"RAG "
쉽게 말하면 : LLM이 질문에 답할 때, 자기 기억(학습 데이터)만 쓰는 게 아니라, 회사 문서나 DB를 실시간으로 검색해서 필요한 정보를 찾아 답변에 넣는 기술.
- 비유: 기억력 좋은 비서가 메모리에서 꺼내는 것뿐 아니라, 필요할 때 사내 자료실에서 최신 문서를 찾아와 답을 보완하는 느낌.
- 활용 포인트:
- 사내 문서(PDF, Word, PPT, Excel 등)를 텍스트로 변환하고, 의미 단위로 쪼개서(chunking) 벡터 DB에 저장.
- 사용자가 질문하면 LLM이 벡터 DB에서 관련 문서를 찾아서, 그 내용을 바탕으로 답변.
RAG에 대해서
1) RAG 핵심 흐름, 한 장 요약
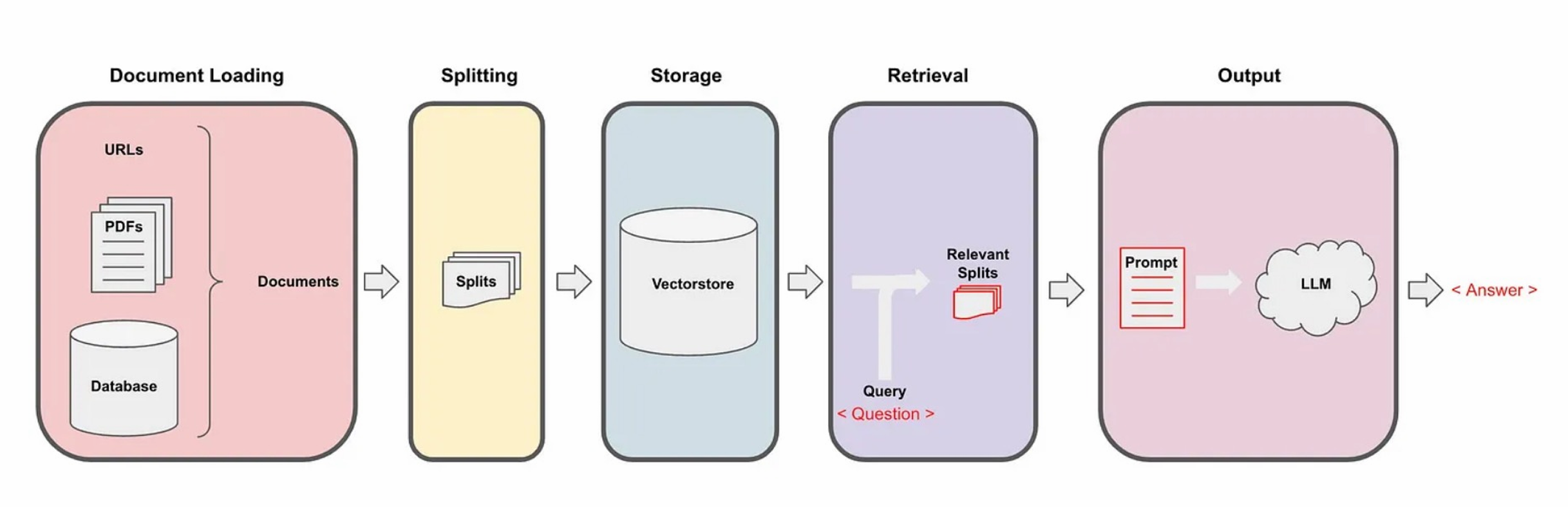
Load → Split → Embed/Store → Retrieve → Generate(p77–83): 문서를 불러와 잘게 자르고(청킹), 벡터로 바꿔 벡터DB에 저장, 질문을 벡터로 바꿔 관련 청크 Top-k를 가져와 답을 생성합니다. 이 파이프라인이 기본 뼈대예요.
2) “청킹”이 성능을 절반은 먹고 들어간다
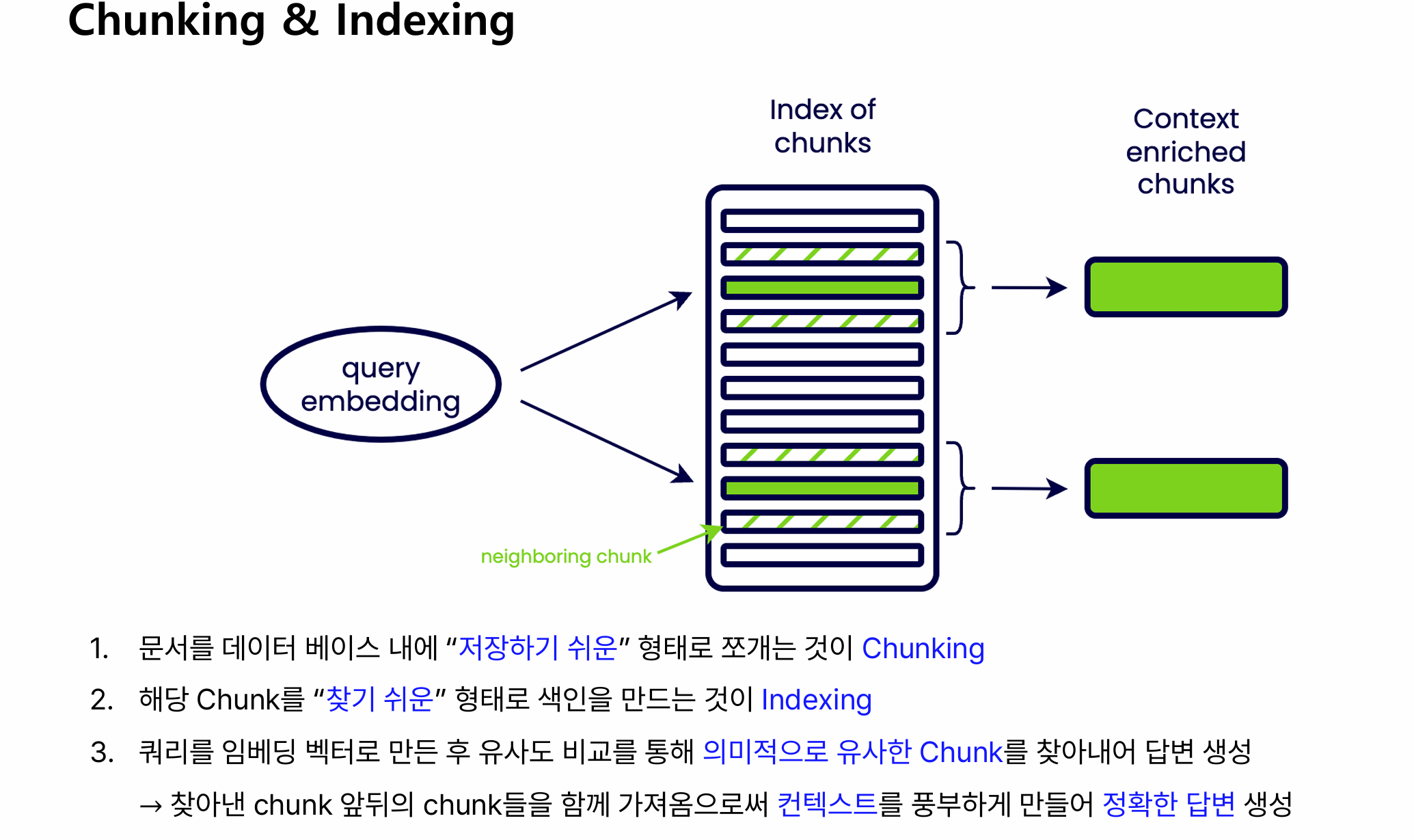
왜 중요? LLM 입력창은 한정되어 있으니, 질문에 딱 필요한 정보가 조밀하게 들어가야 합니다(p19).
방법 레벨
lv3가 현업에서 가장 많이쓰임. lv1,2는 룰베이스고 4,5가 ai로 chunking하는 방식인셈 (수업자료 참고)
Lv1–3: 고정 길이 / 재귀 분할 / 문서 구조 기반 분할(p20–21). 표는 Markdown 변환 등 구조화가 필수(p20). 이미지도 설명 텍스트를 먼저 뽑아 저장(p20).
Lv4: 시맨틱 청킹—문장 임베딩 간 단절점에서 나누기(p22).
Lv5: Agentic/Proposition 청킹—“명제(Proposition) 단위”로 자르면 QA 성능이 오른다는 근거(p23–25). LLM이 명제들을 적절한 청크에 묶도록 “청킹 자체를 맡기는” 접근(p24–25).
팀 적용: 사내 규정/FAQ는 문단 기반 + 표 Markdown + 시맨틱 보정, 약관/가이드라인은 명제 기반이 실전에서 먹힙니다.
3) 검색을 똑똑하게: Hybrid(Embedding 방식) + ReRanking + Top-k

Dense vs Sparse: 의미기반 Dense가 일반적으로 강하지만, 금융 도메인처럼 키워드 정확성이 중요한 경우 Sparse(BM25)가 유리할 때가 있습니다. 그래서 Hybrid(둘 다)로 가는 흐름(p51).
- 하이브리드 검색(p.51): 금융 문서처럼 키워드가 중요한 경우가 많아 BM25(정확 키워드) + 벡터(의미)를 합성하는 게 트렌드.
ReRanking: 1차로 넓게 가져온 후보(예: 50개)를 정밀 채점해 상위 5~10개만 최종 컨텍스트로(p52). Cross-encoder는 성능은 좋지만 지연시간이 커서 실서비스엔 주의(p54).
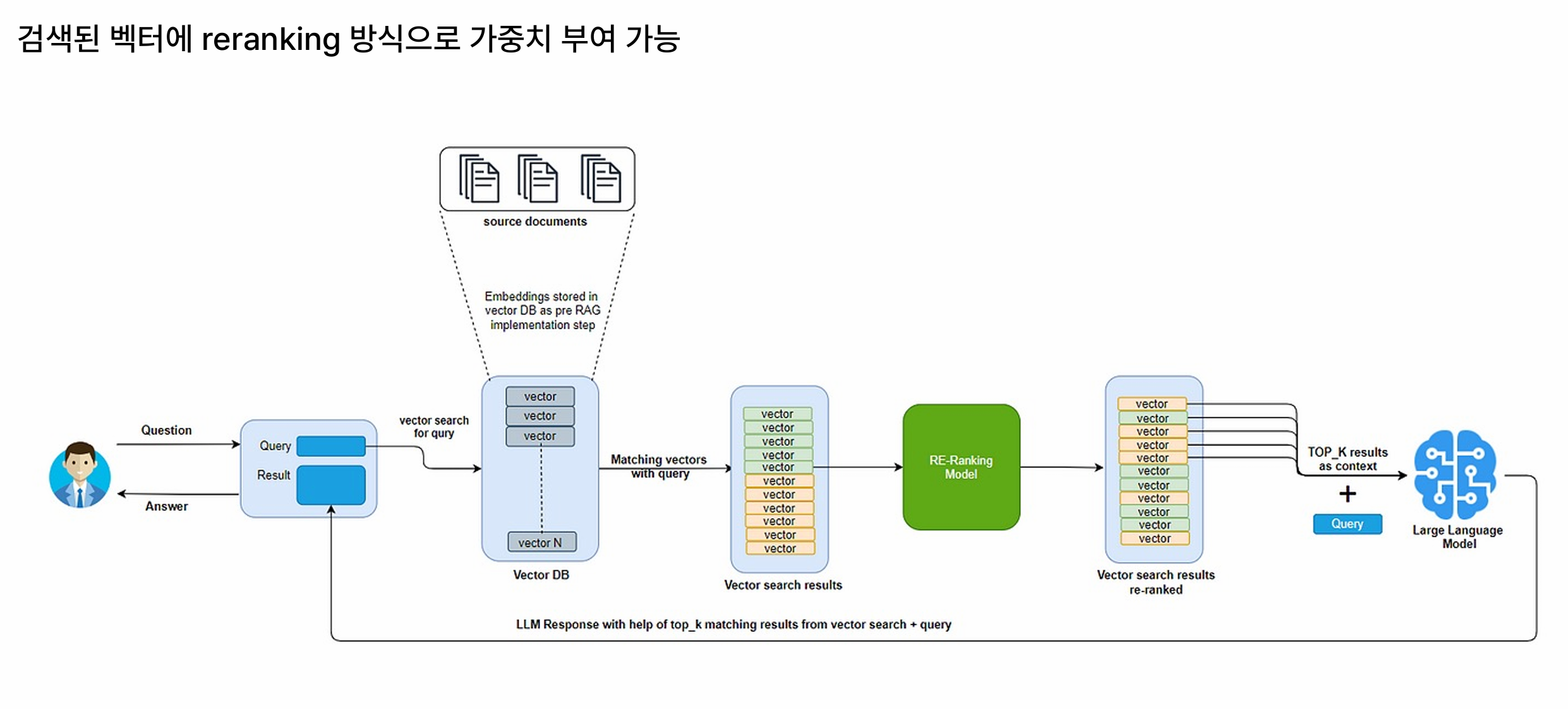
- 재순위화(Reranking, p.52): 1차 검색 Top-k를 Cross-Encoder가 정밀 재정렬 → 근거 품질이 확 눈에 띄게 좋아집니다.
Top-k 트레이드오프: 많이 가져오면 정확도↑, 그러나 잡음과 비용↑. 실제론 k=5~8부터 시작(p84).
팀 적용
Hybrid Retriever 기본값으로 세팅.
초기엔 가벼운 reranker(지연 예산 내)를 붙여 “정확한 상위 N개”만 넣기.
쿼리/도메인별 k를 A/B로 조정.
4) 쿼리 리라이팅(Query Rewriting)
개념: 사용자의 모호한 질문을 검색 친화적 질문들로 자동 변환/확장해서 리트리버가 더 잘 찾게 만드는 단계(p59–60).
예) “급여 규정 알려줘” → “연차 수당 계산 규정?”, “초과근무 수당 지급 시기?”, “2024 개정 사항?” 같이 다각도 파생쿼리 생성 후 합집합 검색.
팀 적용: 초기엔 Multi-Query(동의어/세부화/반대로 묻기) 도입 → 로그로 가장 많이 쓰인 리라이트 패턴을 사전(rule)로 굳혀 속도·일관성 확보.
5) Agentic RAG(자기반성 루프, 라우팅)
SELF-RAG: 검색→초안 생성→스스로 사실성/연관성 평가→추가검색 또는 수정 루프(p62–64).
Adaptive-RAG: 질문 복잡도/정답 위치에 따라 사내DB로 충분한가? 외부 검색이 필요한가?를 라우팅(p65–66).
팀 적용: MVP에선 “사실성 체크 1회 + 필요 시 재검색”만 넣어도 체감 품질이 확 올라갑니다.
6) LangChain으로 구현—우리 팀 기본 레시피
모듈 맵: Loader→TextSplitter→Embeddings→VectorStore→Retriever→(QueryRewrite)→(ReRank)→LLM (p75–83)
권장 세팅(스타트 값)
TextSplitter: 문단 기준 600–800 tokens, overlap 80–120. 표는 테이블→Markdown 전처리(p20–21).
VectorStore: 로컬 POC는 FAISS/Chroma, 운영은 관리형도 고려.
Retriever: BM25 + Dense Hybrid.
Rewriter: Multi-Query(3~5개) → 결과 합친 뒤 dedup.
ReRanking: 상위 40~60 → rerank → 최종 6~8.
Prompt: “출처 근거 달기 / 모르면 모른다고” 지시.
Eval: 정확성(정답/부분정답), 사실성(근거 일치), 회수율(올바른 청크 포함 여부), 지연시간.
아주 간단한 체인 구성 예(개념 스니펫)
user_question
└─ QueryRewrite(MultiQuery) → queries[3~5]
└─ HybridRetrieve(each) → candidates(~50)
└─ Merge & Dedup
└─ ReRank(top 6~8)
└─ LLM(grounded answer w/ citations)
7) 우리 팀 프로젝트에 바로 넣을 운영 가이드
데이터 전략
문서별 청킹 전략표 만들기:
정책/약관/규정 → 명제 기반 우선(p23–25).
공지/가이드/튜토리얼 → 문단+시맨틱 보정.
표/FAQ → 표→Markdown, Q/A 페어 별도 인덱스(p20–21).
이미지(양식 캡처 등) → 설명 텍스트 추출 후 함께 인덱싱(p20).
메타데이터 필터(부서/버전/시행일)로 검색공간을 줄이기(p27–28).
검색 품질 테크닉(우선순위)
Hybrid 기본 + ReRanking(가벼운 모델) (p51–52).
Query Rewriting으로 회수율 올리기(p59–60).
복잡한 질의(“케이스 비교”, “절차+조건”)엔 트리/요약 기반 RAPTOR로 다층 컨텍스트 제공(p31–33).
도메인 간 연결이 많으면 Graph 기반으로 확장(지식그래프 + 커뮤니티 요약)(p28–29, 34–39).
운영/평가
오프라인 평가셋: 사내 문의 티켓 100건 골라 정답·근거 레이블링.
K값, 리라이트 개수, rerank 깊이를 주별로 튜닝—정확도/지연 Pareto 맞추기(목표: P50<1.5s, P95<3s 같은 식).
실패 로그는 “못 찾음/잘못 인용/모호한 질문”으로 분류해 룰(or 리라이트 프롬프트)에 반영.
8) 심사 설득 포인트(경진대회 대비)
정확도 향상 근거: 명제 청킹 + Hybrid+ReRank + Query Rewrite로 회수율↑, 잡음↓(p20–25, p51–52, p59–60).
안전성: “근거 인용”과 “불확실 시 거절” 프롬프트.
확장성: 필요 시 Agentic 루프와 GraphRAG로 난이도 높은 질의 커버(p28–29, p62–66).
운영지표: 정확/사실/지연 3축 공개.
빠른 적용 체크리스트
문서 타입별 청킹 전략 확정(Lv3/4/5 혼합).
Hybrid Retriever 기본 세팅, k=6–8에서 시작.
ReRank: 후보 50 → 최종 6–8.
Multi-Query Rewrite 3–5개.
답변 프롬프트: 근거 인용 + 불확실 시 거절.
100문항 평가셋으로 주별 튜닝.
LLM, RAG, LangChain 비교
✅ RAG
- 구성 요소
-
문서 벡터화 DB (벡터 스토어, 예: Pinecone, FAISS, Chroma)
→ 문서를 잘게 쪼개고(Chunking) 임베딩으로 변환해 저장.
-
검색 단계
→ 사용자가 질문하면 임베딩 기반으로 관련 문서를 찾아옴.
-
LLM
→ 찾아온 문서를 참고해 답변을 생성.
-
- 즉, RAG = LLM + 문서 벡터DB + 검색(리트리버)
- 쉽게 말해: LLM 혼자 대답 못하니까, 문서DB에서 검색해와서 보강하는 구조.
✅ LangChain
- 문제 배경: RAG를 직접 구현하려면
- 문서 쪼개기 (Chunking)
- 임베딩 변환
- 벡터 DB 저장/검색
- 검색 결과 LLM에 전달
- 출력 정리 (예: JSON, 요약, 보고서 형식) 이런 단계를 전부 직접 코딩해야 함 → 너무 복잡.
- LangChain 역할: 이 모든 과정을 모듈화 + 체인(Chain)으로 제공해서 쉽게 조합 가능하게 만들어줌.
- 예:
RetrievalQAChain하나로 질문 → 검색 → 답변 다 가능. - 또, RAG뿐 아니라 에이전트(Agent), 워크플로우, 툴 연동(Google 검색, DB 질의 등)까지 가능.
- 예:
- 쉽게 말해: RAG 구현을 빠르고 편하게 만들어주는 프레임워크.
✅ 비유로 정리
- LLM = 똑똑한 두뇌
- RAG = 두뇌 + 자료실(문서DB) + 사서(검색)
- LangChain = 이걸 자동화해서 쉽게 쓸 수 있는 매니저/레고블록 세트
👉 요약
- “RAG는 LLM에 문서 벡터화된 DB를 붙인 것” → 맞음
- “LangChain은 RAG+LLM 같은 걸 직접 구현하기 힘드니까 쉽게 쓰게 해주는 프레임워크” → 맞음 (단, RAG만이 아니라 더 다양한 LLM 활용 워크플로우까지 포함한다는 점 추가)
