통계분석은 주어진 자료를 체계적으로 정리하여 일정한 패턴을 발견하고 기본적인 특성을 밝히는 단계에서부터 출발한다. 그러나 체계적으로 정리되지 않은 자료는 한낱 한 무더기의 숫자 더미에 불과하다. 자료의 특성을 파악하고 의사결정자에게 의미있는 통계정보를 제공하기 위해서는 자료를 적절한 방법으로 일목요연하게 정리해야 한다.
# 모집단과 표본
통계학의 첫 단계는 자료를 수집하고 이를 분석하는 것이다.
이 때 구한 자료가 관심의 대상 전체인지 아니면 일부인지를 구분한다.
관심의 대상이 되는 모든 개체의 집단을 모집단(population)이라 하고, 관심 대상의 전체 중 일부를 표본(sample)이라 한다. 전 국민을 대상으로 5년마다 하는 인구 조사가 모집단 조사의 대표적인 예이다. 반면에 일부에게만 전화로 설문 조사하는 경우가 표본 조사의 예이다.
# 자료를 시각적으로 요약하기
정리되지 않은 채로 단순히 나열된 자료를 원자료(raw data) 혹은 미정리 자료라 한다.
원자료 속에 숨어있는 가치 있는 정보를 찾아내려면 원자료를 체계적으로 정리하는 것이 필요하다.
대표적인 수단으로는 표나 그림과 같이 시각적으로 요약하는 방법과 평균, 분산 등 자료의 특징을 수치로 표현하는 방법을 들 수 있다.
1. 도수분포표
도수분포표(frequency distribution table)란 자료를 적당한 구간으로 나누고, 각 구간에 포함된 자료의 수를 나타낸 표이다. 도수분포표에서 구간을 계급(class)이라 부르고, 각 구간에서 관찰되는 자료의 수를 도수(frequency)라 부른다.
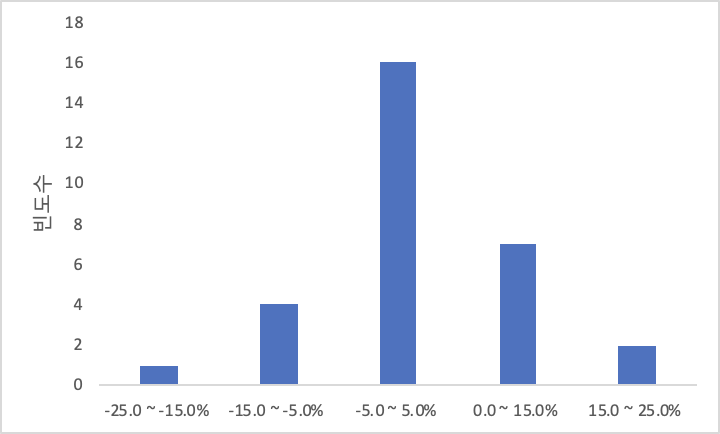
다음은 식료품 업종에 포함된 30개 종목의 연간 수익률을 조사한 도수분포표이다.
30개 종목의 (확장된) 도수분포표
| 계급(수익률 구간) | (절대)도수 | 상대도수 | 누적 (절대)도수 | 누적 상대도수 |
|---|---|---|---|---|
| -25.0 ~ -15.0% | 1 | 3.3% | 1 | 3.3% |
| -15.0 ~ -5.0% | 4 | 13.3% | 5 | 16.7% |
| -5.0 ~ 5.0% | 16 | 53.3% | 21 | 70.0% |
| 0.0 ~ 15.0% | 7 | 23.3 % | 28 | 93.3% |
| 15.0 ~ 25.0% | 2 | 6.7% | 30 | 100.0% |
| 합계 | 30 | 100% |
위의 표에서 볼 수 있는 것처럼, 관찰되는 자료 수가 전체 자료에서 차지하는 비율이 얼마인가 혹은 특정 계급 이하에 해당되는 자료의 비율은 얼마나 되는가 등에 관심을 갖기도 한다. 대표적인 것으로는 상대도수, 누적 절대/상대도수 등이 있다.
상대도수(relative frequency)란 한 계급의 도수가 전체 도수 중에서 차지하는 비율을 의미한다. 상대도수를 누적한 것을 누적상대도수(cumulative relative frequency)라 부르며, 혼동을 피하기 위해 누적도수를 누적절대도수(cumulative absolute frequency)라 부르기도 한다. 같은 이유로 도수는 절대도수(absolute frequency)라 부르기도 한다.
2. 히스토그램
도수분포표를 그림으로 표현하면 좀 더 시각적으로 보여줄 수 있다. 그중 가장 대표적인 것이 히스토그램이다.
히스토그램(histogram)은 자료를 적당한 구간으로 나누고, 각 구간에 포함되는 자료의 수를 막대그래프의 형태로 나타낸다.
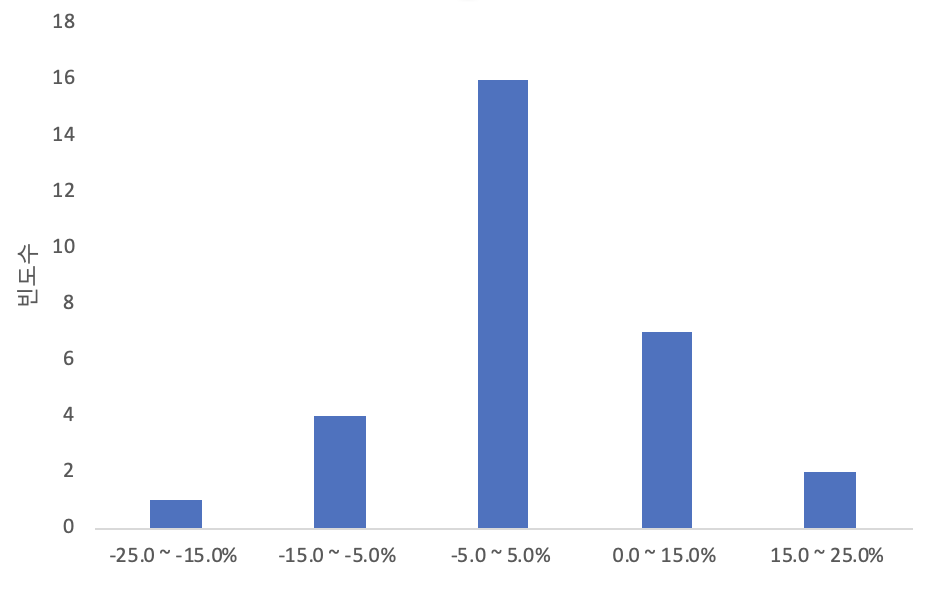
위의 그림은 위의 도수분포표를 히스토그램으로 표현한 것이다. 이 히스토그램을 보면 연간수익률의 분포와 평균 등을 어림잡을 수 있다. 예를 들어, 이 업종의 연간수익률은 어떤 구간에 가장 빈도가 많을까? 평균수익률은 대략 얼마가 될까? 등의 질문에 대해 간략하게나마 답할 수 있다. 즉 막대의 높이를 비교해 보면, 수익률이 -5.0~5.0% 사이에 해당하는 도수가 가장 많고, 5.0~15.0%, -15.0~-5.0%, ... 구간 순으로 분포되어 있음을 한 눈에 알 수 있다.
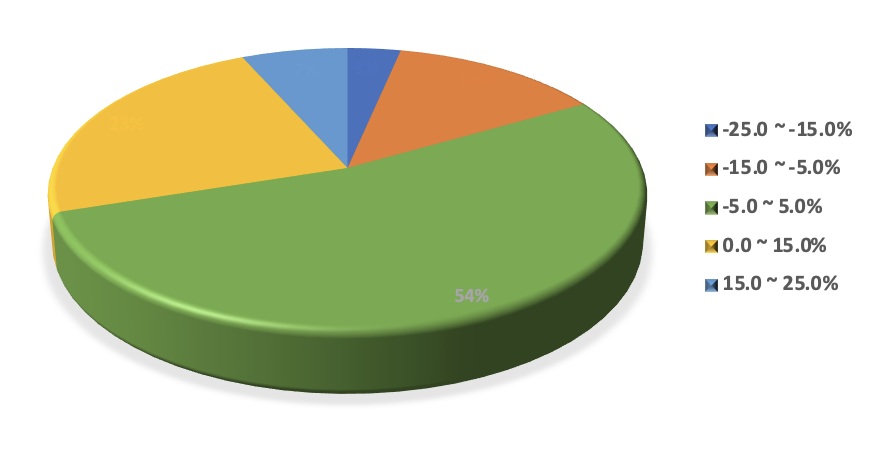
3. 여러 가지 형태의 그림
히스토그램 외에 분포를 시작적으로 나타내는 방안으로 원형그래프(pie graph)를 빼놓을 수 없다.
원형그래프는 도수를 막대가 아닌 파이 조각의 크기로 나타낸다.
자료의 분포를 시각적으로 표현할 때 자주 이용되는 방법으로 죤 튜키(John Tukey, 1977)가 제안한 줄기-잎 그래프(stem-and-leaf graph)를 들 수 있다. 줄기-잎 그래프는 먼저 줄기를 찾고 이어서 잎을 찾아 그리는데, 줄기는 흔히 잎을 나타내는 단위보다 큰 단위를 나타낸다.
예를 들어, 최고점이 99점인 성적자료를 분석하는 경우라면, 10단위의 숫자를 줄기에 표기하고, 1단위의 숫자를 잎에 표시한다. 줄기에 표시된 숫자를 크기가 작은 순으로 나열하고, 잎에 있는 숫자를 크기가 작은 순으로 나열하면 줄기-잎 그래프가 완성된다. 통계학 입문의 기말시험 성적과 이를 줄기와 잎 그래프로 나타낸 결과는 아래와 같다.
통계학 입문 기말시험 성적과 줄기-잎 그래프
[ 80, 91, 95, 76, 80, 93, 61, 79, 82, 85, 85, 90, 89, 86, 84, 88, 91 ]
| 줄기 | 잎 |
|---|---|
| 6 | 1 |
| 7 | 6 9 |
| 8 | 0 0 2 4 5 5 6 8 9 |
| 9 | 0 1 1 3 5 |
줄기-잎 그래프는 자료의 분포 뿐 아니라 특정값의 빈도나 순위도 알려준다. 예를 들어, 80점은 2명이며, 밑에서 4번째라는 사실도 알 수 있다. 위의 줄기-잎 그래프를 시계 반대방향으로 90도 회전하면 막대그래프와 유사해진다.
# 자료를 수치로 요약하기
히스토그램이나 도수분포표는 분포의 대략적인 모습을 파악하는 데 유용하지만, 계급의 구간 크기에 따라 결과가 크게 달라질 수 있는 단점이 있다. 즉 시각적 표현만을 사용하면 분포의 특성을 와전시킬 소지가 있다.
히스토그램이나 도수분포표의 이런 약점은 분포의 특성을 수치로 제시할 경우 해결할 수 있다.
그러나 이 때 어떤 면을 수치로 표현해야 자료의 생김새를 잘 표현할 수 있는가 하는 문제가 남아 있다.
자료의 생김새를 잘 표현할 수 있는 요소들에는 어떤 것들이 있을까?
이러한 요소들 중 분포를 대표하는 대푯값, 분포가 얼마나 흩어져 있는가를 나타내는 산포도, 분포의 대칭 정도를 나타내는 비대칭도 등을 꼽을 수 있다.
1. 대푯값
대푯값을 측정하는 방법은 크게 평균, 중앙값, 최빈값으로 나뉜다.
1.1 평균
평균에는 산술평균, 가중평균, 기하평균 등이 있다.
[ 산술평균 ]
산술평균(arithmetic mean, average)은 관찰집단 내의 모든 자룟값을 합한 후, 이를 자료의 개수로 나누어 얻는다. 산술평균은 모집단과 표본에서 다른 기호인 와 로 표기한다. 일반적으로 평균(mean)이라 하면 산술평균을 뜻한다.
산술평균
으로 구성된 표본의 산술평균 는 다음과 같다.
[ 가중평균 ]
가중치를 반영한 평균을 가중평균(weighted mean)이라 하고 로 표기한다.
가중평균
의 가중치가 이라 하면 가중평균 는 다음과 같다.
한 학생의 통계학 과목 퀴즈 점수는 90점, 90점, 80점이고, 중간시험과 기말시험 점수는 각각 60점, 80점일 때, 이 점수의 평균을 단순히 산술평균으로 구하면 80점[=(90+90+80+60+80)/5]이 된다. 그러나 이는 퀴즈와 정식 시험의 반영비율을 감안하지 않고 구한 평균이다. 만일 개별 퀴즈의 반영비율이 각각 10%씩이고, 중간시험과 기말시험의 반영비율이 각각 35%라면 이 학생의 최종 평균성적은 다음과 같이 75.0이다.
(0.1x90)+(0.1x90)+(0.1x80)+(0.35x60)+(0.35x80) = 75.0
[ 기하평균과 기하평균수익률(성장률) ]
투자액 10원이 첫해에 2배, 둘째 해에 8배가 되어, 결국 2년 후에는 160원이 되었다. 2년동안 16배가 된 것이며, 매년 평균 4배씩이 된 셈이다. 이 연평균 배수 를 기하평균(geometric mean)이라 부른다.
기하평균
으로 구성된 표본의 기하평균 는 다음과 같다.
즉,
경영학이나 경제학에서는 기하평균보다 기하평균수익률의 개념이 더 많이 사용된다. 위의 예에서 첫 해의 수익률은 100%, 둘째 해의 수익률은 700%이므로, 평균 수익률은 300%가 된다. 이 평균수익률이 기하평균수익률이다.
기하평균수익률
이 기간별 수익률이면, 다음 식을 만족하는 가 기하평균수익률이다.
1.2 중앙값(median)
중앙값(media)이란 관찰값을 크기순으로 나열한 후 가운데 위치한 자료의 값이다. 자료의 수 이 홀수이면 가운데 위치를 쉽게 찾을 수 있지만, 짝수이면 번째와 번째 자료의 산술평균을 중앙값으로 간주한다.
중앙값
으로 구성된 표본의 중앙값 median 다음과 같다.
예를 들어, [4, 5, 2, 9, 9]의 중앙값은 크기 순으로 정렬한 후 3번째인 5이고, [4, 5, 2, 9, 9, 7]의 중앙값은 크기 순으로 정렬한 후 3번째와 4번째 자료 5와 7의 산술평균인 6이다.
1.3 최빈값(mode)
도수가 가장 많은 자료의 값을 최빈값(mode)이라 한다. 자료 전체의 평균이나 중앙값이 아니라 가장 빈번하게 나타나는 자료의 값을 의미한다. 예를 들어, [4, 5, 2, 9, 9, 7]의 산술 평균과 중앙값은 모두 6이지만, 최빈값은 9이다. 9의 도수가 2로 가장 높기 때문이다.
1.4 산술평균, 중앙값, 최빈값의 비교
관찰된 모든 자료가 사용된다는 점이 산술평균의 장점이다.
산술평균 계산에 모든 관찰값이 사용되므로 산술평균은 모든 정보가 반영된 값이다.
[10, 20, 30, 40, 50] 과 달리 [10, 20, 30, 40, 10000] 과 같이 극단값이 존재하는 경우,
산술평균이 30에서 2020으로 70배 가까이 커진다. 산술평균이 대푯값의 역할을 하지 못하게 된다.
극단값으로부터 영향을 거의 받지 않는 값이 중앙값을 생각해볼 수 있다.
위의 두 경우 모두 중앙값은 30으로 동일하다.
이처럼 분포의 모양에 따라 산술평균, 중앙값, 최빈값의 상대적 위치가 달라진다.
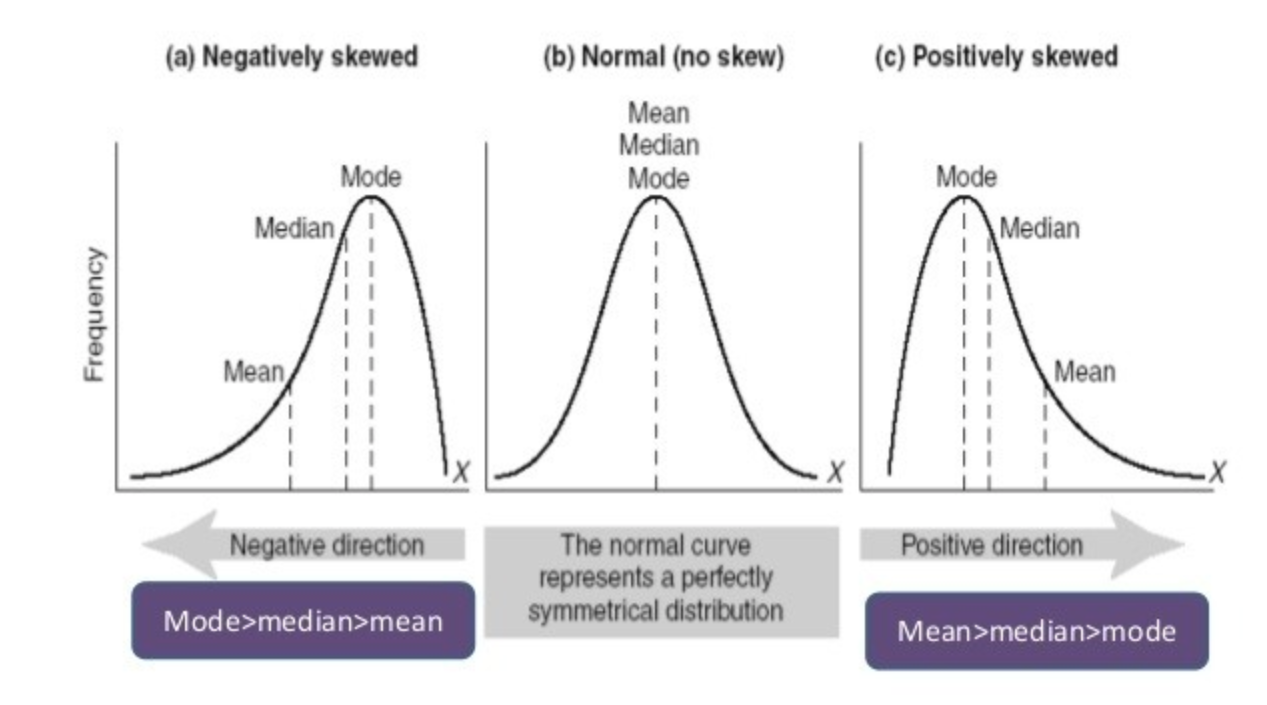
위의 왼쪽 그림과 같이 많은 데이타가 오른쪽에 몰려져 있는 경우, 좀 더 정확히는 왼쪽으로 꼬리가 긴 경우,
최빈값은 가장 오른쪽에, 중앙값은 가운데, 산술평균이 가장 왼쪽에 존재한다.
왼쪽으로 꼬리가 길어 산술평균이 왼쪽으로 치우쳐지기 때문이다.
위의 가운데 그림처럼 좌우대칭일 경우에는 산술평균, 중앙값, 최빈값이 모두 동일하다.
마지막으로 위의 오른쪽 그림과 같이 데이타가 왼쪽에 치우쳐져 있는 경우, 즉, 오른쪽으로 꼬리가 긴 경우,
위의 왼쪽 그림과는 반대로 최빈값이 가장 왼쪽에, 그 다음으로 중앙값, 산술평균이 가장 오른쪽에 존재한다.
# 2. 산포도
골퍼는 골프공을 얼마나 멀리 보낼 수 있을까에 관심을 갖고 있을 뿐 아니라 얼마나 정확하게 공을 보낼 수 있는가에도 관심을 갖는다. 프로골프 선수 중에서 어느 선수가 더 좋은 선수인가는 비거리보다는 공을 얼마나 정확하게 보내느냐에 결정되는 경우가 많다. 볼의 낙하지점이 핀 주변일수록 더 훌륭한 선수라 할 수 있다. 볼 낙하지점이 핀을 중심으로 넓게 퍼져 있을수록 산포도가 크다고 할 수 있으며, 일상적인 말로 정확도가 떨어진다고 표현할 수 있다.
산포도(dispersion)는 자료들이 흩어져 있는 정도를 나타낸다.
산포도를 측정하는 가장 간단한 방법부터 차례로 살펴보도록 하자.
2.1 범위
범위(range)란 자료 중에서 가장 큰 값(최댓값)과 가장 작은 값(최솟값)의 차이이다.
[3, 7, 9, 4]로 이루어진 자료의 범위는 최댓값(9)과 최솟값(3)의 차이인 6이다.
범위는 간단하게 측정할 수 있다는 장점이 있으나, 양극단의 값에 의해 결정되기 때문에 원자료의 분포를 반영하지 못하는 단점이 있다.
범위(range):
범위가 지니고 있는 단점을 해결하려면 모든 관찰점을 계산에 포함하면 된다.
즉, 자료들을 대표하는 중심점을 하나 정하고, 각 자료들이 이 중심점으로부터 어느 정도나 떨어져있는지를 수치화하는 것이다.
자료의 중심으로 (산술)평균 가 주로 이용된다.
임의의 관찰값 가 평균값 로부터 얼마나 멀리 있는가는 로 표현할 수 있는데, 이를 편차(deviation from the mean)라 한다. 편차가 음수이면 관찰값이 평균보다 작다는 뜻이고 양수이면 평균보다 크다는 뜻이다. 편차의 합은 항상 0이기 때문에 편차의 합을 산포도로 사용하기는 어렵다. 이를 해결하기 위한 가장 쉬운 방법이 편차에 절대값을 씌우거나 제곱하는 것이다.
2.2 평균절대편차
평균절대편차(mean absolute deviation, MAD)는 (산술)평균으로부터 관찰점까지의 평균거리를 측정한다.
평균절대편차(MAD):
2.3 분산
분산(sample variance)은 제곱된 편차의 평균이다. (은 표본의 자료 개수이다.)
분산은 모집단과 표본에서 다른 기호인 과 으로 표기한다.
표본분산의 분모는 대신 을 사용하는데, 분산의 정의에 따라 으로 나눈 표본의 분산()이 모집단의 분산()보다 만큼 작아지는 특성이 있기 때문이다. (이유는 나중에 나옴)
표본의 분산(표본분산):
예를 들어, [10, 20, 30]으로 구성된 표본의 평균절대편차(MAD)는 이고, 표본분산 =100 이다.
2.4 표준편차
표본의 표준편차(sample standard deviation)는 표본분산의 제곱근이다. 표준편차는 모집단과 표본에서 다른 기호인 와 로 표기한다.
표본의 표준편차(표본표준편차):
위의 [10, 20, 30]의 예에서 표본 분산은 100이였다. 따라서 표본표준편차는 10()이다.
2.5 평균절대편차, 분산과 표준편차
평균절대편차는 자료가 중심에서 얼마나 멀리 떨어져 있는가를 거리로 나타내므로 좋은 측정수단으로 보인다.
하지만 평균절대편차는 특정한 점(중심)에서 미분이 불가능하다. 이런 단점으로 수학적인 활용도가 떨어져 자주 사용하지 않으며, 미분이 가능한 분산이나 표준편차를 대신 사용한다.
분산은 산포도를 측정하는 수단 중 가장 빈번히 사용되고 있으나,
편차의 제곱의 평균인 분산의 값으로는 경우의 수가 많아 자료의 분포를 정확히 가늠하기 어렵다.
분산은 또한 원자료와 단위가 서로 달라 오해를 일으킬 수 있다.
예를 들어, 원자료의 단위가 라면 분산의 단위는 이 되어 면적으로 오해할 수 있다.
이러한 문제를 해소할 수 있는 방안으로 등장한 것이 표준편차이다.
표준편차는 분산의 제곱근이므로 원자료의 측정단위와 일치시킬 수 있다.
표본 [10, 20, 30]의 예를 다시 한 번 보도록 하자.
MAD=, , 로 표준편차 는 원자료의 단위와 동일하다.
2.6 분산과 표준편차의 활용
분산은 타 집단과 비교할 때 그 의미를 찾을 수 있다.
한국인과 미국인의 키 자료가 다음과 같다고 가정해 보자.
| - | 한국인 | 미국인 |
|---|---|---|
| (키의 평균) | 170 cm | 180 cm |
| (키의 분산) | 80 | 200 |
미국인 키의 분산 200은 그 자체로서 의미는 없지만 한국인 키의 분산 80과 비교하면 그 의미를 찾을 수 있다. 미국인 키의 분산이 더 크므로 미국인은 키가 큰 사람도 많고 작은 사람도 많은 반면, 한국인은 키가 비슷비슷하다는 뜻을 알려주고 있다.
또 다른 예로 금융 상품을 생각해보자.
수익률의 분산이 큰 상품일수록 위험도가 높고 작은 상품일수록 안전한 상품이란 의미이다.
2.7 분포에서 기준과 거리 표현
수량을 나타내는 자료는 모두 고유의 단위를 갖고 있다. 체중 자료는 kg을, 소요시간 자료는 분 혹은 시간 등과 같은 고유 단위를 갖고 있다. 이들은 공통된 특성을 가지고 있는데, 어떤 단위를 사용하든 0을 기준으로 고유 단위의 몇 배 위치에 있다는 형식으로 표시한다. 예를 들어, 170cm 는 기준 0으로부터 고유단위 1cm 의 170배 만큼 떨어져 있는 위치라는 의미이다.
통계분석에서는 0을 기준으로 하지 않고, 자료의 평균을 기준으로 삼는다.
그리고 고유 단위는 자료의 측정 단위 대신 표준편차를 사용한다.
예를 들어, 여대생 평균 신장이 162cm 이고 표준편차가 3cm 라면, 165cm 와 168cm 의 신장은 다음과 같이 평균과 표준편차로 표현할 수 있다.
,
통계분석에서의 기준은 (산술)평균, 고유단위는 표준편차를 사용한다. 즉, 는 다음과 같이 표현된다.
# 3. 기타지표
3.1 변동 계수
변동계수(coefficient of variation)의 정의는 다음과 같다.
표본의 변동계수:
먼저 1) [110cm, 120cm, 130cm] 로 이루어진 표본의 평균과 표준편차는 각각 이다. 다음으로 2) [10cm, 20cm, 30cm] 로 이루어진 표본의 평균과 표준편차는 각각 이다. 마지막으로 3) [1.1m, 1.2m, 1.3m] 로 이루어진 표본의 평균과 표준편차는 각각 이다.
위의 세 경우 모두 동일한 표준편차 값을 갖는다. 그러나 변동계수를 구해보면 1)과 3) 경우는 0.08로 동일한 반면, 2)의 경우는 0.5가 나온다. 2)의 변동계수가 앞의 1), 3)의 변동 계수보다 매우 크다. 동일한 표준편차라 하더라도 2)의 평균 값이 작아 '평균에 비해' 변동폭이 더 크기 때문이다. 즉, 변동계수는 평균 값 대비 변동폭 즉, 변동비율 이라 할 수 있다. 정리하면 다음과 같다.
- 표준편차는 측정 단위에 따라 값이 바뀌는 반면 변동계수는 측정 단위와 관계없이 일정하다.
- 표준편차는 자료의 '변동폭'에 대한 산포도인 반면, 변동계수는 '변동비율'에 대한 산포도이다.
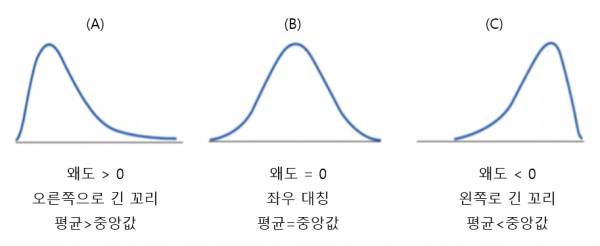
3.2 비대칭도(왜도)
자료가 정규분포를 따르는 경우 평균을 중심으로 좌우가 대칭(symmetric)이다. 그러나 자료의 분포가 대칭에서 벗어나 왼쪽이나 오른쪽의 한 쪽으로 기울어질 수 있는데 이를 비대칭이라 하며, 그 정도를 비대칭도(skewness, 왜도)라 한다. 비대칭도를 측정하는 방법은 두가지이다.
- 비대칭도:
- Pearson의 비대칭도:
위의 산술평균, 중앙값, 최빈값의 비교 섹션에서 설명했던 그림을 다시 보도록 하자.
아래의 왼쪽 그림은 오른쪽으로, 오른쪽 그림은 왼쪽으로 치우쳐져 있다.
좀 더 정확히 말하면, 왼쪽 그림은 왼쪽으로 긴 꼬리를, 오른쪽 그림은 오른쪽으로 긴 꼬리를 가지고 있다.
먼저 왼쪽 그림처럼 자료의 분포가 왼쪽으로 긴 꼬리를 가지고 있는 경우는 (산술)평균값이 중앙값보다 왼쪽에 자리한다. 따라서 Pearson의 비대칭도 값은 (-)이다.
비대칭도는 정규화 값으로 번째 자료 값 가 평균(mean)에서 멀수록 가중치가 크다. 왼쪽 그림처럼 왼쪽으로 긴 꼬리를 가지게 되면, 긴 꼬리 쪽에 존재하는 값들이 가중치가 높아 이들이 비대칭도의 부호를 결정하게 된다. 긴 꼬리 쪽에 해당하는 값들의 이므로, 왼쪽으로 꼬리가 길면 비대칭도는 (-)가 된다.
반대로 오른쪽 그림의 경우는 Pearson의 비대칭도와 비대칭도 모두 (+)가 된다.
(산술)평균값이 중앙값보다 크고, 오른쪽 꼬리 쪽의 값들이 비대칭도의 부호를 결정하기 때문이다.
정리하면 다음과 같다.
비대칭도는 긴 꼬리 쪽의 상대적 위치가 비대칭도의 부호를 결정한다. 또한 꼬리가 길수록 비대칭도의 절대값은 커진다.
오른쪽으로 긴 꼬리 긴 꼬리 쪽이 얇은 꼬리 쪽 값보다 상대적으로 값이 큼 비대칭도 (+)
오른쪽으로 더 긴 꼬리 ()의 값이 더 커짐 비대칭도의 절대값이 더 커짐
아래 왼쪽 그림처럼 오른쪽으로 긴 꼬리를 가지면 긴 꼬리 쪽이 얇은 꼬리 쪽 값보다 더 크므로 비대칭도는 (+),
오른쪽 그림처럼 왼쪽으로 긴 꼬리를 가지면 긴 꼬리 쪽 값이 얇은 꼬리 쪽 값보다 더 작으므로 비대칭도는 (-)가 된다.