Web Crawling으로 카카오 주식을 가져오기
카카오 주식 url : https://finance.naver.com/item/main.naver?code=035720
from urllib.request import urlopen from bs4 import BeautifulSoup import ssl ssl._create_default_https_context = ssl._create_unverified_context html = urlopen('https://finance.naver.com/item/main.naver?code=035720') # kakao url bsObject = BeautifulSoup(html, "html.parser") print(bsObject)
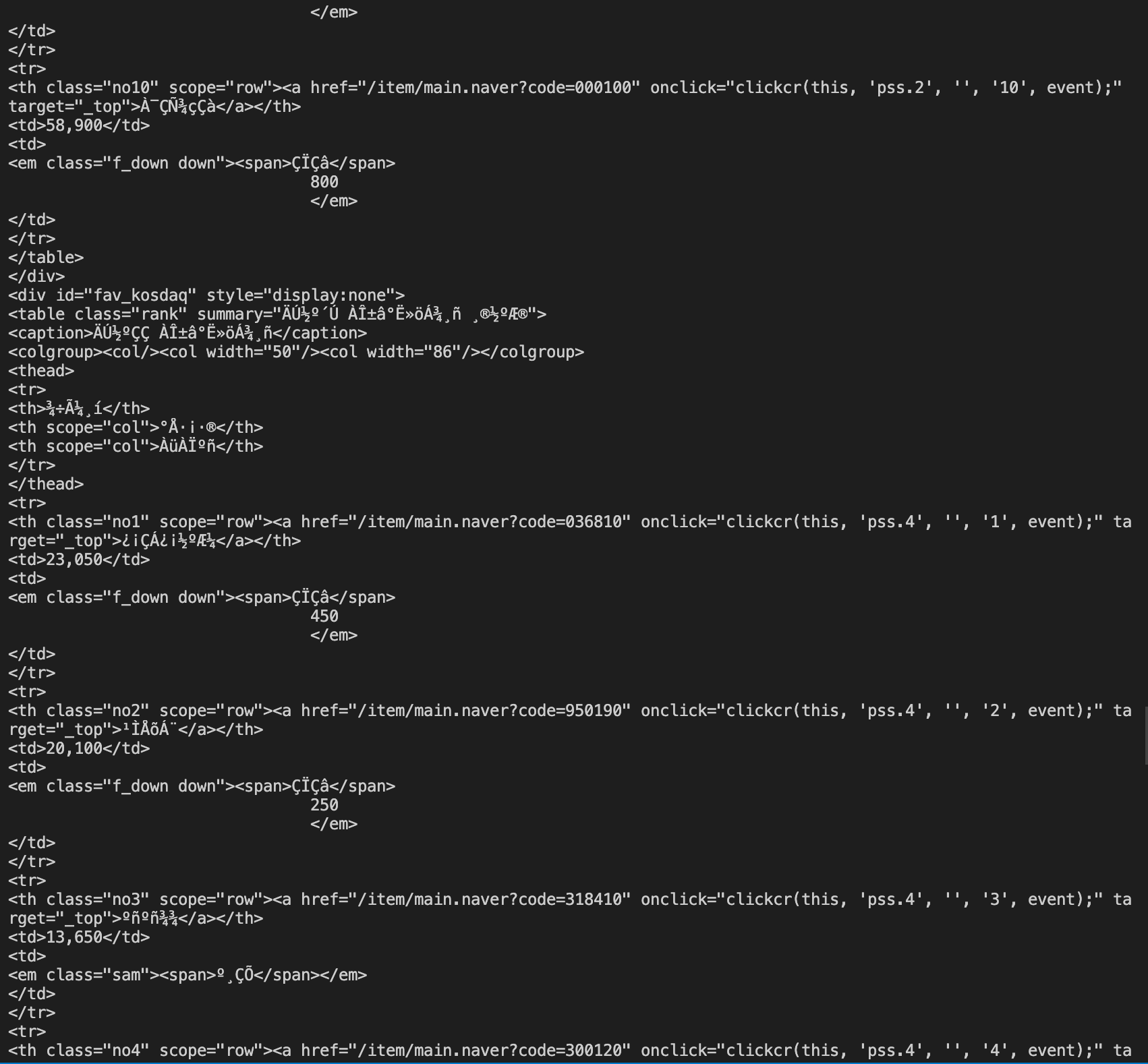
위와 같이 한글이 깨져서 보이는 문제가 생긴다!
한글 깨짐 문제 해결
urlopen이 아닌 requests.get으로 웹사이트를 불러오고 'euc-kr'로 디코딩하여 해결했다!
import requests from bs4 import BeautifulSoup req = requests.get('https://finance.naver.com/item/main.naver?code=035720') # kakao url html = req.content.decode('euc-kr', 'replace') bsObject = BeautifulSoup(html, "html.parser") print(bsObject)
가져올 데이터 찾기
가져오고 싶은 데이터는 현재가, 전일가, 고가, 저가 이렇게 4가지이다.
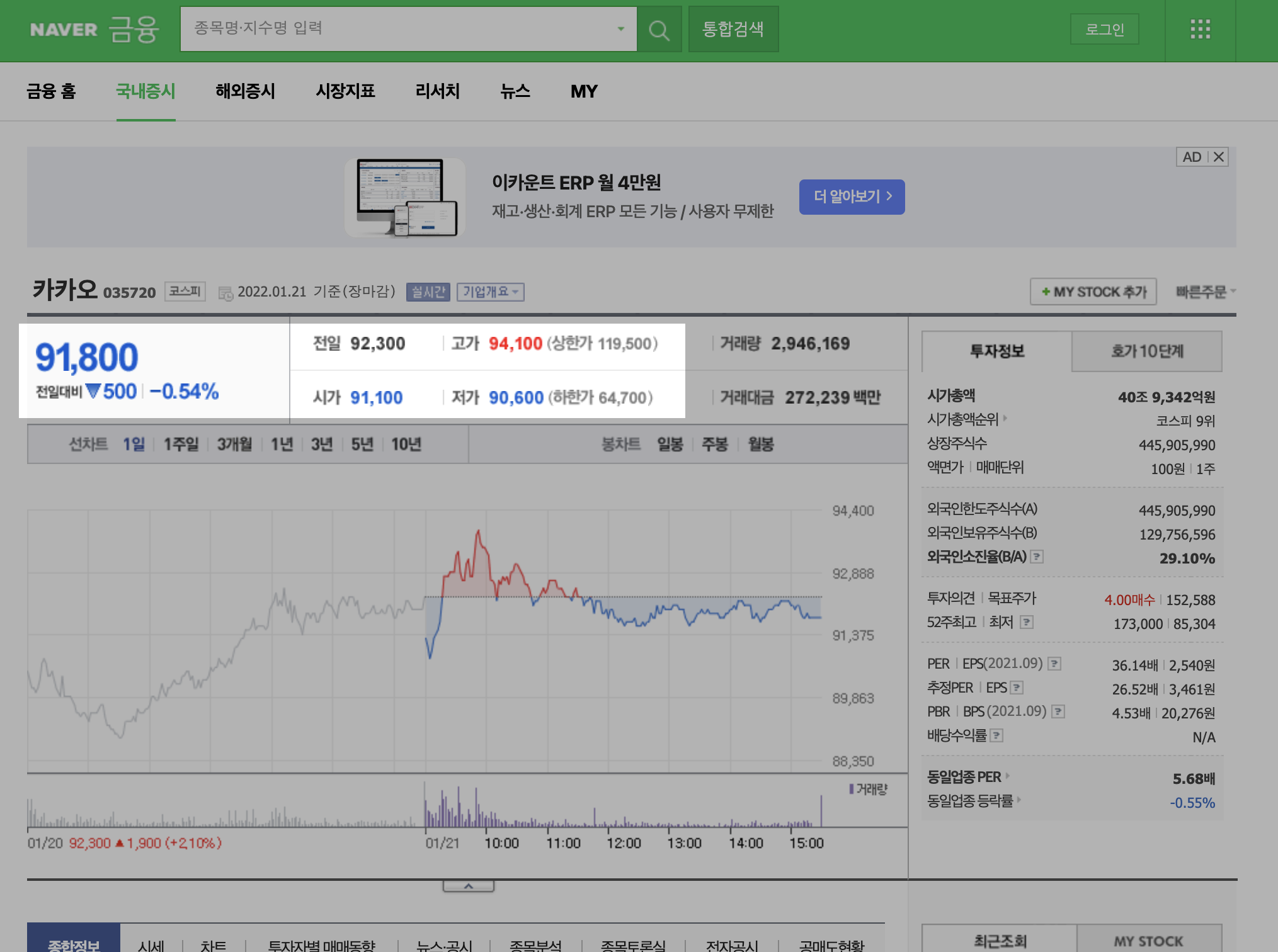
어떻게 데이터를 가져올 지 알아보기 위해, 홈페이지의 소스를 확인해보았다.
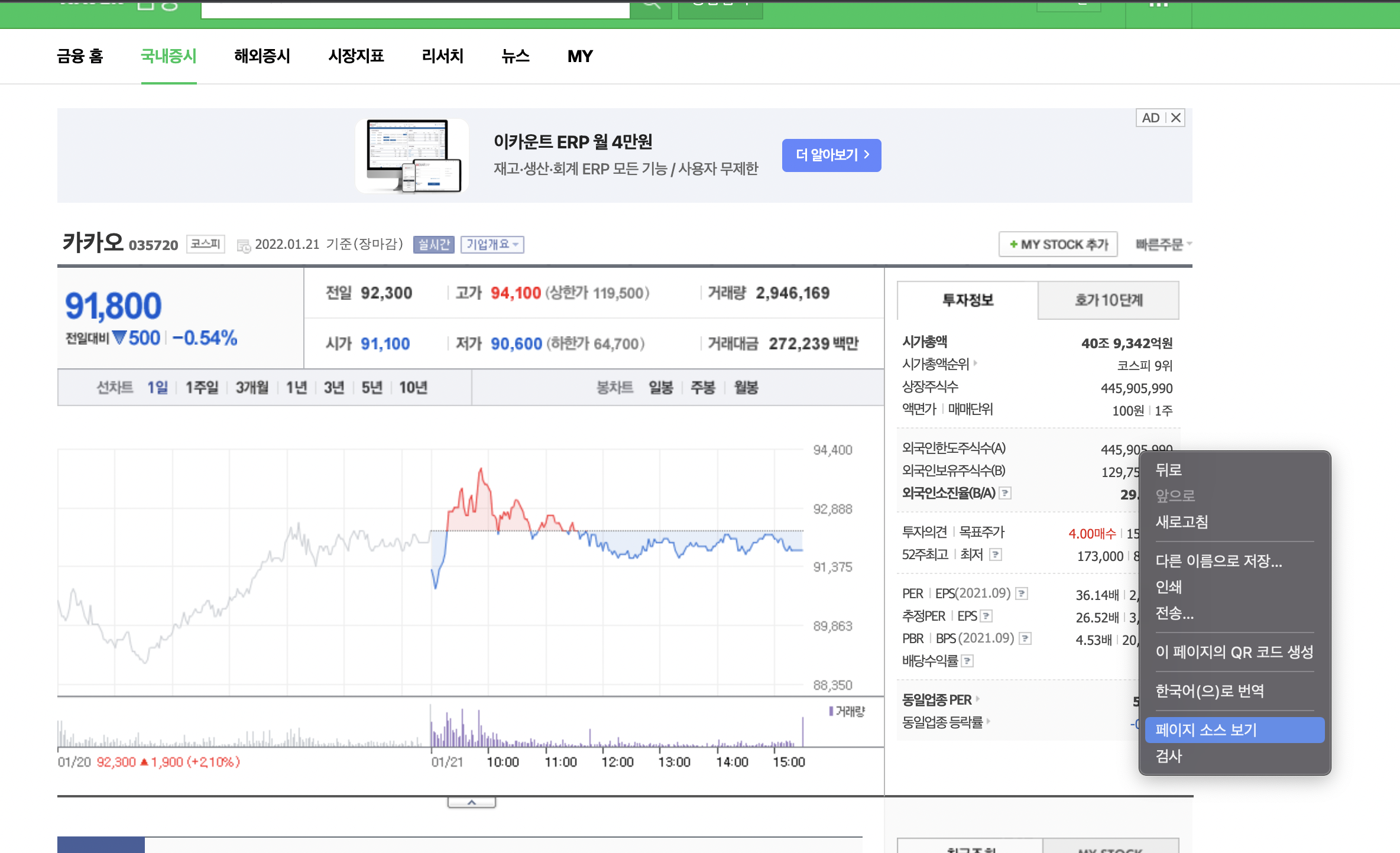
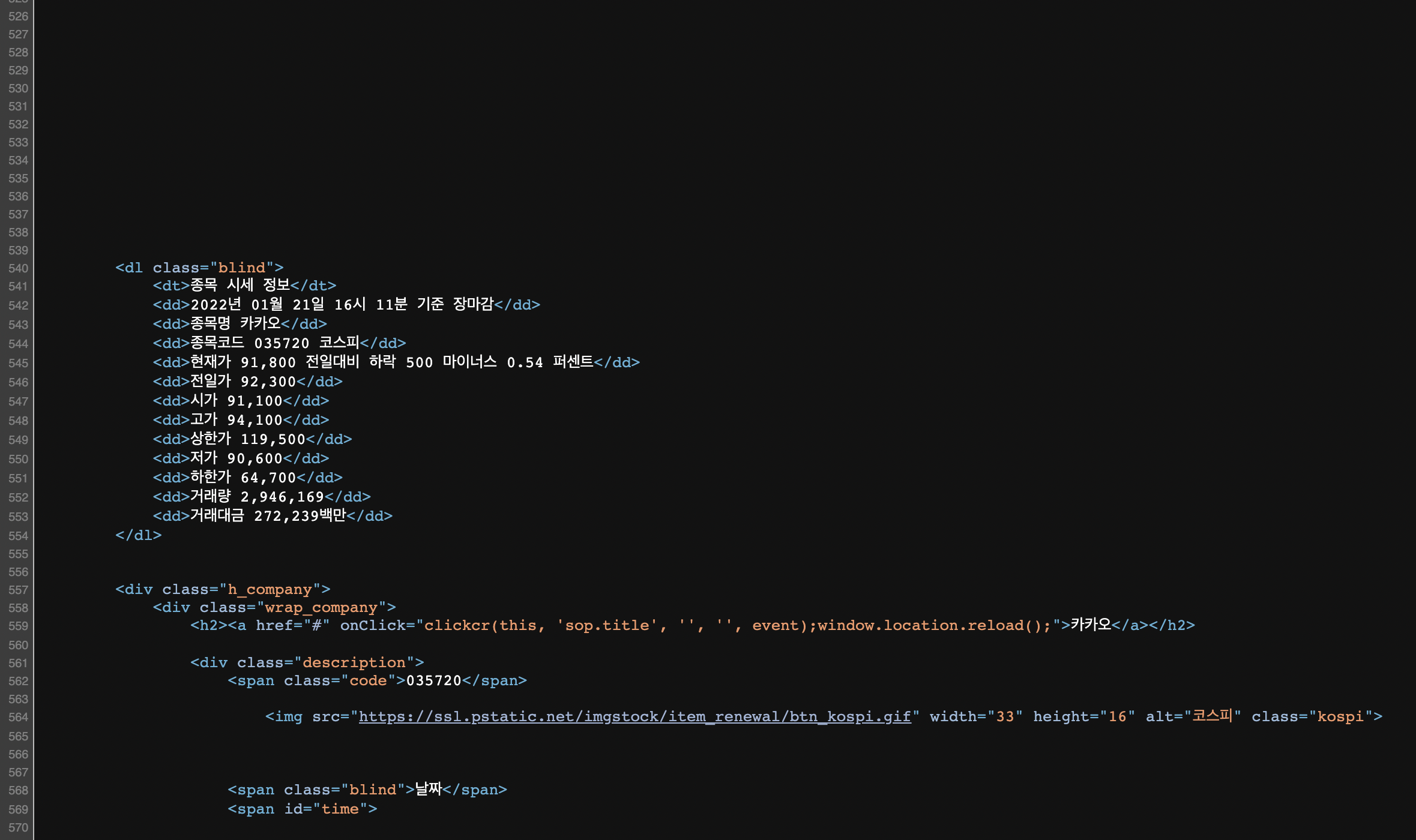
"페이지 소스 보기" 를 클릭하면 위와 같은 창이 뜨는데, 우리가 원하는 데이터는 dl.blind 아래에 있는 dd태그에 있다.
저번에 언급한 select함수를 이용하여 데이터를 불러와보자.
from shelve import BsdDbShelf
import requests
from bs4 import BeautifulSoup
req = requests.get(
'https://finance.naver.com/item/main.naver?code=035720') # kakao url
html = req.content.decode('euc-kr', 'replace')
bsObject = BeautifulSoup(html, "html.parser")
bsSelect = bsObject.select('dl.blind > dd')
print(bsSelect)
위와 같이 결과가 출력되는 것을 확인할 수 있다.
우리가 원하는 것은 현재가, 전일가, 시가, 고가 이므로
print("현재가", bsSelect[3].get_text().split(' ')[1])
print("전일가", bsSelect[4].get_text().split(' ')[1])
print("시가", bsSelect[5].get_text().split(' ')[1])
print("고가", bsSelect[6].get_text().split(' ')[1])위의 코드를 추가하여 결과를 확인해보자.
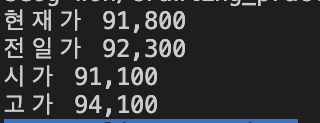
결과가 잘 출력되었다!
find_val = {"현재가", "전일가", "저가", "고가"}
for i in bsSelect:
if i.get_text().split(' ')[0] in find_val:
print(i.get_text())위와 같은 코드로 더 간단하게 출력할 수 있다.
소스 코드
from shelve import BsdDbShelf import requests from bs4 import BeautifulSoup req = requests.get( 'https://finance.naver.com/item/main.naver?code=035720') # kakao url html = req.content.decode('euc-kr', 'replace') bsObject = BeautifulSoup(html, "html.parser") bsSelect = bsObject.select('dl.blind > dd') find_val = {"현재가", "전일가", "저가", "고가"} for i in bsSelect: if i.get_text().split(' ')[0] in find_val: print(i.get_text())
