이번 내용도 탐색과 관련되있어 앞선 탐색1,2의 연장으로 볼 수 있지만!!!!
트리와 관련된 어떠~한 것도 언급되지않는다!!!!
오예!!!!
테이블 자료구조의 이해
AVL트리는 탐색과 관련하여 매우! 만족스러운 성능을 보였지만.... 탐색 키의 비교과정을 거치는 과정이 찾는 대상에 가까워지는 방식이기에 "단번에" 찾아내는 방식이라고 말하기는 무리가 있다.
그래서 이러한 상황에 도입을 검토할 수 있는 자료구조가 바로 테이블이다.
"그럼 테이블은 단번에 찾나요!?"
물론 말이 단번에지만
AVL tree 가 시간 복잡도 로그 이엔을 가지는 반면
테이블은 O(1)의 시간 복잡도를 가진다!!!!

이러니 단번에 라는 표현이 과장이아니다!!!
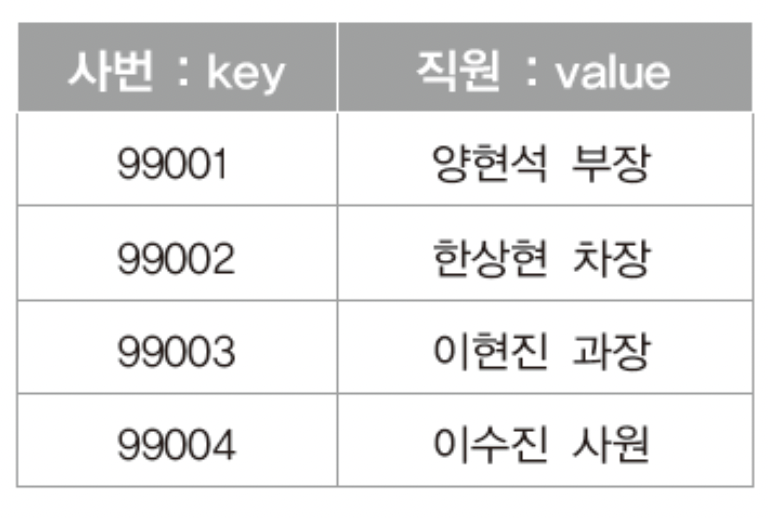
테이블은 한국말로 표 이고 표는 테이블이다!
위의 그림과 같은 것을 테이블 이라고 하는데 그렇다고!
모든 표가 테이블은 아니다!
"저장되는 데이터는 키와 값이 하나의 쌍을 이룬다"
이런 형태를 뛸 때만 !
테이블 자료구조라고 말할수 있다.
테이블에 저장되는 모든 데이터들은 이를 구분하는 "키"가 있어야하고 이 키는 데이터를 구분해야하는 기준이 되기 떄문에 중복이 되어서는 안된다!
이러한 키에는 다음 조건이있다.
"키가 존재하지 않는 값은 저장할 수 없다. 그리고 모든 키는 중복되지 않는다."
이러한 키를 현실세계에서 쉽게 볼 수 있다!
바로 우편함아니겠는가!?
"호수"가 키가 되고 "우편물"이 "값"이되어
특정 호수의 우편물은 "단번에" 찾아낼 수 있지 않는가!?
이정도면 충분히 이해했지만 테이블에 대한 정확한 이해를 돕는 또 하나의 예가 있다
바로 사전이다.
사전또한 테이블 자료구조이다!
"사전? 사전에서 단번에 원하는 단어 어떻게찾아요;;?"
라는 의문이 들수 있다!
맞다!!
하지만! 단번에 찾지 못하는 이유는 산전에 담긴내용이 워낙 방대해서 그렇다!
사전의 아무페이지나 펼쳐보면
단어(key)에 단어 설명(value)가 있다!!
이것은 얼마든지 표로 구성할 수 있지 않겠는가!?
자료구조의 관점에서 줄과 깔끔한편집상태는 테이블과는 아무상관없다.
이러한 이유로 자료구조의 "테이블"은 "사전구조"라고도 불린다!
더불어 "맵"이라 불리기도 한다.
그럼 이제 배열을 기반으로하는 테이블을 한번 작성해보자.
//
// main.c
// HashTable
//
// Created by 서희찬 on 2021/04/22.
//
#include <stdio.h>
typedef struct _empInfo
{
int empNum; // 직원의 고유번호
int age; // 직원의 나이
}EmpInfo;
int main(void)
{
EmpInfo empInfoArr[1000];
EmpInfo ei;
int eNum;
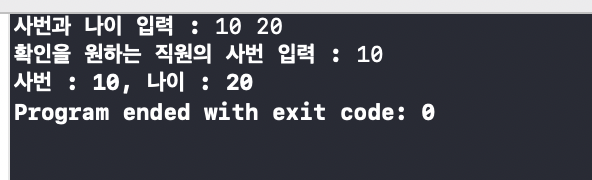
printf("사번과 나이 입력 : ");
scanf("%d %d",&(ei.empNum),&(ei.age));
empInfoArr[ei.empNum] = ei; // 단번에 저장
printf("확인을 원하는 직원의 사번 입력 : ");
scanf("%d",&eNum);
ei = empInfoArr[eNum]; // 단번에 탐색 !
printf("사번 : %d, 나이 : %d \n",ei.empNum,ei.age);
return 0;
}
typedef struct _empInfo
{
int empNum; // 직원의 고유번호(Key)
int age; // 직원의 나이(value)
}EmpInfo;구조체에서 키와 값을 하나의 쌍으로 묶었다.
이제 구조체 기반으로 하는 배열을 보자
EmpInfo empInfoArr[1000];//직원들의 정보를 저장하기 위해 선언된 배열
이 배열만을 가리켜 테이블이라고 하기에는 부족해 보인다.
테이블 이라고 하면
"키를 결정했다면 이를 기반으로 데이터를 단번에 찾을 수 있어야한다"
를 만족해야한다.
즉, 키는 데이터를 찾는 도구가 되어야한다!! 그것도 단번에!
그래서
위에서 이렇게 사용하였다
- 저장 empImfoArr[ei.empNum] = ei;
- 탐색 ei = empInfoArr[eNum];
뭔지 알겠는가!?
그렇다!
직원의 고유번호를 인덱스 값으로 하여, 그 위치에 데이터를 저장하였다.
이렇듯 키의 값은 저장위치!
라는 관계를 형성하여, 단번에 데이터를 저장하고 탐색할 수 있게 하였다.
그러므로 위의 배열은 테이블의 구현결과이다!!!
그런데..
직원 고유번호가 100000000이면 위와 같은 방식의 테이블을 구성하려면 매우~ 큰 배열이 필요하져??
라는 의문이 안들수가 없다!!
이것이 바로 문제점이다!!
이러한 문제점은 바로 테이블의 핵심인"해쉬"와 관련된 내용이 빠져서 등장한것이다!!
그럼 바로 다음포스트에서 해쉬에 대해 배워보자 !
