데이터 분류하기
웹 크롤링을 통해 데이터를 가져올 때, 내가 필요한 데이터만 가져오는 방식에 대해 알아보자.
findAll() find_all()
CSS 코드를 이용해 불러오는 방식이다
findAll(tag, attributes, recursive, text, limit, keywords)위와 같은 값을 이용하여 그에 해당하는 데이터만 가져올 수 있다!
tag로 불러오기
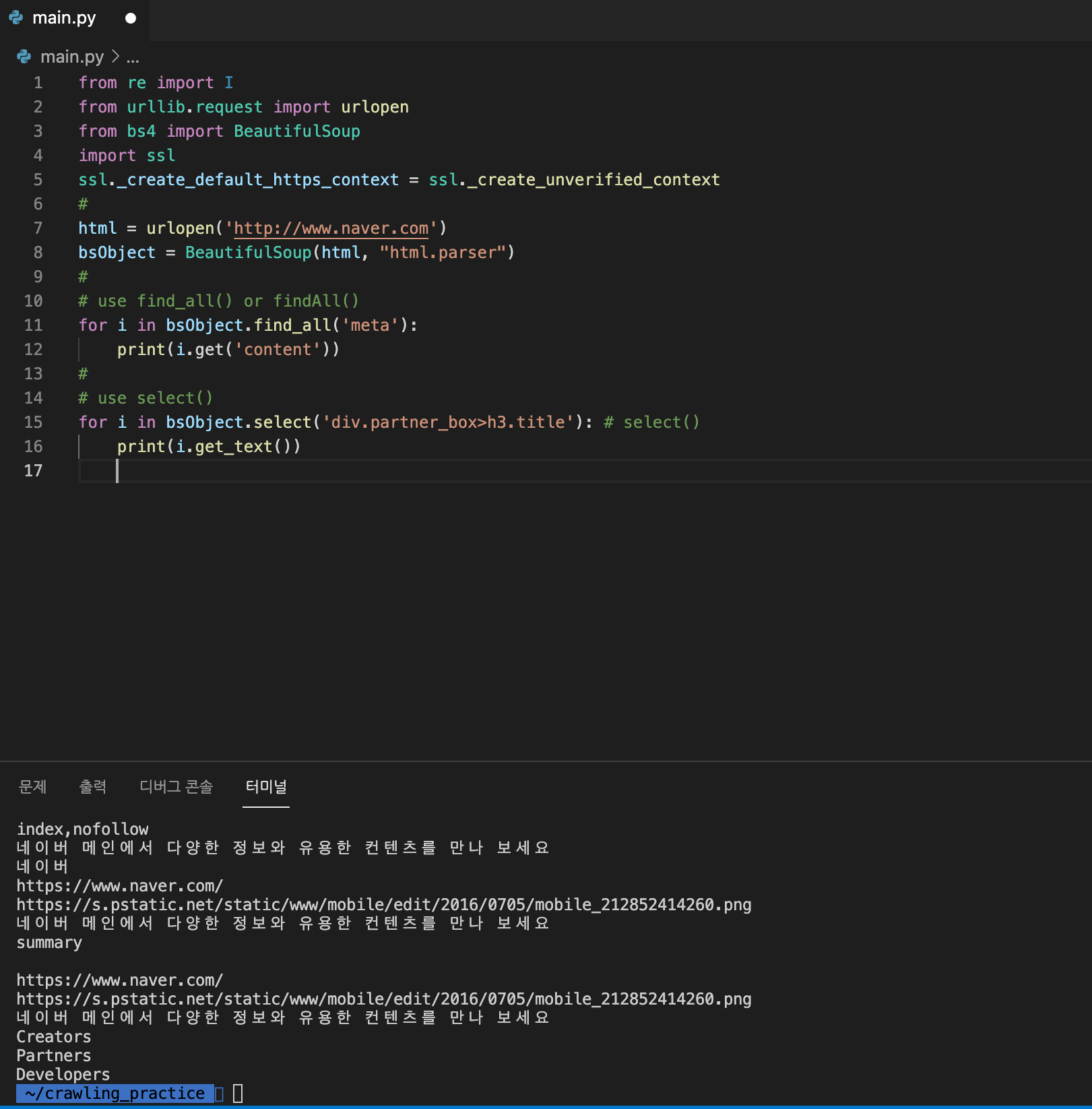
- meta tag의 content값 불러오기
for i in bsObject.find_all('meta'):
print(i.get('content'))
attribute로 불러오기
- 'class' : 'blind' 인 'span' 태그 불러오기
hList = bsObject.findAll('span', {'class':'blind'})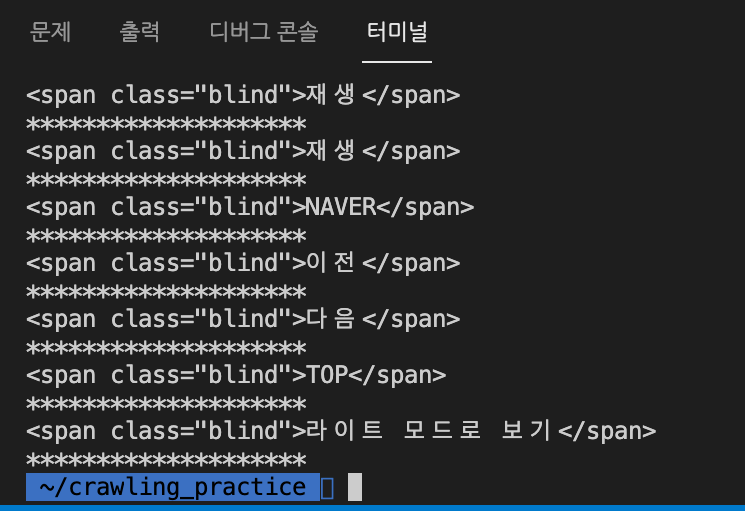
text 매개변수로 불러오기
hList = bsObject.findAll(text = '네이버')keyword 매개변수로 불러오기
hList = bsObject.findAll(id = 'text')
select()
tag 또는 class의 이름, 상하관계를 통해 원하는 데이터를 추출할 수 있다.
select('Tag')
# tag
select('.Class)
# class
select('#Id')
# id
select('tag[attribute]')
# tag - attributeselect('태그이름')
bsSelect = bsObject.select('a')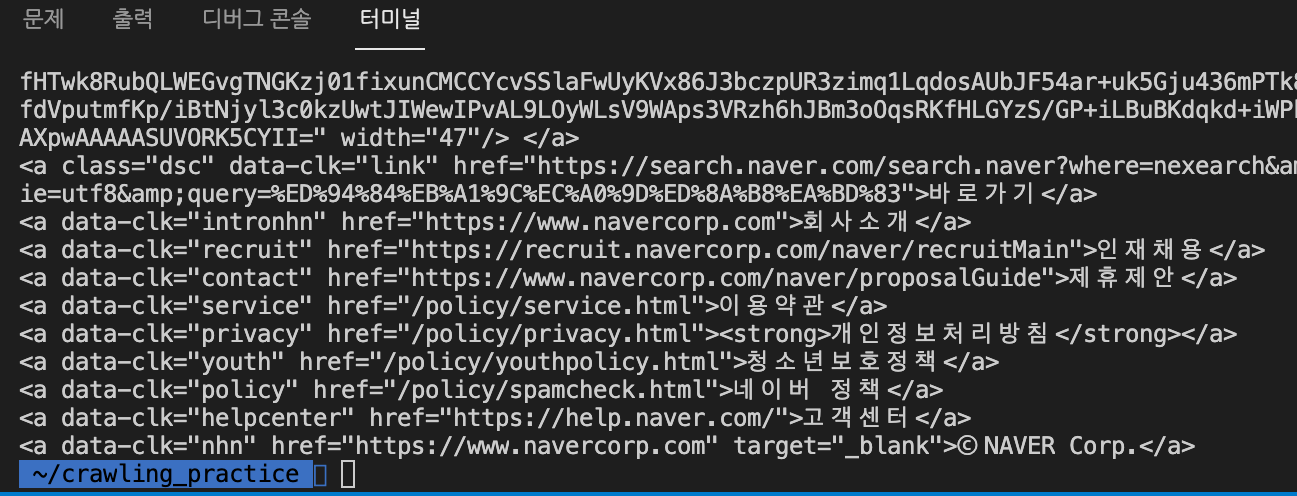
select('.클래스명')
bsSelect = bsObject.select('.content_top')
select('태그명[속성]')
bsSelect = bsObject.select('a[href]')
for i in bsSelect:
print(i.get('href'))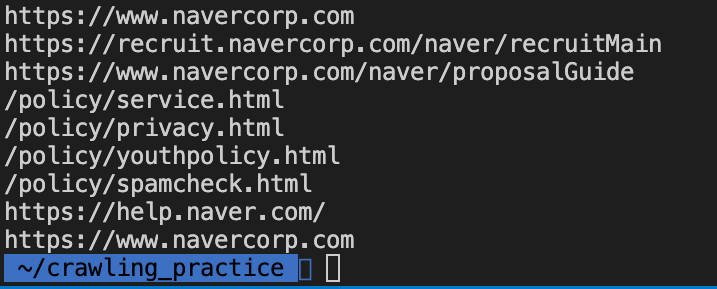
select('상위태그>하위태그')
bsSelect = bsObject.select('div>span') # 자식 관계select('상위태그 하위태그')
bsSelect = bsObject.select('div span') # 자손 관계중첩해서 사용하기
bsSelect = bsObject.select('div.partner_box>h3.title')
for i in bsSelect:
print(i.get_text())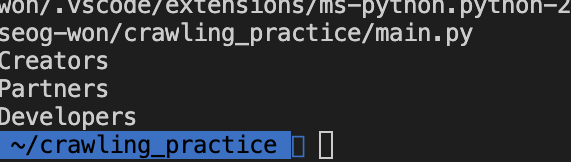
소스코드
from re import I
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
#
html = urlopen('http://www.naver.com')
bsObject = BeautifulSoup(html, "html.parser")
#
# use find_all() or findAll()
#
for i in bsObject.find_all('meta'):
print(i.get('content'))
#
# use select()
#
for i in bsObject.select('div.partner_box>h3.title'): # select()
print(i.get_text())참고한 블로그
https://webnautes.tistory.com/691?category=618796
https://computer-science-student.tistory.com/235
