본 포스팅에서는 허민석님 유튜브 채널과 KAIST Idea Factory 유튜브 채널을 참고하여 내용을 작성하였음을 밝힙니다.
0. WHY RNN?
- input data type이 image인 경우 CNN, sequential(순차적인) 데이터 경우 RNN이 적합하다고 한다. 왜 그럴까
- CNN은 각 픽셀 주변 정보를 처리하는 Convolution 연산을 하고, RNN은 시간 정보를 기억할 수 있기 때문이다
- 이 때 sequential한 데이터는 텍스트(문단 내부 문장, 문장 내부 단어 등), 날씨 정보 같은 series data를 예로 들 수 있다
- sequential data에서 MLP를 못 쓰는 이유?
- MLP는 W matrix가 고정임에 비해 RNN은 sequence 길이에 따라서 W matrix도 달라지기 때문!
1. RNN 컨셉
- 우리가 평소에 보던 신경망을 세로에서 가로로 바꿔놓은 것
- 현재의 state는 이전의 state 정보를 참고해서 학습하게 됨
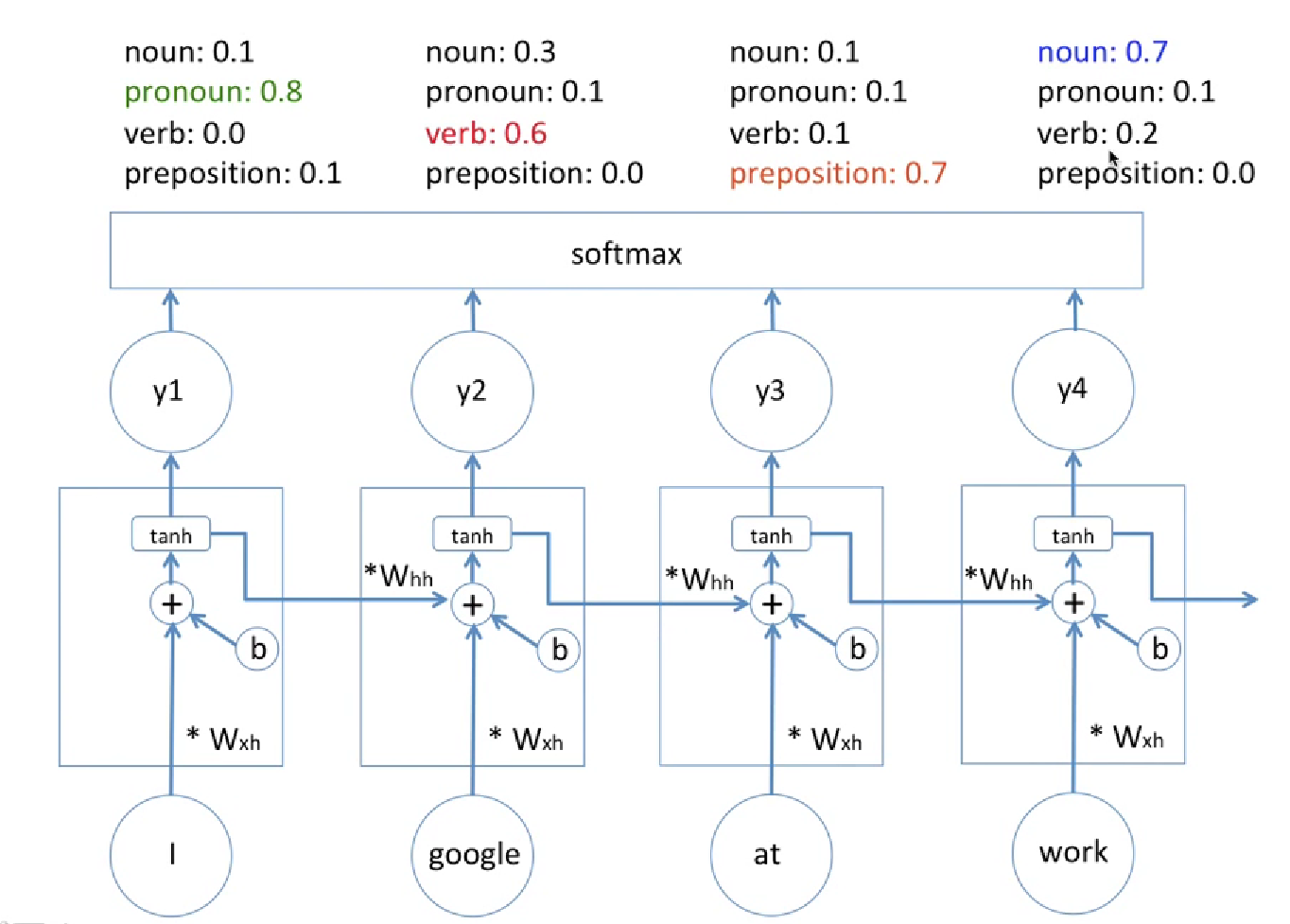
1-1. POS (품사식별) 로 이해하는 RNN 컨셉
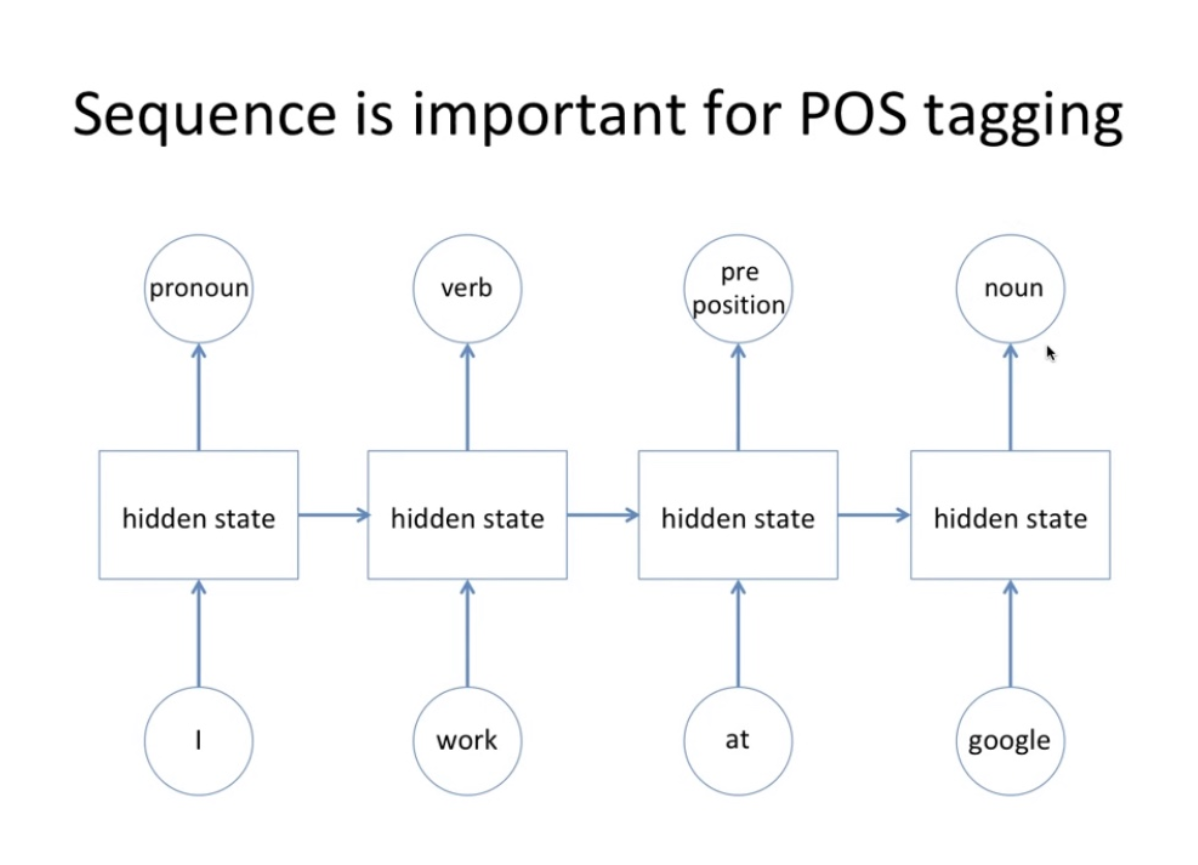
- node 1 : 처음에 I 니까 대명사라고 생각
- node 2 : 앞에꺼가 명사임을 고려하여 (=> 앞에꺼가 명사라는 내용의 state를 받아서) work는 동사라고 생각
- node 3 : 앞에애들이 명사 동사였으니까 전치사라고 생각
- 이런식으로 앞에 결과들이 그냥 아웃풋 방향말고 다음 node에도 영향을 주는것이 RNN!
=> CNN의 경우 이미지 하나별로 출력층 무엇일것이다 예측한것으로 끝났다면, 그 출력층의 최종값이 그 다음 들어올 이미지의 성능에도 영향을 준다는 것임
2. RNN 구조 종류
입력받는 데이터의 개수와, 출력하는 데이터의 수에 따라 나뉘게 된다
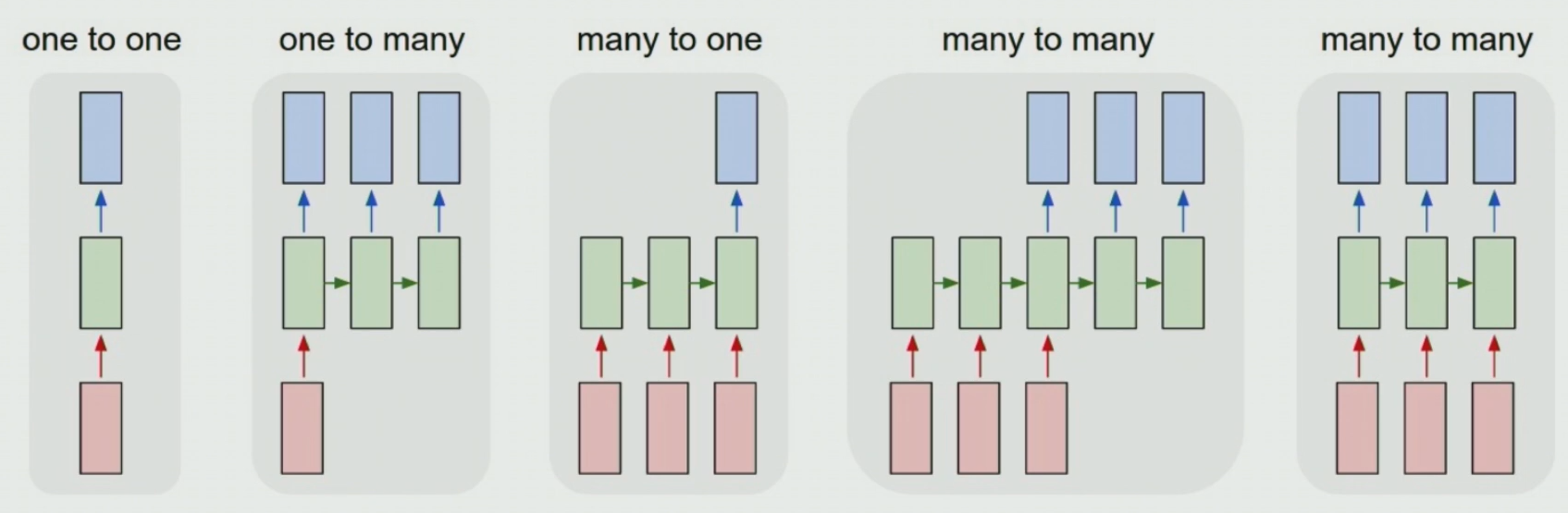
2-1. Many to one 구조
- 여러 시점의 데이터로 하나의 값을 시계열 예측
- 여러 시점의 센서 데이터를 통해 특정 시점의 제품 상태 예측
- t-1, t-2의 데이터(과거 행들의 입력변수)를 통해 t시점의 제품상태(현재 행의 예측변수)를 예측
2-2. One to many 구조
- 단일 시점의 데이터로 여러 값을 예측 (순차적인 Y를 예측)
- 이미지 데이터(단일 시점의 데이터 1개)로 이미지에 대한 설명 문장 생성하는 이미지 캡셔닝(순차적인 여러개의 데이터)
- 전화하는 이미지 인풋 => '남자가 전화를 한다'라는 설명문장이 출력되는 구조
2-3. Many to many 구조
- 순차적인 X로 순차적인 Y를 예측
- 문장이 주어졌을 때, 각 문장에 대한 품사를 예측하는 POS Tagging
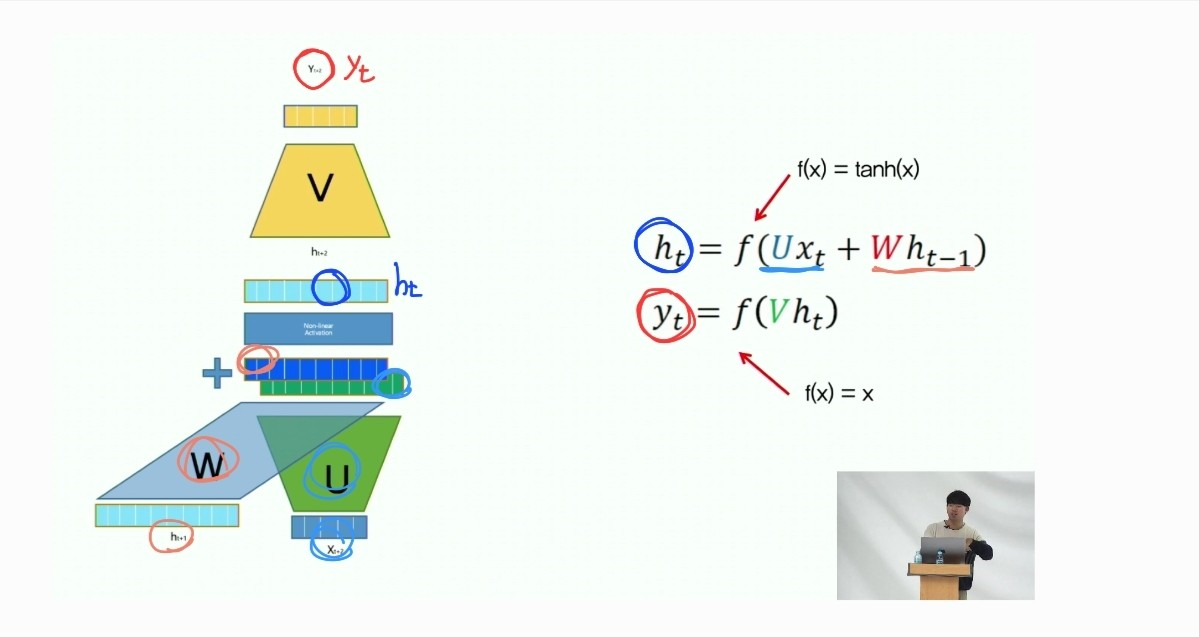
3. RNN 세부 학습구조
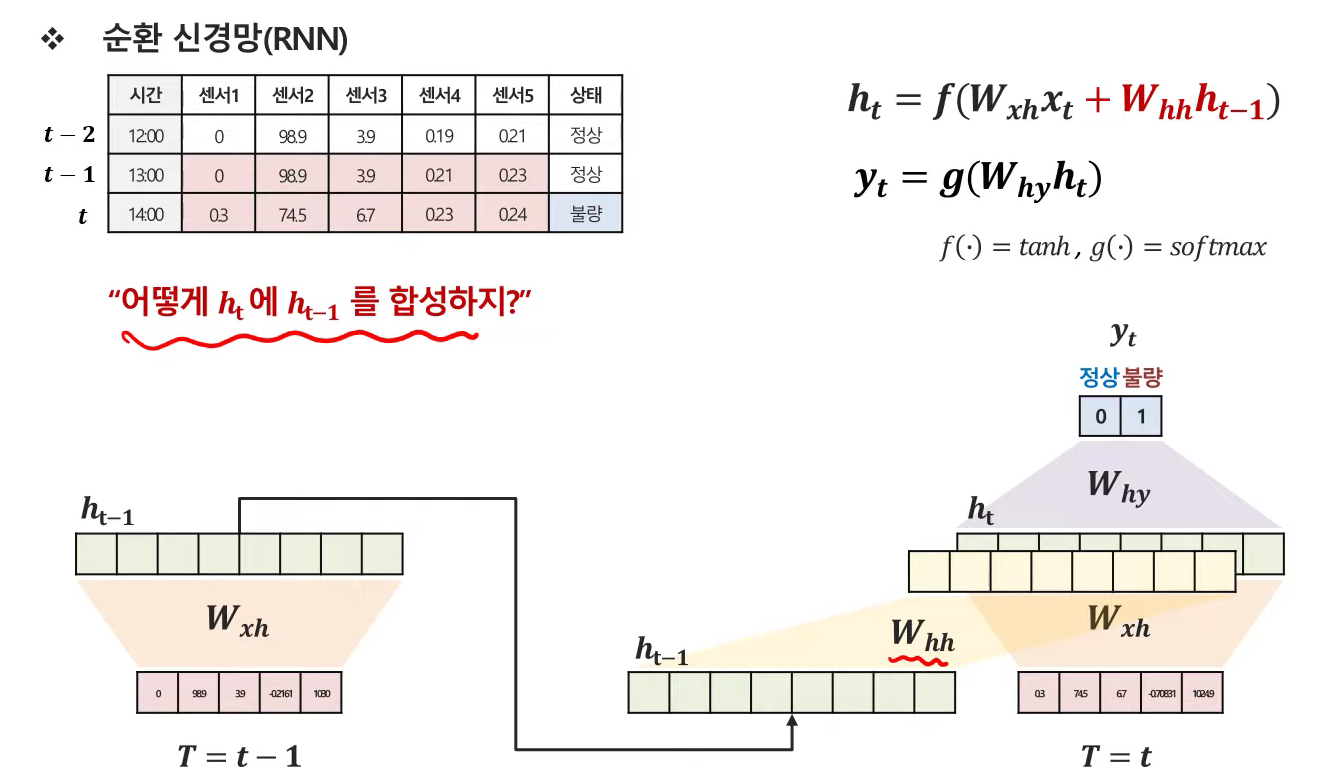
- 이전 정보를 갖고온다는 것은, hidden vector를 갖고와서 가중치를 곱해서 더해주는 것임.
- 이미지 출처
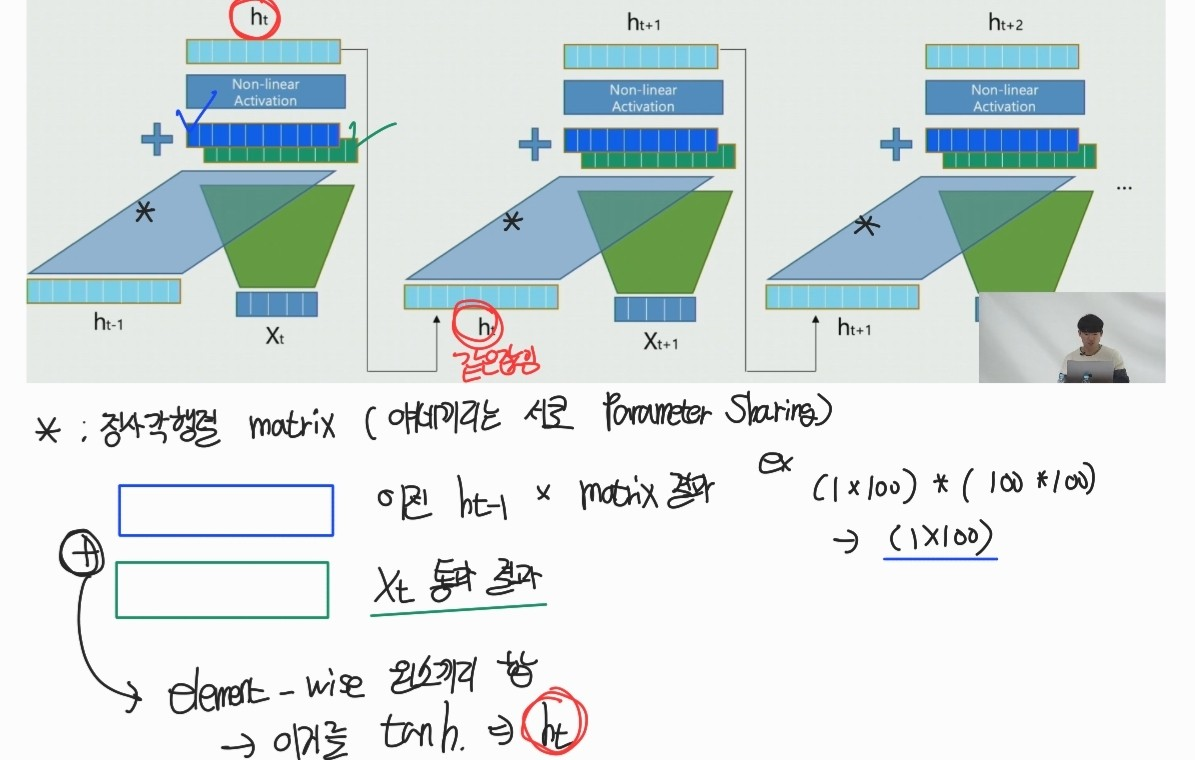
- 이 때, 위의 그림하나가 epoch 1을 의미하는 것이 아님. 데이터가 100개면 100개의 시퀀스를 다 처리해야 epoch 1이 되는것임 ㅇㅇ
tanh 부분을 보면, "똑같은 값"이 1. output으로 2.다음 hidden state로 전달되는것을 관찰할 수 있음
- 그냥 output방향으로 가는게 아니라 다음 state로 영향을 준다 (가중치의 값을 전달한다)
- 이때 가중치를 tanh 거친 상태로 준다
- 여기서 RNN은 Wxh, whh, b 각자 다르지 않고 모두 동일한 값임
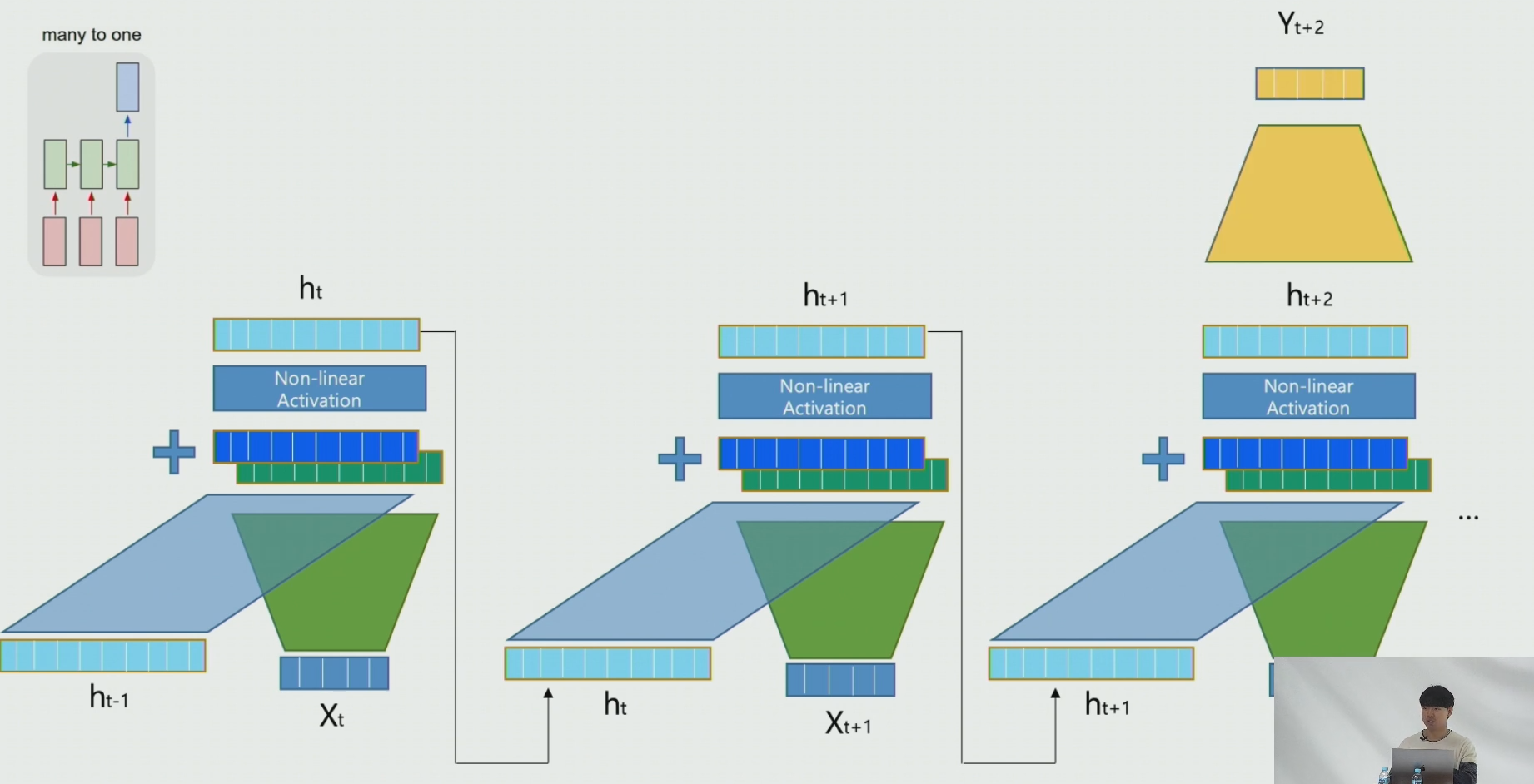
3-1. Many to One 형식일때의 적용
RNN 셀을 거친 마지막 hidden layer의 결과에 fc 등을 거쳐서 예측하는 형태
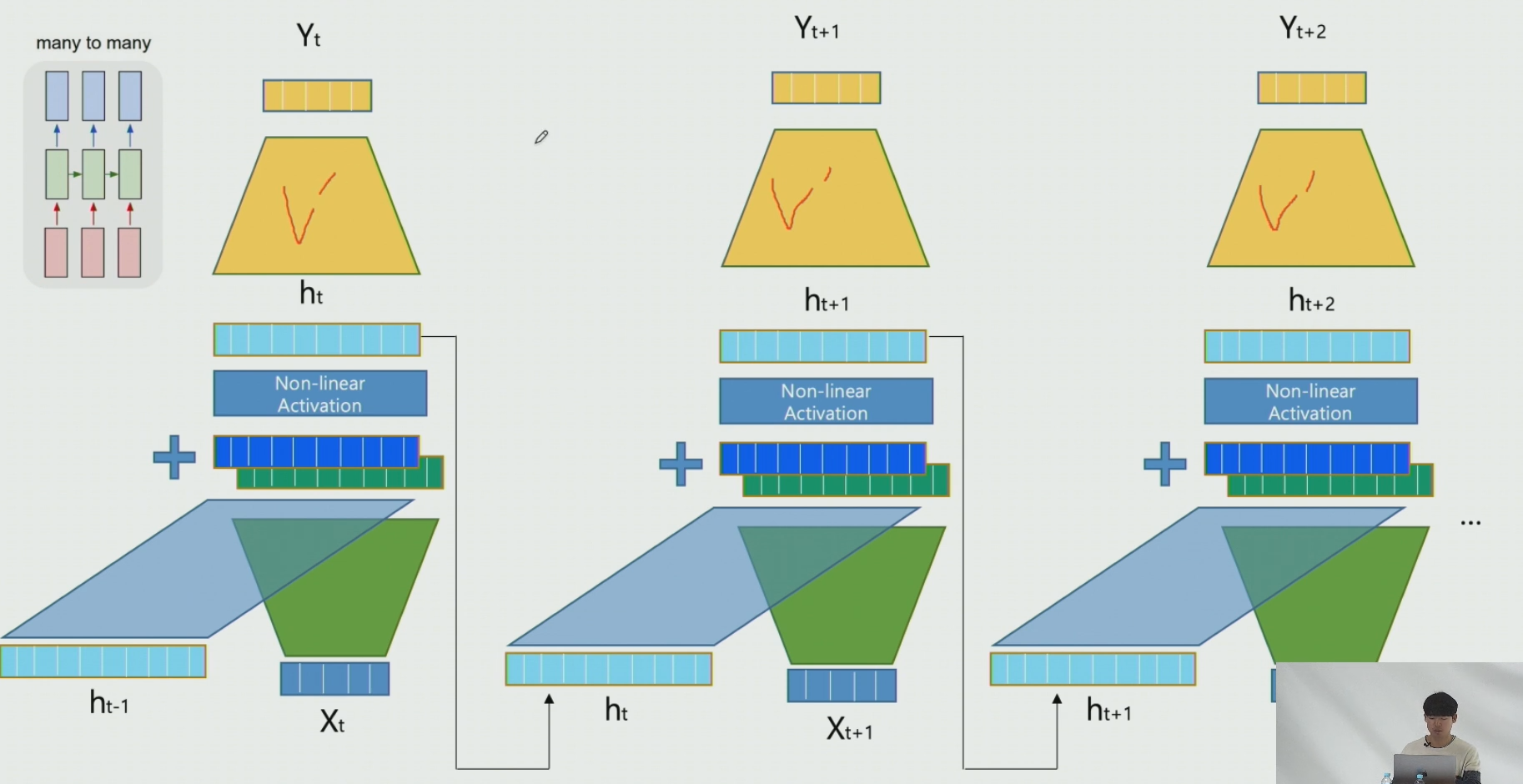
3-2. Many to Many 형식일때의 적용
각각의 결과로 예측한다. 이 때, 여기서도 파라미터 공유한다. loss_fn을 거쳐서 다음 step이 되었을때 update 된다 : v -> v`
3-3. Calculate Loss
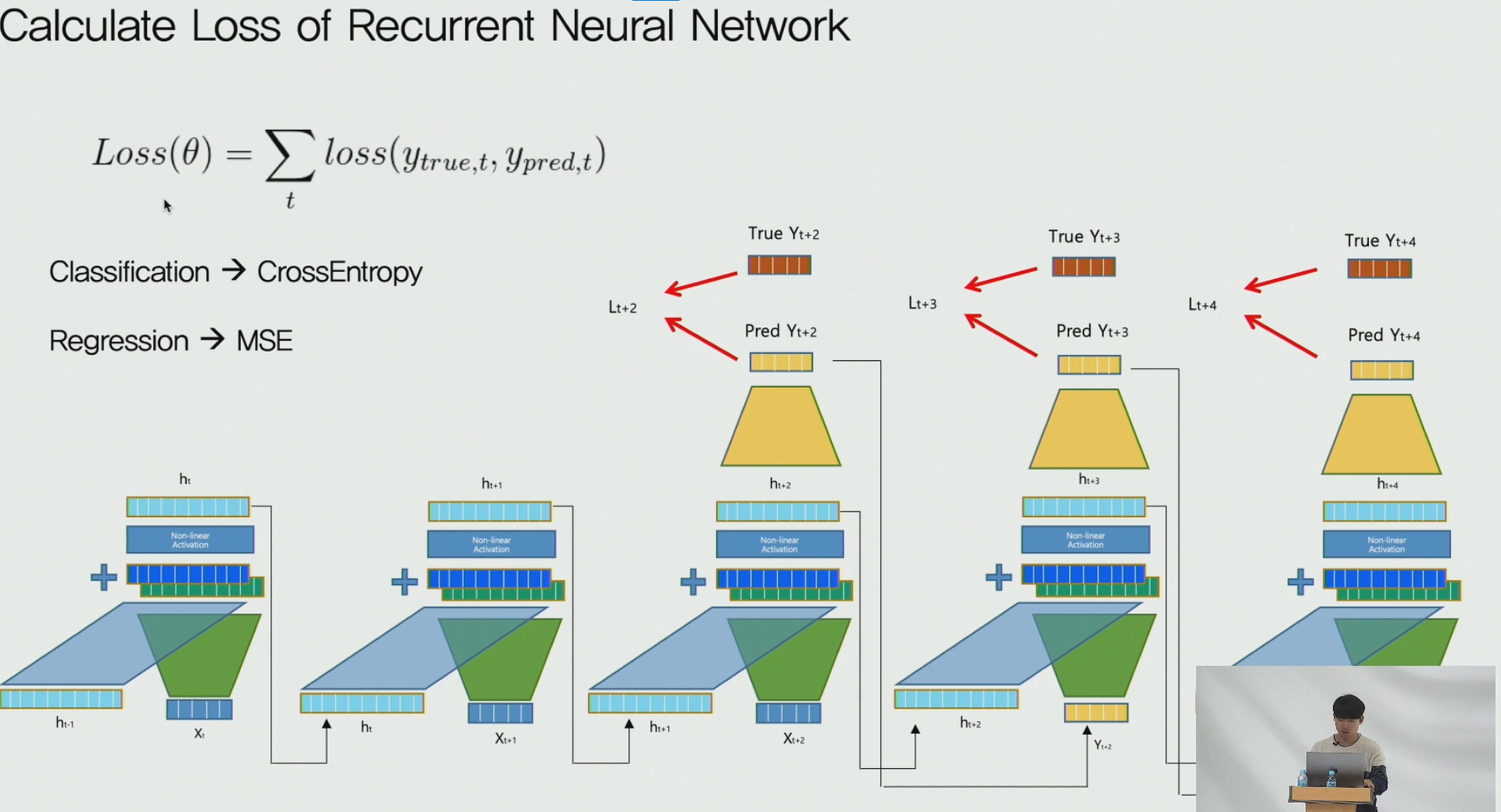
- 예측하는 시퀀스 길이만큼을 나누어서 loss의 평균으로 RNN loss를 계산하게 된다
예를들어 다음 3일치(시퀀스 길이 -> 3)를 예측하는 모델 경우 3일치에 해당하는 loss값을 구하여 이를 평균때린다는 말.
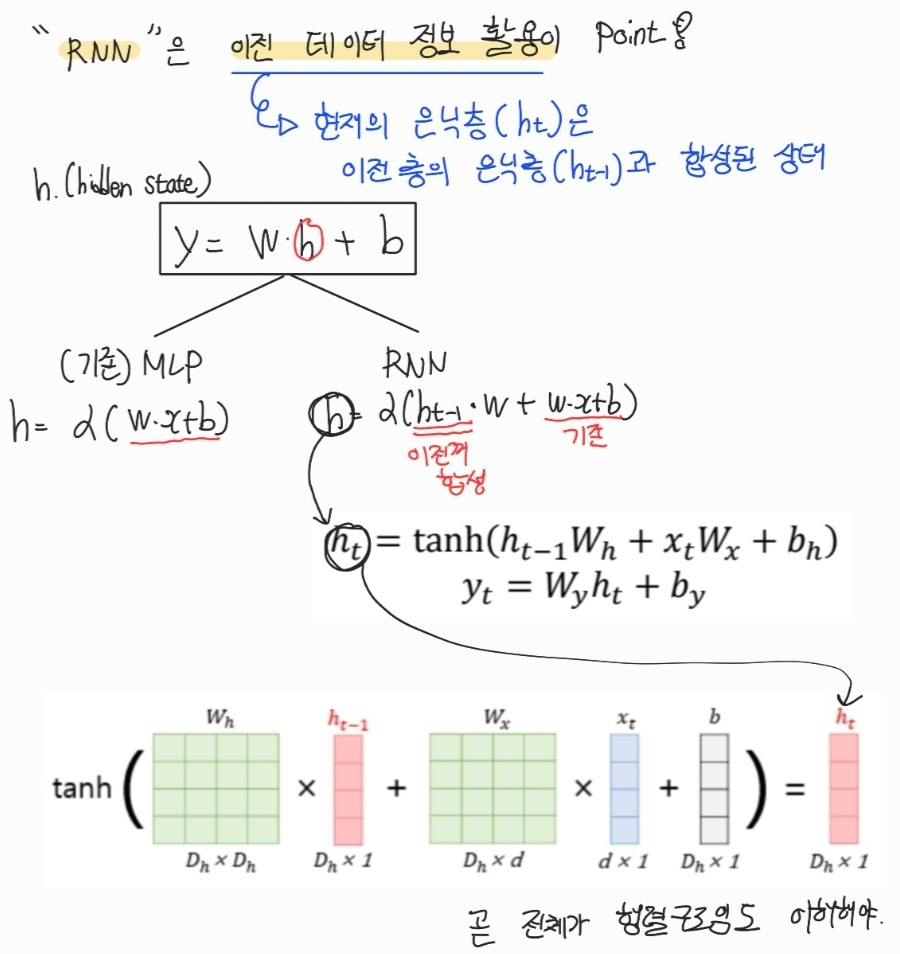
4. RNN 컨셉 요약
현재의 state(=y) = tanh(현재입력값+현재가중치 + 이전가중치 + bias)
- 그리고 바로 위 그림에서도 표현했듯 현재 state의 output도, 이전가중치도 tanh 영향을 받음
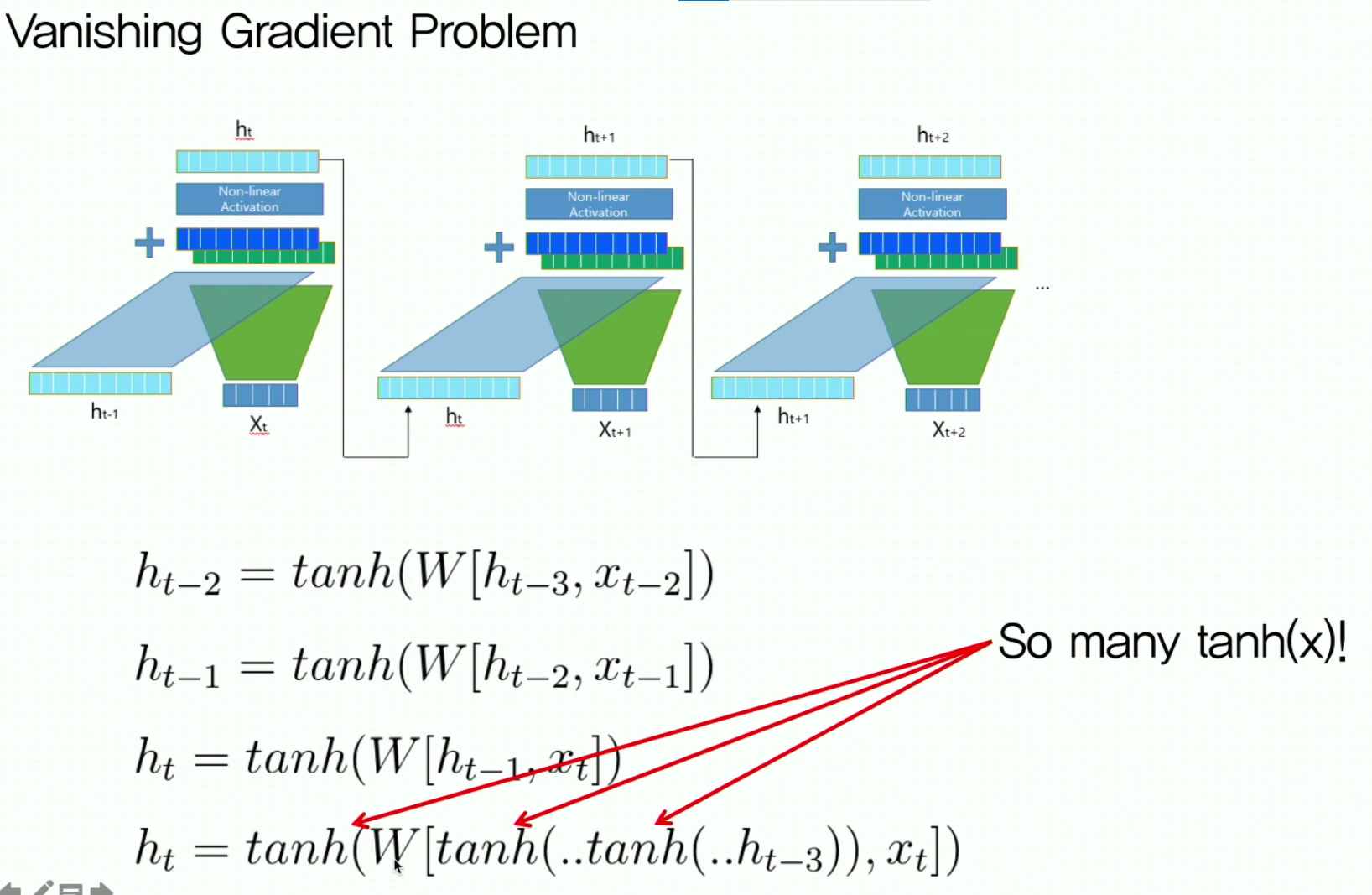
5. RNN의 한계점 : Vanishing Gradient
RNN은 셀 개수가 늘어남에 따라 tanh가 여러번 진행되는데, tanh의 기울기값은 0~1 사이이므로 마지막 step에서는 기울기 소실이 필연적으로 발생하게 됨
- 해결 : LSTM
- 그리고 LSTM에서 연산 경량을 위해 GRU까지 연구됨.
6. LSTM
기존의 RNN 구조에 Information flow(Cell State)를 추가하였다
- 이 flow를 통해 남길 건 남기고, 잊을 건 잊고, 추가할 건 추가해서 중요한 정보만 계속 흘러가도록 한다
- 그리고 내보내게 되는 hideen state는 cell state에서 내보낼것만 적당히 가공해서 만들자
Cell state는 값이 들어있는 하나의 벡터다. 여기에 있는 값을 조정해서 어디에 얼마나 기억하고 잊을지를 정하게 된다.

6-1. RNN과 LSTM 구조비교
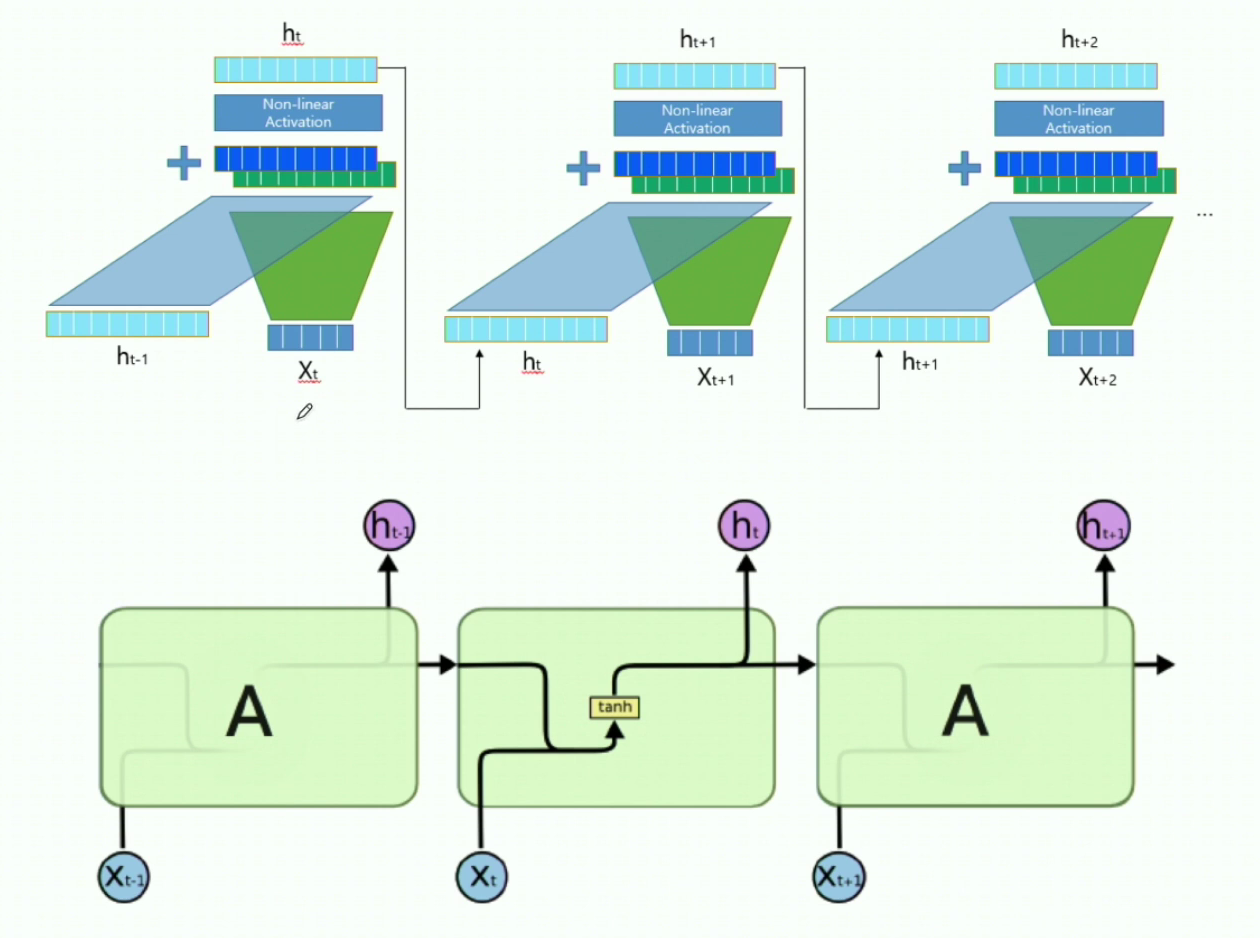
- 위 그림이 기존의 RNN 구조이다.
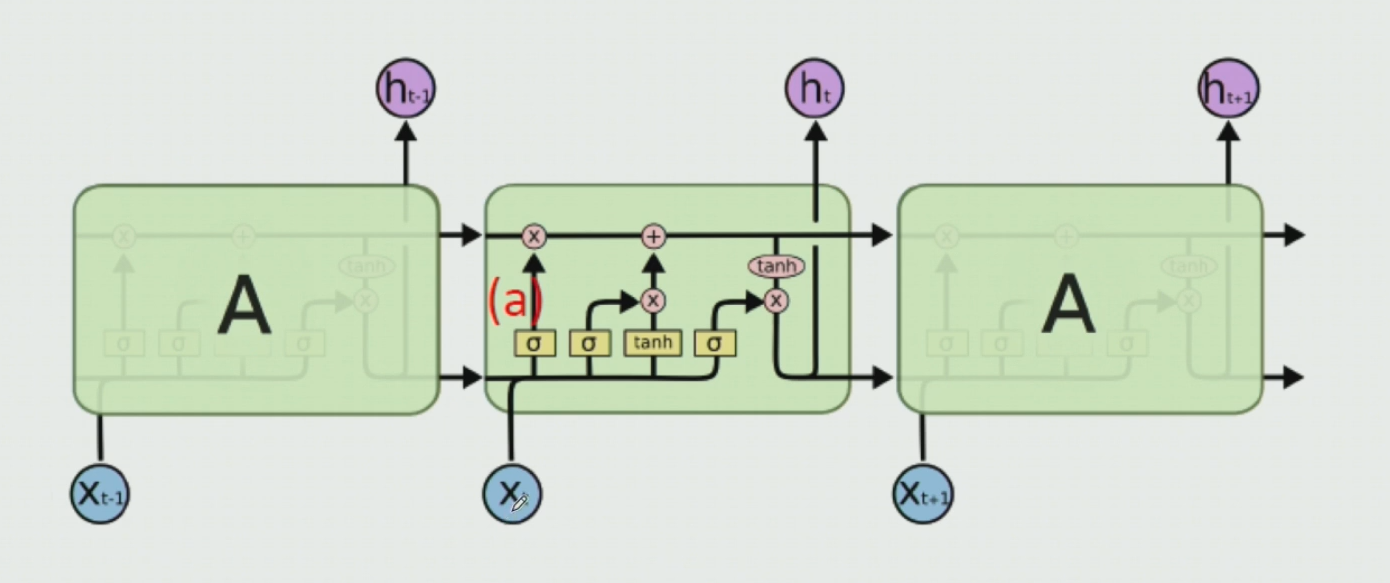
- 위 그림이 LSTM의 구조이다.
6-2. forget gate
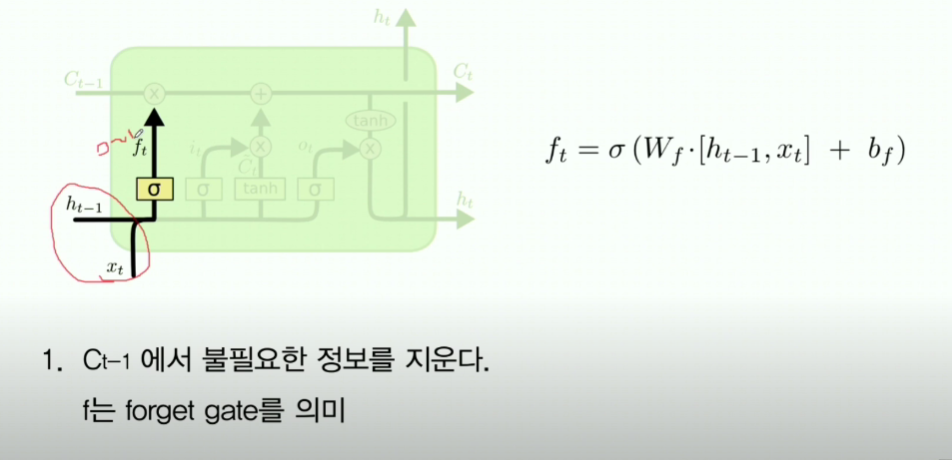
- 이전 h t-1과 x t를 받아서 concat 후 여기에 sigmoid 처리하여 0~1로 표현한다
- 이 0~1 값은 기존의 cell state (C_t-1)에 곱해져서 기존 C_t-1을 얼마나 기억할것인가 를 결정하게 해준다
6-3. input gate
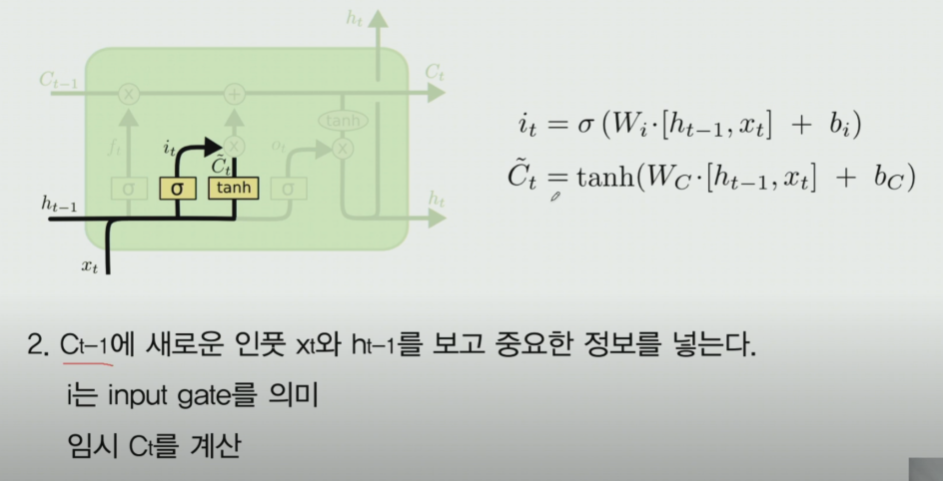
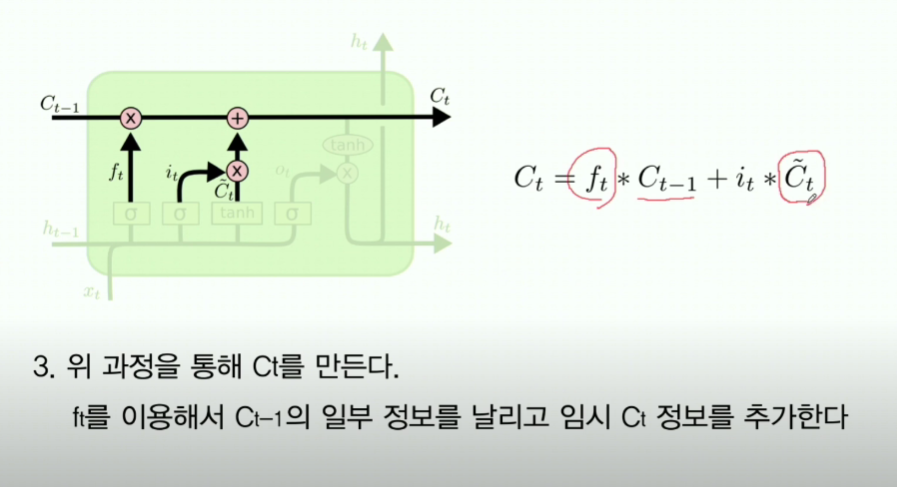
- 여기서는 새로받은 값을 기존 RNN처럼 처리 후, Cell state에 넣어준다
- ~표시는 임시 Cell state라는 의미.
6-4. output gate
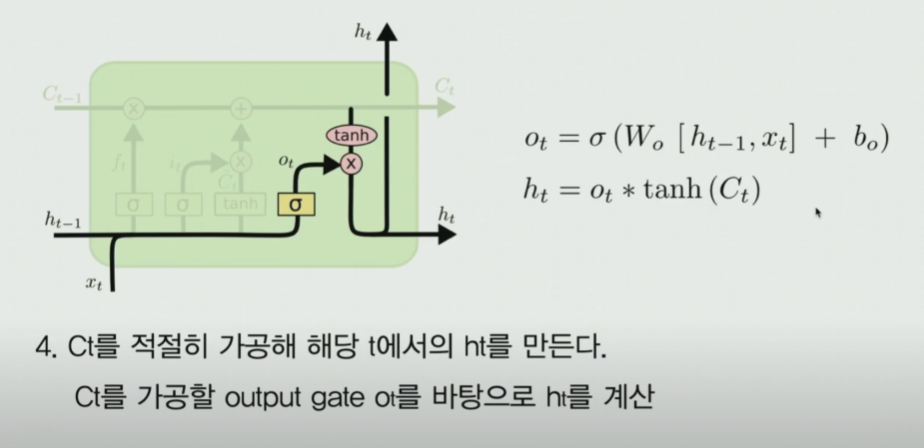
6-5. LSTM은 어떻게 Gradient Issue를 해결하는가
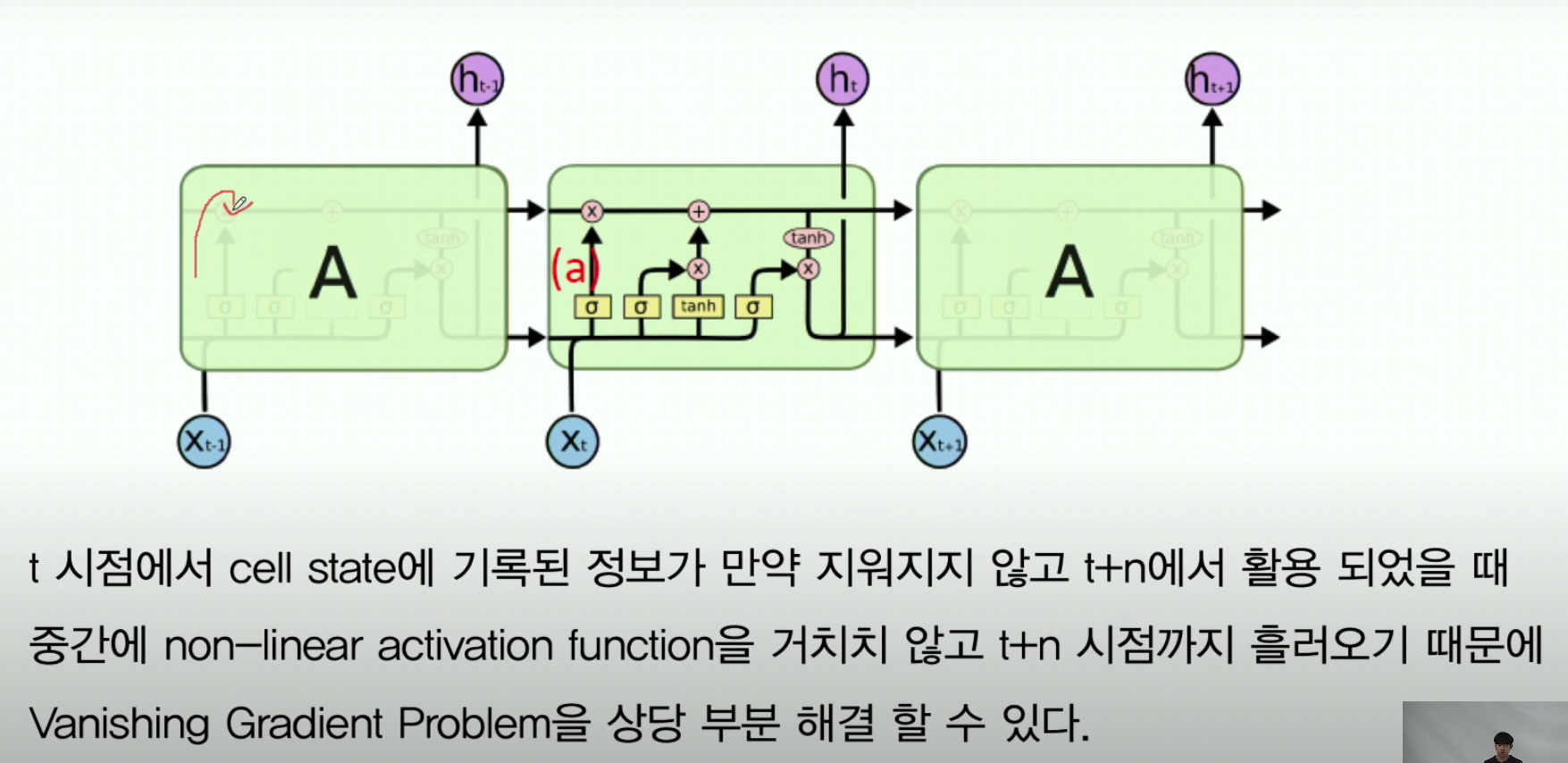
- 위 그림을 보면 cell state에서 tanh가 RNN 셀 개수가 늘어난다고 해서 여러개로 연쇄되는게 아니라, 하나만 작용된다
- 그렇기 때문에 linear하게 진행되는거라서 기울기 소실 문제를 해결할 수 있다
7. pytorch 실습코드로 살펴본 RNN
- reference : 모두를위한딥러닝유튜브
- task : 데이터(시작가, 최고가, 최저가, 종가, 거래량) 의 5개의 input dim과 시계열 7일치 => 그 다음날짜(8일차) 종가 예측
- 주의사항
- regression이기 때문에 output dimension은 1임
- 하지만 이렇게하면 state vector size도 1인데, 이거는 모델 입장에서 굉장히 부담스럽다. hidden layer state 정보를 고작 압축해서 size 1로 주는거니까
- 위에서 언급하였듯, RNN은 output으로 가는거랑 다음 hidden state로 가는거랑 같은값이기 때문이다!
- 그래서 보통 hidden size를 정하고, (예를들어 여기서는 10) 마지막에 output에서 FC로 예측하는 방식
- regression이기 때문에 output dimension은 1임
# hyper parameters
seq_length = 7
data_dim = 5 # 입력 데이터 차원 개수 (칼럼 수)
hidden_dim = 10
output_dim = 1
learning_rate = 0.01
# layers <- rnn 셀을 몇개를 줄 것인가
import torch.nn as nn
class myModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, layers):
super(myModel, self).__init__()
self.layer_rnn = nn.LSTM(input_dim, hidden_dim, num_layers=layers, batch_first=True)
self.layer_fc = nn.Linear(hidden_dim, output_dim, bias=True)
def forward(self, x):
output, _status = self.layer_rnn(x)
output = output[:,-1] # 직전 state정보만을 취급하지!! 7개중에서 (위의 그림 참고)
output = self.layer_fc(output)
return output- 모델 정보는 대략 위와 같다
- 전체 소스코드

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..