1. Kafka란?
여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메세징 시스템.
메시지(데이터)를 받고, 받은 메시지를 다른 시스템이나 장치에 보내기 위해 사용됨.
2. Kafka의 특징
높은 데이터 처리량, 실시간으로 데이터 취급.
- 여러 서버로 scale out 가능 -> 데이터 양에 따라 시스템 확장이 용이함
- 수신한 데이터를 디스크에 유지할 수 있음 -> 언제라도 데이터 읽을 수 있음
- 여러 제품들과 연계 가능 -> 제품과 시스템 연결하는 허브 역할 가능
- 메시지 전달 보증 -> 데이터 분실 걱정이 없음
3. Kafka를 사용하는 이유
- 높은 데이터 처리량
- 데이터 양이 많아져도 scale out이 쉬움
- 다른 시스템과 연결이 용이함
- 실시간으로 스트림에 데이터가 모이지만 데이터를 읽고 싶을 때 읽을 수 있음
4. 용어 정리
- 스트림 데이터: 시시각각 생성되는 데이터
- 스트림 처리: 스트림 데이터를 들어오는 대로 순차 실행하는 것
- 클러스터: 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합
- 주키퍼(Zookeeper): 아파치 프로젝트 애플리케이션으로, 카프카의 메타데이터(metadata) 관리 및 브로커의 정상상태 점검(health check)을 담당 -> 관리하는 놈
- 카프카(Kafka) or 카프카 클러스터(Kafka cluster): 아파치 프로젝트 애플리케이션으로 여러 대의 브로커를 구성한 클러스터
- 브로커(broker): 카프카 애플리케이션이 설치된 서버 또는 노드. broker에서 받은 데이터는 모두 디스크로 내보내기(영속화)가 이루어져 디스크의 총 용량에 따라 장기간 데이터 보존이 가능하다.
- 프로듀서(producer): 카프카로 메시지를 보내는 역할을 하는 클라이언트
- 컨슈머(consumer): 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트
- 토픽(topic): 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유함 -> database에서 table의 느낌
- 파티션(partition): 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것. 파티션을 브로커에 어떻게 배치하는가에 대한 정보는 브로커 측에 유지된다. 또한 producer, consumer 구현 시에는 파티션을 의식할 필요 없이, 토픽만을 지정하면 된다.
- 세그먼트(segment): 프로듀서가 전송한 실제 메시지가 중개인의 로컬 디스크에 저장되는 파일
- 메시지(message) 또는 레코드(record): 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각
- 리플리케이션(replication): 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작, 브로커가 하나 종료되어도 카프카가 안정성을 유지할 수 있음. 토픽이 리플리케이션 되는 것이 아니라 파티션이 리플리케이션 됨.
5. Kafka 구조
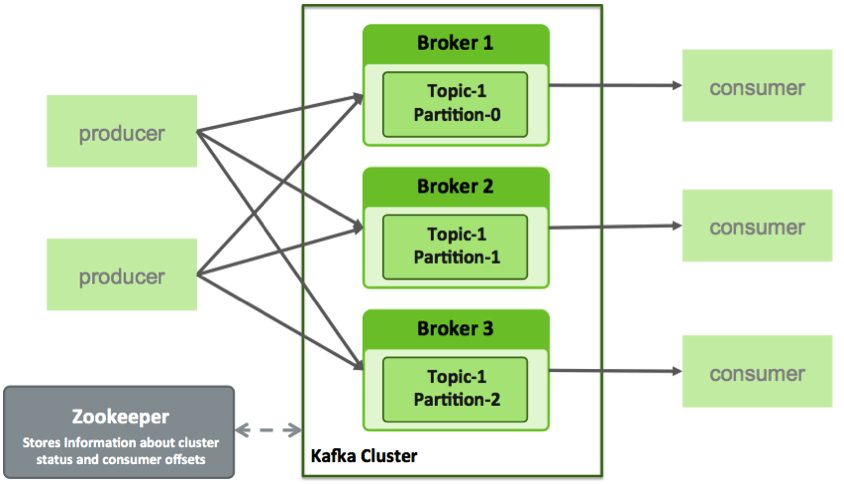
메시지 producer, consumer, 메시지 수집/전달 역할의 broker로 구성되어 있다.
하나의 topic은 여러 broker에 나누어 저장될 수 있다(partition으로 나뉘어진다). 그리고 로드 밸런싱 및 내결함성을 위해 그렇게 하는 것이 일반적이다.
broker를 중간에 끼우는 이유?
1. 접속처를 하나로 줄일 수 있다.
-> producer는 누구에게 메시지를 보낼지 고민하지 않고 broker에 보내기만 하면 되고, consumer도 단순히 broker에서 수신만 하면 된다. broker가 없다면 producer가 consumer에게 메시지를 보내기 위해서 N x M 시스템 구성을 해야 할 수 있다. broker의 존재가 이를 N + M 시스템으로 단순하게 만들어준다.
2. producer, consumer 증감에 대응이 쉽다 -> 네트워크 토폴로지 변경에 강하다.
-> producer, consumer 모두 서로의 존재를 알 필요가 없다. producer, consumer를 증가시키기 위해서 broker에 접속만 시키면 된다. 변경이 생겨도 기존 구조에 영향을 미치지 않는다.
6. PUSH형, PULL형
kafka 시스템에서의 메시지는 producer -> broker -> consumer 흐름으로 이동한다. 여기서 메시지 전달을 어느 쪽에서 발생시키는지 이해하는 것이 중요하다. producer -> broker 메시지 송신은 producer가 주체가 되어 broker에게 전송하는 PUSH형으로 이루어진다. 하지만 broker -> consumer의 데이터 흐름에서 메시지 송신 요청은 consumer에서의 패치 요청을 계기로 메시지가 송신된다. 즉 broker의 입장에서 PULL형으로 이루어진다.
broker -> consumer 송신이 consumer의 PULL에 의해 이루어지는 구조가 가지는 시스템 운영상 큰 장점은, consumer system이 고장이나 유지보수로 정지한 경우에도 broker에 미치는 영향이 적다는 것이다. broker가 PUSH형인 경우, consumer 서비스 중단 시 대응을 매번 broker에서 실시해야 한다. kafka를 경유하는 client가 많을수록, 시스템 운용 부하 및 성능 부하가 증가할 것이다. 또한 broker는 1. consumer의 요청을 기다린다. 2. 해당 요청에 대응해서 메시지를 보낸다. 3. offset에 따라 진행을 관리한다. 라는 특성 덕분에, 후속 시스템(client)가 동적으로 증감해도 consumer별 개별 대응이 적다. 왜냐하면, consumer가 주체적으로 데이터를 수신, 진행 관리하기 때문이다.
이러한 특성 덕분에 kafka에서는 후속 시스템의 확장과 축소가 수월하다.
출처
http://wiki.gurubee.net/pages/viewpage.action?pageId=33752042
https://zeroco.tistory.com/105
사사키 도루, 『실전 아파치 카프카』, 정인식, 한빛미디어(2020)
