앞 장에서 배운 모집단 모수와 표본 통계량 간의 통계적 관계를 이용하여 표본으로부터 모수를 추정하는 방법들을 배워보도록 하자.
I. 점추정과 구간추정
직장인의 평균 근무 시간을 파악하기 위해 한 무리의 직장인을 대상으로 근무시간을 조사하였다. 이들의 근무 시간을 근거로 우리나라 전체 직장인의 평균 근무시간을 추정한 결과로 다음의 세 경우를 생각해 볼 수 있다.
8.5시간
7.8시간부터 9.2시간 사이
7.0시간부터 10.0시간 사이
위의 1. 은 하나의 값으로 추정한 반면, 2. 와 3. 은 구간으로 추정했다. 1. 과 같이 하나의 값으로 추정한 경우를 점추정(point estimation)이라 하고, 2.와 3.과 같이 구간으로 추정한 경우를 구간추정(interval estimation)이라 한다. 2.와 3.은 모두 구간추정이라는 공통점이 있으나 구간의 크기가 다르다.
점추정이 구간추정에 비해 단순하기 때문에 방송이나 신문에서는 점추정 결과를 발표는 경우가 많다. 그러나 구간추정을 간접적으로 내포하는 경우가 흔하다.
설문 조사 결과, ... 향후 경제상황에 대한 질문에서도 50%가 지금보다 더욱 악화될 것이라는 ... 이번 조사는 전국 만 19세이상 ... 신뢰수준 95%에 오차한계는 ±3.5%p 이다.
이 기사를 보면 점추정값인 50%만을 제시한 것처럼 보이지만 '오차한계는 ±3.5%p'라 함으로써, 50%±3.5%p, 즉 구간추정 [46.5%, 53.5%]를 제시한 셈이다.
II. 점추정
모집단 모수의 추정은 표본의 자료를 추정공식에 대입시켜 구한다. 이 때 추정공식을 추정량(estimator)이라 하고 이 공식에 따라 계산된 수치를 추정값(estimate) 또는 추정치라 한다. 직장인의 근무 시간을 추정할 때 추정 공식으로 n∑i=1nXi를 사용하고, 계산결과가 8.5시간이라면 추정 공식인 n∑i=1nXi는 추정량이고 8.5시간은 추정값이다.
모집단 평균 μ의 추정량(즉 추정공식)으로 n∑i=1nXi 가 일반적으로 사용되나 다른 다양한 추정량도 생각해볼 수 있다. 예를 들어, 중앙값이나 최빈값 또는 (최솟값+최댓값)/2 등이다. 그러면 여러 추정량 중에서 어떤 것이 좋은 추정량일까? 다음을 살펴보자.
모수를 θ, 추정량을 θ^라 할 때, 표본추출오차는 θ^−θ이다. 이들의 기대값은 0이므로, 표본추출오차의 크기는 E[(θ^−θ)2]으로 측정한다. 이를 평균제곱오차(mean squared error, MSE)라 부른다. E[(θ^−θ)2]은 E(θ^)를 더하고 빼주어 다음과 같이 정리된다. (여기서 θ^는 추정량 이긴하나, 하나의 표본 x 로부터 얻어지는 추정값 θ^(x)로 해석된다. 또한 θ^는 표본에 따라 값이 달라질 수 있으므로 확률변수로 볼 수 있다. 따라서 E(θ^) 또한 정의된다. E(θ^)는 모든 표본으로부터 얻어질 수 있는 추정값들의 평균이므로 추정시에는 θ^ 보다는 E(θ^)의 의미가 더욱 중요하다.)
위의 식에서 볼 수 있듯이 θ^이 좋은 추정량이 되려면 E[(E(θ^)−θ)2]과 Var(θ^) 의 값이 작아야 한다. 첫째 항 E[(E(θ^)−θ)2]의 최솟값은 0이고, 이 상태를 편향되지 않은 상태 '불편성'(unbiased)이라 한다. 의미적으로는 기대되는 추정값이 모수와 동일함을 의미한다. 둘째항 Var(θ^) 역시 작을수록 좋은데, 이 항의 값이 가장 작은 상태를 '효율성' 이라 한다. 좋은 추정량이 가져야 할 조건 중에 '일치성'이 있는데, 이는 아래에서 설명하도록 한다.
결국 좋은 추정량이 되기 위한 조건은 다음과 같이 세 가지이다.
불편성(unbiasedness)
효율성(efficiency)
일치성(consistency)
이제 각 조건에 대해 공부해보자.
1. 불편성(unbiasedness)
θ를 모수로 하고, θ^를 추정량이라 하면 불편성(unbiasedness)은 다음과 같이 정의된다.
다음의 조건을 불편성이라 한다. E(θ^)=θ
이 조건을 만족하는 θ^를 불편추정량(unbiased estimator)이라 부른다.
(좀 더 의미적으로 해석하면 모수로부터 멀어지지 않은 '불편향' 추정량이라 할 수 있다.)
앞 장에서 배운 표본평균, 표본분산, 표본비율은 모두 위의 '불편성'을 만족하므로 각각 모평균, 모분산, 모비율의 불편추정량임을 알 수 있다. 즉,
E(Xˉ)=μ,E(S2)=σ2,E(P^)=p
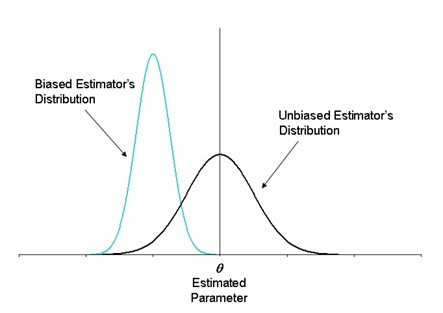
불편성을 만족한다는 의미는 추정량의 기대값이 모수와 동일하여 '추정된 값이 모수와 동일할 가능성이 높다'는 것을 의미한다. 아래 그림을 보도록 하자. 아래 그림의 검정색과 하늘색 그래프 각각은 자신들의 추정량(θ^1,θ^2)에 근거하여 모든 표본에 대하여 추정된 값들을 그래프로 나타낸 것이다. 아래 그림에서 볼 수 있는 것처럼 검정색 그래프의 기대값(E(θ^1))은 모수(θ)와 동일하지만, 하늘색 그래프의 기대값(E(θ^2))은 모수와 동일하지 않다. 따라서 θ^1은 불편추정량이고, θ^2는 편의추정량이다. 그림에서도 확인해볼 수 있듯이 모수(θ)를 추정한다고 할 때, θ^2보다는 θ^1이 좀 더 우수한 추정량임을 알 수 있다.
실제적인 예로 평균이 0이고 분산이 1인 정규분포를 따르는 모집단에서 표본(n=2)을 추출한 경우, S2=[n−1∑i=1n(Xi−Xˉ)2] 과 Q2=[n∑i=1n(Xi−Xˉ)2] 에 대한 분포를 각각 그려보면, S2 분포의 평균이 1인 반면, Q2 분포의 평균은 0.5임을 확인할 수 있다. 따라서, S2은 불편추정량, Q2은 편의추정량이다.
2. 효율성(efficiency)
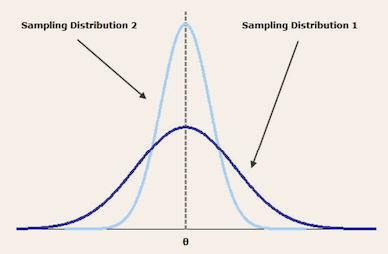
아래의 그림을 먼저 보도록 하자. 아래 보라색 그래프와 하늘색 그래프는 모두 불편추정량이다. 보라색 그래프의 추정량을 θ^1, 하늘색 그래프의 추정량을 θ^2라 할 때, Var(θ^1)>Var(θ^2) 임을 알 수 있다. 두 추정량 중에서는 하늘색 그래프가 분산이 더 적어 모수를 좀 더 잘 추정할 수 있음을 알 수 있다. 이처럼 불편성을 만족하면서 분산이 가장 작은 경우를 효율성(efficiency)라고 한다.
불편성을 만족하면서 최소의 분산을 가진 경우를 효율성이라 한다.
3. 일치성(consistency)
어떤 추정량이 불편성을 만족하지 못한다 할지라도 표본크기가 증가함에 따라 모수에 수렴한다면, 이 추정량은 대표본 (즉, 표본의 크기가 큰 경우) 좋은 추정량이 될 수 있다. 이를 일치성(consistency)이라 한다.
다음의 조건을 일치성이라 한다.
임의의 ϵ에 대해 limn→∞p(∣θ^−θ∣<ϵ)=1
위에서 예시로 든 Q2=[n∑i=1n(Xi−Xˉ)2]이 이 일치성을 만족한다. 표본의 크기가 커질수록 E(Q2)=E(S2)=σ가 된다. 이 외에도 n−1∑Xi, n∑Xi+n1 등은 μ 의 추정량으로 불편성을 만족하지 않으나 일치성을 만족한다.
III. 모평균 μ에 대한 구간 추정
위의 II. 장에서 살펴본 것처럼, 모평균 μ를 추정하기 위한 가장 대표적인 추정량인 표본평균 Xˉ은 좋은 추정량이 되기 위한 세 조건을 모두 만족한다. 여기서는 표본평균 Xˉ를 이용하여 모평균 μ에 대한 구간추정 방법을 알아보도록 한다.
1. 구간 추정의 원리
구간추정(interval estimation)은 모수를 구간으로 추정한다. 구간으로 추정할 때 어려운 문제는 구간의 크기를 정하는 일이다. 구간 크기는 다음의 두가지 요인에 의해 결정된다. 첫 번째 요인은 불확실성 정도이다. 일년 후의 GDP를 예측하는 경우는 비교적 작은 구간으로 추정할 수 있는 반면, 50년 후의 GDP는 불확실성이 높아 추정 구간이 커질 수 밖에 없다. 두 번째 요인은 어느 정도의 확률로 모평균이 추정구간 안에 있게 할 것인가이다. 첫 번째 요인은 외부환경에 의해 결정되는 것으로 분석가가 통제할 수 있는 사항이 아닌 반면, 두 번째 요인은 분석가 스스로 결정할 사항이다. 그러므로 분석가는 두 번째 요인을 조절하여 구간 크기를 결정한다.
모수가 추정구간 안에 있을 확률을 신뢰수준(confiedence level)이라 하는데, 이 수준에 의해 추정구간의 크기가 결정되므로 구간 추정을 신뢰구간추정(confidence level estimation)이라고도 한다.
신뢰수준이 1−α로 정해지면 추정된 구간 [a,b]는 다음과 같은 특성을 갖는다. P(a<θ<b)=1−α
이 때 추정된 구간 [a,b]를 신뢰구간이라 한다. 100(1−α)%의 확률로 모수 θ가 구간 [a,b]내에 있음을 뜻하며, '모수 θ에 대한 100(1−α)% 신뢰구간은 [a,b]이다' 라고 표현한다.
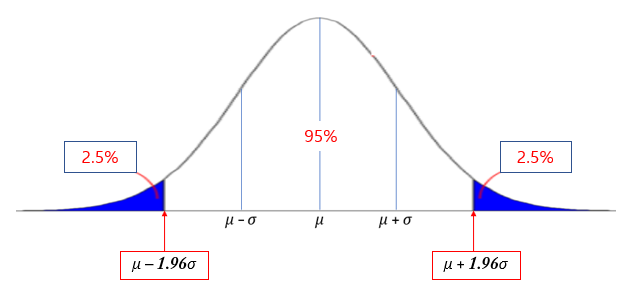
우선 신뢰수준이 95%인 신뢰구간을 찾아보자. Xˉ가 정규분포를 따른다면 Xˉ∼N(μ,nσ2), Xˉ의 분포는 아래와 같다.
Xˉ가 정규분포를 따를 때, Xˉ가 μ−1.96σXˉ와 Xˉ가 μ+1.96σXˉ 사이에 존재할 확률이 95%이므로 다음과 같이 표현할 수 있다.
P(μ−1.96σXˉ<Xˉ<μ+1.96σXˉ)=0.95
이 식을 μ에 대한 구간으로 바꾸면 다음과 같다.
P(Xˉ−1.96σXˉ<μ<Xˉ+1.96σXˉ)=0.95
신뢰구간의 정의에 따라, 하나의 표본으로부터 얻어진 표본평균 xˉ에 대해, [xˉ−1.96σXˉ,xˉ−1.96σXˉ]은 신뢰수준이 95%인 신뢰구간이 된다.
신뢰구간을 일반화하면 다음과 같다.
점추정값 xˉ에 대하여 신뢰수준 100(1−α)%인 신뢰구간 [a,b]는 다음과 같다.
[xˉ−z2ασXˉ,xˉ+z2ασXˉ]
2. 모평균 μ의 구간추정: 모집단 분산 σ2을 아는 경우
모평균 μ의 신뢰수준 100(1−α)%인 신뢰구간은 [xˉ−z2ασXˉ,xˉ+z2ασXˉ]이다. 모집단 분산 σ2을 알고 있으므로, σXˉ=nσ이 되므로 신뢰구간은 다음과 같다.
σ2을 알 때, 모평균 μ에 대한 100(1−α)% 신뢰구간은 다음과 같다.
[xˉ−z2ασXˉ,xˉ+z2ασXˉ] = [xˉ−z2α(nσ),xˉ+z2α(nσ)]
Xˉ가 정규분포이거나 정규분포에 근사한 경우에만 이 공식을 사용할 수 있다는 점에 유의하자.
예제) 경기도에 소재한 영세기업의 월매출액을 조사해보니 분산 360,000(표준편차는 600)인 정규분포를 따른다는 사실을 알았다. 25개의 영세기업을 임의로 선정하여 평균 월매출액을 계산해보니 xˉ=2,500,000원이었다. 1) 모집단 평균에 대한 90% 신뢰구간을 구하시오. 2) 모집단 평균에 대한 95%의 신뢰구간을 구하시오.
1) 모집단 μ에 대한 90% 신뢰구간은 [xˉ−1.645⋅25600,xˉ+1.645⋅25600]
2) 모집단 μ에 대한 95% 신뢰구간은 [xˉ−1.96⋅25600,xˉ+1.96⋅25600]
3. 모평균 μ의 구간추정: 모집단 분산 σ2을 모르는 경우
모평균 μ를 알지 못하는 상황이라면 모분산 σ2도 모르는 경우가 많다. σ2를 모른다면 이의 추정량인 S2을 사용해볼 수 있다. 그러나 이 통계량은 더 이상 표준정규분포를 따르지 않고, 자유도(degrees of freedom)가 n−1인 t 분포를 따른다.
Xˉ∼N(μ,nσ2) 이면, T=S/nXˉ−μ∼tn−1
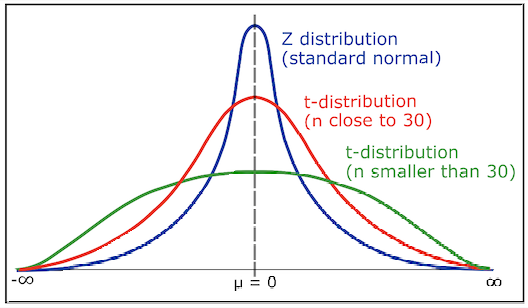
아래 그림은 표준정규분포와 t-분포를 보여주고 있다.
t-분포는 표준정규분포와 유사하나 대체적으로 꼬리가 더 두껍다. 자유도(n값에 의해 결정)가 낮을수록 분산이 커지고 자유도가 높을수록 표준정규분포와 유사해진다. 대체적으로 n이 30이상이면 두 분포의 차이가 미미하다고 판정하고 있다. t2α 또한 표준정규분포와 같이 표나 엑셀을 이용해서 값을 찾아낼 수 있다.
σ2을 모를 때, 모평균 μ에 대한 100(1−α)% 신뢰구간
1) n<30 인 경우, [xˉ−t2α(ns),xˉ+t2α(ns)]
2) n≥30 인 경우, [xˉ−t2α(ns),xˉ+t2α(ns)] 또는 [xˉ−z2α(ns),xˉ+z2α(ns)]
IV. 모비율에 대한 구간추정
모비율 p와 표본비율 Pˉ의 통계적 관계를 정리하면 다음과 같다.
E(P^)=E(nX)=nE(X)=p Var(P^)=Var(nX)=n2Var(X)=np(1−p) P^ 또한 표본평균의 개념이므로 n이 충분히 크면, P^의 분포는 정규분포에 근사한다. 대체적으로 np≥10,np(1−p)≥10 일 경우 P^는 정규분포에 근사한다.
위에서 설명한 바와 같이 신뢰구간은 [p^−z2ασP^,p^+z2ασP^] = [p^−z2αnp(1−p),p^+z2αnp(1−p)] 이다. 그러나 p 값을 알지 못하므로 분산인 np(1−p) 값 또한 알지 못한다. 따라서 표본이 충분히 큰 경우에 한하여 p 대신 p^를 아래와 같이 신뢰구간을 추정한다. 만약 표본크기가 작으면 P^의 분포를 모르므로 신뢰구간을 추정할 수 없다.
모비율 p에 대한 100(1−α)% 신뢰구간 (표본이 충분히 큰 경우)
[p^−z2αnp^(1−p^),p^+z2αnp^(1−p^)]