통계학 기초 - 통계학 이해와 응용
1.통계학은?

test
2.자료의 요약
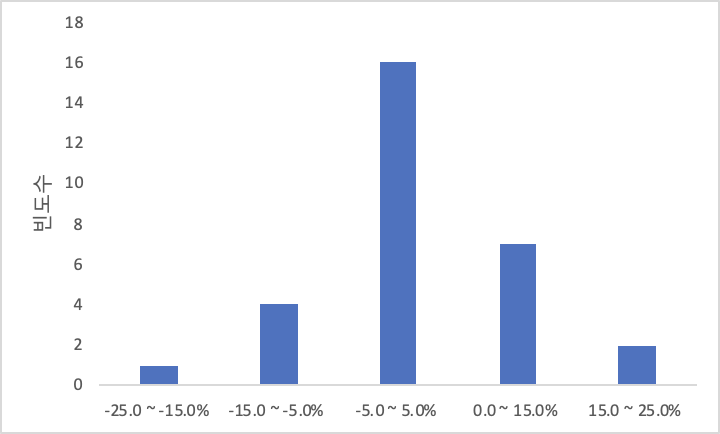
통계분석은 주어진 자료를 체계적으로 정리하여 일정한 패턴을 발견하고 기본적인 특성을 밝히는 단계에서부터 출발한다.
3.확률론
확률(probability)은 어떤 사건이 발생할 가능성의 정도를 0~1사이의 실수로 표현한 척도이다. 예를 들어, 내일 비가 올 확률이 40%라고 하면, 내일 비가 올지 안 올지 정확하지는 않으나 40%의 가능성으로 비가 올 것 같다는 의미이다. 통계학은 불확실한 상
4.확률분포
대학 진학을 앞둔 고등학교 3학년 학생의 경우를 생각해보자. 자신의 수능 점수가 상위 몇 %에 속하냐에 따라 지원 대학과 학과가 결정된다. 그러므로 자신의 수능점수 보다는 전체 학생들의 수능점수 분포에서 자신의 점수가 어디에 위치하고 있는지를 아는 것이 더 중요하다.
5.대표적인 확률분포 유형 - 이산확률분포
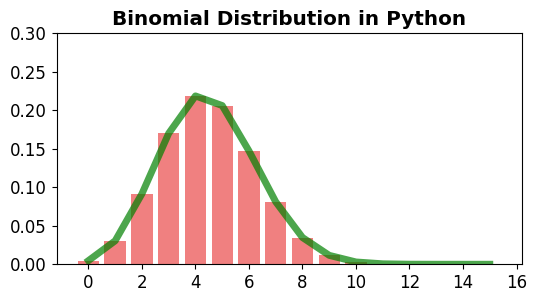
이번 장에서는 몇 가지 정형화된 확률분포를 공부한다. 확률분포는 크게 이산확률분포와 연속확률분포로 나뉜다. 이산확률분포로는 이산균등분포, 이항분포, 초기하분포, 포아송분포가 있으며,연속확률분포로는 연속균등분포, 정규분포, 표준정규분포가 있다. 주사위를 던질 때 윗면에
6.대표적인 확률분포 유형 - 연속확률분포
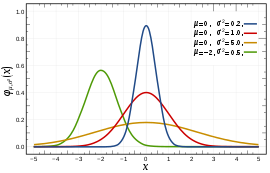
연속균등분포(continuous uniform distribution)는 확률밀도가 일정한 분포이다. 확률변수 $X$가 구간 a, b에서 연속균등분포를 따르면 $X \\sim Ua,b$라 표기한다. 연속균등분포의 확률밀도함수, 기댓값, 분산$f(x) = \\begin{
7.모수와 통계량의 관계: 표본분포
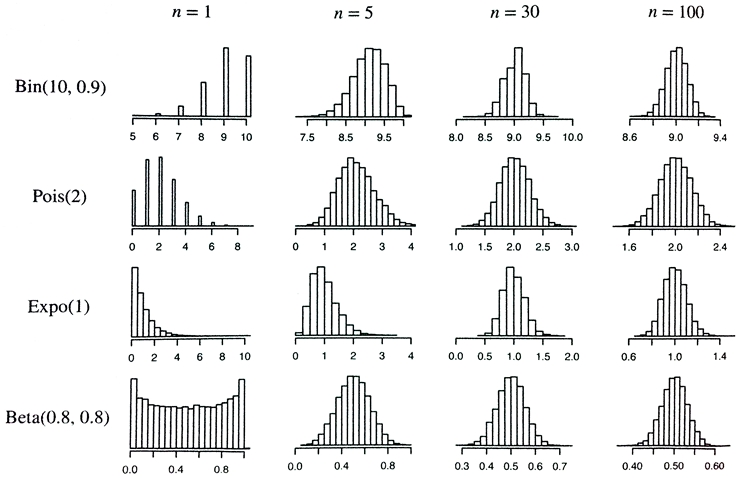
자료의 평균, 분산, 분포 모양 등 자료의 특성을 분석하는 학문 분야를 기술통계학(descriptive statistics)이라 한다. 반면에 주어진 자료 자체를 분석하는 것이 아니라 이 주어진 자료를 이용하여 모집단이 어떻게 생겼는가를 추론하는 학문 분야를 추리통계학
8.추정: 모집단이 하나인 경우
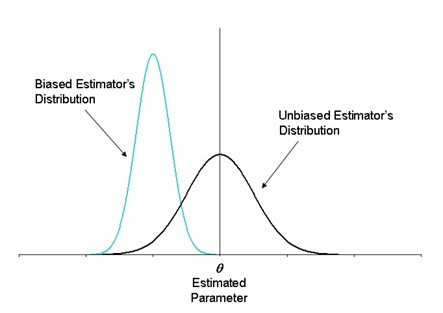
앞 장에서 배운 모집단 모수와 표본 통계량 간의 통계적 관계를 이용하여 표본으로부터 모수를 추정하는 방법들을 배워보도록 하자. 직장인의 평균 근무 시간을 파악하기 위해 한 무리의 직장인을 대상으로 근무시간을 조사하였다. 이들의 근무 시간을 근거로 우리나라 전체 직장인의