오늘은 Upstage에서 제공하는 AI Space에 대해서 글을 적어보려고 한다.
홈페이지에 접속에서 상단 메뉴 중 "Products"를 클릭하면 Generative intelligence, Document intelligence, Intelligence spaces 세가지가 있는데 이중에서 AI Space는 The command center for teams buried in paperwork라고 부연설명되어 있다.
Upstage AI Space
Upstage AI space에서는 다음과 같은 기능들을 제공한다. 내가 직접 활용해본 예시는 아래에 첨부하도록 하겠다.

먼저 아래 캡쳐화면을 보면, 상단 왼쪽의 new project의 경우 다양한 경로를 통해 문서를 받아올 수 있다. local 환경에 저장되어 있는 파일, 혹은 google drive, gmail을 연동하거나 외부 URL link를 통해서 데이터를 불러오는 것이 AI Space에서 가능하다.

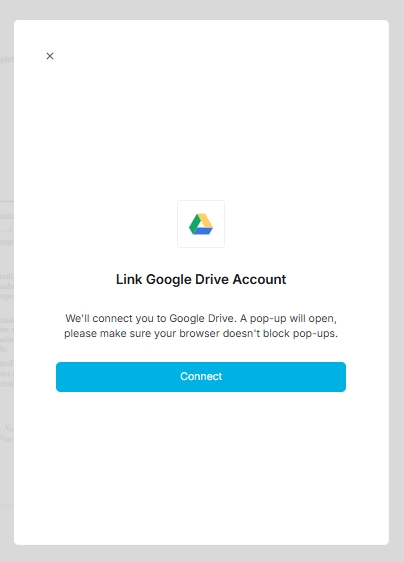
나의 경우, 구글 드라이브에 저장되어 있던 논문을 불러와 봤는데, 일단 해당 기능을 사용하기 위해 클릭하면, 위에 캡쳐 사진처럼, Link google drive account라는 창이 뜨게 되고 이후 Connect 버튼을 누르면, 내 구글 계정에 저장되어 있는 파일들을 AI Space에 불러오는 것이 가능해진다.
What you can do
그렇다면 AI Space를 활용하면 어떠한 기능들을 구체적으로 사용해 볼 수 있을까?
Upstage homepage에 나와있는 공식 설명은 아래와 같다.
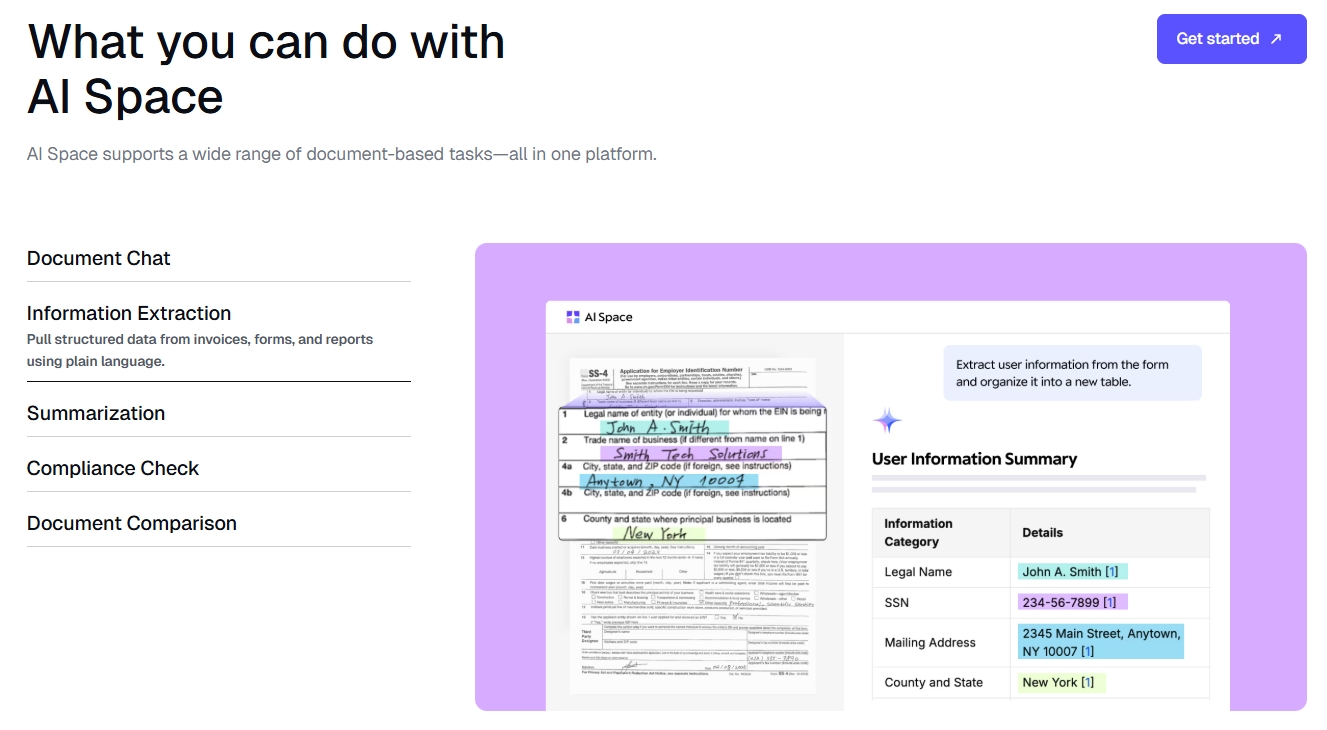
Document Chat: Ask natural-language questions and get accurate, source cited answers
Information Extraction: Pull structured data from invoices, forms and reports using plain language
Summarization: Generate clear overviews from long or complex documents
Compliance Check: Validate that each document meets required formats and content rules-flag non-compliant sections with citations
Document Comparison: Identify version changes across policies, contracts, Invoices, and clinical guidelines
Usability
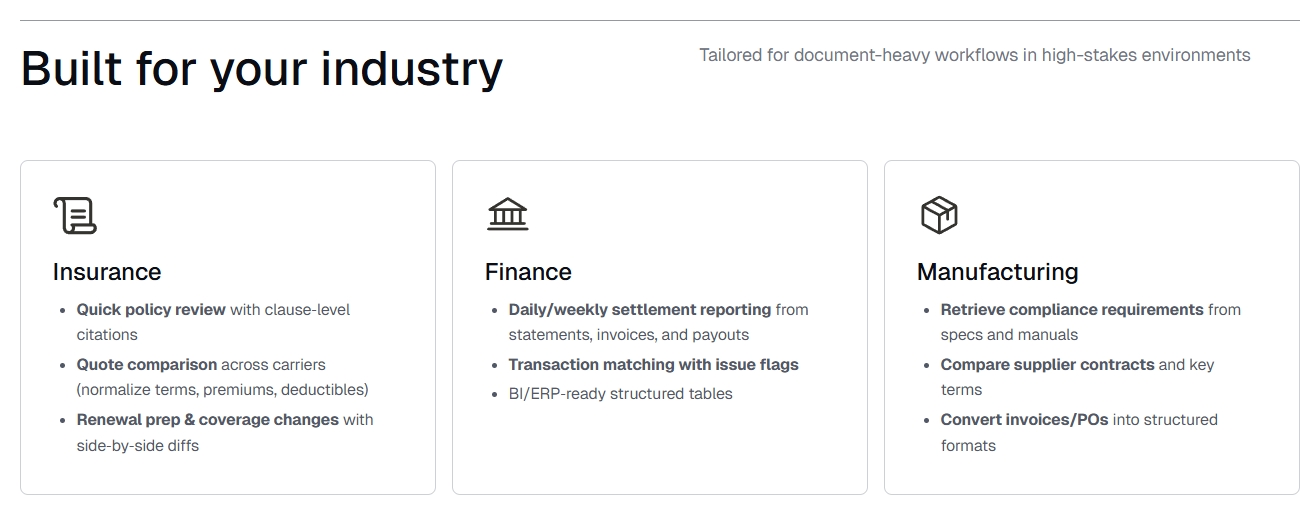
Upstage AI space는 위에 "Built for your industry"를 확인해 보면 알 수 있듯이, 보험, 금융, 제조업 등 여러 비즈니스 환경에서 활용 가능한 서비스이며 위와 같은 기능들을 제공한다. 더불어 업로드 되는 모든 문서, 채팅 내용, 도출된 결과물들은 HIPAA, ISO 27001, SOC 2의 철저한 enterprise-grade 보안 인증에 의해 개인정보가 보호된다.
나는 6개의 파일들을 업로드 해보았고, Solar Pro 2 model에게 해당 문서에 관해 simple Question & Answering task를 진행해 보았다. 위에서 언급한 바와 같이, Upstage AI space는 자연어로 질의를 하면 거기에 맞는 근거를 제공한다. 왼쪽 문서에 보라색으로 해당 영역에 표시가 되기 때문에 내가 필요한 특정 부분에 정보를 쉽고 빠르게 찾을 수 있다. 또한 상단에 HTML 버튼을 클릭하면, Document structure를 HTML format으로 변환하는 기능도 제공한다. 더불어, Solar chat 하단에는 information extraction 기능도 제공하는데, 이를 활용하기 위해서는 우선적으로 해당 문서에 대한 schema가 필요하다.


Advantages of using Upstage information extract
Information extraction의 "set schema" 부분에 대해서는 "Upstage official tech blog"의 글을 참고하여 구체적으로 설명해보도록 하겠다.
예를 들어, 보험 업계의 경우 지난 분기까지만 해도 보험 서류에 47개 항목이 있었는데 이번 분기엔 63개로 늘어나고, 다음 분기엔 또 달라진다. 매번 새 상품이 출시되고 규제가 바뀌며, 기업이 합병되면 용어나 데이터 구조가 순식간에 바뀐다.
여기서 문제는 대부분의 문서 자동화 시스템이 이런 변화를 전제로 설계되지 않았다는 점이다. 대부분의 시스템은 ‘한 번 구축하면 끝’이라는 방식으로 만들어져 있어서, 필드나 구조가 조금만 달라져도 전체 logic이 깨진다. 그때마다 IT팀은 시스템을 다시 수정하고, 운영팀은 기다리며, 그 사이에 문서 처리가 멈춘다. 결국 자동화가 중단되고 다시 수작업이 늘어난다.
Ontology는 IT 스프린트보다 훨씬 빠르게 변하지만, Automation는 그 속도를 따라가지 못한다. 지금 필요한 것은 단순한 자동화가 아니고, 변화를 견딜 수 있는 자동화 따라서, 온톨로지가 바뀌어도 멈추지 않는 시스템이 필요하다. Upstage information extract 는 데이터 구조가 바뀌는 순간에도 스스로 적응할 수 있는 추출 시스템을 활용한다. 즉, Ontology가 변하더라도, 변화에 흔들리지 않는 자동화가 핵심 차별화 포인트가 된다.
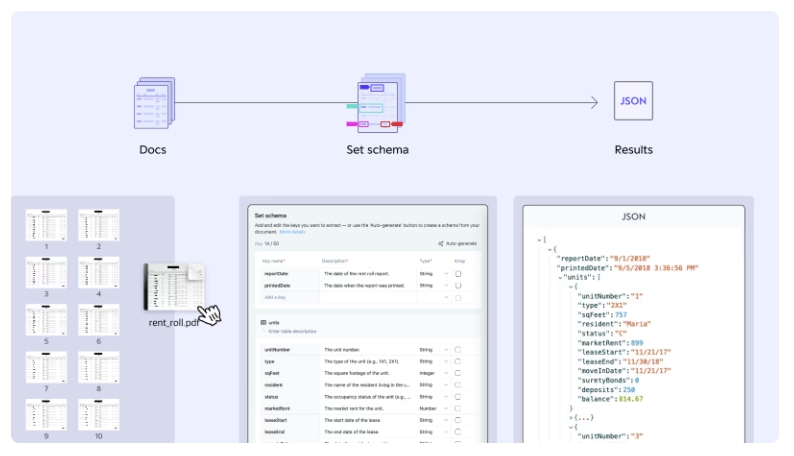
Upstage의 핵심은 스키마를 학습된 모델이 아닌 설정으로 다루는 것이다. 새로운 필드를 추가하거나 설명을 수정해도 모델을 다시 학습시킬 필요가 없다. 보험 서류 항목이 47개에서 63개로 늘어나더라도 스키마만 업데이트하면 된다. 재학습도, 긴 IT 스프린트도 필요하지 않다.
문서 10개만 업로드하면 AI가 자동으로 스키마를 제안하고, 검토 후 바로 배포할 수 있다. 약 3분이면 끝난다. 초기 정확도는 약 80% 수준으로 충분히 실무에 쓸 수 있다. 새로운 용어가 생기면 2~3개의 예시만 추가해주면 된다. 내부 테스트에서는 이런 방식으로 평균 6.65% 정확도가 향상됐다. 더불어 검증 기능도 내장하고 있다. 신뢰도가 낮은 값은 자동으로 표시되어 검토 대상임을 알려주고, 추출된 값이 원본 문서의 어느 페이지, 어느 좌표에서 나왔는지도 바로 확인할 수 있다. 검토 중 발견된 오류는 피드백되어 스키마를 자동으로 개선한다. PDF든, 스캔 문서든, 입력 형식이 달라도 문제되지 않는다. 모든 문서는 Document Parse를 통해 표준화되어, 형식이 바뀌어도 추출 로직이 깨지지 않는다.
만약 밤새 50개의 새 필드가 추가되더라도 복잡하지 않다. 스키마를 업데이트하고, 샘플 배치를 검증한 뒤 배포하면 된다. 몇 분이면 끝난다. 두가지 시나리오 예시를 통해 이 시스템이 이러한 문제 발생상황에서 어떻게 대응 가능한지 설명하도록 하겠다.
Scenario 1: New insurance product launch
보험사가 새 상품을 출시하면서 신청서 양식이 바뀌었다.
기존엔 47개의 필드였지만, 새 상품에는 63개의 필드가 필요하다.
문제는 기존 시스템이 새 필드를 인식하지 못해 신청서를 처리할 수 없다는 점이다.
금요일 출시를 앞두고 이미 수천 건의 신청서가 접수된 상태다.
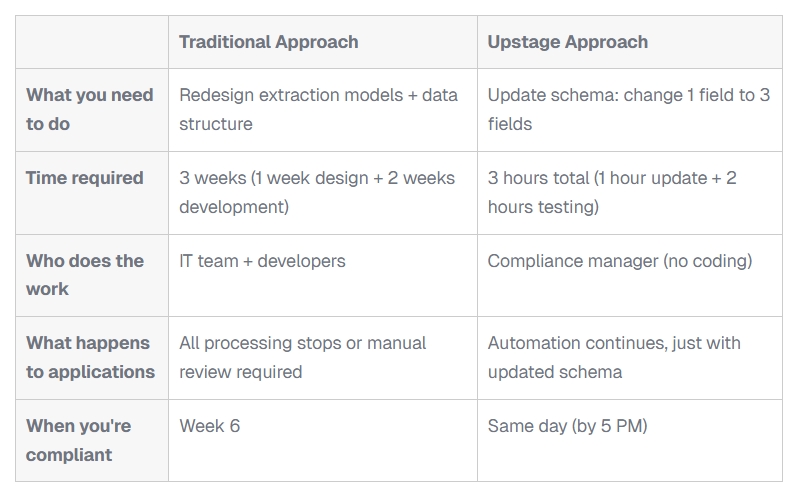
일반적인 시스템이라면 모델을 다시 학습시키고 코드를 수정해야 하지만, Upstage에서는 스키마만 수정하면 된다. 즉, 새 필드 16개를 추가하고 검증한 뒤 바로 배포할 수 있다. 따라서 몇 분 만에 새 상품 양식을 반영하고 업무를 이어가능 것이 가능하다.

Scenario 2: Regulatory compliance update
새로운 개인정보 보호 규제가 즉시 시행되었다.
기존에는 ‘환자 동의’ 항목 하나만 있었지만, 이제는 ‘치료 동의’, ‘데이터 공유 동의’, ‘연구 동의’ 세 항목으로 나뉘어야 한다. 기존 시스템은 하나의 값을 추출하도록 설계되어 있어 법적으로 바로 위반 상태가 된다. Upstage에서는 필드 구조를 세 개로 나누는 스키마 변경만 하면 된다. 모델을 다시 학습할 필요 없이, 새 규제를 반영한 스키마를 바로 배포할 수 있다. 이를 통해 당일 안에 법적 요건을 충족하고, 업무를 멈추지 않고 지속할 수 있게된다.
Reference
When Ontology Changes Faster Than IT: Upstage - tech blog
Upstage console
Upstage AI Space
Upstage - homepage
