
- 2022년 12월 개인적으로 진행했던 토이프로젝트를 재업로드합니다.
3. EDA
1) Data Load
- path : 데이터가 저장된 경로
basket=pd.read_csv(path)
basket=basket.drop(basket.columns[0],axis=1)
basket.head(10)
head.shape(2761, 41)
basket.columnsIndex(['Team_H', 'Team_A', 'HomeWin', 'MP_H', 'FG_H', 'FGA_H', 'FG%_H', '3P_H',
'3PA_H', '3P%_H', 'FT_H', 'FTA_H', 'FT%_H', 'ORB_H', 'DRB_H', 'TRB_H',
'AST_H', 'STL_H', 'BLK_H', 'TOV_H', 'PF_H', 'PTS_H', 'MP_A', 'FG_A',
'FGA_A', 'FG%_A', '3P_A', '3PA_A', '3P%_A', 'FT_A', 'FTA_A', 'FT%_A',
'ORB_A', 'DRB_A', 'TRB_A', 'AST_A', 'STL_A', 'BLK_A', 'TOV_A', 'PF_A',
'PTS_A'],
dtype='object')
2) Features
같은 세부 스탯에 대해 홈팀에 대한 feature와 원정팀에 대한 feature가 각각 존재합니다. 따라서 feature 설명은 세부 스탯별로 한번씩만 진행합니다. 홈팀에 대한 feature 명은 "세부스탯명_H"이고, 원정팀에 대한 feature명은 "세부스탯명_A"입니다.
- Team : 경기 대상인 각 팀을 의미, 팀명 대신 대문자 알파벳 3개로 나타나는 팀별 표기명을 사용
- HomeWin : 홈팀이 이겼는지의 여부를 나타내는 feature. 홈팀이 승리한 경기의 경우 1, 홈팀이 패배한 경기의 경우 0.
- 우리 모델의 label으로 사용할 feature
- KBL에서 제공하는 2Q 종료 후 기대 승률은 해당 경기의 홈팀을 기준으로 제공됩니다. 즉, 홈팀의 승률을 제공하는 것이죠. (홈팀의 득점이 실점보다 많을수록 기대 승률이 높아짐) 따라서 우리가 사용할 NBA데이터의 label 역시 홈팀의 승리 여부를 기준으로 설정했습니다.
- MP : Minutes Played
- 각 선수들이 경기에 뛴 시간의 총합
- NBA는 한 쿼터 당 12분씩 경기를 하고, 한번에 팀당 5명의 선수가 출전하므로 전반전의 총 MP는 팀별 120으로 일정한 상수. (12x2x5=120)
- 팀과 경기에 관계 없이 항상 같은 수치를 가지므로 삭제합니다.
- FG : Field Goals
- 코트 내에서 슛을 던졌을 때 해당 슛이 골이 된 횟수 (총 야투 성공 횟수)
- 2점슛, 3점슛 모두 포함
- 자유투(1점)은 제외
- FGA : Field Goal Attempts
- 총 야투 시도 횟수 (슛을 던진 횟수)
- 2점슛, 3점슛 모두 포함
- 자유투 제외
- FG% : Field Goal Percentage
- 총 야투 성공률
- FG/FGA
- 3P : 3-Point Field Goals
- 3점 야투 성공 횟수
- 3PA : 3-Point Field Goal Attempts
- 3점 야투 시도 횟수
- 3P% : 3-Point Field Goal Percentage
- 3점 야투 성공률
- 3P/3PA
- FT : Free Throws
- 자유투 성공 횟수
- 1점
- FTA : Free Throw Attempts
- 자유투 시도 횟수
- FT% : Free Throw Percentage
- 자유투 성공률
- FT/FTA
- ORB : Offensive Rebounds
- 공격리바운드 수
- 공격리바운드 : 공격 야투 시도 및 실패 후 공격을 시도한 팀의 선수가 리바운드를 따낸 경우
- DRB : Defensive Rebounds
- 수비리바운드 수
- 수비리바운드 : 공격 야투 시도 및 실패 후 공격을 시도하지 않은 팀 (수비를 하고 있던 팀)의 선수가 리바운드를 따낸 경우
- TRF : Total Rebounds
- 총 리바운드 수
- ORB+DRB
- AST : Assists
- 어시스트 수
- STL : Steals
- 스틸 : 상대가 공격중일 때 파울 없이 상대의 공을 가로채 공격권을 가져오는 것
- BLK : Blocks
- 블락 : 수비자가 반칙을 하지 않고 공격자가 슛한 공을 쳐낸 것
- TOV : Turnovers
- 턴오버 : 공격을 하던 팀이 패스 실수, 상대의 스틸 등으로 공격권을 빼앗기는 것
- PF : Personal Fouls
- 파울 횟수
- 한 쿼터에서 팀 통틀어 4회 이상 파울 시 다음 파울부터는 상대팀에게 자유투가 주어진다.
- PTS : Points
- 총 득점
- (FG-3P)x2+3Px3+FT=PTS
3) Data Summarise
(1) Summarise Statistics
basket.describe()
- MP feature의 경우 상수값을 가진다.
(2) NA 값 확인
basket.info()
basket.isna().sum()
- FT%_H와 FT%_A feature에 NA값이 존재합니다. 해당 feature에 NA값이 존재하는 경기를 실제 사이트에서 찾아본 결과, 전반전동안 해당 팀의 자유투 시도 횟수(FT_H 혹은 FT_A)가 0이기 때문에 자유투 성공률(FT%_H 혹은 FT_A%)이 NA값을 가집니다.
4) EDA
(1) feature 별 분포 확인
col_n = 4
row_n = 10
fig, ax = plt.subplots(ncols=col_n, nrows=row_n, figsize=(20,row_n*5))
for i,col in enumerate(basket.columns[2:]):
sns.kdeplot(x=basket[col],data=basket, ax=ax[int(i/col_n),int(i%col_n)], hue="HomeWin")
- 각 변수의 분포 자체는 승리/패배 여부에 관계없이 비슷하며, 거의 정규분포 형태를 가집니다.
right skewed 형태를 띠는 다음 변수들은 log transformation을 고려해볼만 합니다.
- FT_H / FT_A
- FTA_H / FTA_A
- ORB_H / ORB_A
- STL_H / STL_A
- BLK_H / BLK_A
그러나 BLK_H와 BLK_A를 제외하고는 skewed된 정도가 그리 심하지 않기 때문에 추후 BLK_H와 BLK_A만 log transformation을 진행합니다.
left skewed 형태를 띠는 'FT%_H','FT%_A'는 square transformation을 진행합니다.
경기 결과는 홈팀/원정팀의 상대적인 스탯에 따라 결정되기 때문에 홈팀이 원정팀에 '비해'얼마나 잘 했는지가 중요합니다. 따라서 홈팀의 경기 승리 여부에 따라 홈팀과 원정팀의 스탯 차이 분포에 차이가 있는지 확인해 볼 필요가 있습니다.
- 득점(PTS), 야투율(FG%,3P%), 리바운드(TRB) 총 4가지의 주요 스탯에 대해서만 홈/원정 팀의 스탯 차이를 나타내는 변수들로 이루어진 데이터프레임을 생성하여 확인하고자합니다.
- 추후 모델 fitting에서는 홈팀의 스탯과 원정팀의 스탯이 함께 고려되기 때문에 홈팀과 원정팀의 스탯 차이를 나타내는 feature를 만들 필요까지는 없을 것으로 보입니다.
basket_diff=pd.DataFrame(columns=['PTS','FG%','3P%','TRB','HomeWin'])
basket_diff['HomeWin']=basket['HomeWin']
basket_diff['PTS']=basket['PTS_H']-basket['PTS_A']
basket_diff['FG%']=basket['FG%_H']-basket['FG%_A']
basket_diff['3P%']=basket['3P%_H']-basket['3P%_A']
basket_diff['TRB']=basket['TRB_H']-basket['TRB_A']
basket_diff.head(10)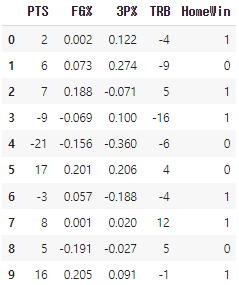
col_n = 4
row_n = 1
fig, ax = plt.subplots(ncols=col_n, nrows=row_n, figsize=(20,row_n*5))
for i,col in enumerate(basket_diff.columns[:-1]):
sns.kdeplot(x=basket_diff[col],data=basket_diff, ax=ax[int(i%col_n)], hue="HomeWin")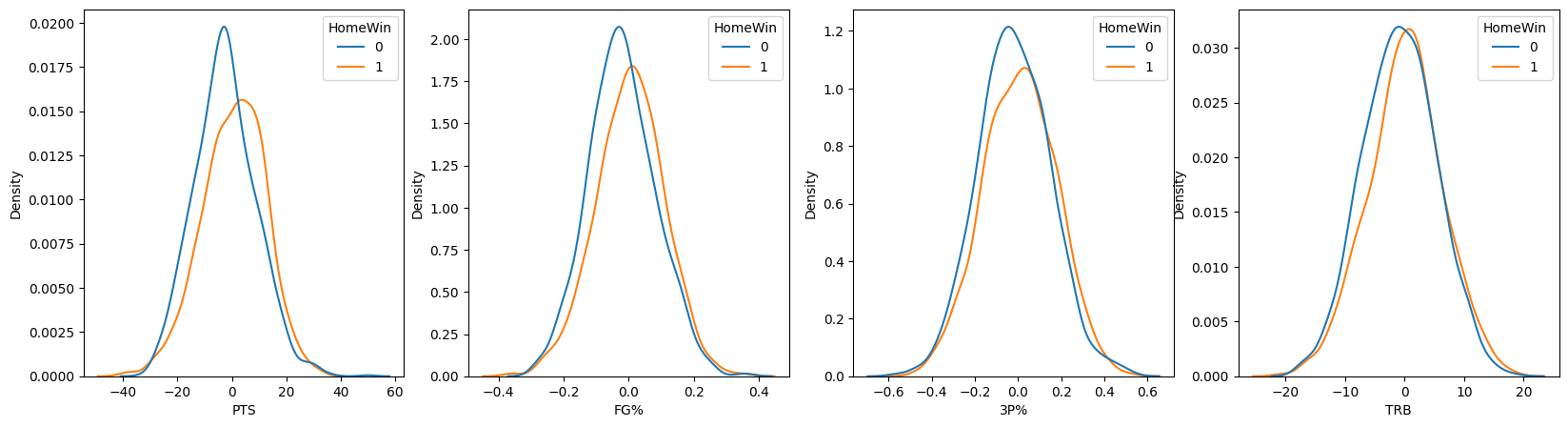
- 'PTS','FG%','3P%','TRB' 모두 수치가 큰 값 일수록 좋다.
위 그래프에서 볼 수 있듯 홈팀의 승리/패배에 따라 주요 스탯의 분포가 약간씩 다르다는 것을 알 수 있으며, 홈팀이 승리한 경우 해당 feature의 차이가 더 오른쪽으로 치우칩니다. 이는 곧 승리했을 경우 해당 feature들에 대해 홈팀이 원정팀에 비해 더 높은 수치의 값을 가짐을 의미하고, 일반적인 해석과 일맥상통합니다.
(2) feature 간 correlation 확인
basket_corr=basket[2:].corr()
plt.figure(figsize=(20,20))
sns.heatmap(basket_corr, annot=True, fmt=".2f", cmap="Blues")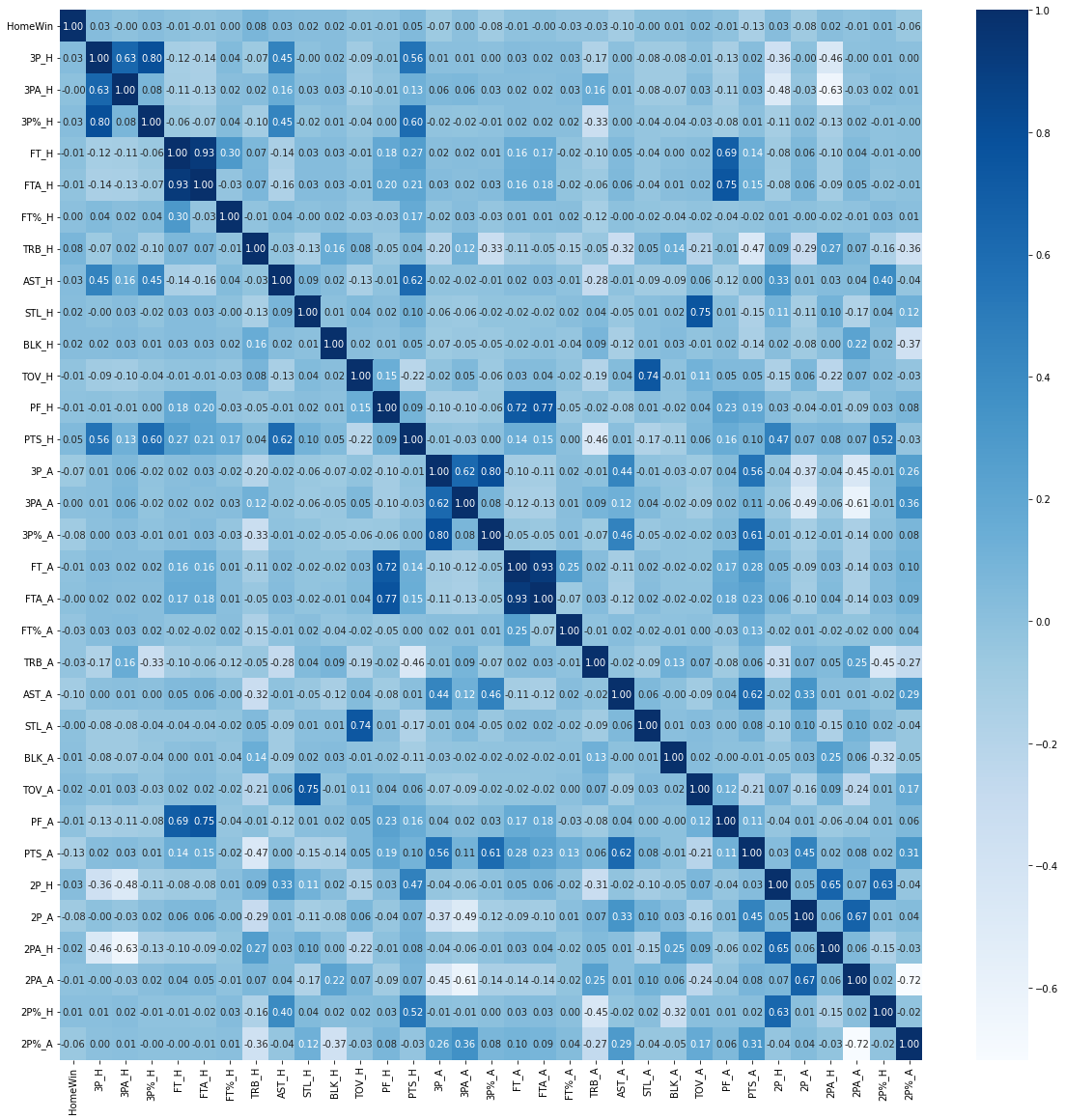
- correlation이 강한 몇몇 변수들이 보이네요. 특히 3P,3PA,3P%와 같이 비슷한 경기 내용을 다루는 변수들 간의 상관관계가 비교적 크게 나타납니다.
