인공지능, 데이터 수집 및 전처리 등의 목적으로 많이 쓰이는 판다스 사용법에 관해 개인적인 팁위주로 정리해보고자 한다
1. 기초표현
판다스 표현 중에 가장 핵심이자 기초는 loc, iloc라고 생각한다
- loc[행정보, 열정보]
- iloc의 경우 index 값으로
1-1. 특정조건에 따른 데이터 추출
- 행이든 열이든 조건설정을 하면 되는데, 포인트는 loc를 쓰는 것임
option = iris['SepalLengthCm']>5
new_iris = iris.loc[option,:]
new_iris.head()2. apply & lambda
행과 열에 특정 함수를 한번에 반영하고자 할때 apply와 lambda를 세트처럼 같이 사용한다
iris.iloc[:,1:4].apply(lambda x:x.mean(), axis=0)
# iris의 1~4번째 칼럼에 대해 mean을 적용하는 코드
# axis = 0 : 행 방향으로 결정 => 칼럼 3개가 샘플값에 대한 평균으로 도출 (axis = 1 : 열 방향)3. group by : 엑셀에서 필터와 같은 기능
기존 loc/iloc는 행과 열의 방향으로만 처리가 가능하지만 group by를 사용하지만 특정 그룹을 지은상태에서 처리할 수 있게 해준다
# 종 별로 처리하기.
group_iris = iris[['SepalLengthCm','SepalWidthCm']].groupby(iris['Species'])
group_iris.mean()
# group_iris 의 value type이 df가 아니라서 그냥 프린트하면 나오는거 뭐 없음.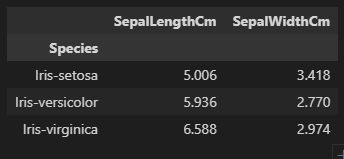
4. empty df에 for loop를 통해서 데이터 하나씩 추가하기
- 기존 append (가장 쉬운 방법) ⇒ 버전 업데이트 되면서 삭제될 예정
- .concat 이용해야 함
df = pd.DataFrame(columns=[])
for npy_path, json_path in zip(json_dir, npy_dir) :
df_temp = pd.DataFrame({'file_name' : [Path(json_path).stem],
'json_path' : [json_path],
'npy_path' : [npy_path]})
df = pd.concat([df, df_temp], ignore_index = True, axis = 0)
return df1) 외부에 empty df 선언
2) df_temp = pd.DataFrame({’col1‘ : [var1], ‘col2‘ :[ var2]}, ignore_index=True, axis=0)
5. 칼럼 값을 뭉치로 받아오고 싶은 경우
- npy_files = df.loc[:,['npy_path']] (x) # 인덱스까지 같이나오고, 형태가 df라 후처리가 필요함
- npy_files = df['npy_path'].tolist() (o) # df[’col name’].tolist() 이게 훨씬 낫다6. 최대한 loc, iloc를 활용하는게 결국에 제일 낫다
- .loc [ [ ] , [ ] ] 이 형태가 기본
- 하나씩인 경우는 [ , ]
- .loc를 통해서 값 바꾸기
- df.loc[행 조건_boolean, 칼럼명] = 바꿀값
- df.loc[df["intensity"] == 1.0, "intensity"] = 100.0 : intensity가 1.0인 전체 행을 100.0으로 바꾼다
- df = df.loc ~~ 와 같이 하지않는다! 이렇게 쓰면 오류임
- 숫자인지 문자인지 구분 : 0 vs ‘0’
- 판다스는 공홈 되게 잘 되어있음, 좌측 메뉴에서 다른것들도 고르기!
pandas.DataFrame.loc - pandas 1.4.2 documentation

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..