Classification analysis
- Given a collection of records(training set)
- Each record contains a set of attributes, one of the attributes is the class
Definition
- Find a model for class attribute as a function of the values of other attributes
- 다른 attribute의 값으로 class value를 가장 최적으로 설명할 수 있도록 model을 찾는 과정
- Model : class attribute를 다른 attribute의 값으로 설명하는 함수
- Classification analysis as the task of mapping an input attribute set x into its class label y
- Classification analysis is the task of learning a target function f that maps each attribute set x to one of the predefined class labels y
- Learn : to gain by experience, exposure to example ; acquire
- Model의 성능을 확인하기 위하여 training set과 test set으로 분할하며, training set은 모델을 build하는 것에, test set은 validate하는 것에 사용된다.
Goals
- 이전에 등장하지 않았던 records에 대하여 최대한 정확한 class를 예측하기 위함이다.
Classification technique의 특징
- Binary or nominal categories를 가지는 data에 대하여 예측하거나 설명한다.
- Categories의 순서가 가지는 의미에 대하여 고려하지 않기 때문에 Ordinal categories에 대하여 비효율적이다.
- Sub-class, super-class 간의 관계를 고려하지 않기 때문에 의미가 누락된다.
- 종양의 음성/양성 여부 판단, 카드의 legitimate 여부 판단, 신문의 카테고리 분류, 단백질 구조 분류 등
- Training set → induction → Learn model(Learning algorithm) → model → apply model → deduction
- 주요 목표는 좋은 일반화 성능을 가지는 모델을 build하는 것이다.
- Learn model : 데이터를 통하여 model을 gain한다 / 학습 모델은 잘못된 말
Deduction : 연역적
- 일반적인 원칙에서 새로운 사실을 도출
Induction : 귀납적
- 구체적인 사실에서 일반적인 원리 도출
Purposes of classification model
Descriptive modeling
- Serve as an explanatory tool to distinguish between objects of different classes.
- Record의 attribute의 관계들을 통하여 왜 class label을 갖게 되는지 설명/묘사
- Classification descriptive model을 통하여 class label과 attribute간의 관계에 대해 설명한다.
Predictive modeling
- Predict the class label of unknown records
- label값이 없는 record에 대하여 값을 예측하기 위하여 모델을 설계한다.

Model evaluation for classification
Confusion matrix
- 실제 값과 예측 값에 대한 정보를 table 형태로 표현한 것
- f_ij ∶ class i에 대하여 class j라고 예측한 record의 수

- Highest accuracy or lowest error -> best model
Artificial neural networks(ANN)
- Input node들에 대하여 가중치를 두고 함수(시냅스)에 입력하고, 함수에서 전부 더하는 등의 과정을 거치고 임계 값과의 비교를 통하여 의사결정(output)을 도출한다.
- 학습을 통하여 X와 Y의 관계, 의존성, 가중치 등을 갱신한다.
- Training ANN means learning the weights of the neurons
- 모델의 성능을 높이고 더 많은 문제를 풀기 위하여 hidden layers를 추가 : deep learning
Perceptron model
- Model은 서로 연결된 node와 weighted links로 구성되어 있다.
- Output node는 각각의 input value를 연결된 가중치를 계산한 값을 sum up한 후 임계 값과 비교 후 논리적인 판단(true/false 또는 sign 등의 함수: 양수이면 1, 0이면 0, 음수이면 -1을 반환)을 한다.
Support vector machine
- Find a linear hyperplane(decision boundary, n – 1 차원) that will separate the data
- Decision boundary와 class간의 margin이 공평하게 나누었을 때, margin이 가장 크게 잡힌 boundary가 optimal
- find hyperplane maximizes the margin
- Hard margin classification : 클래스의 분류를 엄격하게 한다.
- Soft margin classification : 소수의 Outlier에 대한 여지를 준다.
- Non-linear SVM : Kernel을 사용하여 곡선의 형태로 decision boundary를 형성한다.
Decision tree induction
- 사람의 의사결정 과정을 본떠 만든 모델
- Node : attribute를 test하는 것을 나타낸다. / what question?
- Non-terminal node는 records을 나누는 attribute test condition을 포함하고 있다.
- Branch : 테스트의 결과를 나타낸다. / what outcome?
- Node : stop or split?
- Stop : leaf node with class label / Split : internal node with question
- Leaf node(terminal node) : class label을 나타낸다.
Build a decision tree
- Test on an attribute : pose a series of questions
- Construct a tree : arrange questions
- D_t
- Node t에 도달하는 training record의 집합(set of training records that reach a node t)
- D_t가 모두 같은 class x에 속하면 그 node는 x의 label이 붙은 leaf node가 된다.
- D_t가 다른 class value를 가진 레코드가 있다면 attribute test 조건에 의해 더 작은 subset으로 분할되며 각각의 subset에 반복적으로 적용된다.
Hunt’s algorithm
- Global Optimal tree를 찾는 것은 computationally infeasible하기 때문에 suboptimal decision tree를 찾는 방법이 있으며 그 중에서 가장 쉬운 방법이 hunt’s algorithm이다.
- 초기에 모든 record를 사용하여 분류 기준에 맞게 노드를 분류하고 분류된 record가 stop criterion을 만족하면 leaf node로 처리하며 그 외의 경우에는 stop criterion을 만족할 때까지 반복한다.
Assumption for hunt’s algorithm
Basic assumption
- 모든 attribute의 value의 조합은 training data에 존재한다.
- 모든 조합은 unique class label을 가진다.
- 동일한 조합이 다른 class label을 가져서는 안된다.
- Training data에 포함되지 않은 attribute로 인해 동일한 attribute의 value에도 불구하고 다른 class label을 가질 수 있다.
-> 너무 엄격한 기준 / 추가적인 조건이 필요하다
Additional condition needed
- D_t가 empty set인 경우, t는 부모 노드에서 다수 측의 class label으로 labeling한다.
- 조합이 unique class label을 가지지 못하는 경우 다수의 class label을 사용하여 labeling
Tree induction
Greedy strategy
- 데이터를 분할하는 기준으로 사용되는 attribute는 locally optimum한 것을 고른다.
- 전체적인 부분이 아닌 현재의 부분, 지금 가지고 있는 데이터만으로 optimum 도출
Issues
- 어떻게 test condition을 정의하고 best split을 정의할 것인지(evaluation measure)
- 언제 splitting을 그만둘 것 인지
- 모두 같은 class label을 가질 때 stop하거나 다른 기준을 사용하여 일찍 종료할 수 있다.
How to specify test condition?
Depends on attribute types
- Nominal / ordinal / continuous
Depends on number of ways to split
- 2-way split(계산 비용이 적으며, 오버 피팅을 줄일 수 있다 / 가능한 조합을 누락할 수 있다)
- multi-way split
splitting based on nominal attributes
- multi-way split : use as many partitions as distinct values
- binary split : divides values into 2 subsets. Need to find optimal partitioning
splitting based on ordinal attributes
- binary split : {small, large} / {medium} 같이 order의 특성을 무시하는 분류는 피하는 것이 좋다.
- 대수적으로 분류 기준을 특정할 수 없다.
splitting based on continuous attributes
discretization to form an ordinal categorical attribute
- static : 초기에 한 번 범주화를 진행한다.
- Dynamic : 입력되는 record의 데이터에 따라 범주화의 범위를 결정한 후 실행한다.
- Interval bucketing : 범주화되는 구간을 동일하게 설정한 후 범주화를 진행한다.
- qual frequency bucketing : 동일한 record의 수를 가지도록 범주화를 진행한다.
Binary decision
- 가능한 split을 고려하여 가장 best cut을 찾는다
Range query
- 가능한 연속 값의 범위를 계산하여 구간별로 나눈다.
How to determine the best split
Perfect split
- 모든 records가 하나의 leaf node에 같은 class label을 가지도록 하는 split
Best split
- Split 전과 후를 비교했을 때, 분포가 pure한 상태로 있게 하는 split 중 가장 좋은 split이 best split
Measure of node impurity
P(i|t) : node t에 class i의 값을 가지는 record의 부분
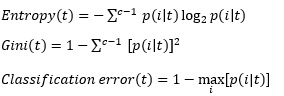
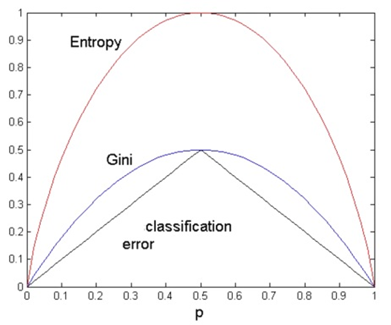
- 모든 class labels가 균등하게 분포할 때, impurity가 가장 높다
- Gini보다 entropy가 다른 class label에 대해 민감하게 반응한다.
- Gini와 entropy는 classification error보다 소수의 class value가 다를 때 민감하게 반응한다.
How to find the best split

GINI
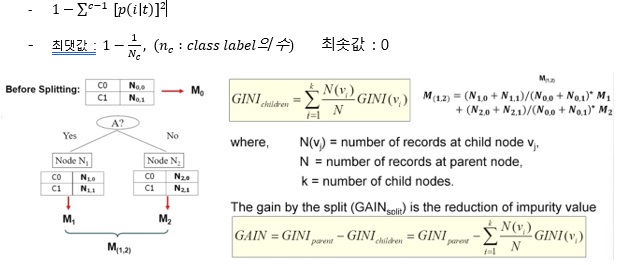
GAIN : 정보 획득량, 더 큰 값을 택한다.

Continuous attributes : computing gini index
- 다양한 split value를 선택할 수 있다.
효율적 split 지점 계산 방법
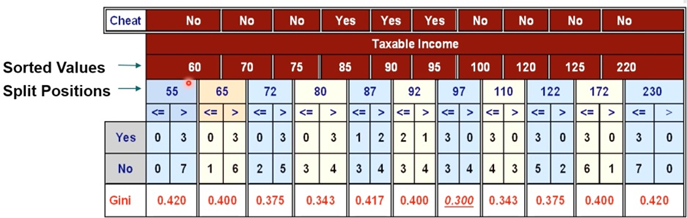
- Data set에 있는 attribute value를 오름차순으로 정렬한 후 label을 mapping한다.
- 최소값과 최댓값 설정 후 각 attribute value의 중간 값을 split point로 설정한다.
- Class label 값이 바뀌는 부분 (80, 97) 만을 고려하면 더 빠르게 계산할 수 있다.
Convex
- 곡선 위에 임의의 직선을 그었을 때 선분 아래 곡선이 존재하는 곡선 : 오목
Concave
- 곡선 위에 임의의 직선을 그었을 때 선분 위에 곡선이 존재하는 곡선 : 볼록
- Gain 사용의 단점
- split이 많을수록 gain이 높아진다 >> 신뢰할 수 없다 >> GainRATIO 사용
GainRATIO
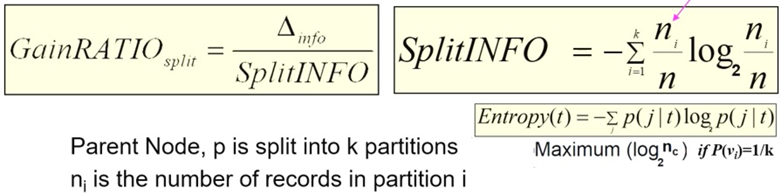
- N : 부모 노드의 record 수 n_i ∶ 각 자식 노드가 가지는 record 수
- 같은 GAIN값을 가질 때, 더 적은 Split의 경우를 선택하기 위해 사용
- 더 신뢰할 수 있는 split >> 적은 splitINFO >> larger GAINRatio
- Partition의 수가 더 많다고 해서 항상 SplitINFO가 큰 것은 아니며 종합적으로 더 신뢰할 수 있는 split을 선택한다.
Classification error at a node t
Error(t) = 1 – max P(i|t)
- 모든 class에 record가 균등하게 분배되어 있을 때 error값을 1 – 1/n으로 가장 큰 값을 가진다.
- 하나의 class에 모든 record가 배당되었을 때 0.0의 가장 작은 값을 가진다.
Stopping criteria
- 모든 record가 하나의 같은 class안으로 분류되었을 때 중단한다.
- 모든 record가 비슷한 attribute 값을 가질 때 중단한다.
- 특정 impurity값을 지정하는 등 다양한 early termination을 선택할 수 있다.
Tree based classification의 장점
- 모델은 구성하는 비용이 싸다
- Unknown records에 대한 분류가 굉장히 빠르다.
- 작은 규모의 트리에 대해 쉽게 해석할 수 있다.
- 많은 단순한 데이터셋에서 다른 분석 기법과 비슷한 성능을 낸다.

KHU, SWCON