Lecture
1.Advanced Big data

Big data: 기존의 도구로는 처리 불가능한 대규모의 복잡한 데이터 기존 방법: 수작업 (feature engineering) --> 현재 방법: 대량의 데이터를 통해 AI가 feature를 자동학습 단어표현 (sparse vs Dense Representatio
2.Artificial Intelligence

volume (규모)1 PB = 1024 TB = 1,048,576 GBvariety (다양성) structured, unstructured, semi structuredvelocity (속도)variability (변동성)veracity (정확성)1950 Turing
3.Image Processing
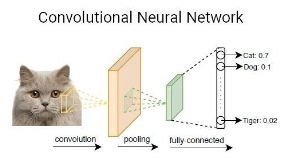
There are tasks in Image processing,Image ClassificationObject DetectionSemantic SegmentationInstance SegmentationImage CaptioningImage GenerationImag
4.Knowledge Graph Embeddings
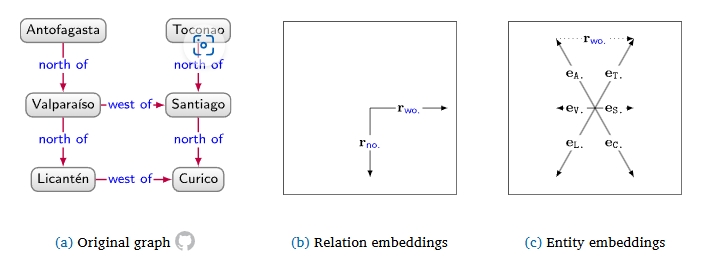
KG: 기계학습에서 추천, 정보 추출, 질의 응답에서 활용(Recommender system, information extraction, question answering, query relazation, query approximation, etc)embedding:
5.Full-text Information Retrieval
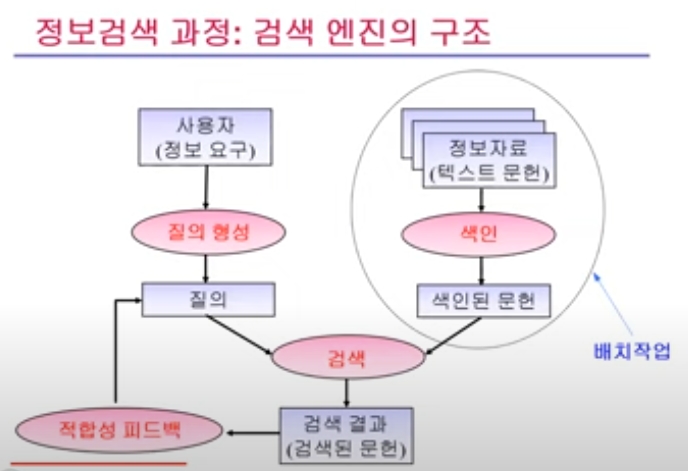
신문기사, 문학작품, SNS(트위터, 블로그, 영화평)음성인식 목적: 지역별(방언), 연령별, 재외국인 등노이즈, 환경 등: 자동차실내 소음, 작업현장/공연장 소음, 새소리 등얼굴 (홍체, 안면인식) /사물(재활용품)/간판 등(개체인식 목적)CCTV 데이터 등(예측/이
6.Web Search Engine

Lycos: CMU의 연구 프로젝트 (1994)Excite: Standford 대학원생OpenText: Washington UniversityHotBot: U.C.Berkley의 검색엔진을 발전시킴Altavista: DEC (1995)Google: Stanford 박사
7.Attention으로 이어진 딥러닝 진화의 계보: Word2Vec to Transformers

딥러닝의 발전은 결국 한계의 인식 → 구조적 재해석 → 전이와 확장의 연속이다.