✔️ 서울시 범죄 현황 데이터 분석 5~6
⭐ folium
- folium 모듈 설치
!pip install folium
※ windows 사용자 중 위 방법으로 설치가 안되는 경우
!pip install charset
!pip install charset-normalizer
import folium
import pandas as pd
import json
- folium.Map()
- 속성 : location: tuple or list, default None
Latitude and Longitude of Map (Northing, Easting).
m = folium.Map(location=[37.544577, 127.055991], zoom_start=14) #0 - 18 m
→ 성수역 좌표를 입력한 결과
- save("path") : 성수역 좌표를 입력한 지도를 html 형식 파일로 저장
m.save('./folium.html')
m = folium.Map( location=[37.544577, 127.055991], zoom_start=14, tiles='Stamen Toner' ) m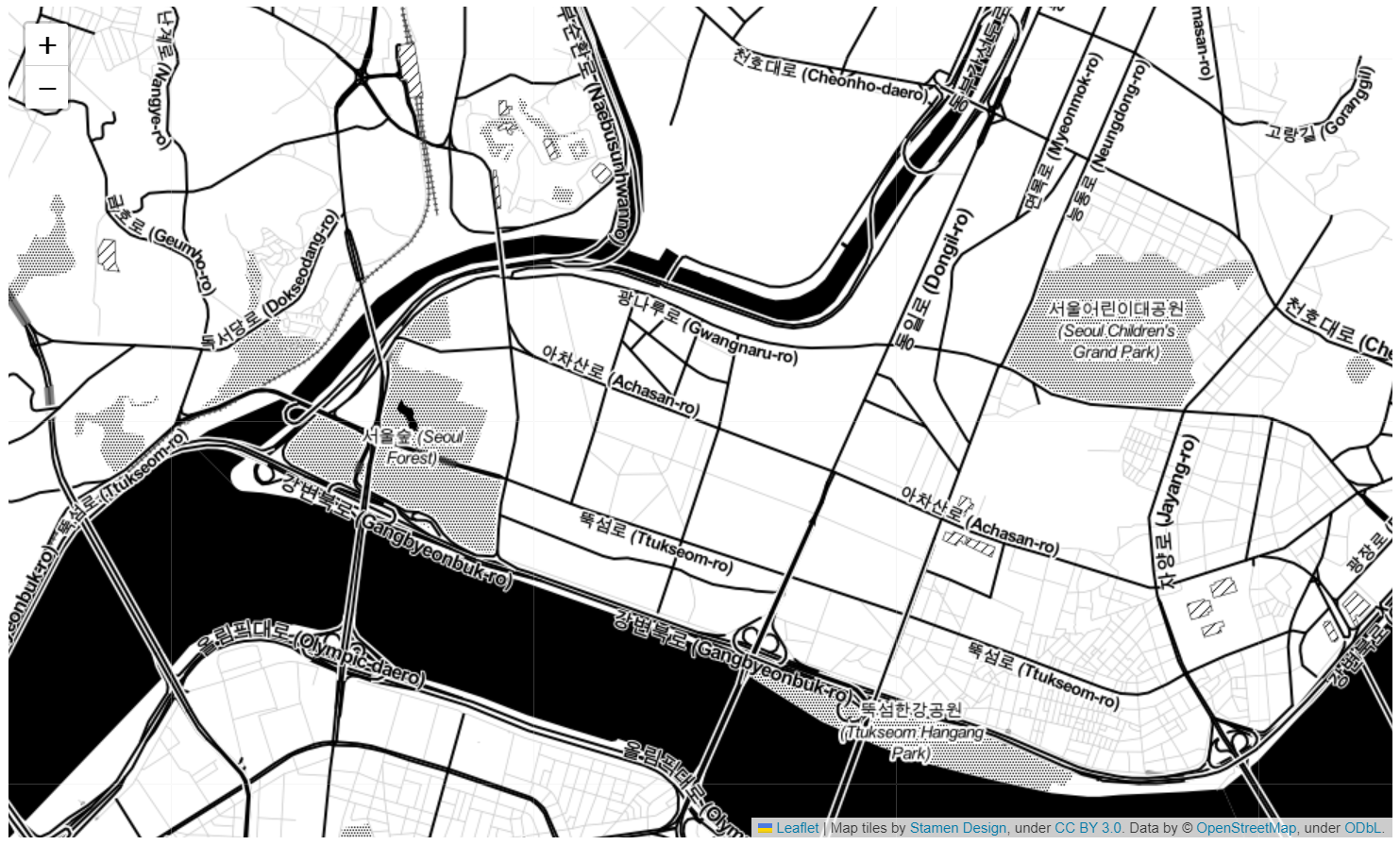
- folium.Marker()
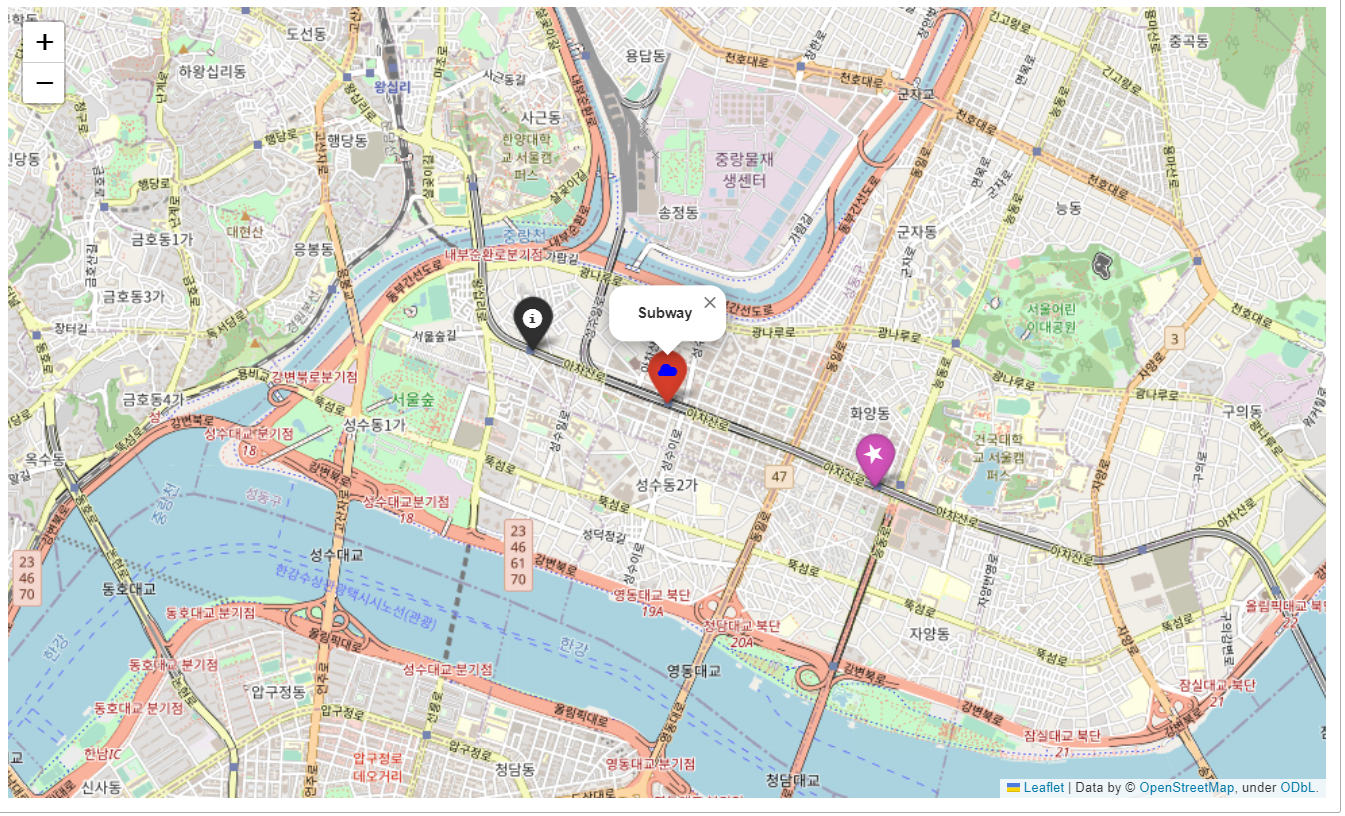
지도에 마커 생성# 성수역 좌표를 기준으로 지도 출력 m = folium.Map( location=[37.544577, 127.055991], zoom_start=14, tiles='OpenStreetMap' ) # 뚝섬역 좌표값 마커 추가 folium.Marker((37.547206, 127.047405)).add_to(m) # popup(성수역) folium.Marker( location=[37.544577, 127.055991], popup='<b>Subway</b>', # 클릭시 말풍선 출력 ).add_to(m) # tootip(성수역) folium.Marker( location=[37.544577, 127.055991], popup='<b>Subway</b>', # 클릭시 말풍선 출력 tooltip='<i>성수역</i>' # 마우스를 갖다대면 출력 ).add_to(m) # html(제로베이스) folium.Marker( location=[37.5454428,127.0581442], popup='<a href="https://zero-base.co.kr/" target=_"blink">제로베이스</a>', # 클릭시 말풍선 출력 및 연결 링크 출력 tooltip='<i>Zerobase</i>' # 마우스를 갖다대면 출력 ).add_to(m) m
→ 마우스를 성수역 위로 올리면 자동 출력됨
→ 마우스로 제로베이스 클릭 시 링크로 연결되는 말풍선 출력됨
- folium.icon()
- prefix : 아이콘 설정 관련 옵션 'icon' 옵션과 아래 지원하는 값이 맞아야 사용 가능
- 'glyphicon' : https://getbootstrap.com/docs/3.3/components/
- 'fa' : https://fontawesome.com/v4/icons/# 성수역 좌표를 기준으로 지도 출력 m = folium.Map( location=[37.544577, 127.055991], zoom_start=14, tiles='OpenStreetMap' ) # icon basic(뚝섬역) folium.Marker( (37.547206, 127.047405), icon=folium.Icon(color='black', inco='info-sign') ).add_to(m) # icon icon_color(성수역) folium.Marker( location=[37.544577, 127.055991], popup='<b>Subway</b>', tooltip='Icon color', icon=folium.Icon( color='red', icon_color='blue', icon='cloud' ) ).add_to(m) # Icon custom(건대입구역) folium.Marker( location=[37.540372, 127.069276], popup='건대입구역', tooltip='Icon custom', icon=folium.Icon( color='purple', icon_color='white', icon='star', # prefix 옵션에서 선택한 값이 지원하는 아이콘만 사용 가능 angle=50, # 아이콘 각도 prefix='glyphicon') # glyphicon, fa ).add_to(m) m
- 지도 위에서 위도/경도를 반환하는 방법 2가지
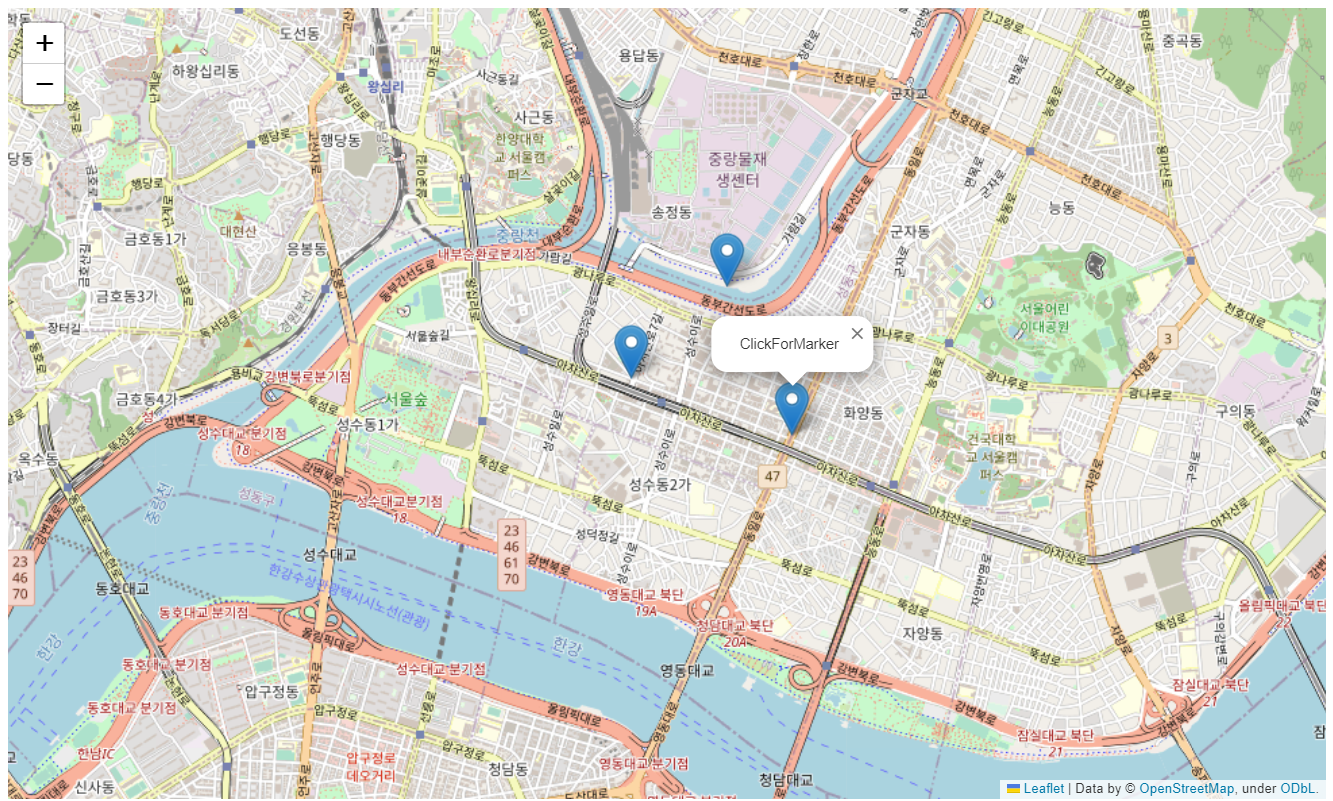
- folium.ClickForMarker()
지도를 마우스로 클릭했을 때 마커를 생성해주고, 마커를 클릭하면 popup기능 출력
별도 지정 없을 시 위도/경도(default) 값 출력- folium.LatLngPopup()
지도를 마우스로 클릭했을 때 위도/경도 정보를 반환해줌# 성수역 좌표값 m = folium.Map( location=[37.544577, 127.055991], zoom_start=14, tiles='OpenStreetMap' ) m.add_child(folium.ClickForMarker(popup='ClickForMarker'))
# 성수역 좌표값 m = folium.Map( location=[37.544577, 127.055991], zoom_start=14, tiles='OpenStreetMap' ) m.add_child(folium.LatLngPopup())
- folium.Circle(), folium.CircleMarker()
m = folium.Map( location=[37.5488935,127.0386158], zoom_start=14, tiles='OpenStreetMap' ) # Circle folium.Circle( location =[37.5571759, 127.0454092], # 한양대학교 radius=100, # 반지름 설정 fill=True, # 색상을 채울건지 설정하는 옵션 color='#914ad9', # color picker 참고 fill_color='red', popup='Circle Popup', tooltip='Circle Tooltip', ).add_to(m) # CircleMarker folium.CircleMarker( location =[37.5443878, 127.0374424], # 서울숲 radius=30, # 반지름 설정 fill=True, # 색상을 채울건지 설정하는 옵션 color='#f8ff75', # color picker 참고 fill_color='#2050c9', popup='CircleMarker Popup', tooltip='CircleMaker Tooltip', ).add_to(m) m
- folium.Choropleth
- 실업률이 높으면 진하게, 낮으면 연하게 색을 지도에 표시하는 그래프
import json state_data = pd.read_csv('../data/02. US_Unemployment_Oct2012.csv') m = folium.Map([43, -102], zoom_start=3) folium.Choropleth( geo_data='../data/02. us-states.json', # 경계선 좌표값이 담긴 데이터 data=state_data, # Series or DataFrame columns=['State', 'Unemployment'], # DataFrame columns key_on='feature.id', fill_color='BuPu', fill_opacity=1, # 0~1 투명도 line_opacity=1, # 0~1 투명도 legend_name='Unemployment rate (%)' # 범례 이름 ).add_to(m) m
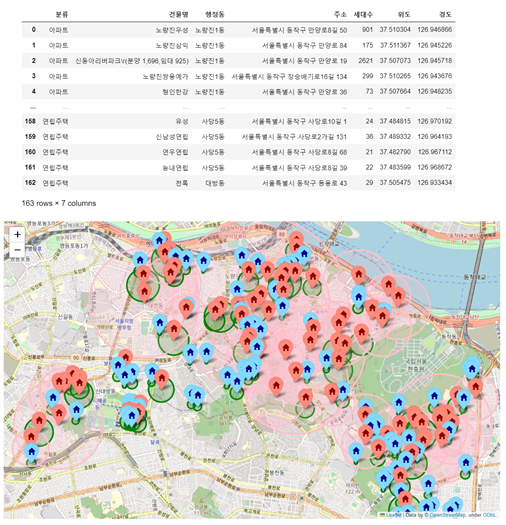
예제 : 아파트 유형 지도 시각화
- 출처 : 공공데이터포털(https://www.data.go.kr/data/15066101/fileData.do)
- 데이터는 NaN값 제거 등 전처리 완료 상태
- 세대수에 따른 비교 시각화
import pandas as pd df = pd.read_csv('../data/02. Apartment.csv', encoding='euc-kr') # cp949 # folium m = folium.Map( location=[37.4988794, 126.9516345], zoom_start=13) for idx, row in df.iterrows(): # location lat, lng = row.위도, row.경도 # Marker folium.Marker( location=[lat, lng], popup=row.주소, tooltip=row['분류 '] , icon=folium.Icon( icon='home', color='lightred' if row.세대수>=199 else 'lightblue', icon_color='darkred' if row.세대수>=199 else 'darkblue' ) ).add_to(m) # Circle folium.Circle( location=[lat, lng], radius=row.세대수 * 0.5, fill=True, color='pink' if row.세대수>=518 else 'green', fill_color='pink' if row.세대수>=518 else 'green' ).add_to(m) m




10. 서울시 범죄 현황에 대한 지도 시각화
import pandas as pd
import json
import folium
crime_anal_norm = pd.read_csv("../data/02. crime_in_Seoul_final.csv", index_col=0, encoding='utf-8')
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
crime_anal_norm.head()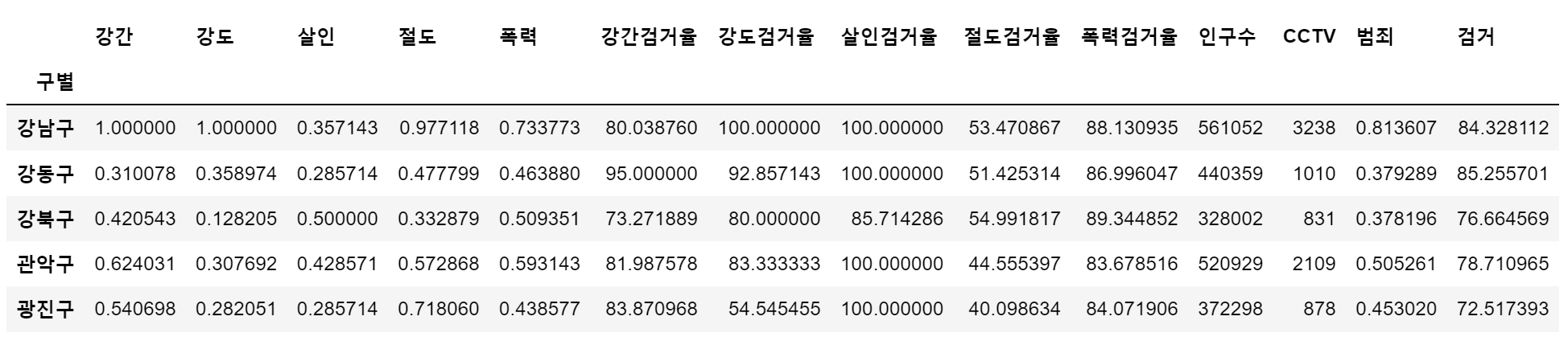
- 살인발생 건수 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm['살인'],
columns=[crime_anal_norm.index, crime_anal_norm['살인']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 살인 발생 건수'
).add_to(my_map)
my_map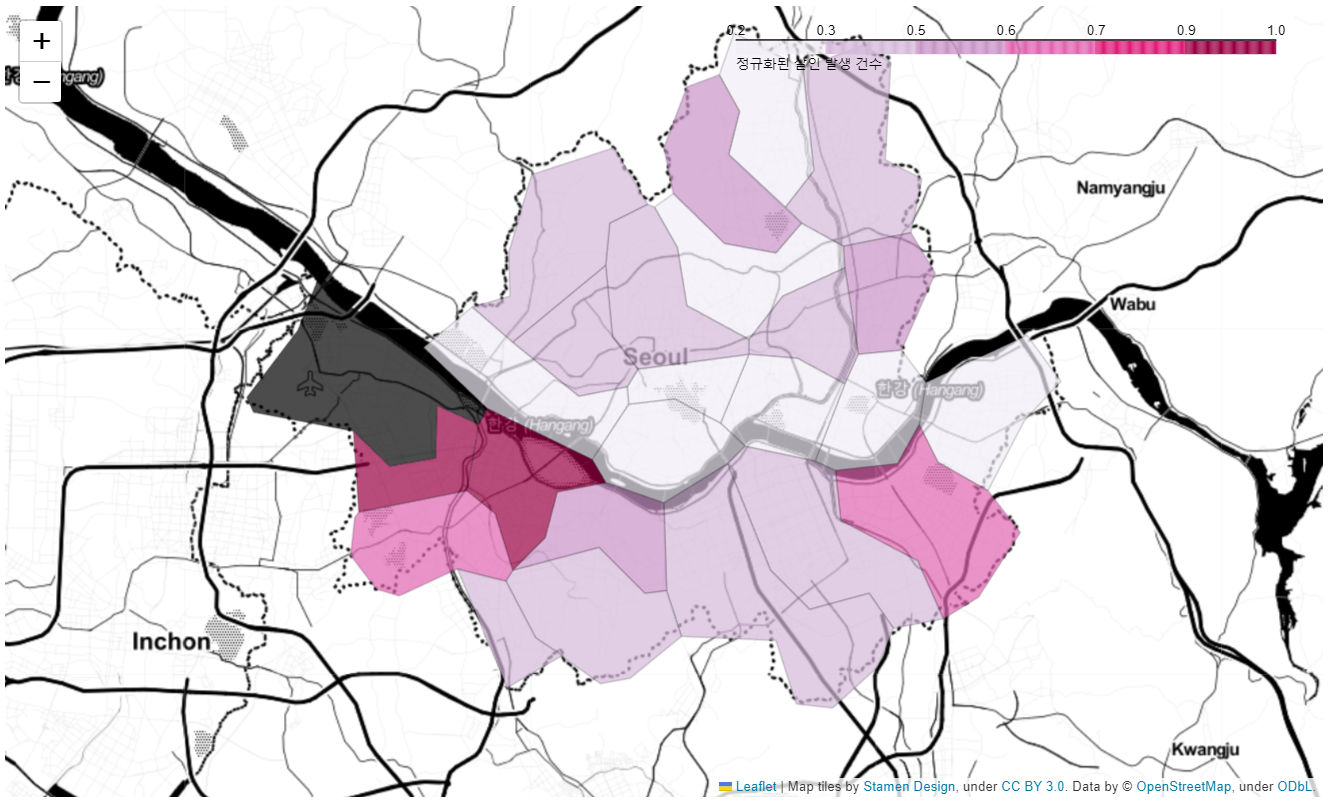
- 성범죄 건수 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm['강간'],
columns=[crime_anal_norm.index, crime_anal_norm['강간']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 강간 발생 건수'
).add_to(my_map)
my_map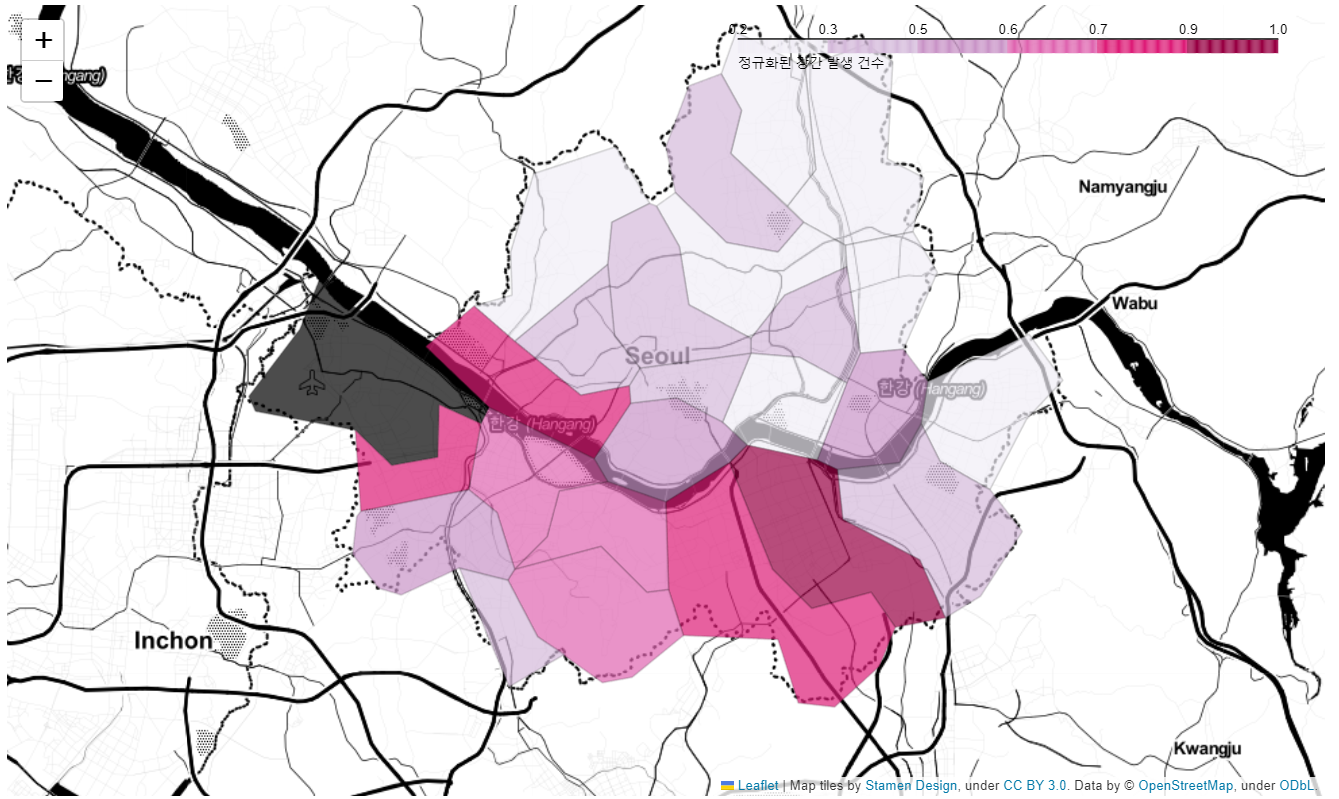
- 5대 범죄 발생 건수 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm['범죄'],
columns=[crime_anal_norm.index, crime_anal_norm['범죄']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 5대 범죄 발생 건수'
).add_to(my_map)
my_map
- 인구 대비 범죄 발생 건수 지도 시각화
tmp_criminal = crime_anal_norm['범죄'] / crime_anal_norm['인구수']
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=tmp_criminal,
columns=[crime_anal_norm.index, tmp_criminal],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='인구대비 범죄 발생 건수'
).add_to(my_map)
my_map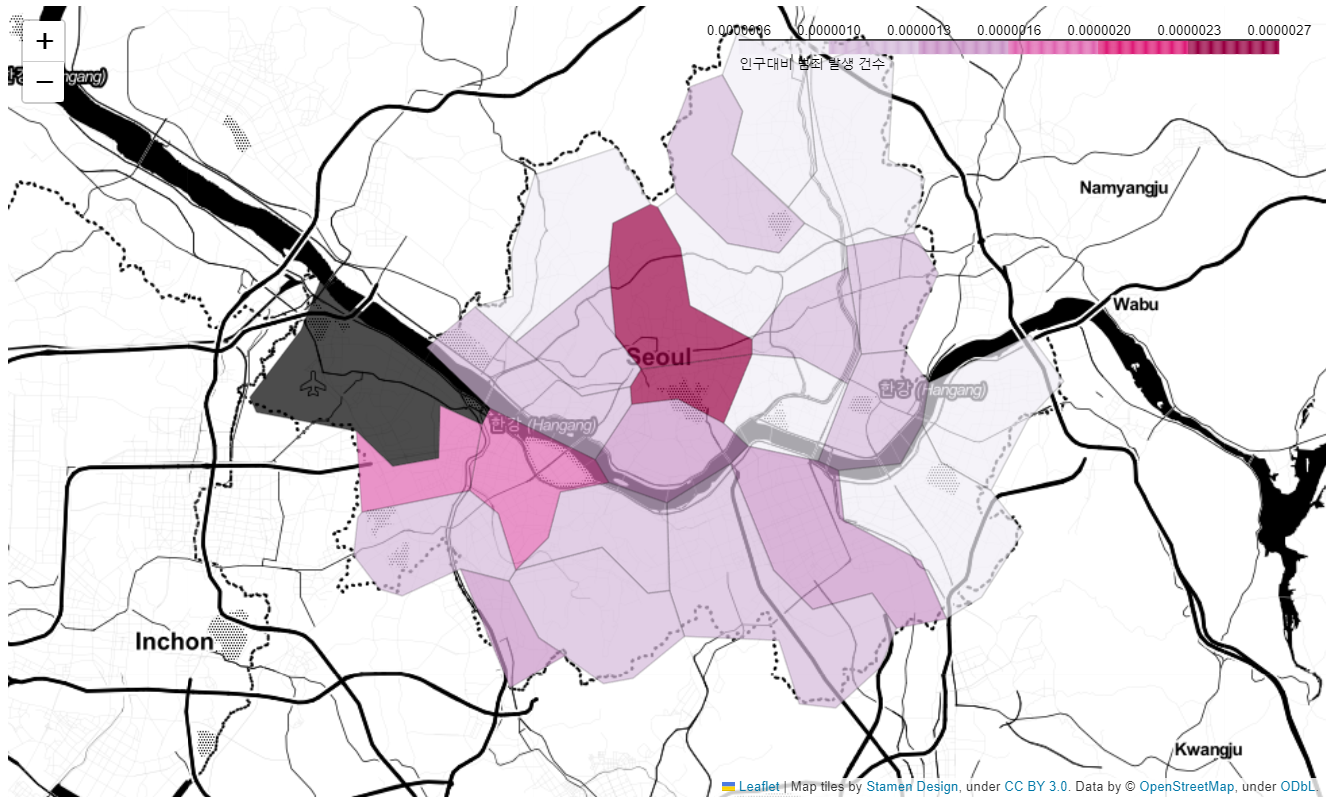
- 경찰서별 정보를 범죄발생과 함께 표시
crime_anal_station = pd.read_csv('../data/02. crime_in_Seoul_1st.csv', encoding='utf-8', index_col=0)
crime_anal_station.head()
- '검거' 컬럼 추가
col = ['살인검거', '강도검거', '강간검거', '절도검거', '폭력검거']
tmp = crime_anal_station[col] / crime_anal_station[col].max() # 정규화
crime_anal_station['검거'] = np.mean(tmp, axis=1) # numpy axis=1 행(가로) / pandas axis=1 열(세로)
crime_anal_station.tail()
- 경찰서 위치 마커 표시
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, row in crime_anal_station.iterrows():
folium.Marker(
location=[row['lat'], row['lng']]
).add_to(my_map)
my_map 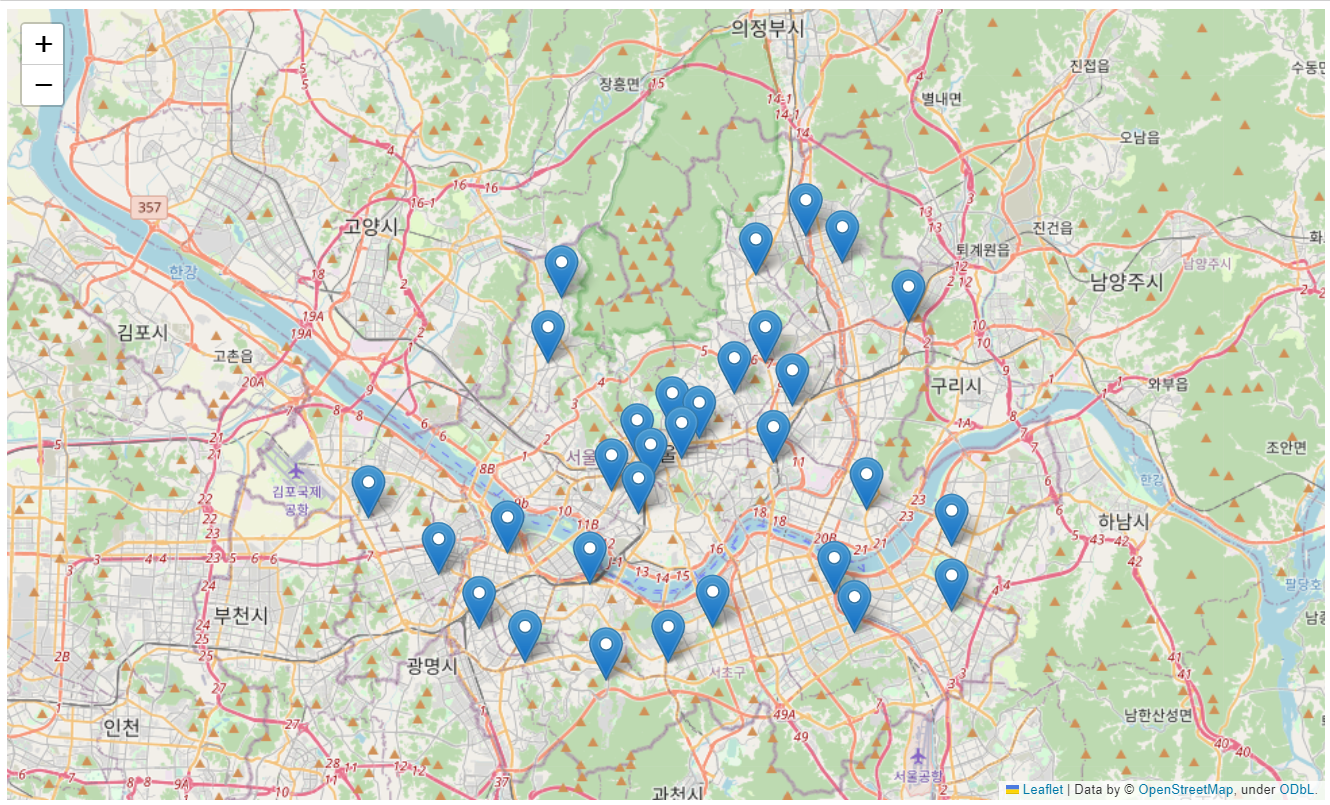
- 경계선을 구분하고 검거에 값을 곱한 뒤 원의 넓이 설정
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
# 경계선 구분
folium.Choropleth(
geo_data=geo_str,
data=crime_anal_norm['범죄'],
columns=[crime_anal_norm.index, crime_anal_norm['범죄']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
).add_to(my_map)
# 원 넓이 조정
for idx, row in crime_anal_station.iterrows():
folium.CircleMarker(
location=[row['lat'], row['lng']],
radius=row['검거'] * 50,
popup=row['구분'] + " : " + "%.2f" % row['검거'],
color='#3186cc',
fill=True,
fill_color='#3186cc'
).add_to(my_map)
my_map 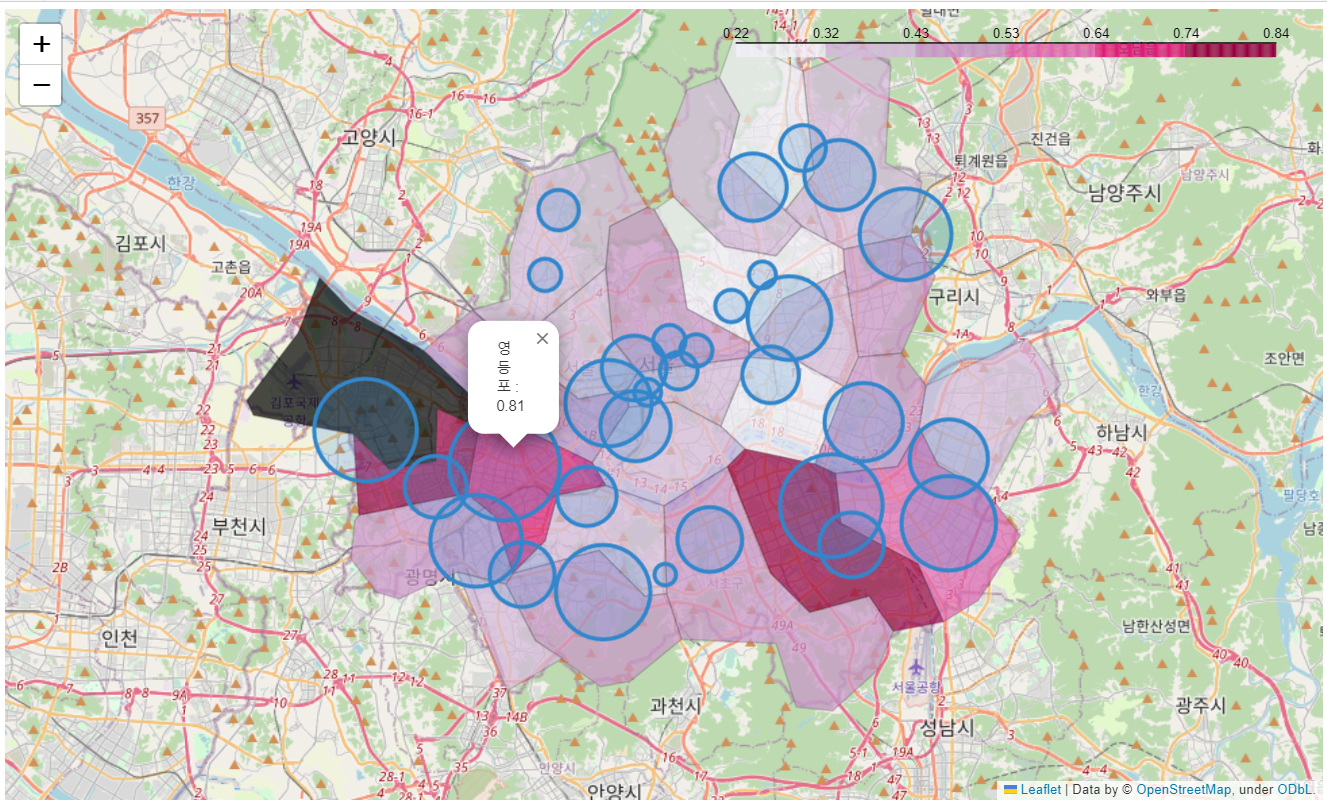
→ 결과적으로 영등포구는 범죄율도 높고 검거율도 높다는 결과가 나타났다.
11. 서울시 범죄 현황 발생 장소 분석
- 추가 검증
crime_loc_raw = pd.read_csv(
'../data/02. crime_in_Seoul_location.csv', thousands=',', encoding='euc-kr')
crime_loc_raw
print(crime_loc_raw.범죄명.unique())
# array(['살인', '강도', '강간.추행', '절도', '폭력'], dtype=object)
print(crime_loc_raw['장소'].unique())
# array(['아파트, 연립 다세대', '단독주택', '노상', '상점', '숙박업소, 목욕탕', '유흥 접객업소', '사무실', '역, 대합실', '교통수단', '유원지 ', '학교', '금융기관', '기타'], dtype=object)
# 장소를 기준으로 각 범죄에 따른 평균 값을 구하는 pivot_table 생성
crime_loc = crime_loc_raw.pivot_table(
crime_loc_raw, index='장소', columns='범죄명', aggfunc=[np.sum]
)
crime_loc.columns = crime_loc.columns.droplevel([0, 1]) # 상위 2컬럼 제거
# 정규화 수행
col = ['살인', '강도', '강간', '절도', '폭력']
crime_loc_norm = crime_loc / crime_loc.max() # 정규화
# 각 범죄의 평균값을 나타내는 '종합' 컬럼 추가
crime_loc_norm['종합'] = np.mean(crime_loc_norm, axis=1)
crime_loc_norm.head()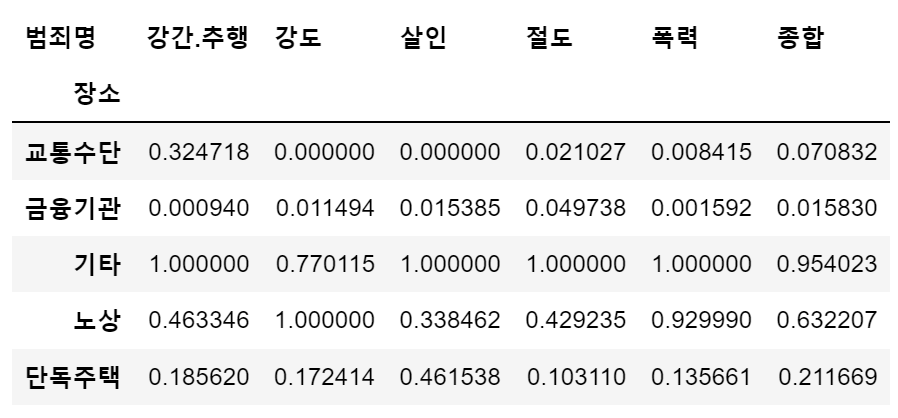
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc('font', family='Malgun Gothic')
%matplotlib inline
crime_loc_norm_sort = crime_loc_norm.sort_values('종합', ascending=False)
def drawGraph():
plt.figure(figsize=(8, 6))
sns.heatmap(
crime_loc_norm_sort,
annot=True,
fmt='f',
linewidths=0.5,
cmap='RdPu',
)
plt.title('범죄 발생 장소')
plt.show()
drawGraph()
→ 범죄 발생 장소는 기타를 제외한 노상에서 가장 많은 범죄가 일어났고, 다음으로 살인은 단독주택에서 많이 일어났다는 결과로 여러 연관된 문제점을 시사해 볼 수 있다.
✔️ 웹 데이터 분석 1
1. BeautifulSoup for web data
⭐ BeautifulSoup 기초
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4-
data
- '03. zerobase.html' -
'03. zeobase.html'
<!DOCTYPE html>
<html>
<head>
<title>Very Simple HTML Code by Seolryung</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="https://velog.io/@seolryung" id="sr-link">seolryung.log</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" target="_blinkid=" id="py-link">Python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>Data Science is funny.</b>
</p>
<p class="outer-text">
<i>All I need is Love</i>
</p>
</body>
</html>
- html 파일 읽어오기
- prettify() : html 파일의 들여쓰기 형태 그대로 가져오는 메서드# import from bs4 import BeautifulSoup page = open('../data/03. zerobase.html', 'r').read() soup = BeautifulSoup(page, 'html.parser') print(soup.prettify())
- 태그 확인
# head 태그 확인 soup.head # body 태그 확인 soup.body # p 태그 확인 soup.p # find() : 처음 발견한 p 태그만 출력 soup.find('p')
- 속성값을 이용하여 특정 p 태그 출력
print( soup.find('p', class_='inner-text second-item') ) # class는 예약어가 있기 때문에 _를 붙여서 호출할 것 # 결과 # <p class="inner-text second-item"> # Happy Data Science. # <a href="https://www.python.org" id="sr-link" target="_blinkid=">Python</a> # </p>
- text 출력
# text 출력시 공백 및 줄바꿈 표시가 같이 출력되므로 strip()으로 제거 후 출력 soup.find('p', {'class':'outer-text first-item'}).text.strip() # 결과 # 'Data Science is funny.'# 다중 조건 soup.find('p', {'class':'inner-text first-item', 'id':'first'}) # 결과 # <p class="inner-text first-item" id="first"> # Happy ZeroBase. # <a href="https://velog.io/@seolryung" id="sr-link">seolryung.log</a> # </p>
- find_all()
# find_all(): 여러개의 태그를 반환하고, 리스트(list) 형태로 반환 soup.find_all('p')
# 특정 태그 확인 soup.find_all(class_='outer-text') # 특정 태그 텍스트 확인 print(soup.find_all(id='sr-link')[0].text) # 결과 # 'seolryung.log'soup.find_all('p', class_='inner-text second-item')print(soup.find_all('p')[0].text) print(soup.find_all('p')[1].string) print(soup.find_all('p')[1].get_text()) # 결과 # Happy ZeroBase. # seolryung.log # None # Happy Data Science. # Python
- p 태그 리스트에서 텍스트 속성만 출력
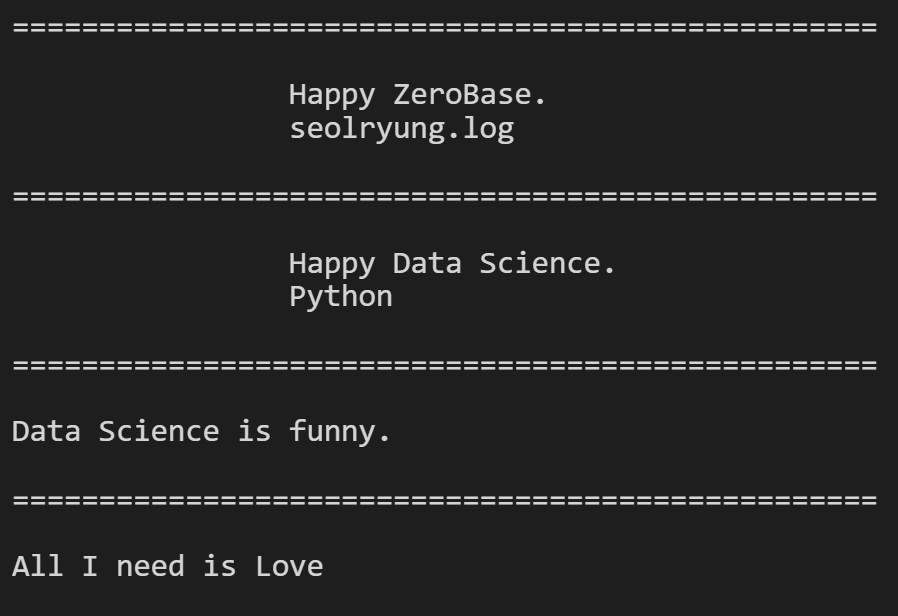
for each_tag in soup.find_all('p'): print('=' * 50) print(each_tag.text)
# a 태그에서 href 속성값에 있는 값 추출 links = soup.find_all('a') links[0].get('href'), links[1]['href'] # 결과 # ('https://velog.io/@seolryung', 'https://www.python.org')for each in links: href = each.get('href') # each['href'] text = each.get_text() print(text + ' => ' + href) # 결과 # seolryung.log => https://velog.io/@seolryung # Python => https://www.python.org
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
