Data Quality
- data cleaning : detection and correction of data quality problems
- robust algorithm : poor data quality를 견뎌낼 수 있을 알고리즘을 사용한다.
Data quality problems : Measurement errors (measured by precision and bias)
Noise
- 사람의 목소리를 왜곡시키거나 텔레비전 스크린에 snow현상을 나타낸다.
- 의도되지 않은 data이며 Random Component이다.
- value를 왜곡시키거나 spurious object를 추가시키기도 한다.
- 관심의 대상이 되지 않으며, 항상 Noise 감소를 목적으로 삼는다.
- 제거가 매우 어려우며 robust algorithm을 사용한다.
- Fourier Transformation : 함수를 주파수 성분으로 변환하여 진폭 주기 등 주요성분을 얻어낸다.
Artifact
- 중량 측정 시 영점 에러나 바구니의 무게 같은 것
- 발생이 일어난 후 고정적으로 데이터를 왜곡시키는 것
measurement error metrics (Measurement error 측정 방법)
- Accuracy : 측정된 값과 true 값 간의 차이
- Precision : 측정된 값의 근접도(측정된 값의 평균값과 true value사이의 거리)
Data quality problems : Data collection errors
Outlier
- 비정상적인 접근 탐지, 부정 거래 내역 탐지 등에서 의미 있는 가치를 가진다.
- Data Set 내의 대부분의 Data 와 상당히 다른 특징을 가지고 있는 Data, 정상적 측정 데이터
Missing and inconsistent values
- 정보를 수집하지 않은 경우나 정보 측정을 거부 당한 경우 / 측정 자체를 할 수 없는 경우
- 해결 방법
- Data Objects제거:data set이 충분히 커서 제거가 결과에 영향을 미치지 않는 경우 사용
- Estimate or ignore Missing Value : 데이터의 관계를 사용하여 추정 또는 무시
- 가능한 값으로 대체 / 존재할 수 있는 확률을 가중치로 하여 계산하는 방법
Duplicate data
- 중복되거나 거의 유사한 데이터 / 복수 개의 DB 데이터를 통합할 때 발생한다.
- EX) 한 사람이 여러 개의 이메일 주소를 가지는 경우 등
- 해결 방법
- Deduplication : 중복되는 두 데이터를 구분하는 방법
- Data cleaning : data quality 문제를 탐지하고 해결하는 과정
Data Preprocessing (Data cleaning 과정)
Aggregation(집성, 집계, 집합화) * Resolution과 관련된다
- 2개 이상의 object를 하나의 object로 통합
- 목적
- Data Reduction : 더 적은 메모리와 processing time / attribute나 objects의 수를 줄인다
- Change of scale : ex) 도시를 주나 국가로 통합한다.
- More stable data : 통합함으로써 variability를 줄인다.
Quantitative attributes(numerical values)
- 합이나 평균을 이용하여 통합한다
Qualitative attributes(categorical values)
- 제거하거나 요약(상위 10개, 대분류 등)하여 통합한다.
Sampling
- 전체 데이터를 모두 사용하기에는 비용과 시간이 너무 많이 들기에 사용한다.
- 샘플은 모집단과 관심있는 property에 대해 representative(유사 분포)를 가져야 한다.
- Simple Random Sampling
➔ 임의로 동등한 확률로 데이터를 뽑는다. - Sampling without replacement
➔ sample데이터로 뽑힌 데이터는 모집단에서 제거한다 - Sampling with replacement
➔ sample데이터로 뽑힌 데이터를 모집단에서 제거하지 않는다. - Stratified sampling
➔ 데이터를 속성에 따라 여러 부분으로 나누고 부분에서 임의로 데이터를 추출한다. - Progressive Sampling : 작은 샘플 수에서 시작하여 충분한 크기가 될 때까지 증가시킨다.
Dimensionality Reduction
Curse of Dimensionality
- 차원이 증가할수록 데이터는 공간에서 sparse하게 된다.
- 분류 문제에서는 모델을 분류하는데 충분한 데이터가 생성되지 않음을 의미한다.
- clustering이나 outlier detection에서는 두 점 사이의 거리나 밀도가 커져 의미를 잃게 된다.
목적
- 데이터 마이닝에 필요한 시간과 memory를 줄이기 위해서
- 데이터 시각화를 수월하게 하기 위해서
- noise와 불필요한 요소 제거에 도움을 받기 위해서
- Curse of dimensionality를 회피하기 위해
기법
- Principle Component Analysis (PCA)
- Singular Value Decomposition (SVD)
- Supervised and non-linear techniques etc..
Principle Component Analysis (PCA)
-
projection을 통해 데이터 손실을 최소화하는 eigen vector 도출
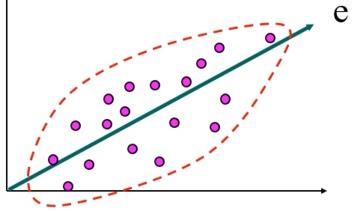
-
covariance matrix를 사용하여 eigen vector를 찾고 새로운 공간을 정의한다
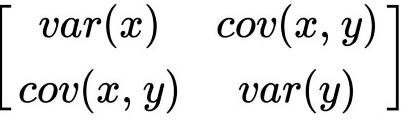
Feature Subset Selection
Redundant Feature (제거가 목적)
- 중복되거나 다른 attribute에 포함되어 있는 정보 (상품 가격과 tax 정보)
Irrelevant feature
- 데이터 마이닝에 유용하지 않는 feature (GPA를 구하는 데 사용되는 학번 정보)
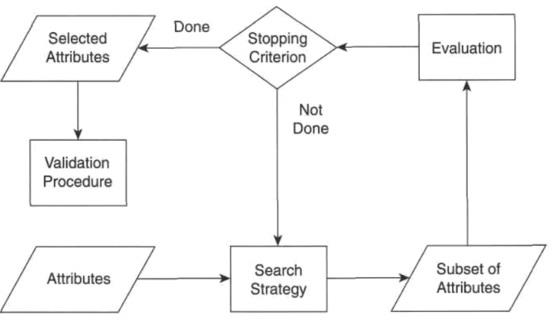
Approaches
- ideal approach : 가능한 모든 subset을 테스트하여 결과가 가장 좋은 subset을 고르는 방법
➔ n개의 attributes가 있다면 총 2^𝑛개의 subset을 테스트해야 하므로 비효율적이다. - domain knowledge나 상식을 이용하여 irrelevant/redundant feature를 제거한다.
- Embedded approaches
➔ 데이터 마이닝 적용 중에 적절한 feature를 고르는 방법(Lasso, Ridge Regression etc) - Filter approaches
➔ 데이터 마이닝 적용 전에 데이터 간의 pairwise correlation을 최대한 낮게 하는 것을 고른다.
➔ target data mining algorithm과 독립적으로 동작한다.
➔ 주어진 attribute set에 대해 실제 데이터 마이닝 알고리즘이 얼마나 잘 수행되는지 예측 - Wrapper approaches
➔ Filter와 embedded 방법의 중간 단계, target data mining algorithm을 사용한다.
➔ 가능성이 있는 subset을 계산 비용을 감당할 수 있을 정도로 선택하여 계산하는 방법 - Feature weighting
➔ 가중치가 0인 attribute를 제거하는 방법
Validation for FSS
- Straightforward evaluation approach
➔ 모든 데이터셋을 사용한 결과와 FSS의 결과로 도출된 데이터셋의 결과를 비교하는 방법 - Validation approach
➔ 여러 FSS 방법으로 도출된 데이터셋을 이용한 정확도를 교차 검증하는 방법
Feature Creation
- 원래의 attributes보다 더 효율적으로 동작하는 정보를 생성하는 방법
Feature Extraction
- 원시 데이터에서 새로운 데이터를 만드는 방법 ex)얼굴 pixel에서 선에 대한 정보를 생성
- 기존 데이터에서 재정의해서 만들며 특정 영역에서만 유효하다. Domain - specific
Feature Construction
- 기존의 데이터를 조합하여 정보를 생성 ex) 밀도 = 질량/부피
Mapping data to new space
- Fourier transformation : time domain > frequency domain
- Wavelet transform : frequency + time data
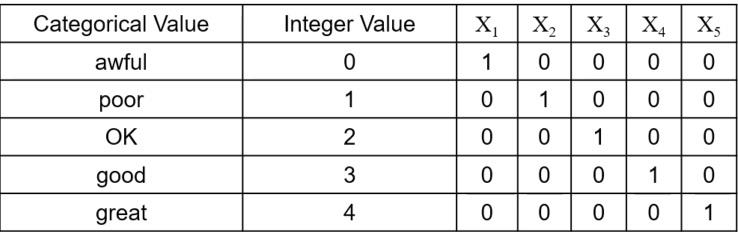
Discretization (=Categorization)
- continuous attribute를 categorical attribute로 변환한다.
Binarization
-
continuous/discrete attributes를 하나 이상의 binary attribute로 변환한다.
-
원시 데이터를 [0, m-1] 범위의 categorical value에 할당한다. m은 데이터 개수
-
변환된 정수를 이진수로 변환한다. n = ceiling(log2 𝑚) 만큼의 수가 필요하다.
-
순서가 있다면 다음과 같이 표현하며
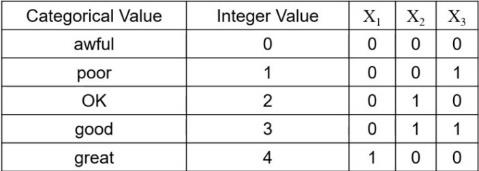
-
순서가 없다면 단일 값으로 나타낸다.
-
관련성 분석 모델에서는 1이 나타난 것끼리 correlated하다고 간주하기 때문에 ok, good 등을
연관 있는 것이라고 간주하기 때문에 One-Hot코드로 나타내야 한다.
Standardization and Normalization
- 공통된 속성을 가지도록 변환해준다

Standardization : 𝑍 = (𝑋−𝑋𝑚𝑖𝑛) / (𝑋𝑚𝑎𝑥−𝑋𝑚𝑖n)
Normalization : 𝑍 = (𝑋−mu) / sigma 분포의 성향을 띌 때
Measures of Similarity and Dissimilarity
Similarity
- 두 data object간의 유사성을 수치형으로 표기하며 비슷할수록 높은 값을 가진다.
- 대부분 [0, 1] 사이의 값을 가진다.
Dissimilarity
- 두 data object간의 상이성을 수치형으로 표기하며 비슷할수록 낮은 값을 가진다.
- 하한은 0의 값을 가지며 상한의 값은 다양하게 설정된다.
Proximity : similarity + dissimilarity
- 유사성과 상이성의 변형
- Similarity가 [0, 1]의 값을 가질 때, dissimilarity를 d = 1 – s로 나타낼 수 있다.
- similarity를 dissimilarity의 반대 부호 값으로 지정할 수 있다.
- proximity를 [0, 1]의 값으로 변형 : p = (s – min_s) / (max_s – min_s)
- non-linear transformation : 𝑑' = d / d + 1
➔ [0, 1]사이로 값이 mapping되지만 값들이 1의 근처로 몰리게 된다. - Correlaton [-1, 1]을 절댓값을 취함으로써 [0, 1]의 값을 얻는 방법
objects with a single nominal attribute
- similarity : 1 if attribute values match, 0 otherwise
- dissimilarity : 1 if attribute values mismatch, 0 otherwise
objects with a single order attribute
- 순서에 대한 정보를 포함해야하므로 연속적인 정수에 mapping한다.
- poor = 0 / fair = 1 / ok = 2 / good = 3 / wonderful = 4
- d(p1, p2) = |3 – 2| or |3 – 2|/4 for [0, 1] (min-max scaling)
- s = 1 - d

City block distance
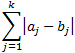
dissimilarity between two data objects : Euclidean distance (ex/ annual sales of two companies)
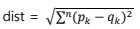
두 벡터의 크기가 다르다면, 표준화가 필요하다
Similarity between binary vectors
- binary attributes를 가지는 2개의 data object의 유사성을 나타내는데 사용한다.
- 𝑓01 = 𝑡ℎ𝑒 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒𝑠 𝑤ℎ𝑒𝑟𝑒 𝑥 𝑤𝑎𝑠 0 𝑎𝑛𝑑 𝑦 𝑤𝑎𝑠 1
- 𝑓10 = 𝑡ℎ𝑒 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒𝑠 𝑤ℎ𝑒𝑟𝑒 𝑥 𝑤𝑎𝑠 1 𝑎𝑛𝑑 𝑦 𝑤𝑎𝑠 0
- 𝑓00 = 𝑡ℎ𝑒 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒𝑠 𝑤ℎ𝑒𝑟𝑒 𝑥 𝑤𝑎𝑠 0 𝑎𝑛𝑑 𝑦 𝑤𝑎𝑠 0
- 𝑓11 = 𝑡ℎ𝑒 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒𝑠 𝑤ℎ𝑒𝑟𝑒 𝑥 𝑤𝑎𝑠 1 𝑎𝑛𝑑 𝑦 𝑤𝑎𝑠 1
Simple Matching Coefficient (SMC) (ex/ true false questions)
- number of matches / number of attributes
- (𝑓11 + 𝑓00) / (𝑓01 + 𝑓10 + 𝑓00 + 𝑓11 )
Jaccard Coefficient (ex/ taking course)
- asymmetric binary attributes로 이루어진 objects를 다루는데 사용한다
- Transaction matrix : 0 (not purchased), 1 (purchased)
- J = 𝑓11 / (𝑓01 + 𝑓10 + 𝑓11)
Cosine Similarity (ex/ document vectors)
- cos(d1, d2) = (d1 ∙ d2) / ||d1|| ||d2||
- ||d1|| : d1벡터의 길이 -> d1 = (3 2 0 5)
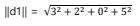
Correlation (ex/ stock prices)
- correlation measures the linear relationship between the attributes of the objects

Hamming distance
- binary attributes만을 가진 data objects의 다른 값을 가진 bit수를 나타낸다.
Issues in Proximity Calculation
- How to handle the case in which attributes have different scales and/or are correlated.
- Mahalanobis Distance
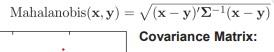

KHU, SWCON