- 본 포스팅은 네이버커넥트재단과 신기정 교수님(KAIST AI대학원) 자료를 참고하여 작성하였습니다
1. 추천시스템이란
- 개인에 대한 데이터가 수 없이 많이 쌓이는 세상이기 때문에게, 각 개인에게 맞춤형 추천시스템을 많은 회사에서 도입하고 있습니다
- 유튜브의 알고리즘, 넷플릭스에서의 영화 추천, 최근 떠오르고 있는 마이데이터 관련 사업들이 그것들의 일환이라고 할 수 있겠습니다
1-1. 추천시스템과 그래프
- 사용자별 구매 기록을 노드로 표현하여 이종 노드의 그래프로 나타낼 수 있습니다
- 그래프 관점에서 추천 시스템은 '미래의 간선을 예측하는 문제(무엇을 구매하겠는가)' 혹은 '누락된 간선의 가중치를 추정하는 문제(사용자가 별점을 얼마나 메길지)'로 해석할 수 있습니다
2. 추천시스템의 종류
2-1. 내용 기반 추천 시스템
내용 기반 추천은 각 사용자가 구매했던 상품과 유사한 것을 추천하는 방법입니다
- 예시) 동일 학교를 졸업한 사람을 페이스북 친구로 추천 등
내용 기반 추천은 다음 네 가지 단계로 이루어집니다
1. 사용자가 선호했던 상품들의 상품 프로필 수집
- 상품 프로필이란 해당 상품의 특성을 나열한 벡터입니다
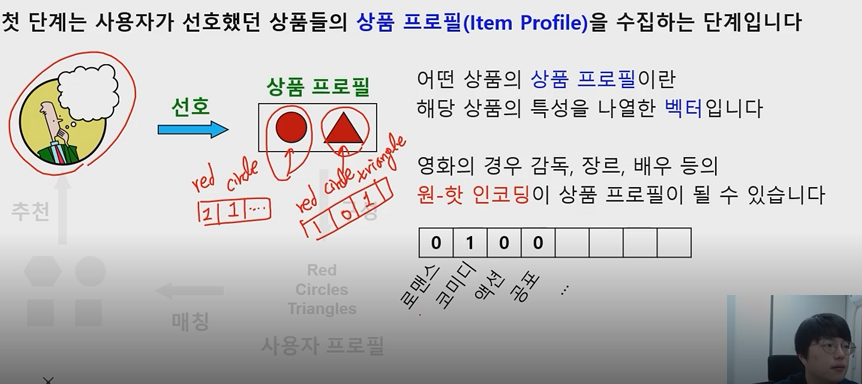
2. 사용자 프로필을 구성합니다
- 위 과정에서 작성된 상품 프로필의 벡터들을 가중 평균하여 사용자 프로필(마찬가지로 벡터)를 계산합니다
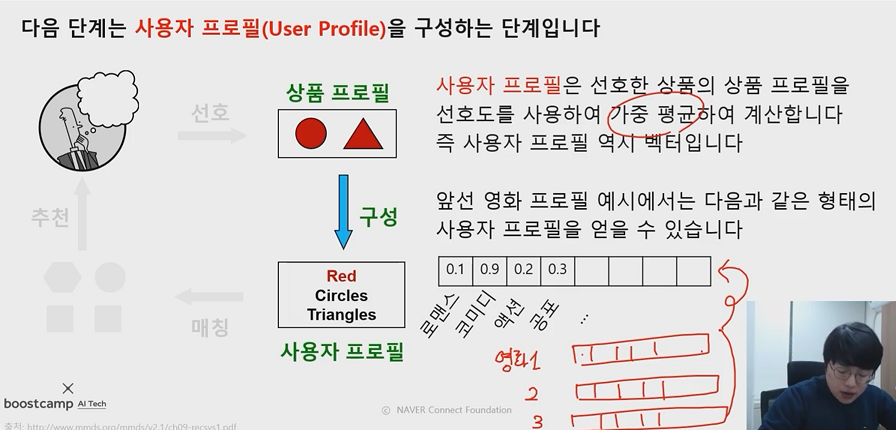
3. 사용자 프로필과 (이용하지 않았던) 다른 상품들의 프로필을 매칭합니다
- 사용자 프로필 벡터와, 상품 프로필 벡터에 대해 코사인 유사도를 계산합니다
- 코사인 유사도가 높을수록 선호할 확률이 높다고 판단할 수 있습니다
4. 코사인 유사도가 높은 상품을 사용자에게 추천합니다
다음과 같은 장단점을 가질 수 있습니다
- 장점 : 다른 사용자의 구매 기록이 필요하지 않음, 추천의 이유를 제공할 수 있음, 특이 취향 반영 가능
- 단점 : 구매 기록이 없는 사용자의 경우거나 추천하고자 하는 상품에 대한 부가 정보(벡터로 표현하기 위한 속성 정보)가 없는 경우에는 사용 불가, 과적합으로 인한 협소한 추천 가능성
2-2. 협업 필터링 추천시스템
사용자-사용자 협업 필터링은 유사한 취향의 사용자들로부터 선호 상품을 찾아 추천하는 원리입니다
- 예시) 넷플릭스 영화 추천 시스템
협업 필터링은 다음 세 가지 단계로 이루어집니다
1. 유사한 취향의 사용자 찾기

- 사용자 x,y에 대한 취향 유사성 sim(x,y)는 상관 계수(Correlation Coefficient)를 통해 측정
- 공동으로 이용한 상품에(S_xy) 한해서만 계산
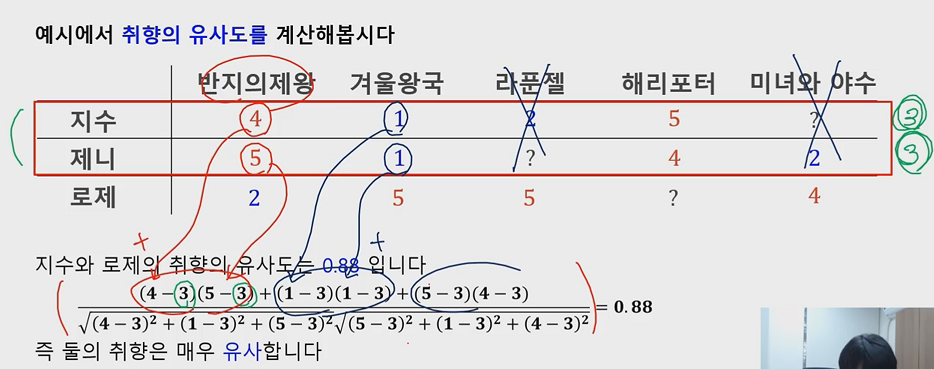
- 위와 같이 둘다 선호하면 (+)(+)로 곱해져서 (+), 둘다 싫어하면 (-)(-)로 곱해져서 (+)로 표현된다
2. 이용하지 않은 다른 상품의 평점 추정하기

- 추천하고자 하는 사용자와 취향이 비슷할수록 가중치를 반영하여 상품의 가중 평균을 계산해서 평점을 추정한다
- 취향 유사성 sim(x,y)를 가중치로 이용하여 가중 평균 산출
3. 추정한 평점이 가장 높은 상품을 추천
다음과 같은 장단점을 가질 수 있습니다
- 장점 : 상품에 대한 부가 정보가 없는 경우에도 사용 가능
- 단점 : 데이터의 충분한 수 필요, 새로운 사용자/상품에 대해서는 추천 불가능, 독특한 취향의 사용자에게 사용 불가능
3. 추천 시스템의 평가
3-1. 데이터 분리
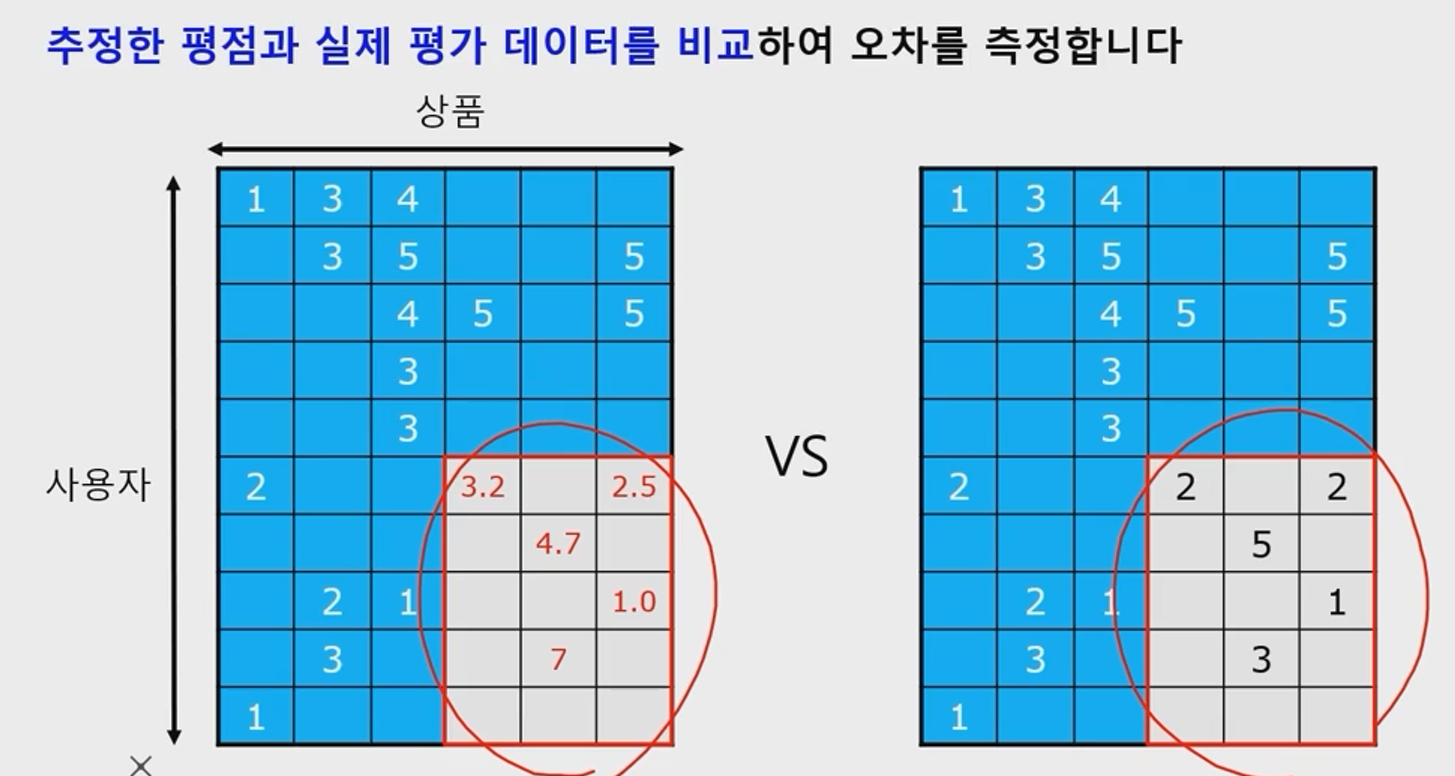
- 사용자가 상품에 대해 매긴 평점 값을 matrix로 구성할 수 있음
- 값이 비어 있는 경우는 사용자가 해당 상품을 이용한적이 없는 경우
- 푸른색이 훈련에 이용된 데이터, 붉은색이 추정 데이터
- 우측의 붉은색은 ground truth(label)
3-2. 평가 지표
- 다른 분야와 유사하게 MSE, RSME 이용
- 이 밖에도 다음과 같이 다양한 지표가 사용될 수 있다
- 추정 순위와 실제 순위 간의 상관 계수
- 추천 상품 중 실구매 비율
- 추천 순서 및 다양성 고려 지표
4. 추천 시스템 실습
위의 링크에서 제가 작성한 코드 내용을 확인하실 수 있습니다

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..