빅데이터분석기사 실기 특징
- 라인별 실행불가 (주피터처럼 셀단위가 안된단것임)
- 각종 자동완성 불가 (라이브러리 이름, 함수명 다 외워가야함)
- 유형1 : 무슨짓을 하든 결과만 잘 나오면 됨
- 유형2 : 하루면 완성가능. 템플릿이 정해져있으니 무지성 암기. 유형2에는 시간투자 많이 X
- 시험시간 180분이며 꼭 실제환경에서 테스트를 해보자.
- dir, help 사용 후 메모장에서 다 붙여놓고 이후 ctrl + F

제1유형
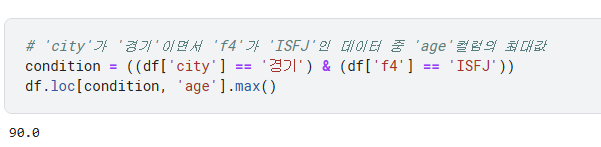
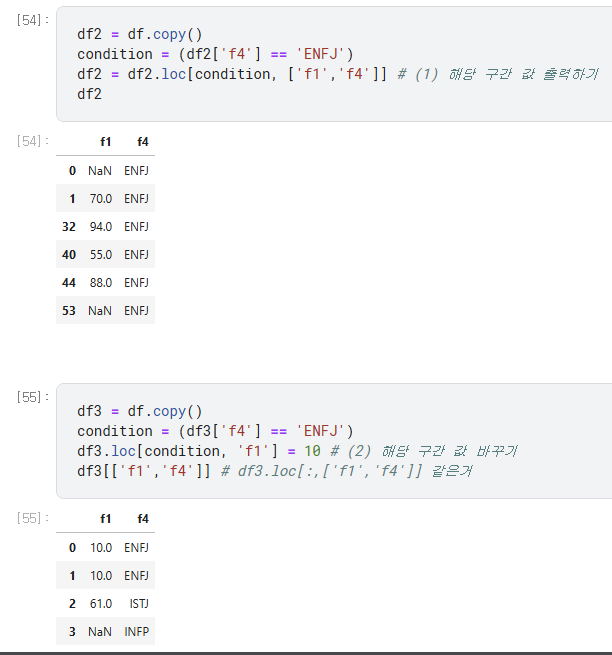
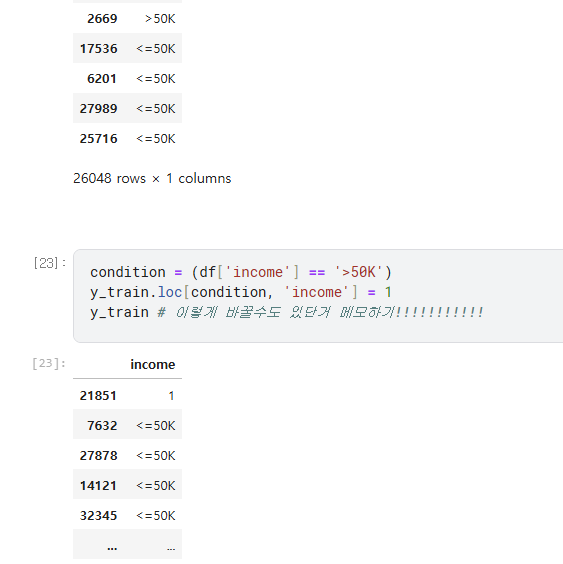
- df.loc[행조건, 열조건] => 이건 곧 그 구역값을 지정하는 방법인거다
- (1) 원하는 구간을 출력을 원한다면 : df = df.loc
- (2) 원하는 구간에 값을 바꾸고 싶다면 df.loc = 값
- 값을 바꾸는것도 가능 그 구역에 값을 대입하면 곧 적용이 되는거니까!
- df[행조건, 열조건] = 값 <- 거기에 해당하는 칸에는 모두 값이 들어가지게 되는셈이라고 생각하면됨
# 0. 습관처럼
import pandas as pd
import numpy as np
df = pd.read_csv(path)
print(df.shape())
print(df.isnull().sum())
df.head()
# 1. 이상치 => "quantile"
q1 = df[col].quantile(0.25) # 1사분위 값
q3 = df[col].quantile(0.75) # 3사분위 값
iqr = q3 - q1
v1 = q1 - 1.5 * iqr
v3 = q3 + 1.5 * iqr
# 2. 반올림 / 올림 / 버림
## 2-1. 데이터프레임으로 받는경우 (넘파이 필수)
c = np.ceil(df)
f = np.floor(df) # 내림 -5.5 => -6
t = np.trunc(df) # 버림(절삭) -5.5 => -5
r = np.round(df,자릿수)
r_mean = r.mean() # 이런식으로 array, df는 끝에 '.함수()' 가 많음.
## 2-2. 그냥
import math
math.round(value, 자릿수)
# 3. 값 삭제 => 특정 행/열 drop, 결측치 포함 행/열 drop'na' *loc,iloc 쓸수있으면 쓰는게 젤 낫다
df = df.drop('지울칼럼명', axis = 1) # axis = 1 해줘야함.'1' 세로방향 모양
df = df.drop('지울행 인덱스값 : 행이름이 없으니') # 디폴트가 axis = 0
df = df.dropna() # 결측치 하나라도 있는 행 다 삭제
# 4. 결측치채우기 => df[열].fillna(값)
df['col'] = df['col'].fillna(df['col'].median()) # 중앙값으로 결측치 다 채우는경우
# 이게 이런걸 주의해야함 drop이랑 비슷한건데 1) df['f1'].fillna(variance)라고 해서 반영되지 않음 저거 자체의 결과값은 데이터프레임에 바로 반영이 아니라 값 자체같은거임
# 2) df = df['f1'].fillna(variance) 이것도 잘못된거지 값 자체를 전체 데이터프레임으로 대입하려 했으니까
# 3) ★ df['f1'] = df['f1'].fillna(median_num) 이렇게해줘야 반영이됨!! 즉 pandas에서 잘 안되는거있으면 이런식의 사고를 해보기 ★
# 5. 왜도와첨도
v1 = df['col'].skew()
v2 = df['col'].kurt()
# 6. df1의 누적합 df2 구하기 => cumsum()
df2 = df1.cumsum()
df2 = df2.fillna(method = 'bfill') # 이 때 발생하는 결측치를 뒤의 값 채우기
df2 = df2.fillna(method = 'ffill') # 앞의값으로
<<<<< # 7. 표준화 >>>>> => 암기 ★sklearn ~ StandardScaler ~ fit_transform★
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['col'] = scaler.fit_transform(df[['col]]) # df['f5'] 이렇게하면 오류남!!! 인자를 시리즈가 아닌 데이터프레임으로 받아야하기 떄문!!
df.head()
'''
* 기본 외워야함 : from sklearn.preprocessing import StandardScaler, scaler(), fit_transform
* fit_transform은 인자를 series가 아닌 dataframe으로 받는다
* 가장 쉬운거는 []말고 [[]]로 하면 dataframe이 된다!
* seires, dataframe 차이 : series는 dataframe의 구성요소로 열 한개임. df도 열이 한개일 수는 있지만 series는 무조건 한개겠지
위에처럼 그냥 []하면 series로 나오고 [[]]로 하면 df로 나옴..!!
'''

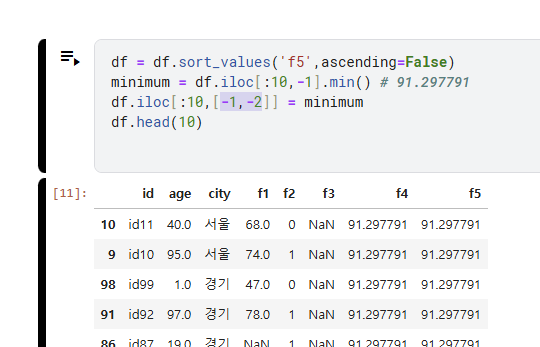
# 8. 특정 칼럼 기준 데이터프레임 정렬하기
df = df.sort_values('col', ascending=False) # 내림차순
df.head()
# 8-2. 특정 칼럼의 개수(빈도) 세기
df[col].value_counts() # type이 series임!
# 9. 표준편차 => .std()
# 데이터셋(basic1.csv)의 'age'컬럼의 이상치를 더하시오!
# 단, 평균으로부터 '표준편차*1.5'를 벗어나는 영역을 이상치라고 판단함
# 표준편차는 'std' 란걸 기억하자!
std = df['age'].std()*1.5
mean = df['age'].mean()
option = (df['age'] > mean + std) | (df['age'] < mean - std)
df.loc[option]['age'].sum()
'''
암기 : .sum(), std(), mean(), max(), min()
특이사항 : 전부 다 df.~~ 이다 평균이든 칼럼삭제든 정렬이든 전부!!!
'''
<<<<< # 10. 시계열 pd.to_datetime >>>>> (<<<시계열 나오면 먼저 바꾸고 시작 일단 바꾸고!>>>)
'''
- 문자열로 접근해도 되지만 datetime 쓰는게 훨씬 정신건강에 낫다!
- df[col] = pd.to_datetime(df[col]) 이 시작! df[col] = df[col].to_datetime 아님! 이것만 조금 다르단거 꼭 암기!
1) df[col] = pd.to_datetime(df[col])
2) df[col].dt.year임 df[col].year아님!
'''
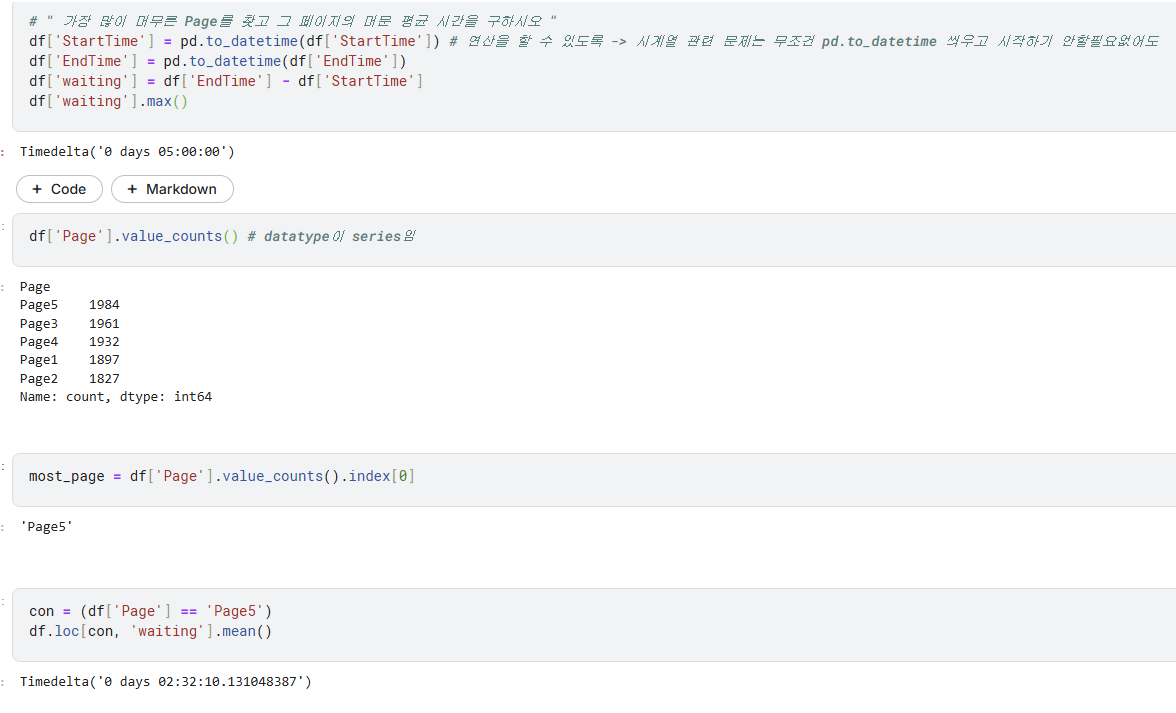
# 날짜가 2018년 1월인 데이터 개수 구하기
df['date_added'] = pd.to_datetime(df['date_added']) # "September 25, 2021" 이런걸 인식해서 "2021-09-25" 이렇게 바꿔주는거임
con1 = (df['date_added'].dt.year == 2018) # 주의1) df[col].year이 아니라 df[col].dt.year이다!!
con2 = (df['date_added'].dt.month == 1) # 주의2) '2018'이 아니라 2018임!
# 아래처럼 연산하듯이 비교도 가능 이럴땐 dt.year이런걸 안쓰는거고 문자열로 감싸줘야
cond2 = df['date_added'] >= '2018-1-1'
cond3 = df['date_added'] <= '2018-1-31'
len(df.loc[con1&con2])
Group by
시험을 떠나 group by는 판다스에서 매번 헷갈리는 개념이였기에 여기에 추가로 정리한다
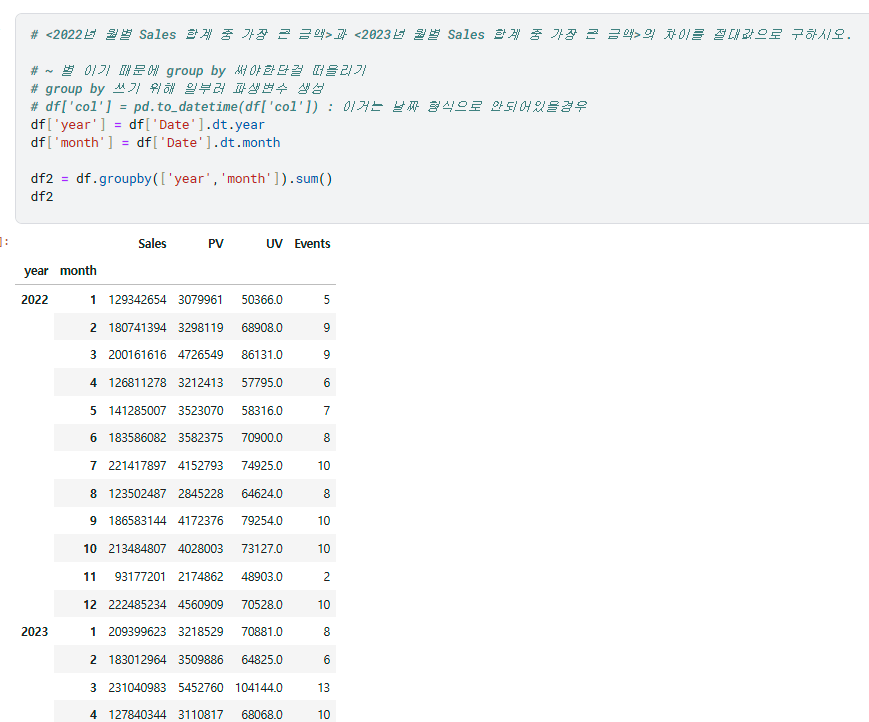
위와 같은 데이터가 있다고 할 때,
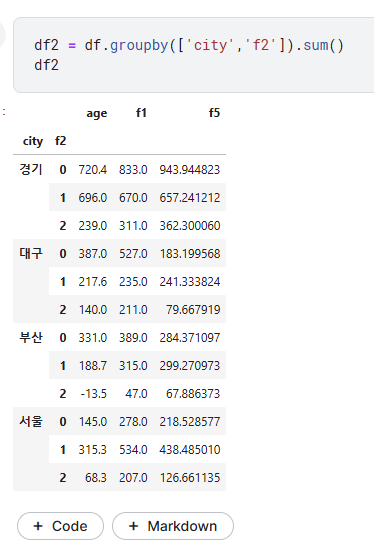
- groupby : 특정 "(범주형)칼럼" 기준으로 새로운 피봇테이블 탄생 => 여기서의 칼럼은 기존 칼럼중 수치형 칼럼만남음
- df2 = df.groupby(['원하는 칼럼들']) : 이거는 행위만 하는거기 때문에 출력해도 아무것도 나올 수 없음
- df2 = df.groupby(['원하는 칼럼들']).sum() 이런식으로 min sum 등 해야 출력가능
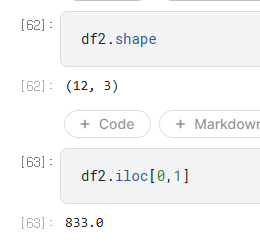
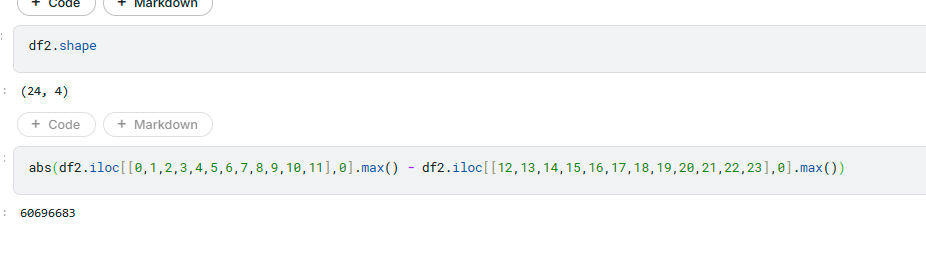
- df2 출력한 후 원하는건 iloc로 찍으면됨. => 이렇게 1) sum,min 조치등 까지 했을때 원하는 칼럼을 기준으로한 새로운 df가 만들어지며,
- 2) 여기서는 기존 df들 처럼 iloc 이런거로 찍을수도 있게 되는것임! (즉 이제서야 데이터프레임에 원하는 후처리 가능)

제2유형
아묻따 랜덤포레스트
위에 링크가 정말 좋음
파라미터튜닝까진 할 필요없고 정형화해서 암기하기
1. 데이터 load, 수집
- x_train, y_train, x_test, y_test(제출값!) : 얘네 순간적으로 안헷갈리게 조심!
- x_train은 레이블이 확실히 제외되어있는지, y_train은 레이블만 확실히 있는지!
- x_train = train.drop('col',axis=1) # col 여러개면 리스트로 넣으면됨
- y_train = train['label'] # [['label']]
- head(), shape(), info() 기본
- x_train은 레이블이 확실히 제외되어있는지, y_train은 레이블만 확실히 있는지!
2. 전처리[결측치 - 변수선택 - 원핫인코딩]
-
결측치
- 결측치 확인
- print(x_train.isnull().sum())
- print(x_test.isnull().sum())-
발생한 칼럼마다
-
x_train[col] = x_train[col].fillna(x_train[col].mean())
- x_test[col] = x_test[col].fillna(x_train[col].mean())
- 이러면 개수 차이 다른거 train, test, x, y 이런 이슈들 다 없어짐
null_cols = ['workclass', 'occupation','native.country'] for col in null_cols : x_train[col] = x_train[col].fillna(x_train[col].mean()) x_test[col] = x_test[col].fillna(x_test[col].mean()) print(x_train.isnull().sum()) print(x_test.isnull().sum()) # 둘다 0으로 되었는지 확인 # 수치형이 아닌경우 그냥 "null"로 대체! x_train[col] = x_train[col].fillna("null") ```
-
-
-
변수선택
-
원핫인코딩(겟더미)
- x_train = pd.get_dummies(x_train) # 걍 통으로 넣으면됨 칼럼선택노필요!!!
- x_test = pd.get_dummies(x_test)
- 혹시나 나중에 오류나면 train과 test 칼럼 수 달라져서 그럼 이때는 걍 set으로 차집합 구현해서 남는거 없애기
3. 모델링 : 랜덤포레스트
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# 특히 Classif'i'er 철자 주의 ㅎ (발음을 속으로 정확히 읽어보며)
model = RandomForestClassifier()
model.fit(x_train, y_train)
pred = model.predict(x_test)- 혹시나 분류해서 0,1로 둔게 object(float)라서 오류난다면 int로 바꿔주면됨!
- y_train = y_train.astype('int')
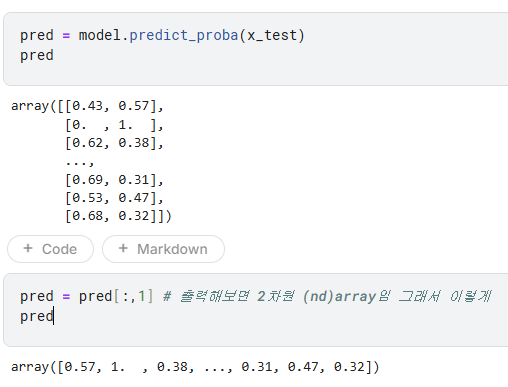
- 분류문제중 확률값을 물어보는거라면
- pred = model.predict_proba(x_test)
- pred = pred[:,1]
<<<<< 4. 제출(코드 암기!!) >>>>>
pd.DataFrame({}).to_csv('title.csv', index=False)
pd.DataFrame({'ID': test.ID, 'segmentation': pred}).to_csv('수험번호.csv', index=False)- 제출 결과 요구형태가 확률값인지, label(정수)인지 확인
- 보통 index 제외하라고 하니 index 제외되었는지 확인
- 제출해야하는 칼럼명 확인
-> 제출파일은 직접 눈으로 확인!
3유형
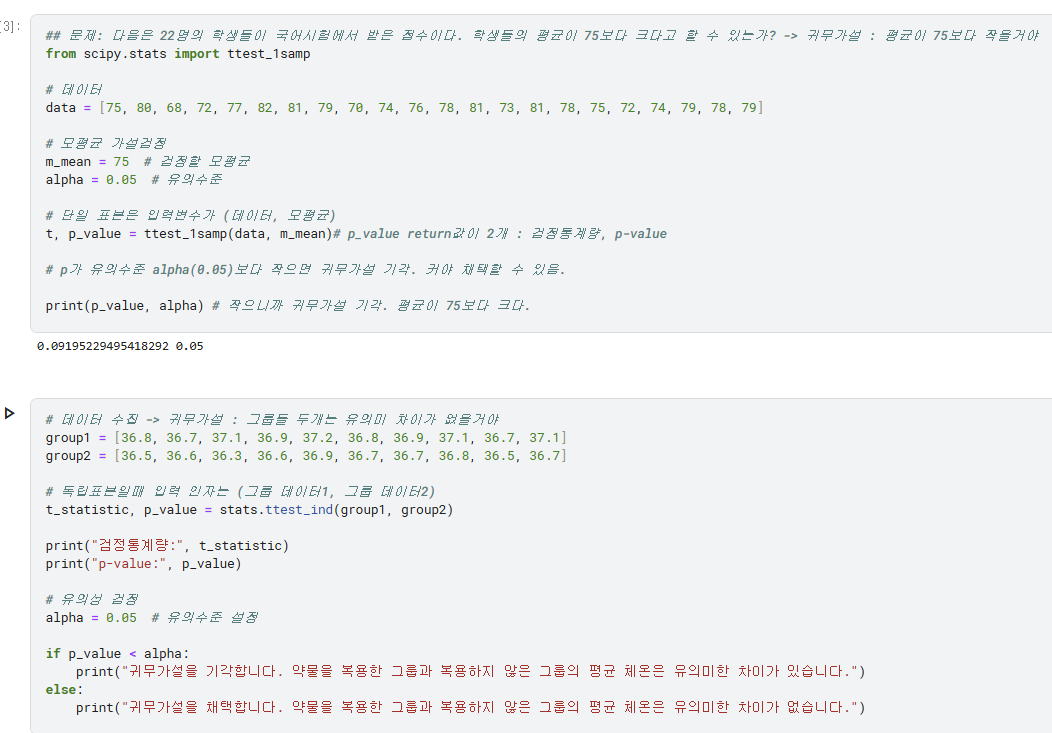
1) t-검정
- 한 개의 그룹 : 단일 표본 t 검정 -> 1 sample -> 1samp
- 두 개의 그룹
- 그냥 별개 그룹 : '독립' 표본 -> independent -> ttest_ind
- 영향 있는 그룹 : '관련' 표본 -> related -> ttest_rel
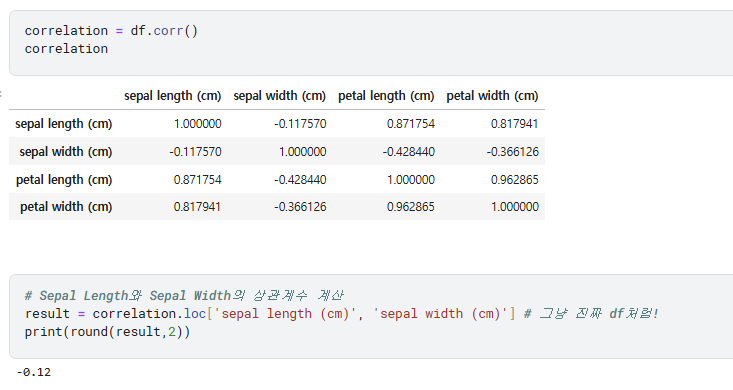
2) 상관계수
시험후기 (합격)
- 1유형 : 지금까지 이 시험의 기출 비교하면 매우 어려웠음.(그래도 일반 기업 코테보다는 비슷하거나 조금 더 낮음) 기사임에도 합격률 실기 높단점때문에 일부러 대폭 상향했다는 생각이 들었음.
- 2유형 : 매우 쉬웠음. 위에 한 정도대로 랜덤포레스트 + 전처리도 거의 안하는 정도.. 해도 만점 나왔음
- 3유형 : 실제로 공부안해서 난이도 어땠는지 모르겠음
드리는 말씀
1) 1유형에 집중하세요. 난이도 조정이 들어간다면 1유형을 건들기좋고 실제로 금번시험도 1유형 매우 어려웠습니다. 그리고 어차피 판다스 익혀두면 좋으니깐요
2) 2유형은 자신만의 최소한의 틀만들고 외우는정도만 한 뒤 1유형에 몰빵하는게 좋을 것 같습니다 + 3유형 심신안정용 최소한의 공부정도.. 신유형이니까 앞으로 또 어떻게 될지 모르니깐요. 근데 전 안함 그리고 3유형은 특성상 맞은것같은데 하면서 열심히 해도 알고보면 0점인경우도 되게 많을 수 밖에 없어요 (실제로 그렇습니다)
3) 저는 2유형 만점, 1유형 1개만 틀리고 3유형 다 날려서 붙었습니다. 혹시 이거 보시는 분도 가성비 좋게 붙으시길..

맛있게 정리해놓으셨네요, 시험 5일전인데 한번 트라이 해볼게요 후기남기겠습니다.