터가 준비되지 않았다면, 즉 요청에 대한 결과를 반환할 수 없는 상태라면 -1 을 리턴해서 호출한 스레드가 다른 작업을 수행할 수 있도록 한다.
여기서 찐한 파란 부분은 웨이터의 도움을 받아야 하는, 즉 CPU Active 한 시간이고 연한 파란 부분은 웨이터의 도움이 필요 없는, 즉 I/O (CPU Inactive) 시간이다.
그럼 싱글 스레드인 상황에서, 각각 언제 써야 할까?
-
CPU Burst Time > I/O Burst Time인 프로세스
Blocking I/O가 유리할 수도 있으며,Non-BlocKing I/O가 커다란 도움을 주지 못할 수 있다. 왜냐하면 어차피 대부분 시간은 CPU가 계산하고 있으며 I/O는 드물게 발생하고 짧게 끝나기 때문이다. -
CPU Burst Time < I/O Burst Time인 프로세스
Non-Blocking I/O가 절대적으로 유리하다.Blocking I/O면 CPU가 싱글 스레드라 다른 요청도 처리하지 못하기 때문에,Non-Blocking이여야지 다른 작업을 처리하면서 I/O 완료를 기다릴 수 있기 때문이다.Node.js와Redis역시 많은 네트워크 요청(I/O)을 주고 받기 때문에 여기에 속한다.
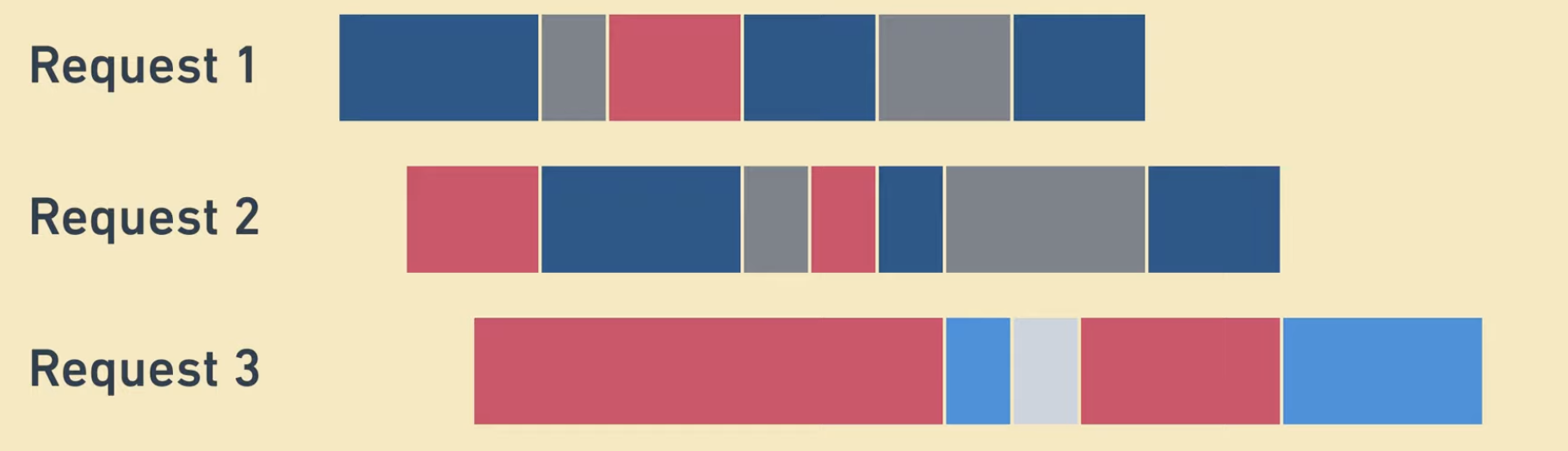
하지만 호출한 스레드가 어떻게 I/O 작업이 완료되었는지 알 수 있지?
이걸 가능하게 하는 방법이 여러가지가 있다.
1. 주기적으로 확인 : Polling
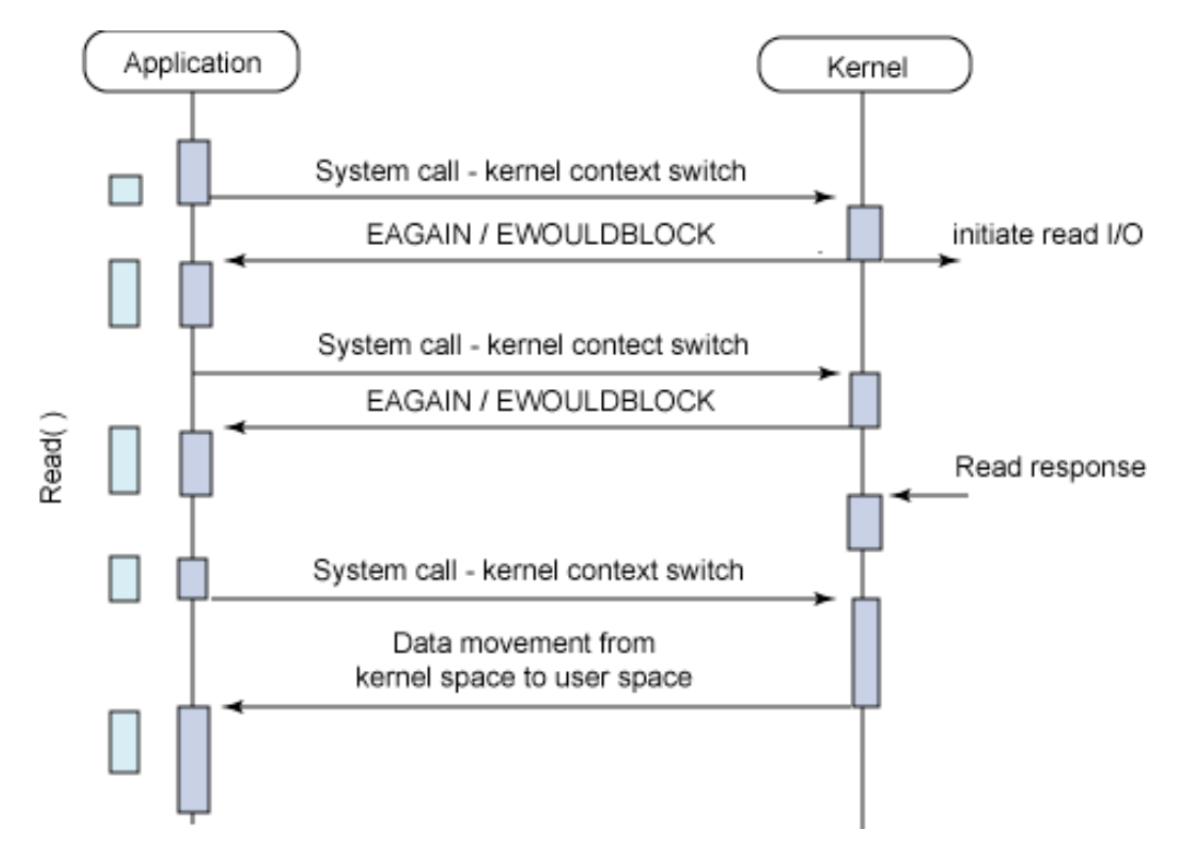
주기적으로 확인하는 것을 폴링 방식이라 하는데, 확인을 한다는 점에서 폴링은 Non-Blocking + Synchronous 로 동작한다.
커널로부터 제어권을 받어 효율적이라 보일 수 있지만, 결과를 반환하기 까지 계속 데이터를 반환했는지 확인하는 busy-waiting 상태가 되어버린다.
이렇게 되면 다른 작업을 하다가도 상태를 확인하기 위해 컨텍스트 스위칭이 일어나고, 다시 작업을 수행하다가 또 컨텍스트 스위칭이 일어나는 의미 없이 컨텍스트 스위칭 비용만 낭비해 성능을 떨어트릴 수 있다. 또한 이렇게 Polling 주기에 따라 성능에 영향을 미치므로 설정이 매우 중요해진다.
2. 준비됨을 알림 : I/O MultiPlexing
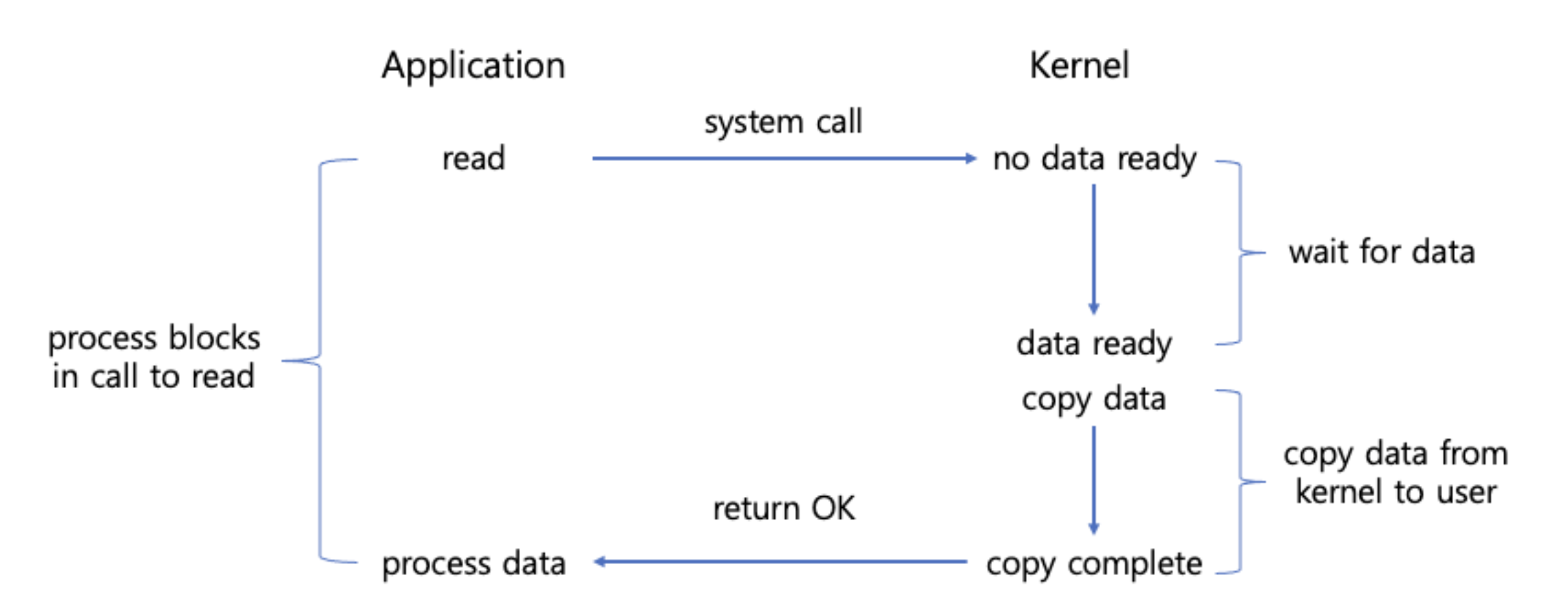
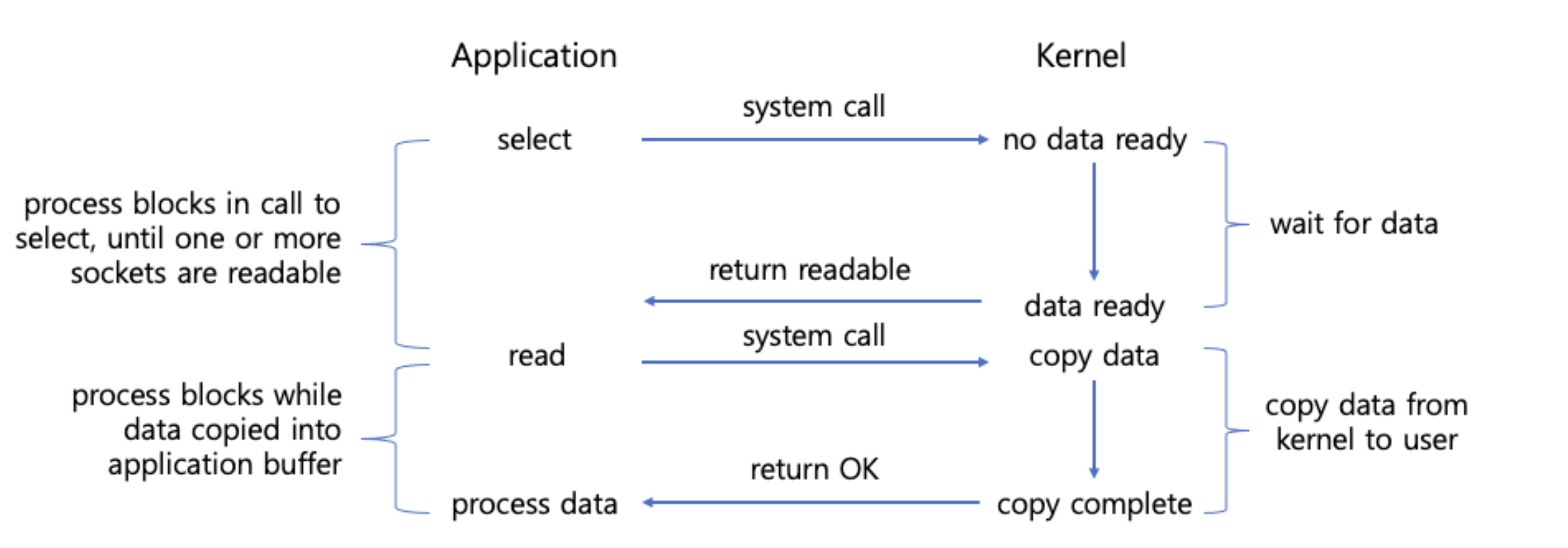
I/O MultiPlexing 이란, 관심 있는 I/O 작업들을 동시에 모니터링 하고 그 중에 완료된 I/O 작업들을 한번에 알려주는 기법이다. 선택 혹은 폴링 시스템 호출을 통해 운영체제에서 단일 스레드가, 여러 소켓 요청을 동시에 기다릴 수 있게 된다.
리눅스에서는 모든 것이 파일로 귀속된다. 따라서, 소켓 또한 파일이므로 스레드가 하나라도 여러 개의 파일을 동시에 관리할 수 있다면, 다수 유저의 요청을 처리할 수 있게 된다.
이전 동작 방식
이전에는, 하나의 메인 스레드에서 소켓이 열리면 그 소켓에서 read 할 데이터가 있을 때까지 무한정 기다렸기 때문에 스레드가 블락되었다. 즉 무조건 read 요청을 하고, 데이터가 버퍼에 복사될 때까지 기다리는 것이다.
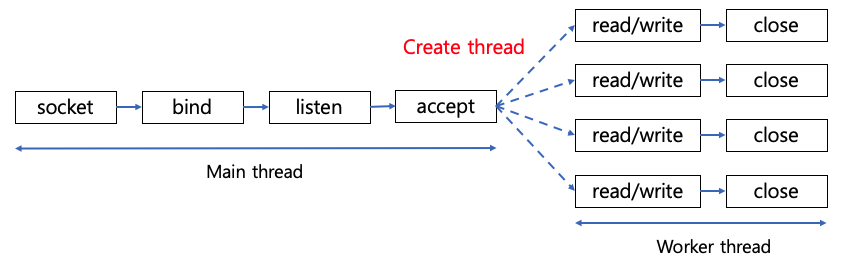
I/O 멀티플렉싱 동작 방식
I/O 멀티플렉싱에서는 하나의 스레드가 여러 개의 소켓들을 탐색하면서, read 할 데이터가 있는지 검사한다.
검사 기법은 다음과 같이 다양하다.
select,poll같은 기법에서는 스레드가file descriptor테이블을 순회하면서 데이터가 들어왔는지 검사하므로O(N)시간복잡도를 가진다. 이 때 계속 상태를 확인하는 작업이 일어나므로Synchornous+Non-Blocking인 방식이다.epoll과 같은 기법에서는 커널이 직접fd의 상태를 관리해 상태가 바뀐 것을 통지하므로Asynchornous+Non-Blocking인 방식이다.
즉 어찌 되었던 커널에서 결과 값이 준비되었다는 콜백 신호가 오면, 그때서야 유저 프로세스는 자신의 버퍼로 데이터를 복사하므로 실제 디스크에서 커널 버퍼까지 가져오는 시간을 대기하지 않아도 되는 장점이 있다.
명확히 구분하자면 유저 프로세스에서의
I/O작업 자체가 블락 되는 것이 아니라select,poll같은 멀티플렉싱 관련system call에 대한 커널의 응답이 블락된다고 봐야 한다.
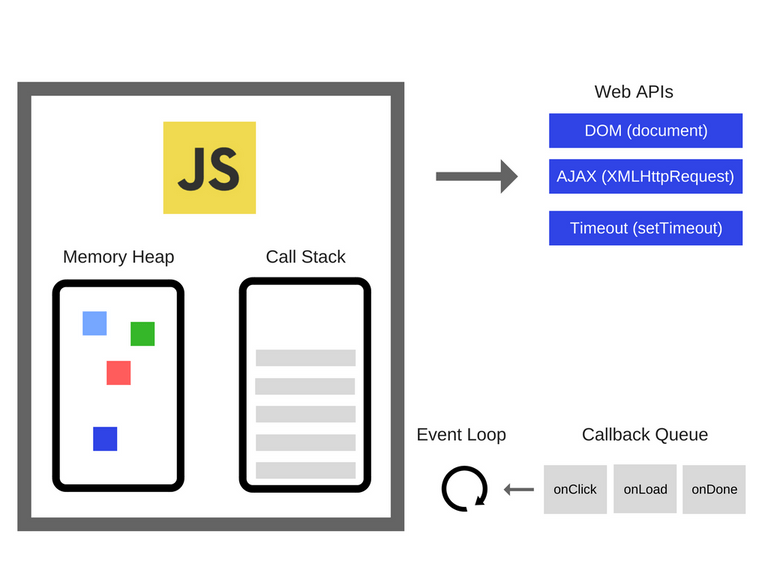
Event-Loop
자바 스크립트의 Event-Loop 방식과 비슷하게 동작한다. 이벤트 루프는 콜 스택을 계속 감시하고 있다가 비어있는 상태가 되면, 콜백 큐에 있던 콜백을 전달해준다. 즉 콜 스택과 콜백 큐를 항상 모니터링 하고 있다.
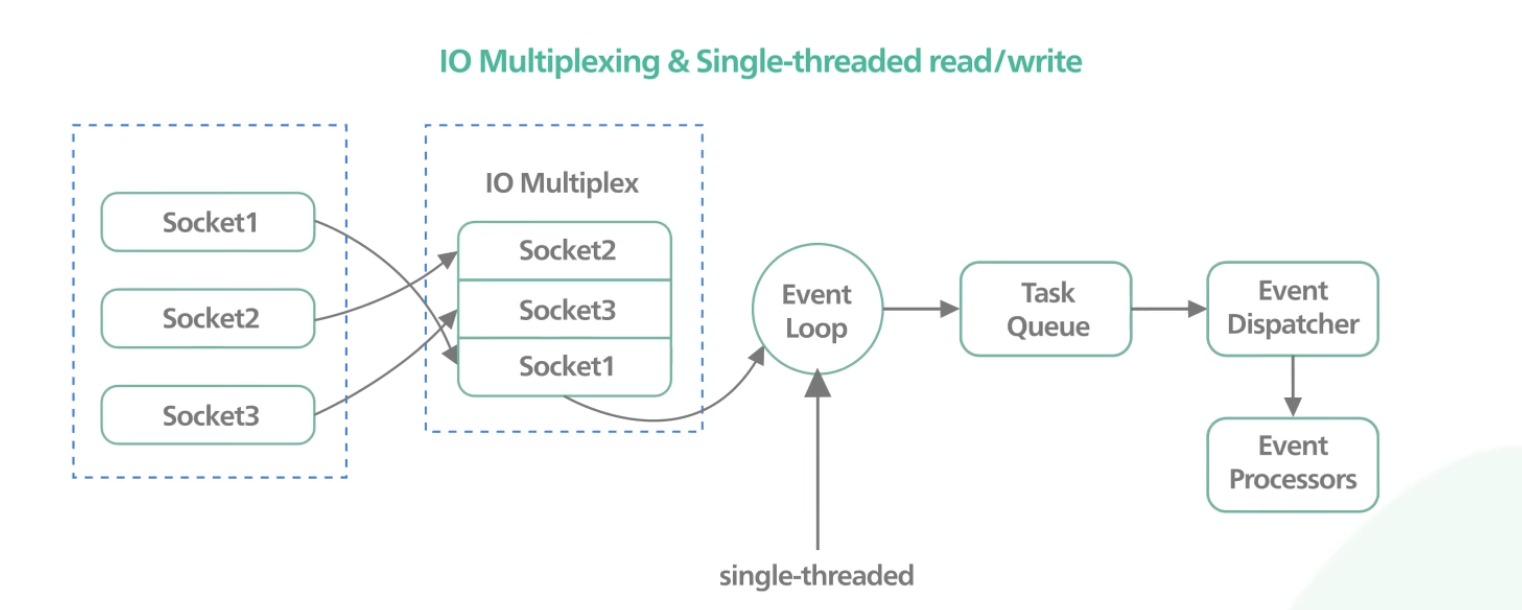
싱글 스레드 형식의 Redis Event Loop 에서는, 하나의 이벤트 루프에서 앞서서 말했던 IO Multiplexing 을 이용해서 read / write 이벤트를 받아온다. 커널에 할당된 폴링공간에 모니터링할 이벤트를 등록하고, 발생한 이벤트를 리턴받아 Multiple I/O Event 를 처리할 수 있도록 해주는 방식이다.
즉 TCP 연결을 비동기 방식으로 수락한 다음, 이벤트 루프에서 수락된 각각의 연결을 처리한다. 이때 읽기/쓰기 작업에 사용이 가능하도록 준비가 된 fd 를 알기 위해, epoll()을 사용한다.
참고자료
https://betterprogramming.pub/internals-workings-of-redis-718f5871be84
https://engineering.linecorp.com/ko/blog/do-not-block-the-event-loop-part1
https://blog.naver.com/n_cloudplatform/222189669084
https://www.youtube.com/watch?v=wB9tIg209-8
https://notes.shichao.io/unp/ch6/
https://www.youtube.com/watch?v=mb-QHxVfmcs
