본 포스팅의 사용된 이미지 출처는 허민석님 유튜브 채널 입니다.
Sequence to Sequence
- 문장번역시 단어 하나하나를 하는 건 불가능 (문장구조, 어순 등) => 문장 통단위로 번역을 함
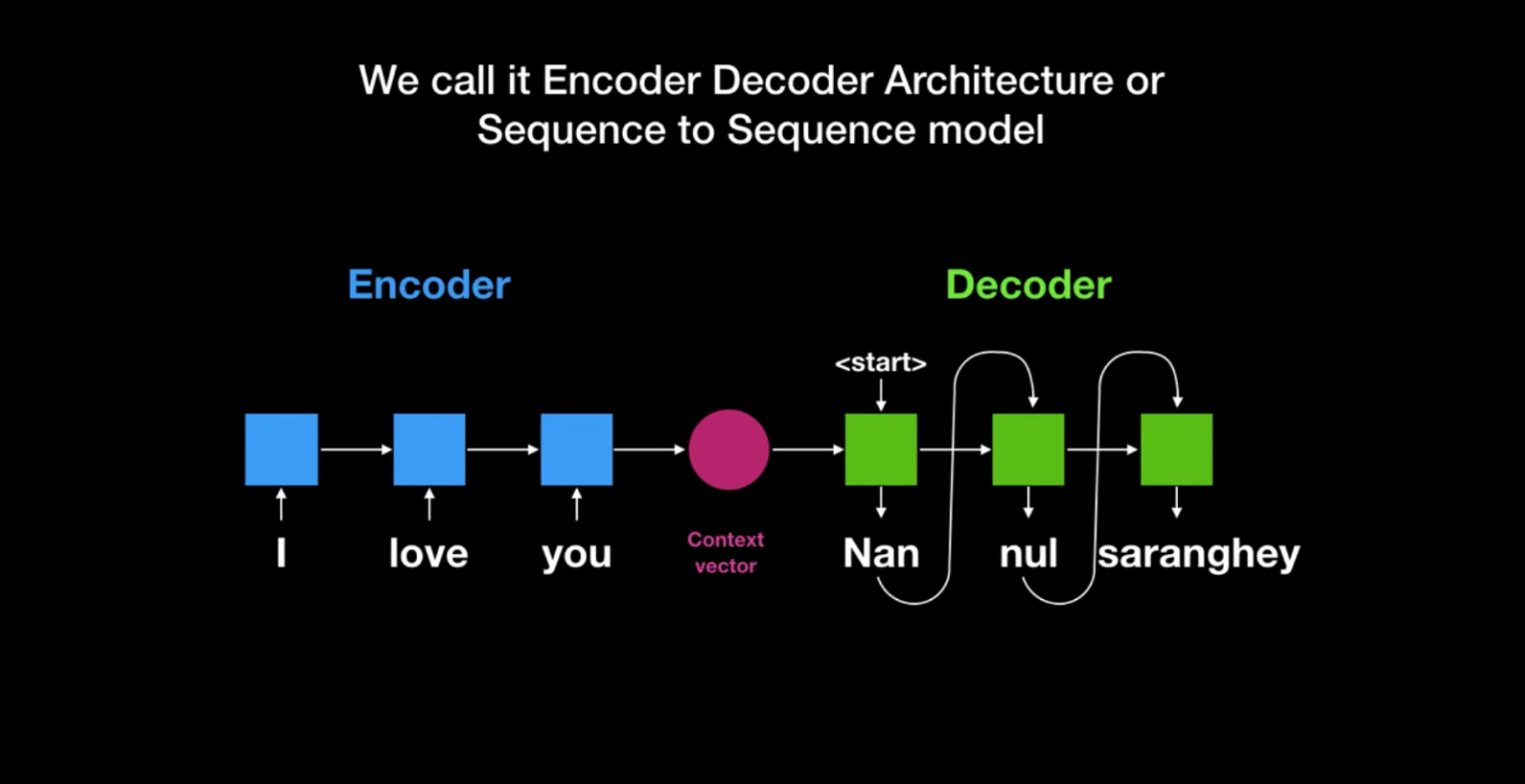
- 문장 벡터를 생성하는 Encoder 과정과, 인코더에서 생성된 벡터를 통해 번역을 하는 과정을 Decoder라고 함
- 이런 구조를 Encoder Decoder Architecture, 혹은 Seqence to Sequence 라고 함
=> 하지만 Context Vector(문맥 벡터) 사이즈가 고정 되어 있어서 문장이 여러개인 경우는 번역이 불가한 구조임
Attention
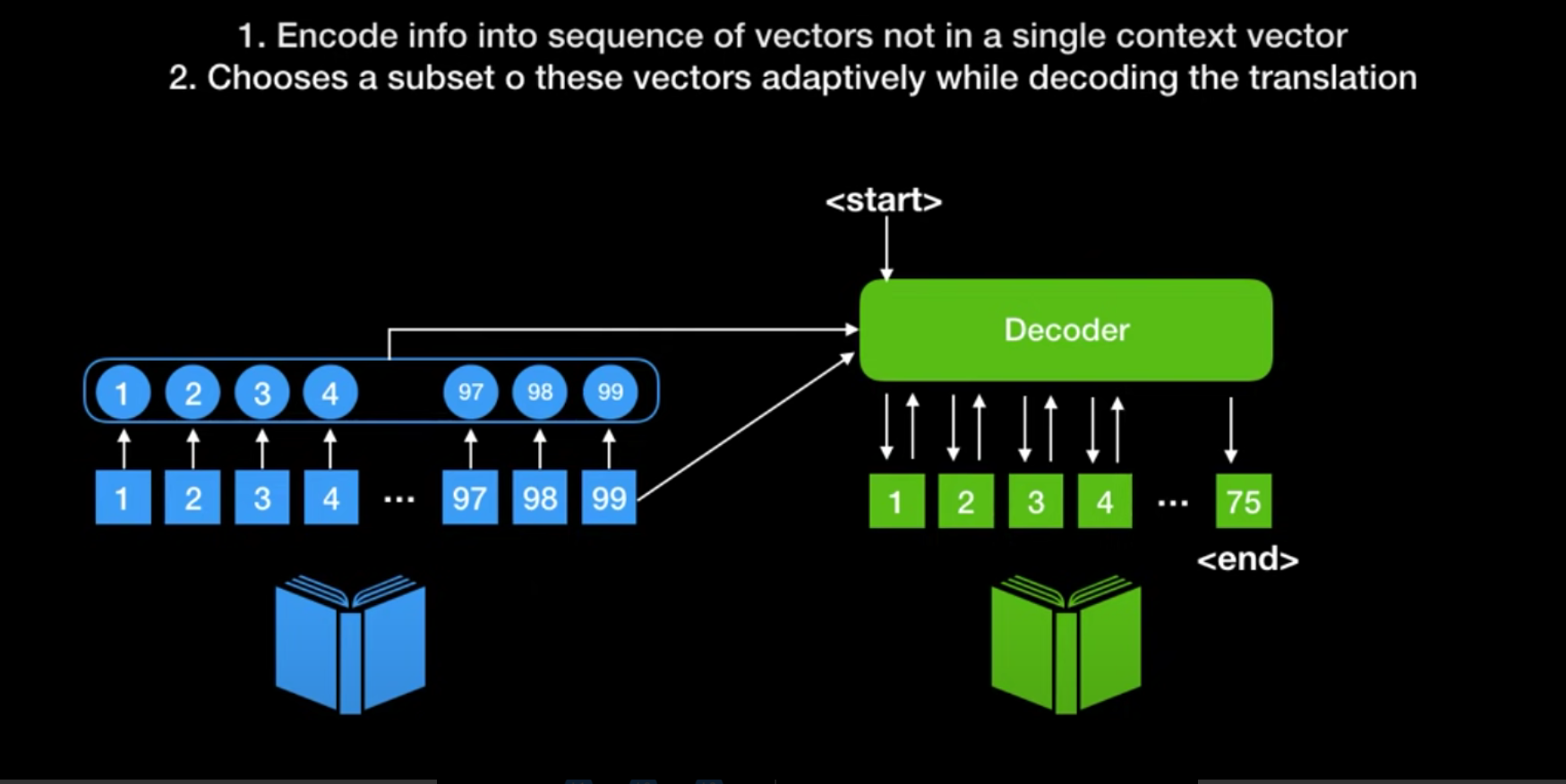
💡 위 방식에서 인코더 파트의 모든 rnn셀의 state 값을 활용하는 방식!!
- attention weight을 통해 어떤 rnn셀의 state을 집중할지 결정하는 방식인거임
- 문맥벡터(context vector)가 각각 state별로 디코딩 할때마다 달라진다 (사이즈 고정 x)
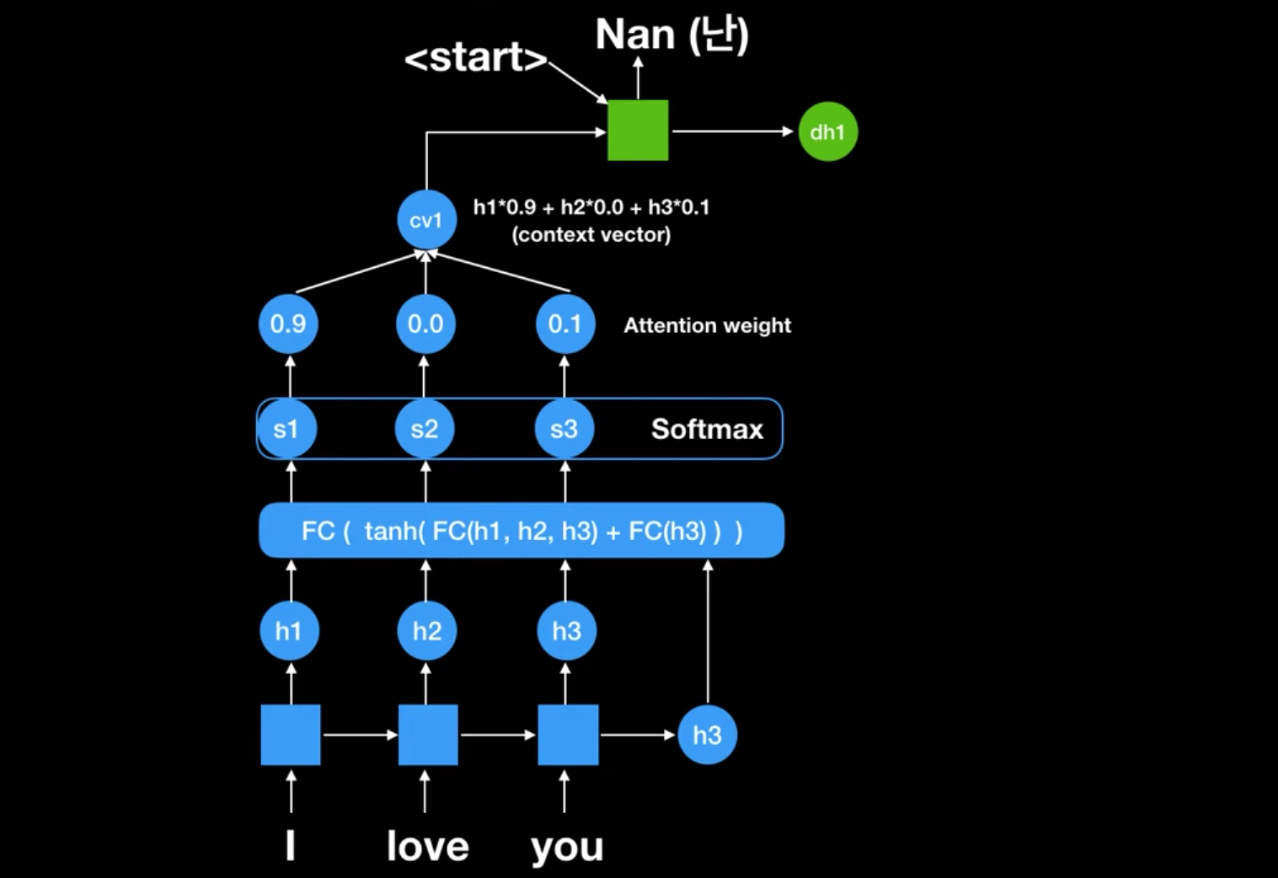
- 각 셀별로 나오는 state 값(h1, h2, h3) & seq2seq에서의 문맥벡터인 h3 가 FC 인풋값으로 넣으면 ⇒ 이값을 소프트맥스에 넣어서 attention weight이 나옴. 얘네가 첫번째문맥벡터인 cv1이 되는거임 : [0.9h1 +0.0h2 + 0.1h3]
- 이 cv1과 (지금이 처음이라 인풋으로 받아올게 없어서) Start 벡터를 받아서 ‘난’을 출력함
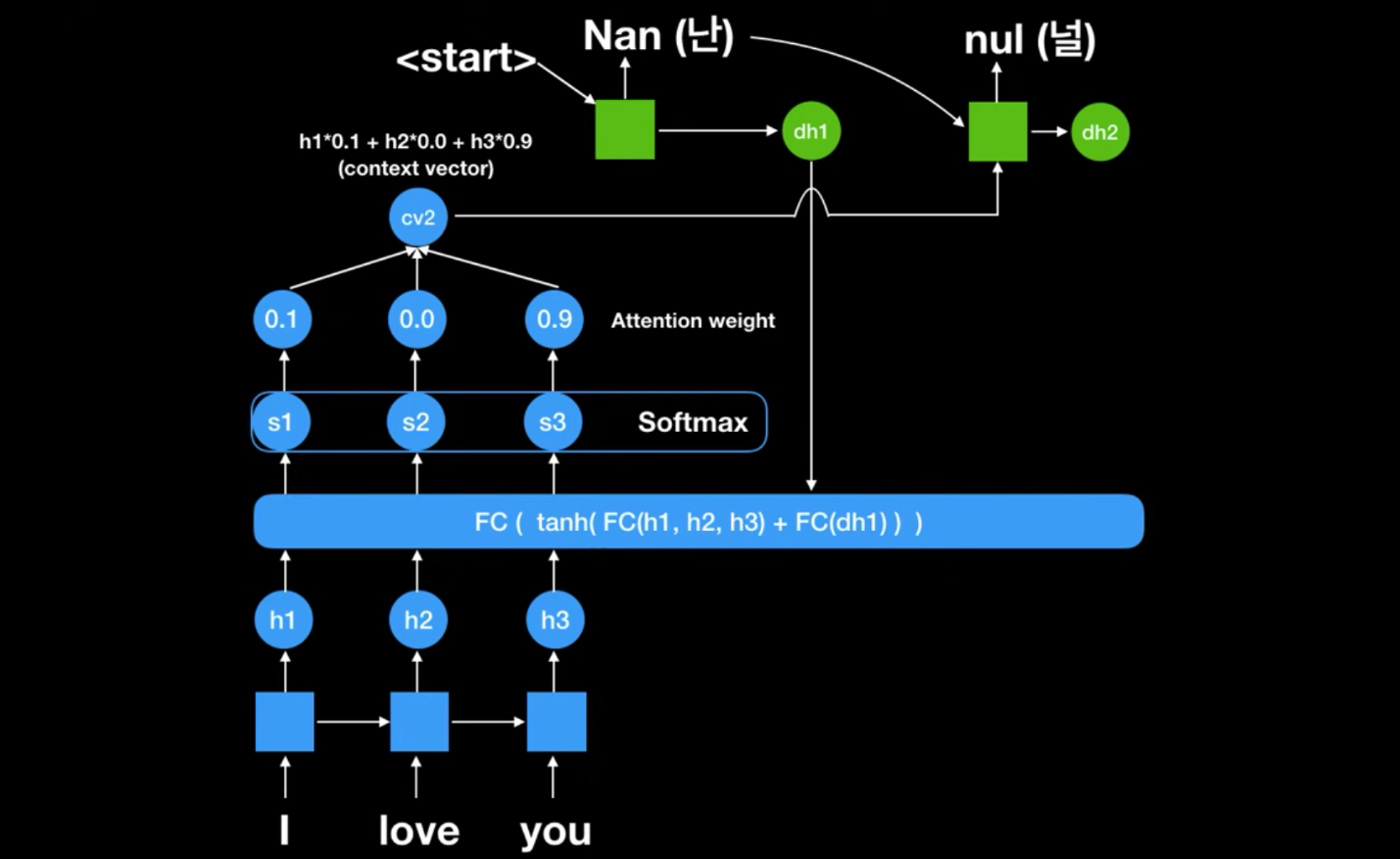
- 그전에 출력받은 ‘난’이 다시 FC로 들어가서 새로운 Attention weight이 나옴
- 얘네로 새로운 문맥벡터 cv2가 나오고 ‘난’과 cv2가 입력값으로 작용하여 ‘널’이나옴
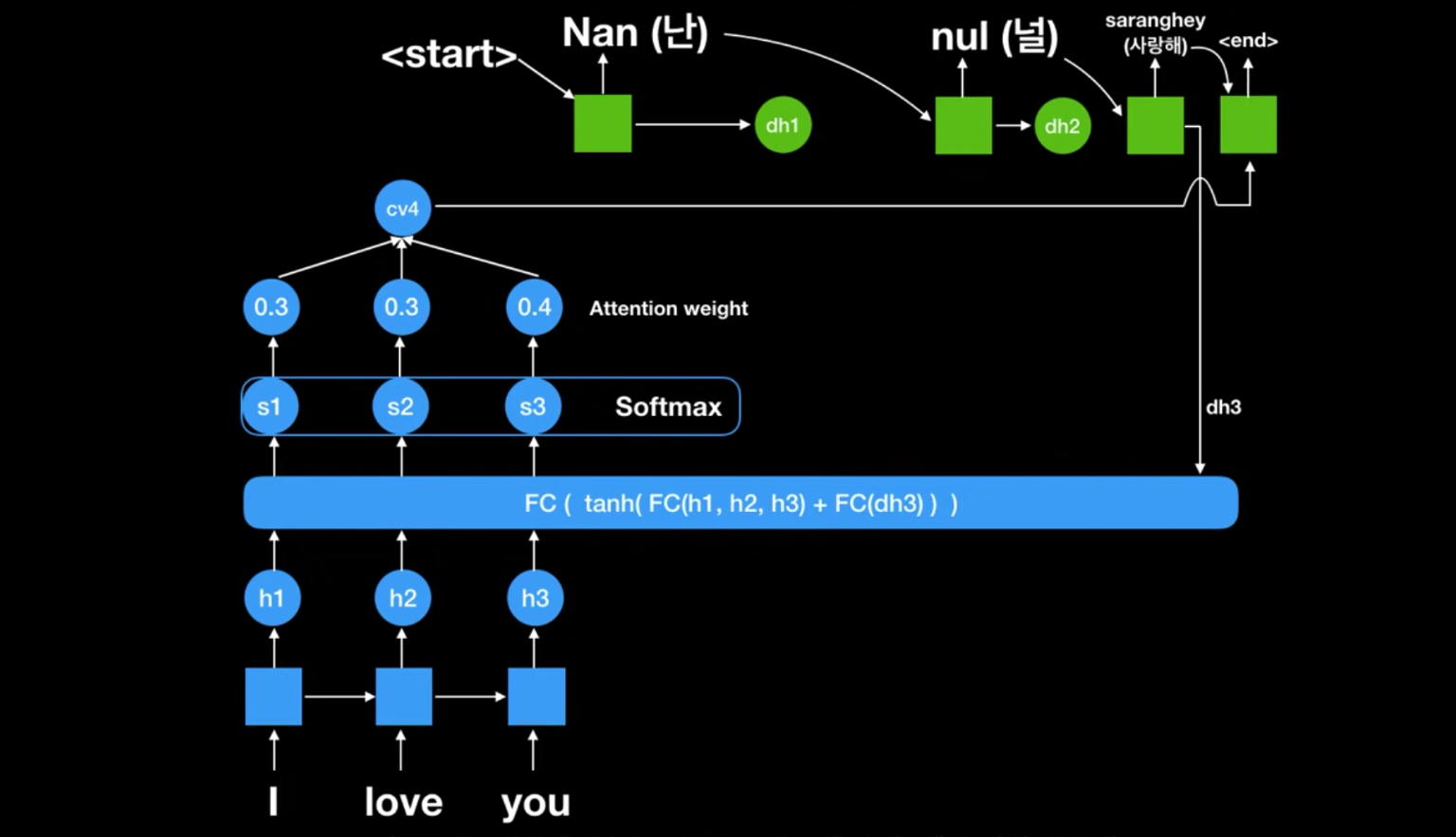
- 마찬가지로 반복하다가 젤 끝에 End 벡터가 나옴

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..