
Project Description
이번 프로젝트는 'BERT' 모델을 이용하여 입력된 한국어 대화 문장이 일상주제의 대화인지, 연애 관련 대화인지 이진 분류를 하는 모델을 만드는 것이었다. BERT는 800백만 개의 단어로 pre-training 되어 있고, fine-tuning이 쉽다는 점을 이용하여 사용하게 되었다(이전 글에 pre-training, fine-tuning에 대한 설명 있음!).
이전 글에서는 BERT를 이용한 이진 분류 모델을 만들기 전, BERT에 대한 이론적인 내용을 정리해보았다. BERT의 핵심적인 내용 위주로만 간략하게 정리를 해놨는데, 읽어두면 앞으로 살펴볼 코드에 대해 좀더 쉽게 이해할 수 있다!🤩
👉블로그👈에도 프로젝트 관련 글을 작성해놓았는데, 프로젝트다운 글이다..ㅎ(가볍게 읽을 수 있는 프로젝트 글이고, 깊게 알고 싶다면 여기 velog 이론편/코딩편 글을 읽는게 좋다. 아마도ㅎ)
코드는 구글에서 GPU를 사용하여 작성되었고, bert_naver_movie_colab.ipynb를 참조하였다. 참조한 코드는 네이버 영화평을 BERT로 이진분류하는 모델을 만드는 코드인데, 약간의 주석과 설명이 포함되어 있어서 코드만 봐도 어느정도 이해가 된다. 아무튼 이 코드에서 데이터셋을 바꾸고, 전처리 부분과 테스트 부분을 추가해(모델 학습 코드는 동일) 프로젝트에 맞는 코드를 작성하였다. (그럴 일이 있겠나 싶겠지만 코드를 복붙하고자 한다면 일일이 복붙하지 말고 깃허브(관리x)에 있는 ipynb 파일을 다운!)
이제 코드를 살펴보도록 하겠다.
(중요하지 않은 부분은 설명 생략!)
1.Colab 환경 설정
먼저, GPU를 사용하기 위해 시스템 환경 유형 변경을 통해 GPU로 변경해주고, 아래 코드를 입력하여 라이브러리를 설치하고 import 해준다.
!pip install transformersimport tensorflow as tf
import torch
from transformers import BertTokenizer
from transformers import BertForSequenceClassification, AdamW, BertConfig
from transformers import get_linear_schedule_with_warmup
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import random
import time
import datetime라이브러리 하는 모듈들을 보면, 이전 글에서 설명한 Bert의 Tokenizer(WordPiece), BertForSequenceClassification 등이 있는 것을 확인할 수 있다.
n_devices = torch.cuda.device_count()
print(n_devices)
for i in range(n_devices):
print(torch.cuda.get_device_name(i))이 코드는 GPU가 맞게 설정됐는지 확인하는 코드이다. 맞게 설정되었다면 'Tesla T4' 라고 출력될 것이다.
2.데이터셋 불러오기
(1)학습데이터 불러오기
일상대화/연애대화를 분류하는 모델을 만들기 위해선, pretrain 되어 있는 BERT에 추가로 일상대화/연애대화 데이터를 학습시켜주어야 한다. 따라서 데이터를 불러오고, 입력으로 들어가기 위한 전처리가 필요하다.
한편, 추가로 학습시킬 데이터는 이전 글에서도 설명했지만 깃허브에서 가져온 Chatbot data이다. 이 데이터는 11,876개의 한글 대화 문답으로 되어 있는 인공데이터로, 일상 대화, 이별과 관련된 대화, 긍정적인 사랑에 대한 대화가 각각 0, 1, 2로 라벨링 되어 있다. 이제 이 데이터를 깃허브에서 다운로드 한 뒤, 구글 드라이브를 연동하는 방식으로 데이터를 가져왔다.
from google.colab import drive
drive.mount('/content/drive')를 입력하세요구글 드라이브 연동 방법은 위 코드를 수행하면 링크가 뜨는데, 링크에 들어가서 '허용'버튼을 누르고 길게 출력되는 문자열을 복사한 뒤 코드 출력창에 뜬 입력창에 복붙해주기만 하면 된다. 그러면 내 계정의 구글 드라이브와 연동이 된다.
import csv
import pandas as pd
# 데이터프레임으로 변환
# 본인 경로에 맞게 수정
chatbot_data = pd.read_csv('/content/drive/MyDrive/챗봇/ChatbotData.csv',encoding="utf-8")chatbot_data.shape(11823,3) 이라고 출력되면 잘 불러온 것이다.
그렇다면 데이터가 어떻게 이루어졌는지 5개의 행을 살펴보자.
chatbot_data.sample(n=5)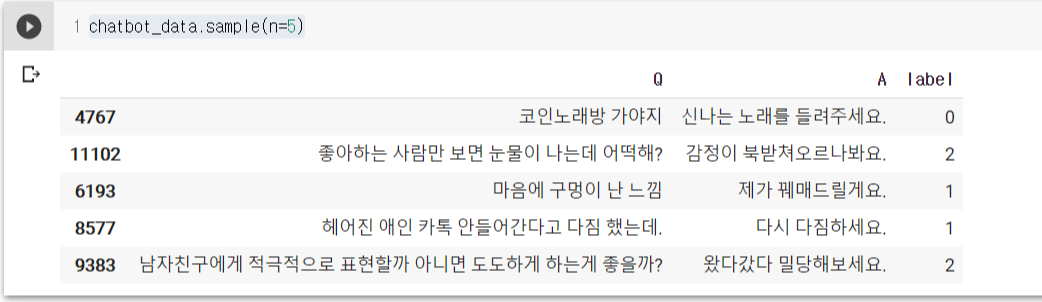
랜덤으로 5개의 행을 출력한 결과, 위와 같이 'Q'라는 컬럼에 있는 한글 질의에 대해 'A' 컬럼에 답변 데이터가 있고, 'label' 컬럼에 해당 질의에 대해 일상 대화인지, 연애 관련 대화 중 이별(부정)에 관한 대화인지, 사랑(긍정)에 관한 대화인지 라벨링 되어 있음을 확인할 수 있다.
현재 3개의 클래스로 라벨링 되어 있는데, 이번 프로젝트에서는 일상대화인지 연애 관련 대화인지 이진분류를 할 것이기 때문에 '1'과 '2'로 라벨링 되어 있는 데이터를 모두 '1'로 바꿔주어야 한다. 따라서 아래 코드를 실행해주자.
chatbot_data.loc[(chatbot_data['label'] == 2), 'label'] = 1 #라벨 1과 2는 모두 1로 통일(2)Train set / Test set으로 나누기
데이터를 Train set과 Test set으로 나누기 전, 데이터를 확인해보면 알겠지만 0~5290 까지의 행이 모두 클래스가 '0'인 행이고, 5291행부터 마지막 행까지 모두 클래스가 '1'이다. 특정 비율로 데이터셋을 나눌 때, 클래스가 '0'인 데이터와 '1'인 데이터가 골고루 들어가기 위해선 데이터를 랜덤으로 섞어주고 나눠야 한다. 따라서 다음과 같이 코드를 입력해준다.
chatbot_data_shuffled = chatbot_data.sample(frac=1).reset_index(drop=True)데이터를 섞었다면 train data와 test data의 비율을 설정해주어야 하는데, 11823개의 데이터에서 9000개는 train data로, 나머지 2823개의 데이터는 test data로 간단하게 나눠주도록 하겠다. 추후에 train data는 또 한번 train data와 validation data로 나누게 된다.
#train data & test data 로드
train = chatbot_data_shuffled[:9000]
test = chatbot_data_shuffled[9000:]3.Train set 전처리
여기서부터 지금까지 전처리한 dataset이 BERT 모델의 입력데이터가 되기 위한 특수한 전처리가 필요하다.
(1) [CLS]와 [SEP]
BERT 분류 모델의 경우 각 문장의 앞마다 [CLS]를 붙여 인식시키고, 문장의 종료는 [SEP]를 붙여 인식시킨다. [CLS]을 인식함으로써 문장의 처음이라 알 수 있게 하고, [SEP]을 인식함으로써 문장의 끝을 알 수 있게 하기 위함이다. 이전 글에서 BERT의 pretrain 방법 중 하나가 [SEP]를 인식하여 두 문장이 이어지는 문장인지, 관련 없는 문장인지 학습하는 것이었다. 아무튼 추가한 데이터 역시 학습을 해야하니 각 문장마다 [CLS]와 [SEP]를 붙여주어야 한다.
# CLS, SEP 붙이기 (문장의 시작, 끝)
sentences = ["[CLS] " + str(s) + " [SEP]" for s in train.Q]5개의 데이터를 출력해서 잘 붙여졌는지 확인해보자.
sentences[:5]
#output
>>['[CLS] 파도가 엄청 세 [SEP]',
'[CLS] 코딩 좀 배울까 [SEP]',
'[CLS] 오늘부로 짝녀를 보내기로 했어요. [SEP]',
'[CLS] 진짜 이해가 안가 근데 잊을려고 [SEP]',
'[CLS] 청소는 넘나리 귀찮 [SEP]']한편, '0'과 '1'의 라벨이 들어있는 컬럼을 'labels'이라는 array에 따로 저장한다.
labels = train['label'].values
#labels >> array([0, 0, 1, ..., 0, 1, 0])(2)서브워드 토크나이저 : WordPiece
BERT에서 사용하는 토크나이저인 WordPiece에 대해 지난번 글에서 설명했다. 단어를 토큰화 할 때, 단어집합에 없는 단어는 더 쪼개서 '##'을 붙여주는 방식이었다. BertTokenizer 라이브러리를 통해 이를 수행할 수 있는데, '안녕하세요'라는 문장에 대해 적용해보았다.
import pandas as pd
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased", do_lower_case=False)
result = tokenizer.tokenize('안녕하세요')
print(result)>> ['안', '##녕', '##하', '##세', '##요']현재 단어 집합이 비어있는 상태이므로 '안녕하세요'라는 단어가 단어집합에 없다. 따라서 이 단어는 한번 더 쪼개어 지는데 '##'을 붙임으로써 '##녕', '##하', '##세', '##요' 가 어떠한 단어의 서브워드라는 것을 나타내준다. 이렇게 나타내 줌으로써 단어의 의미를 잃지 않고 다시 원래 단어로 복원을 할 수 있게 된다.
그렇다면 이제 WordPiece 토크나이저를 이용하여 전체 데이터에 토크나이징을 수행하도록 한다. 토크나이징을 하는 코드는 간단하다.
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False)
tokenized_texts = [tokenizer.tokenize(s) for s in sentences]한번 토크나이징이 잘 되었는지 확인해보자.
print(sentences[0]) #토크나이징 전
print(tokenized_texts[0]) #토크나이징 후>> [CLS] 파도가 엄청 세 [SEP]
>> ['[CLS]', '파', '##도가', '엄', '##청', '세', '[SEP]']이 이후에, 문장의 최대 시퀀스를 설정하여 정수 인코딩과 제로 패딩을 수행해준다.
MAX_LEN = 128 #최대 시퀀스 길이 설정
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")이렇게 코드를 다 실행했다면 input_ids[0]에 대해 다음과 같이 출력될 것이다.
array([ 101, 9901, 68516, 9553, 40311, 9435, 102, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0])(3) Attention Mask (어텐션 마스크)
어텐션 마스크에 대해선 이전 글에서 설명을 하지 않았는데, 어텐션 마스크란 0 값을 가지는 패딩 토큰에 대해서 어텐션 연산을 불필요하게 수행하지 않도록 단어와 패딩 토큰을 구분할 수 있게 알려주는 것을 말한다. 따라서 [40311, 9435, 102, 0, 0]와 같은 패딩된 데이터가 있을 때, 패딩된 값은 '0', 패딩되지 않은 단어는 '1'의 값을 갖도록 시리얼 데이터를 만들어 주어야 한다.
예) 패딩된 데이터 = [40311, 9435, 102, 0, 0]
>>어텐션 마스크 = [1.0, 1.0, 1.0, 0.0, 0.0]
attention_masks = []
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)어텐션 마스크가 잘 생성되었는지 print(attention_masks[0])를 입력하고 실행해보자.
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
(4)Train set을 훈련셋과 검증셋으로 분리하기
데이터가 입력의 형태를 갖췄다면 훈련셋과 검증셋으로 분리해주도록 한다. 어텐션 마스크도 함께 훈련셋과 검증셋으로 분리하고, 데이터를 모두 파이토치 텐서로 변환시킨다.
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids,
labels,
random_state=2000,
test_size=0.1)
train_masks, validation_masks, _, _ = train_test_split(attention_masks,
input_ids,
random_state=2000,
test_size=0.1)
train_inputs = torch.tensor(train_inputs)
train_labels = torch.tensor(train_labels)
train_masks = torch.tensor(train_masks)
validation_inputs = torch.tensor(validation_inputs)
validation_labels = torch.tensor(validation_labels)
validation_masks = torch.tensor(validation_masks) 마지막으로 배치사이즈를 32로 설정하고, 입력데이터, 어텐션 마스크, 라벨을 하나의 데이터로 묶어 train_dataloader, validation_dataloader라는 입력데이터를 생성해준다.
batch_size = 32
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)4.Test set 전처리
Train set을 전처리 한 것과 같은 방식으로 Test set에도 같은 과정을 수행한다.
# [CLS] + 문장 + [SEP]
sentences = ["[CLS] " + str(sentence) + " [SEP]" for sentence in sentences]
# 라벨 데이터
labels = test['label'].values
# Word 토크나이저 토큰화
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False)
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
# 시퀀스 설정 및 정수 인덱스 변환 & 패딩
MAX_LEN = 128
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
# 어텐션 마스크
attention_masks = []
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
# 파이토치 텐서로 변환
test_inputs = torch.tensor(input_ids)
test_labels = torch.tensor(labels)
test_masks = torch.tensor(attention_masks)
# 배치 사이즈 설정 및 데이터 설정
batch_size = 32
test_data = TensorDataset(test_inputs, test_masks, test_labels)
test_sampler = RandomSampler(test_data)
test_dataloader = DataLoader(test_data, sampler=test_sampler, batch_size=batch_size)5.BERT 모델 불러오기
이제 BERT 모델을 불러오도록 한다.(여기서부터는 참조한 코드와 동일하다.)
그 전에 GPU 설정을 위한 디바이스 설정을 해준다.
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print('No GPU available, using the CPU instead.')위 코드를 실행하고 'There are 1 GPU(s) available.' 라는 문구가 출력되면 사용이 가능하다는 뜻이다.
이제 pretrain된 BERT 모델을 불러오도록 하겠다.
model = BertForSequenceClassification.from_pretrained("bert-base-multilingual-cased", num_labels=2)
model.cuda()한편, 하이퍼 파라미터를 설정해주어야 하는데, 파라미터 값은 참조한 코드에 있는 값 그대로 설정했다. 에폭 수는 간단하게 4로 설정해주었다.
# 옵티마이저
optimizer = AdamW(model.parameters(),
lr = 2e-5, # 학습률(learning rate)
eps = 1e-8
)
# 에폭수
epochs = 4
# 총 훈련 스텝 : 배치반복 횟수 * 에폭
total_steps = len(train_dataloader) * epochs
# 스케줄러 생성
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)6.모델 학습
# 정확도 계산 함수
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
# 시간 표시 함수
def format_time(elapsed):
# 반올림
elapsed_rounded = int(round((elapsed)))
# hh:mm:ss으로 형태 변경
return str(datetime.timedelta(seconds=elapsed_rounded))필요한 함수를 설정해주고 난 뒤, 아래 코드를 실행하여 모델을 학습시켜준다.
#랜덤시드 고정
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
#그래디언트 초기화
model.zero_grad()
# 학습
for epoch_i in range(0, epochs):
# ========================================
# Training
# ========================================
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
# 시작 시간 설정
t0 = time.time()
# 로스 초기화
total_loss = 0
# 훈련모드로 변경
model.train()
# 데이터로더에서 배치만큼 반복하여 가져옴
for step, batch in enumerate(train_dataloader):
# 경과 정보 표시
if step % 500 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 배치를 GPU에 넣음
batch = tuple(t.to(device) for t in batch)
# 배치에서 데이터 추출
b_input_ids, b_input_mask, b_labels = batch
# Forward 수행
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# 로스 구함
loss = outputs[0]
# 총 로스 계산
total_loss += loss.item()
# Backward 수행으로 그래디언트 계산
loss.backward()
# 그래디언트 클리핑
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 그래디언트를 통해 가중치 파라미터 업데이트
optimizer.step()
# 스케줄러로 학습률 감소
scheduler.step()
# 그래디언트 초기화
model.zero_grad()
# 평균 로스 계산
avg_train_loss = total_loss / len(train_dataloader)
print("")
print(" Average training loss: {0:.2f}".format(avg_train_loss))
print(" Training epcoh took: {:}".format(format_time(time.time() - t0)))
# ========================================
# Validation
# ========================================
print("")
print("Running Validation...")
#시작 시간 설정
t0 = time.time()
# 평가모드로 변경
model.eval()
# 변수 초기화
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# 데이터로더에서 배치만큼 반복하여 가져옴
for batch in validation_dataloader:
# 배치를 GPU에 넣음
batch = tuple(t.to(device) for t in batch)
# 배치에서 데이터 추출
b_input_ids, b_input_mask, b_labels = batch
# 그래디언트 계산 안함
with torch.no_grad():
# Forward 수행
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
# 로스 구함
logits = outputs[0]
# CPU로 데이터 이동
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 출력 로짓과 라벨을 비교하여 정확도 계산
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print(" Accuracy: {0:.2f}".format(eval_accuracy/nb_eval_steps))
print(" Validation took: {:}".format(format_time(time.time() - t0)))
print("")
print("Training complete!")약 9,000개의 데이터를 추가 학습시키는데 약 15분이 걸렸다!
출력되는 값들은 다음과 같다.
======== Epoch 1 / 4 ========
Training...
Average training loss: 0.44
Training epcoh took: 0:02:48
Running Validation...
Accuracy: 0.85
Validation took: 0:00:07
======== Epoch 2 / 4 ========
Training...
Average training loss: 0.31
Training epcoh took: 0:03:04
Running Validation...
Accuracy: 0.87
Validation took: 0:00:07
======== Epoch 3 / 4 ========
Training...
Average training loss: 0.22
Training epcoh took: 0:03:05
Running Validation...
Accuracy: 0.88
Validation took: 0:00:07
======== Epoch 4 / 4 ========
Training...
Average training loss: 0.17
Training epcoh took: 0:03:06
Running Validation...
Accuracy: 0.88
Validation took: 0:00:07
Training complete!마지막 4번째 에폭에서 출력된 Validation set의 정확도를 보면 0.88이 나온걸로 봐서 정확도가 꽤 높게 나온 것을 확인할 수 있다. 하이퍼 파라미터를 재조정하고 에폭 수를 증가시키면 정확도가 조금 더 높게 나올 수 있지 않을까 싶다.
7.테스트셋 평가
지금까지 pretrain된 BERT 모델에 추가로 9000개의 한글 대화 데이터를 추가로 학습시켰다. 이제 테스트 셋 데이터로 학습시킨 모델의 정확도를 측정해보도록 하겠다.
#시작 시간 설정
t0 = time.time()
# 평가모드로 변경
model.eval()
# 변수 초기화
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# 데이터로더에서 배치만큼 반복하여 가져옴
for step, batch in enumerate(test_dataloader):
# 경과 정보 표시
if step % 100 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(test_dataloader), elapsed))
# 배치를 GPU에 넣음
batch = tuple(t.to(device) for t in batch)
# 배치에서 데이터 추출
b_input_ids, b_input_mask, b_labels = batch
# 그래디언트 계산 안함
with torch.no_grad():
# Forward 수행
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
# 로스 구함
logits = outputs[0]
# CPU로 데이터 이동
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 출력 로짓과 라벨을 비교하여 정확도 계산
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("")
print("Accuracy: {0:.2f}".format(eval_accuracy/nb_eval_steps))
print("Test took: {:}".format(format_time(time.time() - t0)))>> Accuracy: 0.87
>> Test took: 0:00:19그 결과, 0.87의 정확도가 측정되었다. Train set에 대한 정확도도 0.88이 나왔으니 데이터셋이 골고루 잘 학습되었음을 확인할 수 있다.
8.새로운 문장 테스트
이제 새로운 문장을 입력하여 분류가 잘 이루어 지는지 살펴보도록 하자!
입력하는 문장도 BERT의 입력 형태로 만드는 작업이 필요하기 때문에 우선 아래 코드를 실행해준다.
# 입력 데이터 변환
def convert_input_data(sentences):
# BERT의 토크나이저로 문장을 토큰으로 분리
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
# 입력 토큰의 최대 시퀀스 길이
MAX_LEN = 128
# 토큰을 숫자 인덱스로 변환
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
# 문장을 MAX_LEN 길이에 맞게 자르고, 모자란 부분을 패딩 0으로 채움
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
# 어텐션 마스크 초기화
attention_masks = []
# 어텐션 마스크를 패딩이 아니면 1, 패딩이면 0으로 설정
# 패딩 부분은 BERT 모델에서 어텐션을 수행하지 않아 속도 향상
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
# 데이터를 파이토치의 텐서로 변환
inputs = torch.tensor(input_ids)
masks = torch.tensor(attention_masks)
return inputs, masks# 문장 테스트
def test_sentences(sentences):
# 평가모드로 변경
model.eval()
# 문장을 입력 데이터로 변환
inputs, masks = convert_input_data(sentences)
# 데이터를 GPU에 넣음
b_input_ids = inputs.to(device)
b_input_mask = masks.to(device)
# 그래디언트 계산 안함
with torch.no_grad():
# Forward 수행
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
# 로스 구함
logits = outputs[0]
# CPU로 데이터 이동
logits = logits.detach().cpu().numpy()
return logits이제 새로운 문장을 입력할 준비가 끝났다. 먼저 기존 데이터셋에 있는 일상대화 문장을 입력해 보도록 하겠다.
logits = test_sentences(['더 나은 학교생활 하고 싶어'])
print(logits)
if np.argmax(logits) == 1 :
print("연애 관련 대화")
elif np.argmax(logits) == 0 :
print("일상 대화")'더 나은 학교생활 하고 싶어'라는 문장을 입력하니, 다음과 같이 '일상 대화'로 예측되었다.
>> [[ 2.241536 -2.6760721]]
>> 일상 대화반면, 새로운 문장으로 '저녁 뭘 먹을지 추천해줘' 라고 입력해보았다.
logits = test_sentences(['저녁 뭘 먹을지 추천해줘'])
print(logits)
if np.argmax(logits) == 1 :
print("연애 관련 대화")
elif np.argmax(logits) == 0 :
print("일상 대화")
>> [[ 0.62954295 -0.69384205]]
>> 일상 대화해당 문장에 대해 '일상 대화'라고 잘 예측되었다.
이번엔 연애 관련 문장을 입력해보았다.
logits = test_sentences(['여자친구한테 선물 뭘로 줄까?'])
print(logits)
if np.argmax(logits) == 1 :
print("연애 관련 대화")
elif np.argmax(logits) == 0 :
print("일상 대화")
>> [[-2.0409577 2.6851814]]
>> 연애 관련 대화이번에도 연애 관련 대화라고 잘 예측되었다. 근데 이렇게 잘 예측하나 싶었지만 위 문장에서 '여자친구'를 '엄마'라고 바꾼 '엄마한테 선물 뭘로 줄까?'를 입력해보니 똑같이 연애 관련 대화로 예측되었다. 학습한 모델이 '선물', '줄까' 이런 단어에 점수를 높게 두었는지 '엄마'라는 단어가 들어가도 연애 관련 대화로 예측되었다.
그 밖에도 추가로 여러 문장을 입력하고 결과를 확인했는데, 연애와 관련된 단어가 확실히 들어가 있는 문장은 잘 예측한 반면, 애매한 뉘앙스의 문장은 정확도가 떨어지는 것 같았다. 특히 문장을 길게 쓸수록 정확도가 높아지는 것 같았다. 아무래도 판별할 것들이 많을수록 잘 예측하나 싶다.
Result
한국어 대화 데이터셋을 불러와 전처리를 한 뒤 pretrain 되어 있는 BERT 모델에 추가로 학습한 후 예측까지, 전 과정을 수행해보았다. 머신러닝, 딥러닝을 배울 때 기본적으로 배우는 CNN, RNN, LSTM 등과는 다르게 어텐션이라는 방식을 통해서 자연어 학습을 하는 것이 새롭기도 하고, 또 큰 차이의 성능을 보여주는 것 같다. 특히 BERT 모델이 이미 pretrain 되어 있어서 output layer만 바꾸어서 파인튜닝을 해주면 원하는 용도에 맞게 사용할 수 있다는 점이 가장 큰 장점인 것 같다.
학습 및 예측 결과에 대해서는 나름대로 만족하는데, 데이터셋이 작고, epoch 수를 낮게 설정했지만 그에 비해서는 정확도가 높게 측정된 것 같다. 만약 배치 사이즈, learning rate, epoch 등 하이퍼 파라미터 값들을 변경해가면서 학습을 시켜보면 정확도가 90%까지도 나올 수 있지 않을까 싶다.
이렇게 BERT를 이용하여 기본적인 이진 분류 모델을 만들어보았는데, 사실 KOBERT라는 것이 있다. KOBERT에서 KO는 Korean을 뜻한다. 즉, 한국어 버전의 BERT 모델인데, KOBERT는 약 8000개 한국어 단어가 있는 집합을 사용하기 때문에 한국어 데이터에 대해서 높은 정확도를 보인다고 한다. 따라서 다음 글에서는 KOBERT를 이용하여 한국어 대화를 7개의 클래스로 다중분류 하는 모델을 만들었던 프로젝트에 대해 글을 작성하도록 하겠다😆
REFERENCE

4개의 댓글


궁금한게 있습니다.
테스트 데이터 중 Q만 학습하고, A는 학습하지 않는 이유가 따로 있는건가요?
혹은 제가 잘못 알고 있는걸까요...?
학습 시킬때 여러 개의 열을 입력하고 싶거든요. 그렇게 하는 방법이 있을까요?
"sentences = ["[CLS] " + str(s) + " [SEP]" for s in train.Q]"
글 정말 잘 봤습니다
많은 참고가 되었는데 실행 코드 돌리는 중에 4.test set 전처리 부분에 실행 문제가 있어 문의드리고 자 합니다
test_data = TensorDataset(test_inputs, test_masks, test_labels)
에서 AssertionError: Size mismatch between tensors 에러가 발생하네요 ㅠㅠ