✔️ 웹 데이터 분석 2~4
⭐ BeautifulSoup
예제 1-1 : 네이버 금융
- 웹 데이터 출처 : https://finance.naver.com/marketindex/
from urllib.request import urlopen
from bs4 import BeautifulSoupurl = 'https://finance.naver.com/marketindex/'
response = urlopen(url)
# 'page' 변수 말고 'response', 'res'라고도 많이 칭함
response.status #200 → 상태코드- 페이지 불러오기
url = 'https://finance.naver.com/marketindex/'
page = urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify())
- 원하는 문구 추출
# 방법1
soup.find_all('span', 'value'), len(soup.find_all('span', 'value'))
# 방법2
soup.find_all('span', class_='value'), len(soup.find_all('span', 'value'))
# 방법3
soup.find_all('span',{'class':'value'}), len(soup.find_all('span',{'class':'value'}))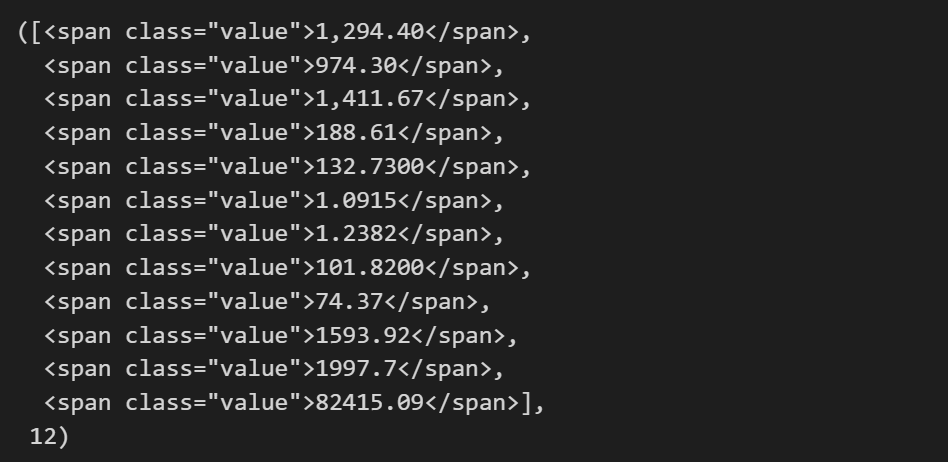
# 텍스트 추출 방법 3가지
soup.find_all('span', {'class':'value'})[0].text
soup.find_all('span', {'class':'value'})[0].string
soup.find_all('span', {'class':'value'})[0].get_text()
# '1,294.40'예제 1-2 : 네이버 금융
- 웹 데이터 출처 : https://finance.naver.com/marketindex/
- !pip install requests
- find(), select_one() : 단일선택
- find_all(), select() : 다중선택
import requests
# from urllib.request.Request
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/marketindex/'
response = requests.get(url)
# response # response.status 작성하지 않아도 requests 모듈에서는 상태코드 바로 출력
# response.text # 한줄에 태그/텍스트가 나타나기 때문에 보기좋게 변환
soup = BeautifulSoup(response.text, 'html.parser')- find_all()
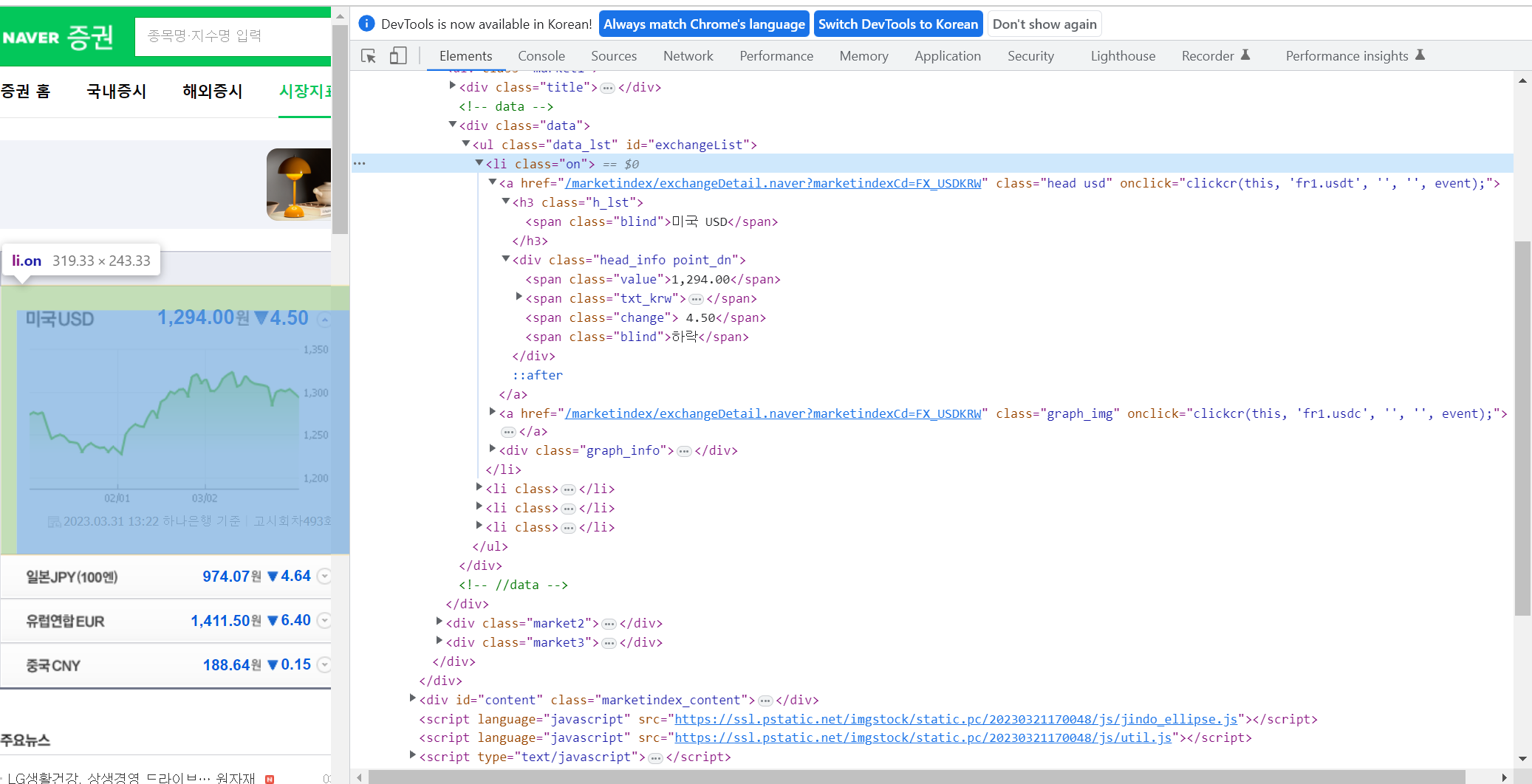
findmetohd = soup.find_all('ul', id='exchangeList')
findmetohd[0].find_all('span', 'value')[0].text
# '1,295.10'- select(), selcet_one()
- class: . 으로 시작, id: # 으로 시작
- > : 하위를 나타냄
# soup.find_all('li', 'on')
exchangeList = soup.select('#exchangeList > li')
len(exchangeList), exchangeList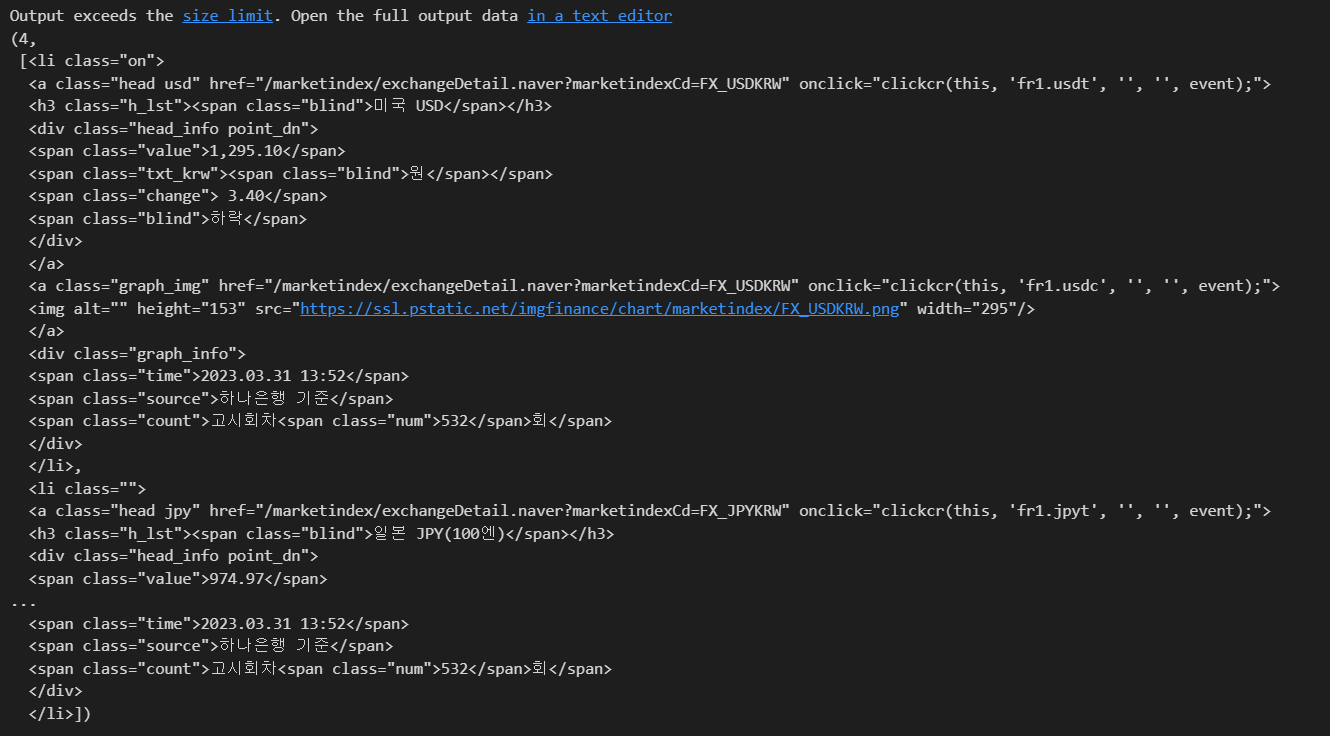
# 나라이름
title = exchangeList[0].select_one('.h_lst').text
# 환율 시세
exchange = exchangeList[0].select_one('.value').text
# 변동
change = exchangeList[0].select_one('.change').text
# 상승/하락
updown = exchangeList[0].select_one('.head_info.point_dn > .blind').text # > : 바로 밑 하위 나타냄
# 연결 링크
link = exchangeList[0].select_one('a').get('href')
title, exchange, change, updown, link
# ('미국 USD',
# '1,295.10',
# ' 3.40',
# '하락',
# '/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW')* class 태그에 띄어쓰기로 여러 단어가 있을 경우, 코드에서 실행할 때는 .으로 연결해줘야 함
→ head_info.point_dn 이 해당되는 경우
baseUrl = 'https://finance.naver.com'
baseUrl + exchangeList[0].select_one('a').get('href')
# 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'- 4개 데이터를 수집하고 엑셀파일로 저장
import pandas as pd
exchange_datas = []
baseUrl = 'https://finance.naver.com'
for item in exchangeList:
data = {
'title': item.select_one('.h_lst').text,
'exchange': item.select_one('.value').text,
'change': item.select_one('.change').text,
'updown': item.select_one('.head_info.point_dn > .blind').text,
'link': baseUrl + item.select_one('a').get('href')
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel('./naverfinance.xlsx', encoding='utf-8')
예제 2 : 위키백과 문서정보 가져오기
- 웹 데이터 출처 : https://ko.wikipedia.org/wiki/여명의_눈동자
import urllib
from urllib.request import urlopen, Request
html = 'https://ko.wikipedia.org/wiki/{search_words}'
# https://ko.wikipedia.org/wiki/여명의_눈동자
req = Request(html.format(search_words=urllib.parse.quote('여명의_눈동자'))) # 글자를 URL로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
- 등장인물 '채시라' 찾기
n = 0
for each in soup.find_all('ul'):
print('=>' + str(n) + '==================')
print(each.get_text())
n+=1
→ 32번째 줄에 있는 것 확인
soup.find_all('ul')[32].text.strip().replace('\xa0','').replace('\n','')
# '채시라: 윤여옥 역 (아역: 김민정)박상원: 장하림(하리모토 나츠오) 역 (아역: 김태진)최재성: 최대치(사카이) 역 (아역: 장덕수)'1. 시카고 맛집 데이터 분석 - 개요
- 최종목표 : 총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
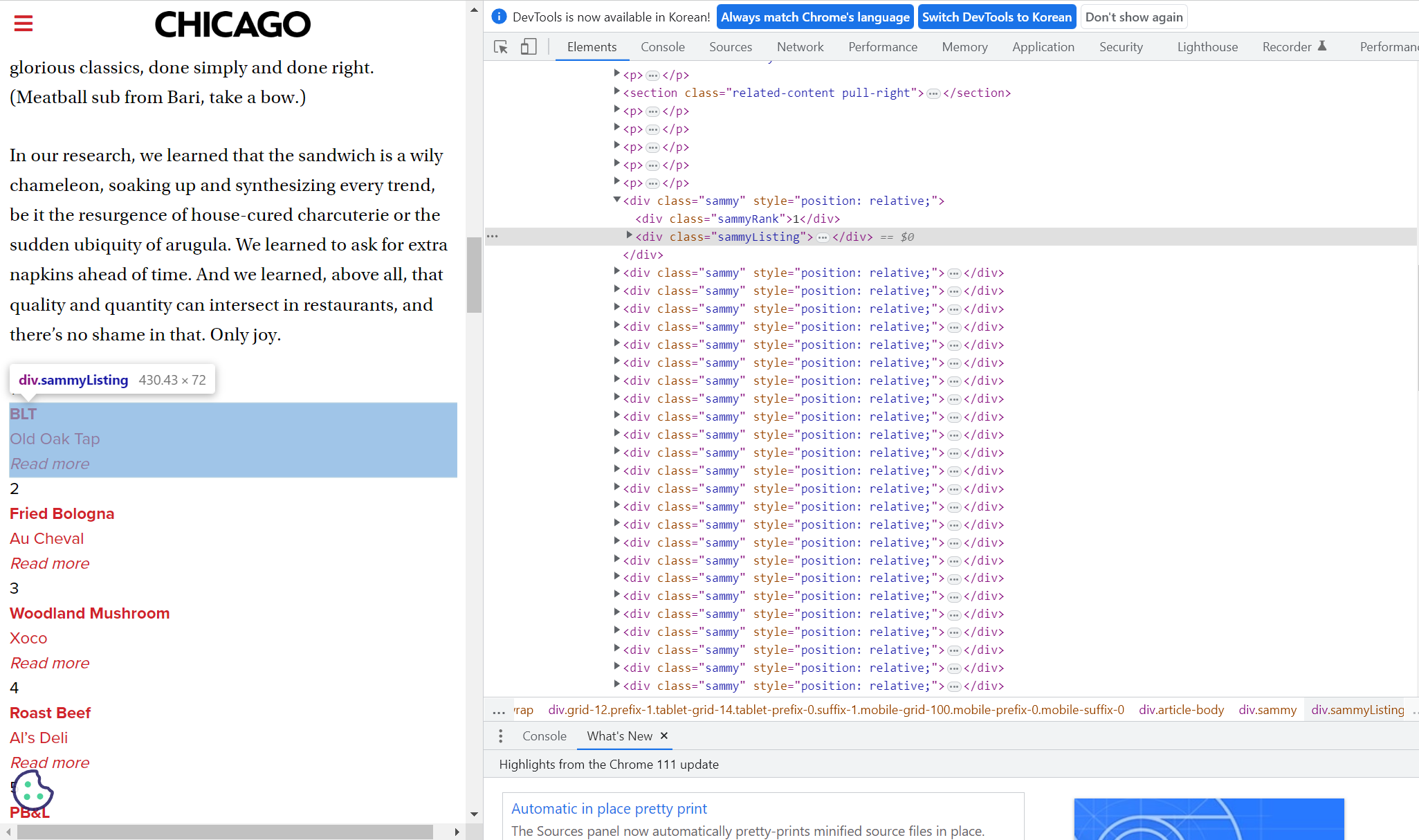
2. 시카고 맛집 데이터 분석 - 메인페이지
- 목표 : 메뉴, 가게이름 추출
# !pip install fake-useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = 'https://www.chicagomag.com'
url_sub = '/chicago-magazine/november-2012/best-sandwiches-chicago/'
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={'User-Agent': ua.ie})
# req = Request(url, headers={'User-Agent':'Chrome'})
# req = Request(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'})
html = urlopen(req)
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())
- 요소 확인
soup.find_all('div', 'sammy'), len(soup.find_all('div', class_='sammy'))
# soup.select('.sammy'), len(soup.select('.sammy'))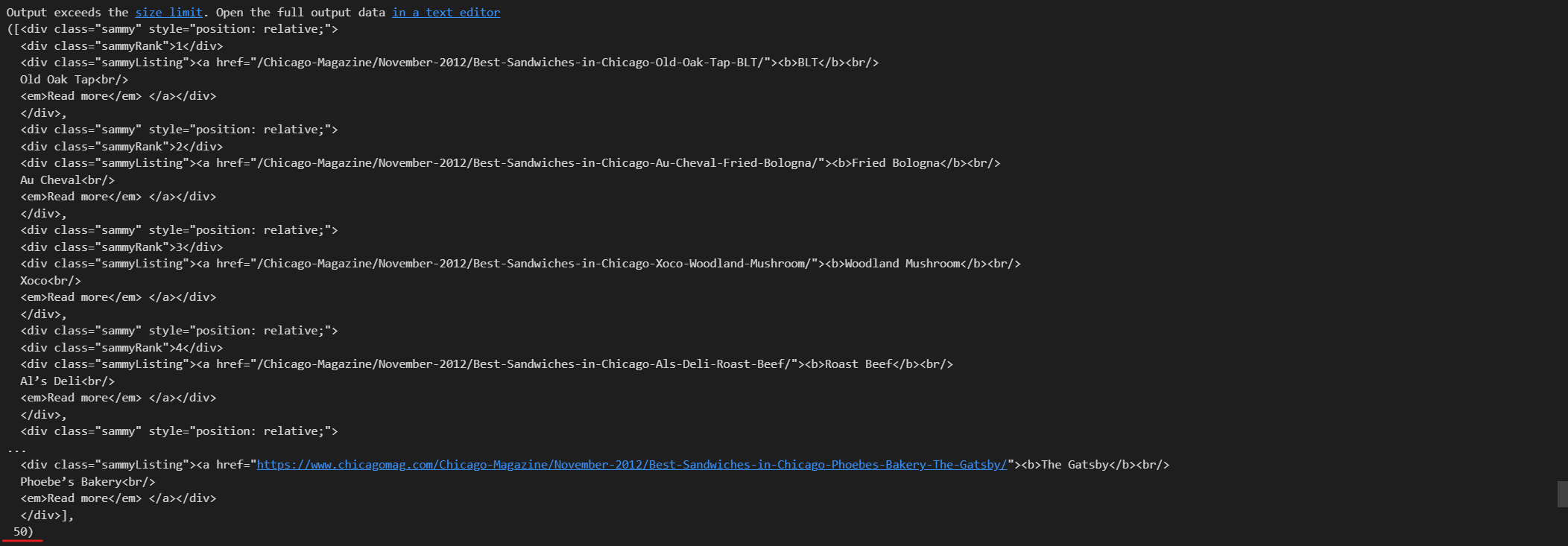
tmp_one = soup.find_all('div', 'sammy')[0]
tmp_one
type(tmp_one) # bs4.element.Tagtmp_one.find(class_='sammyRank').get_text() # '1'
# tmp_one.select_one('.sammyRank').texttmp_one.find('div', {'class':'sammyListing'}).get_text() # 'BLT\nOld Oak Tap\nRead more '
# tmp_one.select_one('.sammyListing').text# tmp_one.select_one('a')['href']
# tmp_one.select_one('a').get('href')
tmp_one.find('a')['href']
# '/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'# re 모듈 : 정규 표현식 (search(), findall(), split(), sub() 등 사용가능)
import re
tmp_string = tmp_one.find(class_='sammyListing').get_text()
# \n = LF (줄 바꿈) → Unix / Mac OS X에서 줄 바꾸기 문자로 사용
# \r\n = CR + LF → Windows에서 줄 바꾸기 문자로 사용
re.split(('\n|\r\n'), tmp_string) # ['BLT', 'Old Oak Tap', 'Read more ']print(re.split(('\n|\r\n'), tmp_string)[0]) # BLT → menu
print(re.split(('\n|\r\n'), tmp_string)[1]) # Old Oak Tap → cafe name- 50개의 가게 정보를 각 리스트에 추가
from urllib.parse import urljoin
url_base = 'https://www.chicagomag.com'
# 필요한 내용을 담을 빈리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_menu = []
url_add = []
list_soup = soup.find_all('div', 'sammy') # soup.select('.sammy)
for item in list_soup:
rank.append(item.find(class_='sammyRank').get_text())
tmp_string = item.find(class_='sammyListing').get_text()
main_menu.append(re.split(('\n|\r\n'), tmp_string)[0])
cafe_menu.append(re.split(('\n|\r\n'), tmp_string)[1])
url_add.append(urljoin(url_base, item.find('a')['href'])) # url_base가 있으면 join 하지 않고, 없으면 join 실행해주는 함수: urljoin()
print(len(rank), len(main_menu), len(cafe_menu), len(url_add)) # 50 50 50 50
print(rank[:5]) # ['1', '2', '3', '4', '5']
print(main_menu[:5]) # ['BLT', 'Fried Bologna', 'Woodland Mushroom', 'Roast Beef', 'PB&L']
print(cafe_menu[:5]) # ['Old Oak Tap', 'Au Cheval', 'Xoco', 'Al’s Deli', 'Publican Quality Meats']
print(url_add[:5]) # ['https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/', ··· , 'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/']- DataFrame에 담기
import pandas as pd
data = {
'Rank': rank,
'Menu': main_menu,
'Cafe': cafe_menu,
'URL' : url_add
}
df = pd.DataFrame(data)
# 컬럼 순서 변경
df = pd.DataFrame(data, columns=['Rank', 'Cafe', 'Menu', 'URL'])
df.tail()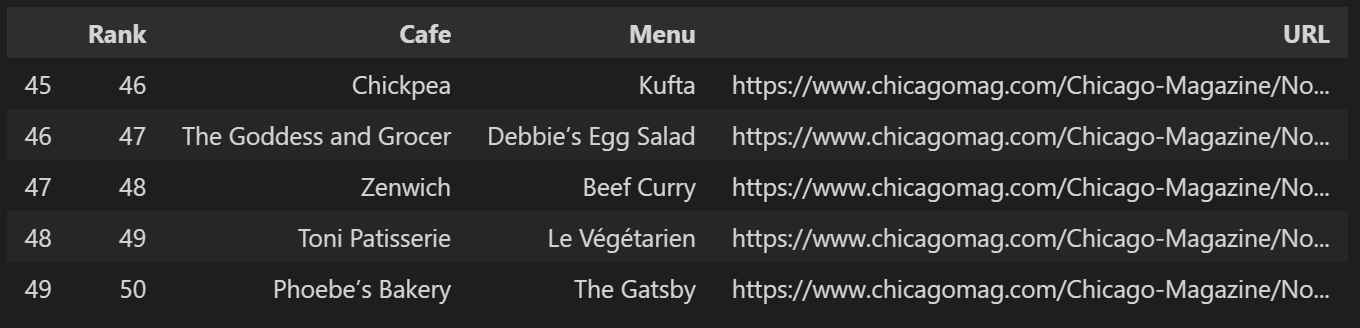
- csv 파일로 저장
df.to_csv('../data/03. best_sandwiches_list_chicago.csv', sep=',', encoding='utf-8')3. 시카고 맛집 데이터 분석 - 하위페이지
- 목표 : 가격, 주소 추출하여 위 테이블에 추가
# requirements
import pandas as pd
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
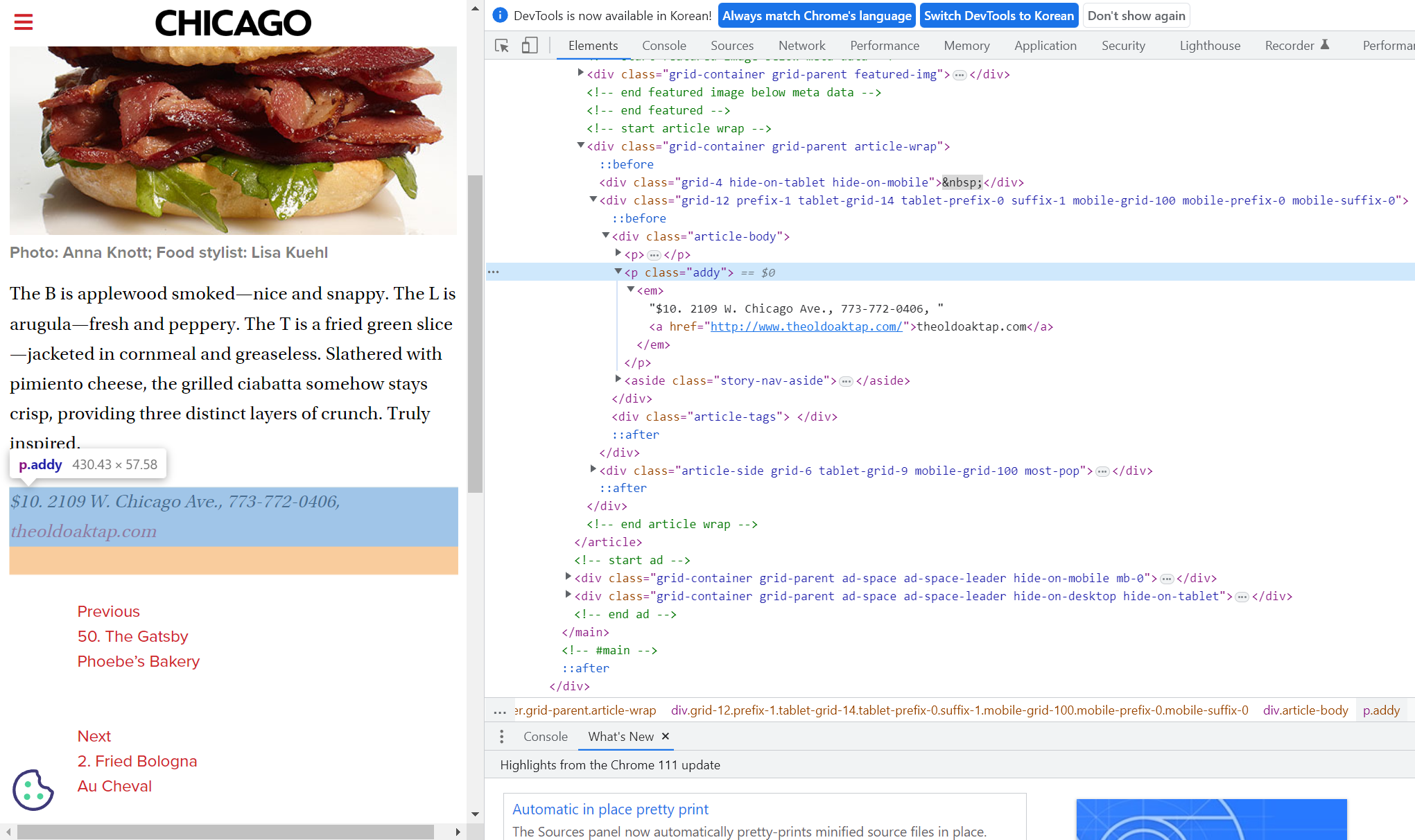
from bs4 import BeautifulSoupdf = pd.read_csv('../data/03. best_sandwiches_list_chicago.csv', index_col=0)
df.tail()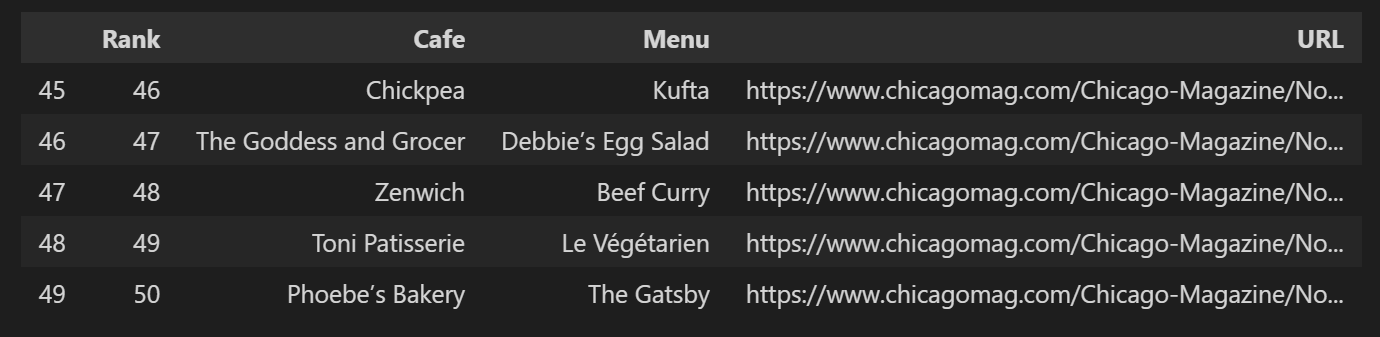
- 데이터프레임 요소 확인
req = Request(df['URL'][0], headers={'user-agent':ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')
soup_tmp.find('p', 'addy') # soup_tmp.select_one('.addy)
# <p class="addy">
# <em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>price_tmp = soup_tmp.find('p', 'addy').text
price_tmp # '\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'# regular expression
import re
re.split('.,', price_tmp)
# ['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']price_tmp = re.split('.,', price_tmp)[0]
price_tmp # '\n$10. 2109 W. Chicago Ave'tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
print(tmp) # $10. → 가격
print(price_tmp[len(tmp) + 2:]) # 2109 W. Chicago Ave → 주소- 정보를 담을 각 리스트 생성
# conda install -c conda-forge tqdm
from tqdm import tqdm # 로딩 바와 같은 모듈
price = []
address = []
for idx, row in df.iterrows():
req = Request(row['URL'], headers={'user-agent':ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')
gettings = soup_tmp.find('p', 'addy').get_text()
price_tmp = re.split('.,', gettings)[0]
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx) # 잘 실행되고 있는지 확인하기 위한 쿼리- 위에서 만든 DataFrame에 추가
df['Price'] = price
df['Address'] = address
df = df.loc[:, ['Rank', 'Cafe', 'Menu', 'Price', 'Address']] # 데이터프레임 컬럼 순서 정렬
df.set_index('Rank', inplace=True) # 'Rank'를 인덱스로 설정
df.head()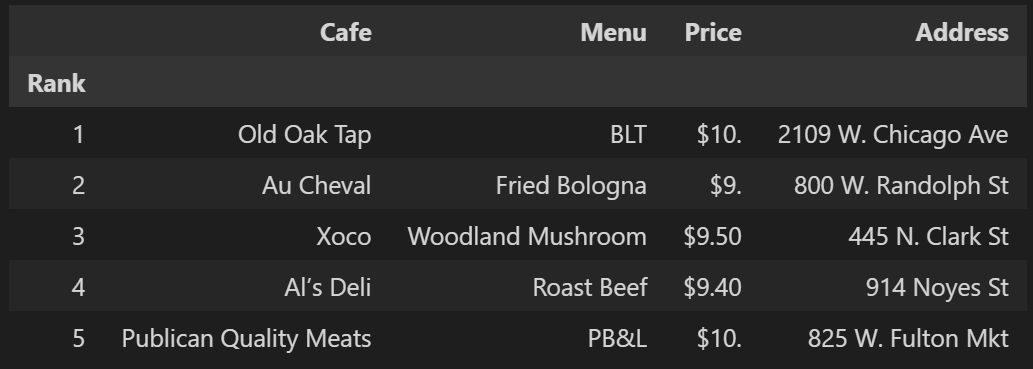
- 최종 결과를 파일로 저장
df.to_csv('../data/03. best_sandwiches_list_chicago2.csv', sep=',', encoding='utf-8')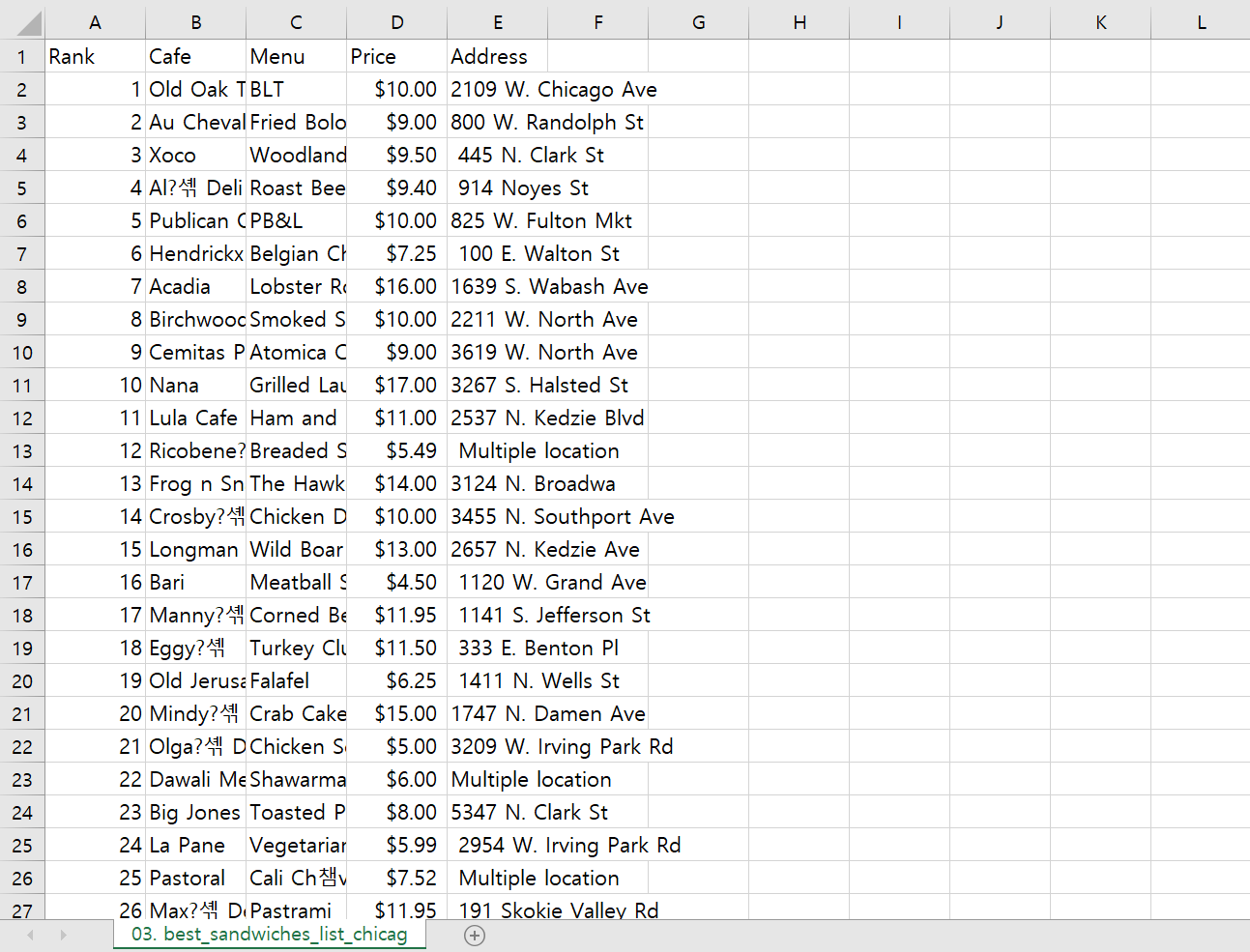
4. 시카고 맛집 데이터 지도 시각화
# requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdmdf = pd.read_csv('../data/03. best_sandwiches_list_chicago2.csv', index_col=0, encoding='utf-8')
df.tail(10)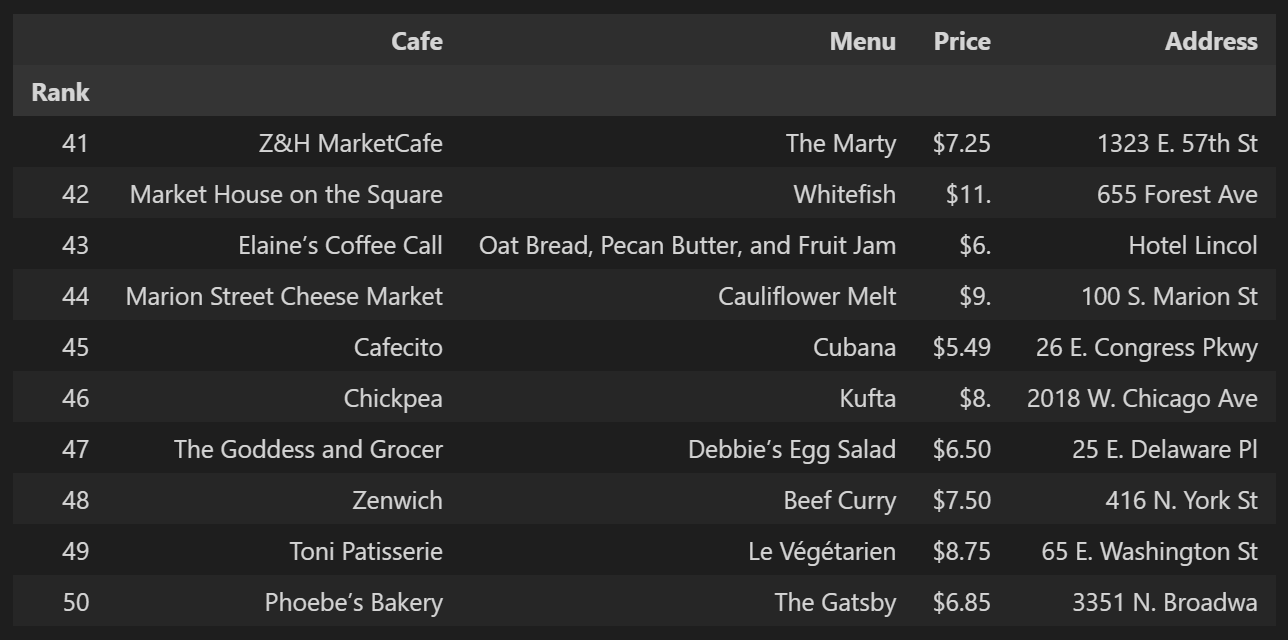
- 위도('lat'), 경도('lng') 받아오기
gmaps_key = "AI~~~~~foA"
gmaps = googlemaps.Client(key=gmaps_key)
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row['Address'] == 'Multiple location':
target_name = row['Address'] + ', ' + 'Chicago'
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get('geometry')
lat.append(location_output['location']['lat'])
lng.append(location_output['location']['lng'])
else:
lat.append(np.nan)
lng.append(np.nan)
df['lat'] = lat
df['lng'] = lng
df.head()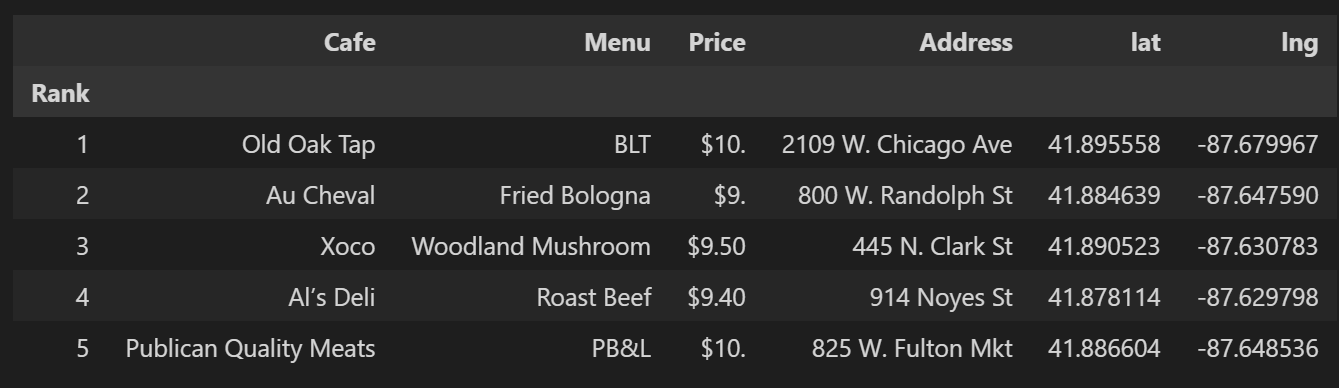
- 지도에 마커를 이용하여 'Cafe', 'Menu' 표시 및 아이콘 설정
mapping = folium.Map(location=[41.895558, -87.679967], zoom_start=11)
for idx, row in df.iterrows():
if not row['Address'] == 'Multiple location':
folium.Marker(
location = [row['lat'], row['lng']],
popup = row['Cafe'],
tooltip = row['Menu'],
icon = folium.Icon(
icon='coffee',
prefix='fa'
)
).add_to(mapping)
mapping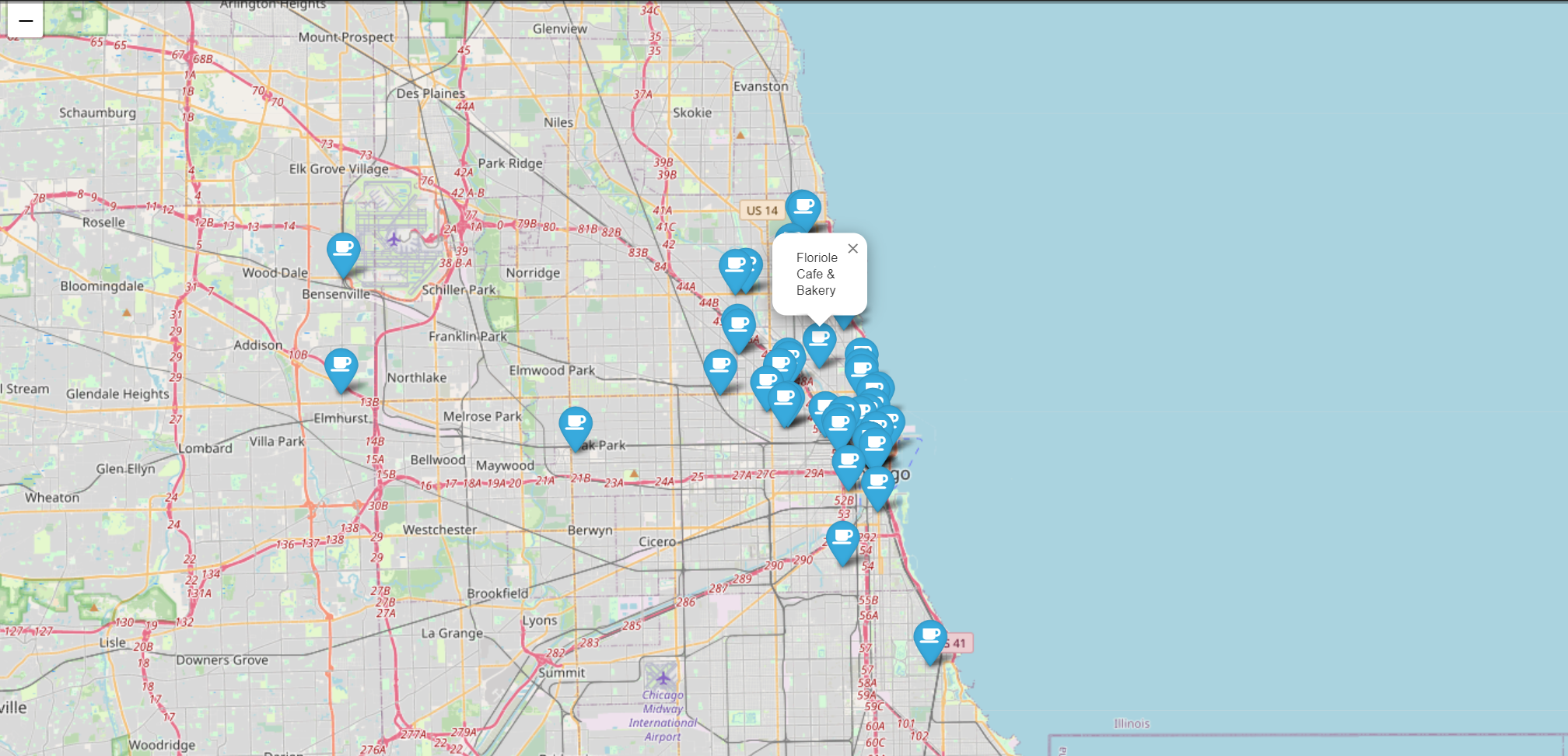
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
