SOREC과 같은 저자가 쓴 논문. 한 분야에 대해 이렇게 몇 년간 논문을 내는 거구나,,
Abstract
matrix factorization framework에 social regularization을 더해서 추천 시스템에 social network information을 합치겠다!
Introduction
"trust relationships" 와 "social friendships"는 다르다.
social friendship의 경우 관계에서 confirm이 필요함
너무 많은 다양한 친구를 가진 경우 친구라고 비슷한 취향을 가질 것이라는 보장이 없음
본 논문에서는 두 regularization terms를 이용해서 social network information를 반영하고자함!
Related Work
trust value들을 user간 similarity에 추가 [24]
SoRec [23]
=> Pysical interpretation이 부족
[22]에서는 realisitcally하게 하기 위해서 user의 final rating decision을 user's own taste와 trusted users' favors를 밸런스하는데 이용
[20]에서는 text-based predictor에 regularization constraints 더함
[23]의 경우 trust-aware method고
나머지 previous work에서도 social network information을 제대로 활용하고 있지 못함
본 노문에서는 social recommendation problem을 분석하고, social recommender system과 trust-aware recommender system의 차이를 분명히 하겠다
5. Social Regularization
5.1 Model1: Average-based Regularization
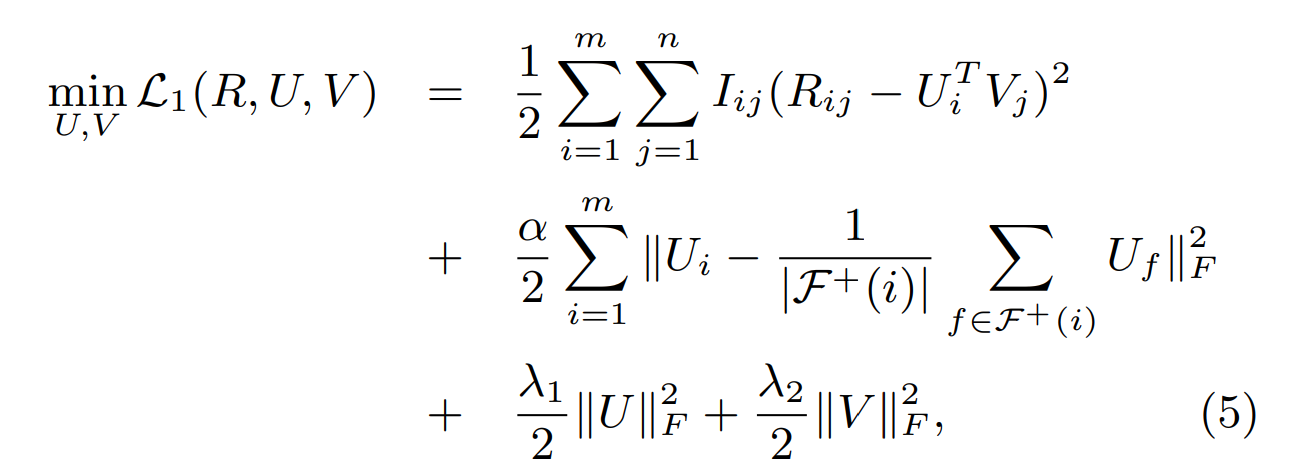
기존의 Matrix-facorization에 social regularization term 추가
이러한 term 덕분에 user의 taste는 그 user의 friend들의 taste의 평균에 가까워진다!
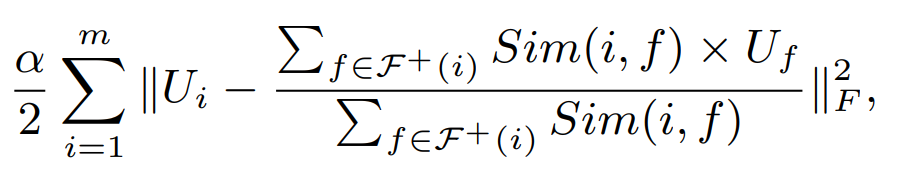
하지만 친구가 많은 경우 그 모든 친구들이 user와 similar한 taste를 가졌다고 볼 수 없기 때문에 위와같이 비슷한 정도를 반영해서 낸 가중 평균에 가까워지도록 한당
5.2 Model2: Individual-based Regularization
5.1 model의 문제점은 친구들이 다양한 taste를 가진 user에게 적절하지 않음. 따라서 one user와 user의 친구를 개별적으로 맵핑하는 term을 제안
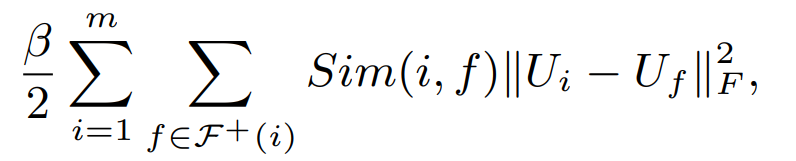
나누기 2는 아마도 같은 pair에 대해서 두번씩 계산해서 있는 거 아닐까??
이 방법의 장점은 ui와 uf가 친구고, uf, ug가 친구인 경우 Ui와 Ug 사이의 distance 역시 가까워지도록 taste가 propagate된다는 것임!!
5.3 Similarity Function
user간의 similarity 정의
1) VSS
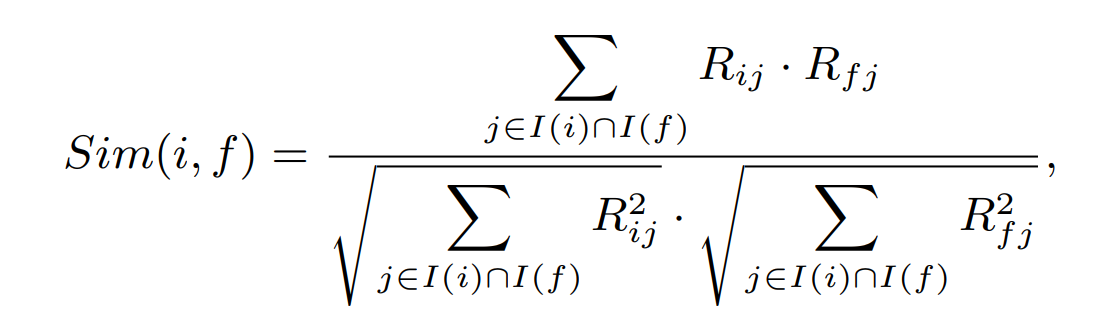
[0,1] 사이의 값을 갖는데, 이 방식의 문제는 user마다 rating style이 다르다는 것을 간과함 (누구는 일반적으로 높은 평점을 주고, 누구는 낮게 주는 이런 평균값이 반영이 안됨)
그래서 PCC 등장
2)PCC
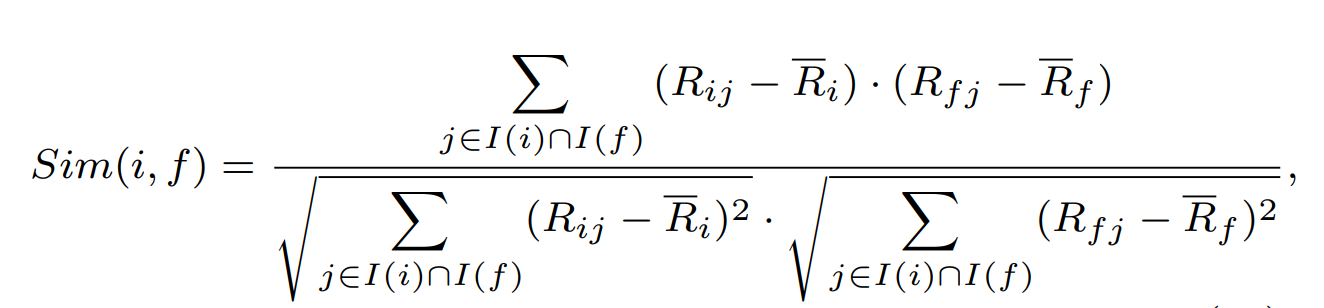
이런 식으로 연산하기 때문에 평균값을 빼줘서 보다 적절하게 user간 유사도 계산 가능
문제는 음수가 나올 수 있어서 이 값의 범위가 [-1, 1]이 됨 따라서 본 논문에서는 f(x) = (x+1)/2를 통과시켜서 유사도 값이 [0, 1]이 되도록 함
