Cluster Analysis
- object를 설명하고 관계를 설명하기 위하여 information에만 의존하여 data를 grouping한다.
- grouping된 객체는 같은 그룹의 객체와 유사하고 다른 그룹의 객체와는 차이점을 나타낸다.
inter-cluster distance are maximized
- between cluster
- 각각의 cluster간의 거리를 최대가 되도록 군집을 형성한다.
- inter-cluster distance만을 고려하는 경우 2개의 cluster로 나뉜다.
intra-cluster distances are minimized
- with in cluster
- 같은 cluster 내의 객체 간의 거리를 최소화한다.
- intra-cluster distance만을 고려하는 경우 무수히 많은 sub-cluster가 생성된다.
Clustering for utility
summarization
- 데이터셋의 크기를 줄인다.
- 전체 데이터에 알고리즘을 적용하기보다는 clustering prototype에만 알고리즘을 적용할 수 있다.
compression
- cluster prototype을 이용하여 데이터를 압축할 수 있다.
- 데이터의 세부내용을 저장하기보다는 type n 등 간단히 표현할 수 있다.
compression vs. summarization
- 요약은 각 군집의 대표성을 의미하며 압축은 각각의 객체를 저장하지만 세부내용을 저장하지 않고 간단히 표현하는 것에 사용한다.
efficiently finding nearest neighbors
- 특정 데이터를 찾기 위하여 먼저 cluster에 접근한 후 세부 객체에 접근함으로써 효율적인 데이터 검색을 할 수 있다.
types of clusterings
hierarchical clustering
- cluster를 계층적으로 중첩하여 생성한다.
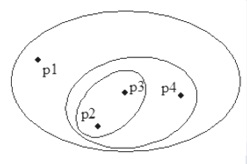
partitioning clustering
- 데이터를 겹치지 않는 subset으로 cluster를 구성한다.
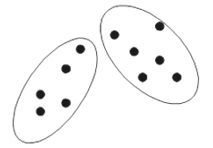
fuzzy clustering
- 중첩이 가능한 clustering이며 각각의 데이터가 각 cluster에 소속된 정도를 0과 1 사이의 값으로 나타낸다.
- 가중치의 합은 1이 되어야 한다.
- probabilistic clustering과 유사
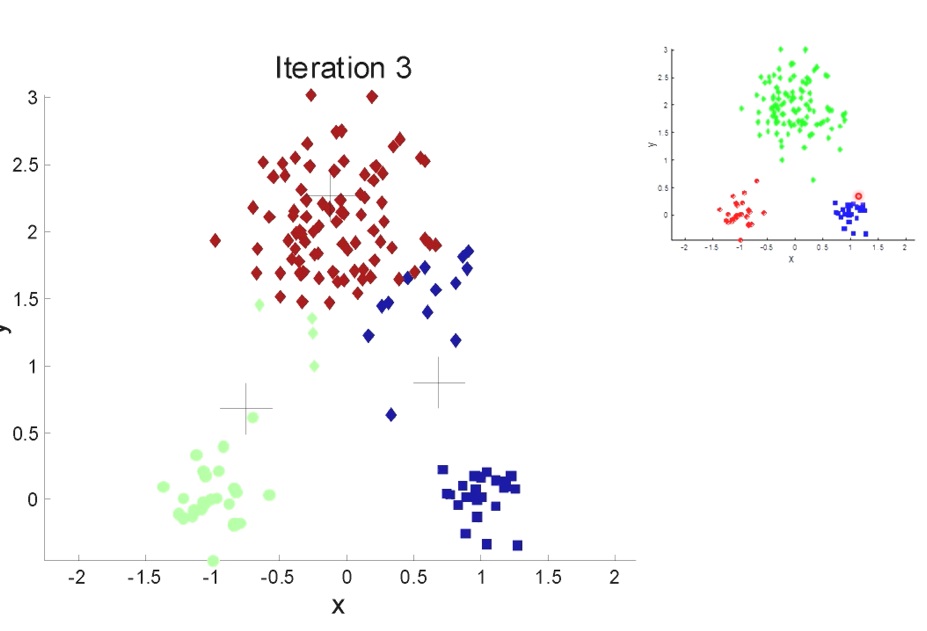
K-means clustering
- partitional clustering의 일종
- 각각의 군집은 centroid(center point)와 관련된다.
pseudo code

구축 과정
-
초기 centroid를 임의로 지정한다.
-
각각의 좌표를 행렬 형태로 생성 후 euclidean distance, cosine similarity 등을 이용하여 closeness를 측정한다.
-
D^i에서 작은 값을 가지는 그룹에 할당한다.
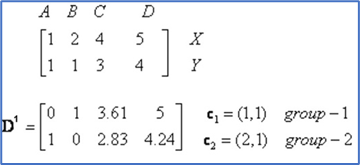
-
Group에 속한 요소의 x, y좌표의 평균으로 centroid를 업데이트한다.
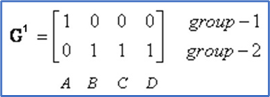
-
종료 조건을 만족할 때까지 반복한다.
복잡도
- O(K I n * d)
- n : number of points
- K : number of clusters
- I : number of iterations
- d : number of attributes
choosing intial centoid
importance
- 초기 centroid가 어떻게 설정되냐에 따라 cluster의 최적화 정도가 달라진다.
problems
- 적절한 초기 centroid를 선택할 확률은 k!/(k^k)로 굉장히 낮으며 계산 비용이 굉장히 크다.
solutions
multiple runs
- 확률이 굉장히 낮아 유용하지 않다.
sample and use hierarchical clustering
- 계산 비용이 굉장히 증가하기 때문에 적은 sample과 k일 때 사용한다.
select more than k intial centroids and select among these initial centroids
- 초기 설정 k보다 더 많은 centroid를 설정한다.
postprocessing
- split / disperse / merge의 방법이 있다.
- cluster를 split하거나 제거하고 merge함으로써 initial centroid 문제점을 해결할 수 있다.
evaluation
- 각 cluster 내의 데이터와 centroid 간의 거리를 구한 후 sum of squared error를 구하여 군집을 평가할 수 있다.
bisecting K-means
pseudo code

구축 과정
- 초기에 데이터를 이분할 한다.
- SSE를 기반으로 군집을 평가하며 평가가 좋지 않은 군집을 대상으로 이분할 한다.
- 종료 조건을 만족할 때까지 반복한다.
Empty clusters
- K-means 알고리즘은 empty cluster를 생성할 수 있는 문제점을 가지고 있다.
전략
- 현재 clustering 진행 중인 centroid와 가장 먼 point를 선택한다.
- 가장 큰 SSE를 가지는 Point를 새로운 군집으로 할당한다.
- outlier일 가능성이 크기 때문이다.
- empty cluster가 사라질 때까지 과정을 반복한다.
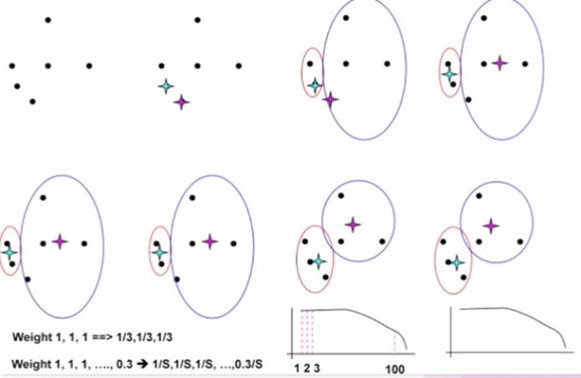
Updating centers incrementally
- 전체의 요소를 고려하여 업데이트하는 것이 아닌 점 하나하나 업데이트 함으로써 empty cluster 방지가 가능하다.
- 각각의 할당은 2 or 0 centroid를 update한다.
- 계산 비용이 증가하며 데이터의 순서에 따라 결과가 달라질 수 있다.
- 절대 empty cluster를 발생시키지 않는다.
- 가중치를 사용하여 변화에 영향을 줄 수 있다.
- 일반적으로 clustering이 진행되면서 가중치가 낮아진다.
- 앞의 단계를 지나오면서 형성된 cluster가 뒤의 outlier 등과 같은 데이터로 cluster가 급격하게 바뀌는 것을 방지한다.
- 전체의 가중치 합이 1이 되도록 조정한다.

KHU, SWCON