Large Language Models are Zero-Shot Rankers for Recommender Systems
Abstract
추천 문제를 ranking task로 정의.
본 논문에서는 LLM이 zero-shot ranking 능력이 뛰어남을 보였으나
1) historicla itneraction order를 인지하는데 struggle하고 있고
2) popularity나 item postion등에 의해 bias가 생김
이는 특별하게 고안된 prompting이나 bootsrapping staregies로 해결 가능!
1. Introduction
LLM을 ranker로 활용하기 위해 다음 두 가지 질문을 대답하고자 한다.
– What factors affect the zero-shot ranking performance of LLMs?
– What data or knowledge do LLMs rely on for recommendation?
그리고 다음과 같은 finding을 찾았다 !!
– LLMs struggle to perceive the order of the given sequential interaction
histories. By employing specifically designed promptings, LLMs can be
triggered to perceive the order, leading to improved ranking performance
– LLMs suffer from position bias and popularity bias while ranking, which can
be alleviated by bootstrapping or specially designed prompting strategies
– LLMs outperform existing zero-shot recommendation methods, showing
promising zero-shot ranking abilities, especially on candidates retrieved by
multiple candidate generation models with different practical strategies.
3.1 Can LLMs Understand Prompts that Involve Sequential Historical User Behaviors?
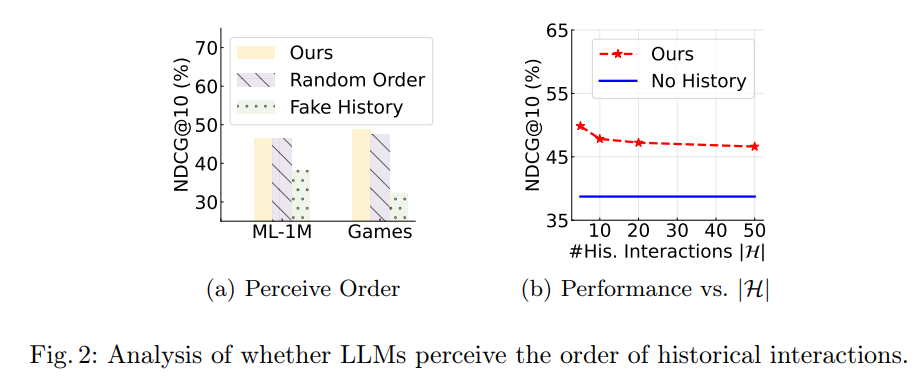
흥미로운 결과인데, Ours model이 History Random Order로 줬을 때 성능이 비슷하고,
또 history item 수를 늘릴수록 성능이 떨어짐
=-> 이는 recency 반영이 안되고 모든 아이템을 동등하게 처리하기 때문에 아이템이 많아질수록 성능이 저하되는 것임
따라서 최신 아이템 기록 짧게 주는게 제일 좋음!
3.2 Do LLMs suffer from biases while ranking?
candidate에서 order역시 성능에 영향을 줌
candidate에서 정답이 뒤에 있을수록 성능 떨어짐
-> bootstrapping을 통해서 여러번 candidate 섞은 다음 결과 merging해서 도출하면 개선됨
popularity bias
=> user history에 집중하게 하면 됨
-> history 길이를 줄여서 거기 잘 보도록(prompt history 길이 줄이기)
3.3 How Well Can LLMs Rank Candidates in a Zero-Shot Setting?
파라미터 수가 많은 LLM일수록 성능이 좋음.
LLM-based model은 기존 zero-shot 방법들을 크게 능가.
특히 ML-1M dataset에서도, title similarity만으로는 힘든 추천 task를 LLM의 내재된 지식으로 해결.
쨌든.. 흥미롭고 LLM (GPT가져다가) Zero-shot task를 제대로 했다는 점! 코드도 다 있음
zero-shot에서 attack은 의미가 없을까?
