인공지능 학습 dataset 종류
텍스트
- 신문기사, 문학작품, SNS(트위터, 블로그, 영화평)
음성 (텍스트 전사)
- 음성인식 목적: 지역별(방언), 연령별, 재외국인 등
- 노이즈, 환경 등: 자동차실내 소음, 작업현장/공연장 소음, 새소리 등
이미지
- 얼굴 (홍체, 안면인식) /사물(재활용품)/간판 등(개체인식 목적)
영상
- CCTV 데이터 등(예측/이상탐지 목적)
수치 데이터
- 기상정보, 이동인구 등(예측/이상탐지 목적)
원시 데이터, 원천 데이터, labelled 데이터
해외 경진대회: kaggle
국내 경진대회: Dacon
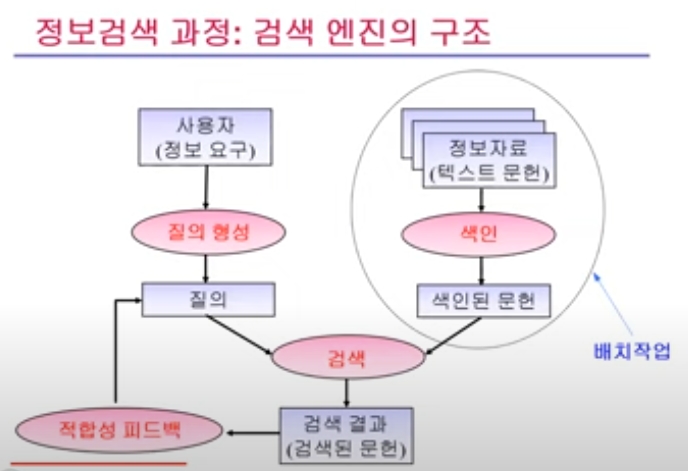
Search Engine (SE)
Indexing
-
정보자료(문서)의 내용을 표현하는 어휘(사용자 질의어)가 포함된 '문서'를 효율적으로 검색하기 위한 목적
각 문서에서 사용자 질의에 의해 검색 대상이 되는 어휘들을 색인하는 작업 -
이용자에게 빠른 속도로 검색결과를 제공함으로써 방대한 정보자료의 탐색시간 최소화 가능
색인 작업 과정
- 각 입력 문서들로부터 색인어 추출
- 역파일 구조로 색인 정보 저장 -> 색인 DB 생성
- 일괄처리(전체문서를 한꺼번에) 또는 점증 방식으로 수행
색인과정: 전방향 색인, 역방향 색인
- 각 문서에서 색인어 추출 -> forward indexing
- Stemming (어근 추출)
- 불용어 (stopword) 제거 - 영어의 관사 a,the 등
- 색인어의 출현 빈도 (TF: Term Frequency) 계산
<문서, 색인어 list>
문서(doc ID) 색인어 및 가중치
001 (병렬4), (시스템3), (특성1), (설계2), (연구3)
002 (정보2), (검색3), (시스템3), (연구3), (성과1)
003 (프로그램4), (시스템3), 설계4), (성능1), (향상1)
004 (병렬2),(프로그램2),(연구6)
색인 과정
-
문서빈도 및 TF-IDF 계산
문서빈도 (DF: Document Frequency) 계산
--> 각 색인어의 출현 문서개수
문서 벡터 생성: 색인어 가중치 TF-IDF 계산 (IDF = 1/DF) --> TF % IDF -
Inverted file 생성: backward indexing
<문서, 색인어 list> -> <색인어, 문서 list>로 재구성
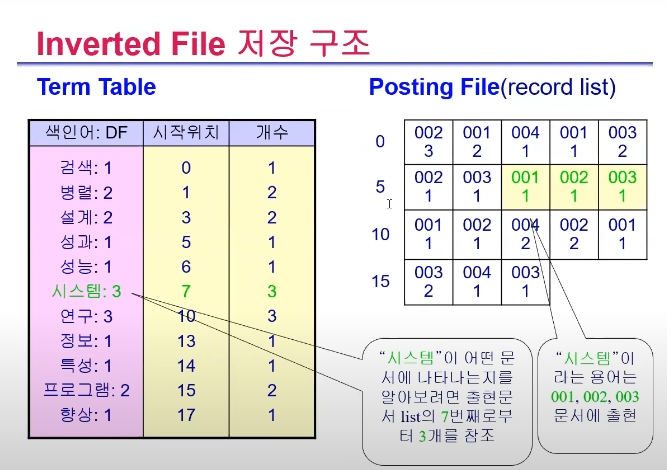
색인결과(역방향 색인)의 저장 문제
역방향 색인에 의한 색인 결과를 색인 DB에 저장
색인어마다 (문서번호, 가중치) 개수 차이가 큼
- 1개 문서에 출현한 것
- 10만개 문서에 출현한 것
- 100만개 문서에 출현한 것
Problem
- 각 색인어에 대한 가변길이 레코드를 어떤 자료구조로 저장할 것인가?
--> Term table과 posting file로 분리

What exactly is Searching?
정의: 사용자 질의 분석, 질의에 적합한 문서를 찾는 과정
검색 단계
- 사용자 질의 분석 -> 사용자 질의 형성
- 시스템 질의와 각 문서들과의 유사도 계산
- 유사도 순으로 각 문서를 정렬
주요 검색 모델, boolean model, vectorspace model, 확률 모델
이 중에서는 vectorspace model(VSM)을 가장 많이 사용함
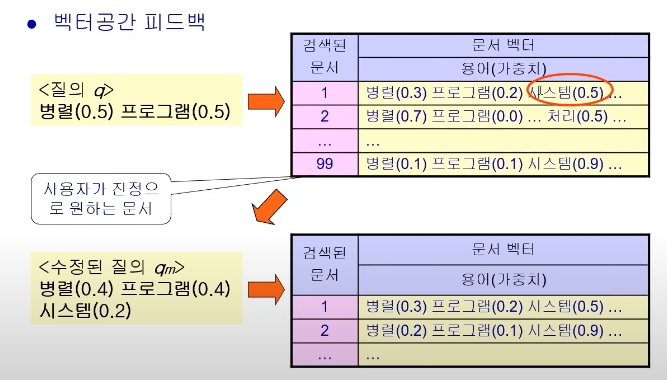
질의 분석
- 사용자 질의를 분석하여 시스템 질의를 형성
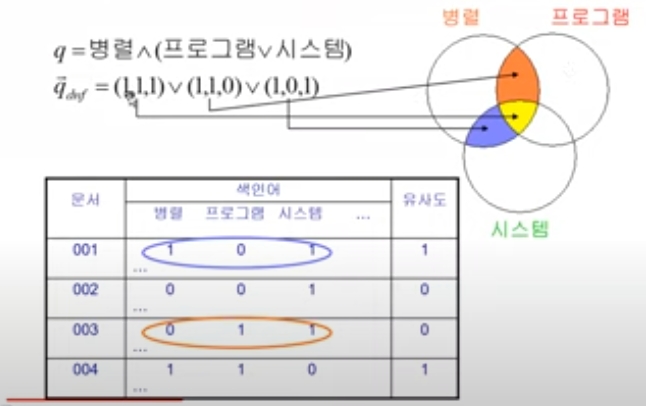
병렬시스템이나 병렬 프로그램에 대해 알려주세요
--> stemming / 가중치 계산 / 불용어 처리
--> (병렬,2) (시스템,1) (프로그램,1)
boolean model
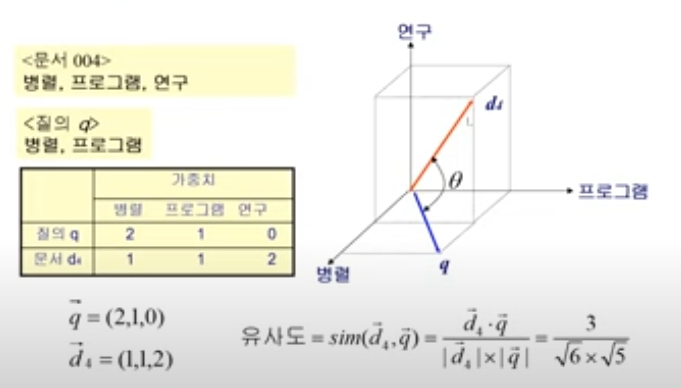
Vector space model

검색엔진의 목표: 자연어 검색
초기: 질의어, 키워드 에 적합한 문서들을 번호들에 나열
최근: 질의응답 시스템 (Question and answering system)
현실: '색인어'로 웹문서/뉴스/블로그/동영상 검색
CS의 응용 (지능의 확장)
지식 = 표현 + 생성 + 검색
생성(인간 유전자 염기서열, 인간 커넥텀 프로젝트, 빅 메커니즘), 검색(Google's Pagerank 알고리즘)
순서 메기기: 사람들이 가장 많이 볼것같은 페이지가 우선
page = node --> : link
많이 링크할수록 중요한 노드 weight(가중치) 계산
Reference
검색엔진의 구조 개요 (강승식 교수)
SNU ON_컴퓨터과학이 여는 세계 지식검색: 구글페이지 순위 매기기 (이광근 교수)
