Big data
5Vs
- volume (규모)
- 1 PB = 1024 TB = 1,048,576 GB

- variety (다양성)
- structured, unstructured, semi structured
- velocity (속도)
- variability (변동성)
- veracity (정확성)
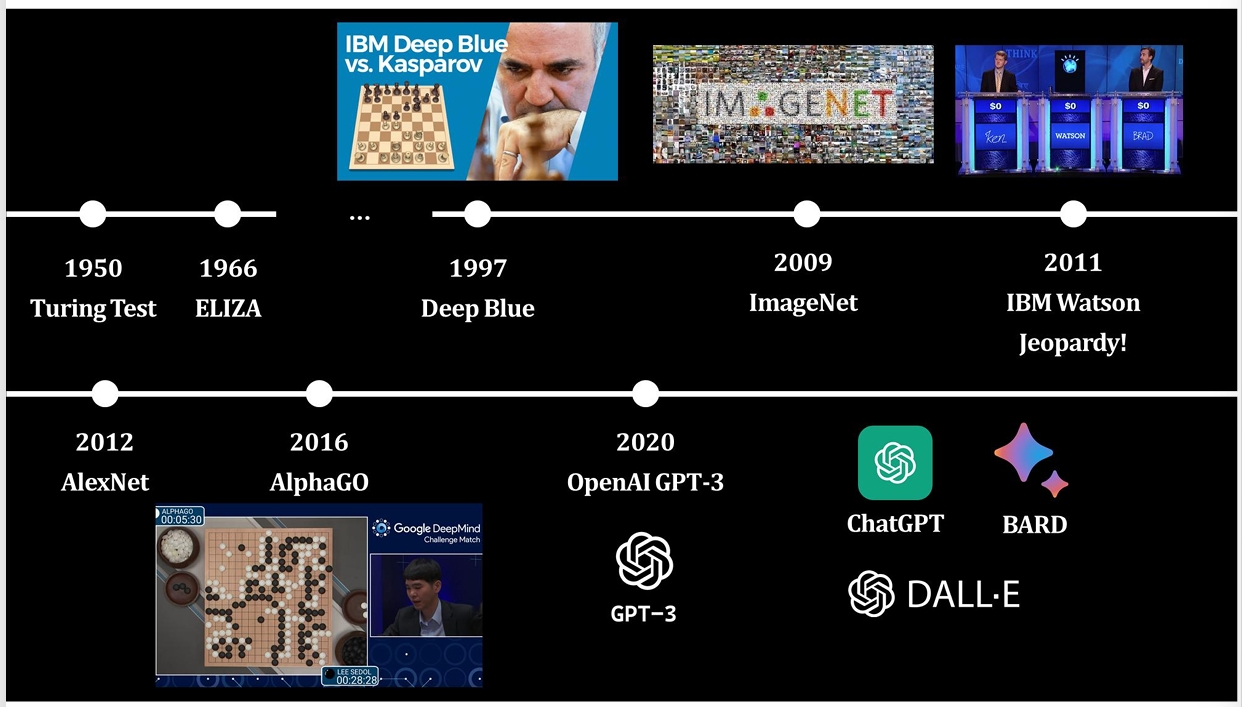
인공지능의 변천과정
1950 Turing Test
1966 Eliza
1997 Deep Blue
2009 ImageNet
2011 IBM Watson Jeopardy
2012 AlexNet
2016 AlphaGo
2020 OpenAI GPT-3
2021 ChatGPT BARD DALL-E
Machine Learning
System that learns patterns from data and improve performance without explicit programming
ex) Supervised Learning, Unsupervised Learning, Reinforcement Learning
Multi Layer Perceptron
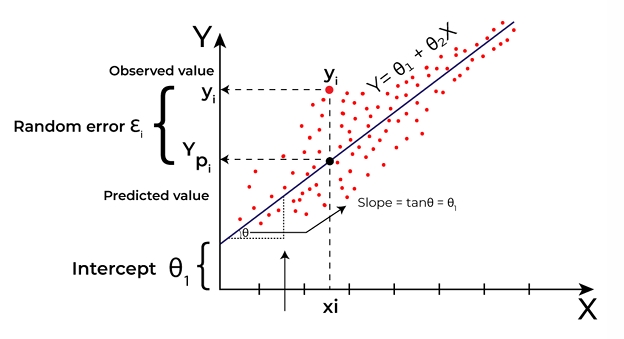
Linear Regression
- statistical / machine learning algorithm used to model the relationship between one or more independent variables(features) and a dependent variable (target)
Non-Linear Activation Function
ANN (Artificial Neural network)
- consists of multiple layers of neurons including non-linear activation functions
- fully connected feedforward network with at least one hidden layer
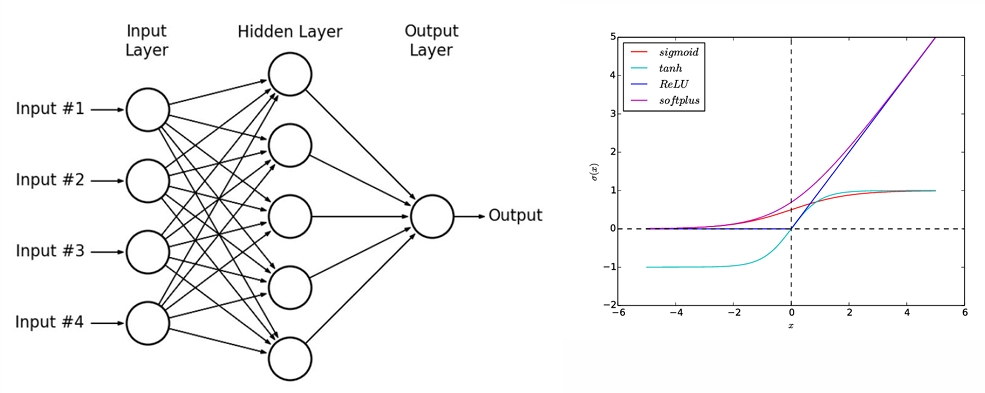
비선형 활성화 함수?
뉴런의 출력값에 비선형 변환을 적용하는 함수
선형함수만 사용하면, 신경망이 깊어져도 표현력에 한계가 있음
비선형성을 도입하여 복잡한 패터학습 가능
1. Sigmoid
- S자 형태 곡선
- 출력이 항상 (0,1)사이 --> 확률값처럼 사용 가능
장점: 확률적 해석 가능, 로지스틱 회귀, 초기 딥러닝에서 많이 사용
단점: Vanishing gradient problem, 입력이 커지면 기울기 거의 0 --> 학습이 느려짐
출력이 0을 중심으로 하지 않음 --> 중심이동 안됨 --> 느린 수렴
2. Tanh (Hyperbolic Tangent)
- Sigmoid와 유사하지만 중심이 0임
- 출력 범위: (-1, 1)
장점: 중심이 0이라 학습이 더 안정적, sigmoid보다 성능이 일반적으로 더 좋음
단점: vanishing gradient 발생 가능
3. ReLU (Rectified Linear Unit)
0 이하에서는 0, 0 초과에서는 그대로 출력
f(x)=max(0,x)
장점: 계산이 매우 간단하고 빠름, Gradient Vanishing 문제 해결, 딥러닝 에서 기본 활성화 함수로 자주 사용
단점: Dead Relu 문제: 음수 입력이 계속되면 뉴런이 죽은 상태가 됨 (출력 0, 학습 불가)
4. Softplus
- ReLU의 스무딩(smooth) 버전
- 도함수가 sigmoid와 같음
장점: 미분가능, ReLU의 장점을 유지하면서 수학적으로 안정적
단점: 계산량이 ReLU보다 많아 속도가 느림

Neuro-symbolic AI researcher