자료의 평균, 분산, 분포 모양 등 자료의 특성을 분석하는 학문 분야를 기술통계학(descriptive statistics)이라 한다. 반면에 주어진 자료 자체를 분석하는 것이 아니라 이 주어진 자료를 이용하여 모집단이 어떻게 생겼는가를 추론하는 학문 분야를 추리통계학(inferential statistics)이라 한다. 이 때 주어진 자료를 표본(sample)이라 부른다.
모집단의 특성(예를 들어 평균, 분산)을 수치로 나타낸 것을 모수라 하며, 표본의 특성을 수치로 나타낸 것을 통계량이라 한다. 표본으로부터 모수에 대해 추론하려면 통계량과 모수 간의 통계적 관계를 파악해야 가능하다. 이번 장에서는 이런 통계적 관계를 분석한다.
I. 모집단과 표본
1. 모집단과 표본의 구분
어느 제약회사가 진통 기간이 긴 신약을 개발했는데, 치통 환자를 대상으로 진통시간이 얼마나 되는지 조사하려고 한다. 치통 환자 전체를 대상으로 진통 시간을 조사하는 것이 불가능하여 일부를 대상으로 진통 시간을 조사하기로 하였다. 이처럼 관심의 대상이 되는 모든 개체의 집합을 모집단(여기서는 모든 치통 환자의 진통 시간)이라 하고, 실제 분석의 대상이 된 개체의 집합을 표본(여기서는 일부 치통 환자의 진통시간)이라 한다. 이 예제에서 개체란 진통 시간을 말한다.
모집단의 특징을 묘사하는 요소에 모평균 , 모분산 등이 있는데, 이들을 모수(parameter)라 한다. 반면에 표본의 특징을 묘소하는 요소에 표본평균 , 표본분산 등이 있고, 이들을 통계량(statistic)이라 한다.
2. 표본조사
모집단의 모든 개체에 대한 자료를 수집하는 행위를 전수조사(census)라 한다. 인구주택총조사나 징집 대상자를 대상으로 실시하는 신체검사 등이 있다. 반면에 모집단의 일부인 표본만을 대상으로 자료를 수집하는 행위를 표본조사(sample survey)라 부른다. 표본조사를 실시하는 이유는 다음과 같다.
- 경제성 - 비용이 적게 듦
- 시간절약 - 단기간에 수행 가능
- 정확성 - 전수보다 더 정확하고 세밀하게 조사 가능
- 전수조사가 불가능한 경우 -
모집단이 너무 크거나 모집단을 파악하기 어려운 경우
통조림 위생 점검과 같이 조사 대상의 파괴가 동반되는 경우 - 민감한 정보를 수집하는 경우
3. 표본 추출 방법
모집단으로부터 표본을 선택하는 행위를 표본추출(sampling)이라 한다. 표본추출 방법은 크게 확률적 추출(probability sampling)과 비확률적 추출(non-probability sampling)로 나뉜다.
[ 확률적 추출 ]
| 이름 | 추출 방법 |
|---|---|
| 단순무작위 추출 (simple random sampling) | 개의 모집단 개체에서 를 추출할 경우, 개별 개체가 선택될 확률은 모두 으로 일정 |
| 체계적 추출 (systemic sampling) | 특정 추출 알고리즘을 활용하여 기계적으로 추출 예) 모집단 개체 각각에 1~까지의 번호를 붙이고 일정 번호 간격으로 표본 요소를 추출 |
| 층화추출 (stratified sampling) | 모집단을 일정 군집이나 계층으로 나누고, 각 집단에서 일정 비율의 표본 요소를 추출 |
| 군집추출 (cluster sampling) | 모집단을 특성에 따라 여러 집단으로(cluster)으로 나눈 후, 이들 일부 집단에서만 일정 비율의 표본 요소를 추출 |
[ 비확률적 추출 ]
| 이름 | 추출 방법 |
|---|---|
| 판단추출 (judgement sampling) | 연구자 판단에 따라 표본 요소를 선택 예) 소비자 물가지수, 생산자 물가지수 |
| 할당추출 (quota sampling) | 모집단을 일정 군집이나 계층으로 나누고, 연구자의 판단에 따라 각 집단에서의 표본 수를 결정 |
| 편의추출 (convenience sampling) | 연구자가 쉽게 접근할 수 있는 표본 요소를 선택 예) 자신이 소속한 병원의 암환자를 대상으로 실험 |
확률적 추출은 표본추출의 과정에 표본요소를 무작위로 선택하는 과정이 포함된다. 반면 비확률적 추출은 연구자의 편견이 결과를 좌우하기 때문에 통계학의 표본분포 이론을 적용할 수 없는 단점이 있다. 그러나 모집단에 대한 개략적인 정보가 신속히 필요하거나 조사 대상이 비협조적일 때 적용할 수 있는 장점이 있다.
II. 표본평균과 모수의 통계적 관계
1. 간단한 사례
통계량과 모수 중 하나인 표본평균()와 모평균()의 관계를 파악하기 위해 간단한 예로 출발하자.
항아리에 10, 20, 30 이라고 쓰인 구슬이 3개 있다. 이 항아리의 숫자를 모집단이라고 하면, 모집단의 평균 이고, 분산 이다. 이제 이 모집단에서 표본크기 인 표본을 추출해 보자. 표본 추출은 꺼낸 구슬을 다시 항아리에 집어넣은 후에 다음 구슬을 꺼내는 복원추출(sampling with replacement) 방식을 사용한다. 이 방식으로 추출하면 10, 20, 30이 꺼내질 확률은 동일하게 1/3이 된다. 반면에 꺼낸 구슬을 항아리에 넣지 않고 두 번째 구슬을 꺼내는 경우를 비복원추출(sampling without replacement)이라 한다.
표본크기를 2로 하여 복원추출 방식으로 표본을 추출할 경우 아래와 같이 9개의 표본이 1/9 확률로 나타난다.
| 표본 | 표본평균() | 확률 |
|---|---|---|
| (10, 10) | 10 | 1/9 |
| (10, 20) | 15 | 1/9 |
| (10, 30) | 20 | 1/9 |
| (20, 10) | 15 | 1/9 |
| (20, 20) | 20 | 1/9 |
| (20, 30) | 25 | 1/9 |
| (30, 10) | 20 | 1/9 |
| (30, 20) | 25 | 1/9 |
| (30, 30) | 30 | 1/9 |
위의 표를 근거로 표본평균()의 확률분포표를 만들면 다음과 같다.
| 표본평균() | 확률 |
|---|---|
| 10 | 1/9 |
| 15 | 2/9 |
| 20 | 3/9 |
| 25 | 2/9 |
| 30 | 1/9 |
확률변수 의 표본분포를 이용하여 평균인 를 계산해보자.
이 수치는 모집단 평균 의 값과 일치한다. 이는 과 이 다르더라도 동일한 관계가 유지된다.
(증명)
이제 표본평균 의 분산, 를 계산해보자.
으로 모집단의 분산 을 표본 수 로 나눈 값과 동일하다.
이 관계는 과 이 다르더라도 동일한 관계가 유지된다.
(증명)
참고로, 비복원 표본추출의 경우는 다음과 같다.
(증명) 를 이용.
비복원 추출의 경우 표본 평균에 대한 확률분포표를 만들면 다음과 같다.
복원 추출의 경우보다 표본 평균의 분산이 작아짐을 알 수 있다. 크고 작은 값이 더 적게 나오기 때문이다.
| 표본 | 표본평균() | 확률 |
|---|---|---|
| (10, 20) | 15 | 1/6 |
| (10, 30) | 20 | 1/6 |
| (20, 10) | 15 | 1/6 |
| (20, 30) | 25 | 1/6 |
| (30, 10) | 20 | 1/6 |
| (30, 20) | 25 | 1/6 |
위의 표를 이용하여 를 구해보면 다음과 같다.
위의 식에서 인데, 이 값은 복원 추출의 경우에서 얻어낼 수 있다.
복원 추출의 경우에 이므로, 이다.
또한, 이므로, 이 된다.
비복원 추출로 다시 돌아가서,
이 된다.
따라서,
2. 와 의 구분
는 모든 가능한 표본들의 표본 평균을 구하고, 이들의 분산을 구한 값이다.
반면 은 특정 표본 하나에서 얻어지는 표분 요소들의 분산을 의미한다.
예를 들어, 통계량을 구하기 위해 크기가 인 표본 하나를 얻어냈었다고 가정하자.
이들 개의 평균과 분산이 각각 , 이다.
반면, 크기가 개인 모든 표본 각각에 대해서 평균 를 구하고, 다시 이들 표본 평균들에 대한 평균과 분산을 구한 값이 , 이다.
3. 표본추출오차
가 175가 나오면 이를 근거로 모평균 를 175라고 추정한다. 이 때 실제 모평균 가 170이라면 5만큼의 오차가 발생하게 된다. 이 오차는 표본추출로 인해 발생했기 때문에 이를 표본추출오차(sampling error)라 한다.
표본추출오차 = 통계량(statistic) - 모수(parameter)
표본추출오차는 (-)가 나올 수 있으므로 표본추출오차의 기대값은 표본추출오차를 제곱한 후 얻어낸다.
표본추출오차의 크기는 위의 식에서 볼 수 있는 것처럼 두 가지 요인의 영향을 받는다.
첫째, 표본 크기 이다. 표본 크기가 커질수록 표본추출오차가 작아진다. 여론조사를 진행할 경우, 100명을 조사하는 것보다는 10,000명을 조사해야 여론을 더 정확하게 추정할 수 있다.
둘째, 모집단의 표준편차이다. 모집단의 불확실성이 높을수록 오차가 클 가능성이 크다.
4. 표본평균의 분포 모양
표본평균의 분포 모양에 대해서는 아주 간략히 설명한다.
-
모집단이 정규분포를 따르는 경우
표본평균 는 표본 크기에 관계없이 정규분포를 따른다. -
모집단이 정규분포를 따르지 않는 경우
모집단이 정규분포를 따르지 않을 때는 표본평균의 분포가 1) 모집단의 크기 2) 표본 크기에 영향을 받는다. 표본의 크기 이 동일할 때, 모집단의 크기 이 클수록 표본평균 의 분포가 좀 더 정규분포와 유사해짐을 확인할 수 있다. 또한 모집단의 크기 이 동일할 때는 아래 그림에서처럼 표본 크기가 커질수록 표본 평균 의 분포가 정규분포와 유사해짐을 유추할 수 있다.
일반적으로 표본을 추출할 경우에는 모집단의 크기 이 어느 정도 크다는 것을 가정하므로, 모집단이 정규분포를 따르지 않는 특이한 분포라 하더라도 표본 의 크기가 커지면 표본 평균 의 분포는 정규분포와 유사해진다. 이 논리는 중심극한정리(central limit theorem)의 기초가 된다. 대부분의 통계학 책에서는 '충분히 큰' 표본의 크기 의 기준으로 30을 제시하고 있다.
[중심극한정리]
무한모집단에서 표본이 커지면 표본평균 의 분포는 정규분포로 수렴한다.
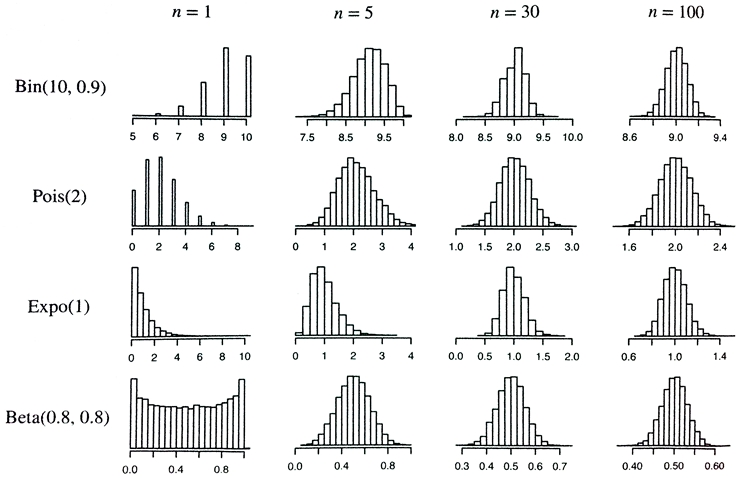
- 모집단이 정규분포를 따르지 않고 표본크기가 30미만인 경우
표본 크기가 작으면 표본평균의 분포가 정형화된 패턴을 보이지 않고 모집단의 분포에 따라 달라진다.
즉, 모집단이 정규분포를 따르지 않고 표본크기가 작으면 통계학적인 분석을 진행할 수 없다.
III. 표본분산과 모수의 통계적 관계
위의 항아리 사례를 다시 살펴보자. 10, 20, 30이라고 쓰인 구슬이 3개 있는 항아리에서 복원추출 방식으로 2개의 구슬을 꺼낼 때 나올 수 있는 모든 표본과 표본분산은 다음과 같다. ()
| 표본 | 표본평균() | 표본분산() | 확률 |
|---|---|---|---|
| (10, 10) | 10 | 0 | 1/9 |
| (10, 20) | 15 | 50 | 1/9 |
| (10, 30) | 20 | 200 | 1/9 |
| (20, 10) | 15 | 50 | 1/9 |
| (20, 20) | 20 | 0 | 1/9 |
| (20, 30) | 25 | 50 | 1/9 |
| (30, 10) | 20 | 200 | 1/9 |
| (30, 20) | 25 | 50 | 1/9 |
| (30, 30) | 30 | 0 | 1/9 |
위의 표를 근거로 표본분산()의 확률분포표를 만들면 다음과 같다.
| 표본분산() | 확률 |
|---|---|
| 0 | 3/9 |
| 50 | 4/9 |
| 200 | 2/9 |
이 표본분포를 이용하여 표본분산 의 평균을 계산해보자.
이를 통해 이 모집단 분산 과 일치함을 알 수 있다.
(증명)
모집단이 정규분포를 따른다면, 은 자유도가 인 분포를 따른다.
과 모수와의 관계
IV. 표본 비율과 모수의 통계적 관계
모집단에서의 성공의 비율을 라 하면, 실패의 비율은 가 된다. 이 를 모집단 비율(population propotion)이라 부른다.
표본크기가 일 때 성공 횟수를 라 하면, 표본에서의 성공비율 은 다음과 같으며, 이를 표본비율(sample propotion)이라 부른다.
는 성공횟수로 0, 1, 2, ... , 의 수치를 취하는 이항분포를 따른다. 이항분포의 특성인 를 이용하여, 의 평균과 분산을 계산하면 다음과 같다.
또한 표본평균의 개념이므로 이 충분히 크면, 의 분포는 정규분포에 근사한다. 대체적으로 일 경우 는 정규분포에 근사한다.
예를 들어, 항아리에 3개의 구슬이 있는데, 1개는 빨간색(), 2개는 검정색()이라 하자. 이 항아리에서 크기가 2인 표본을 추출하되 복원추출의 방식을 취한다면 다음의 표와 같이 9가지의 경우가 나온다.
| 표본 | 표본비율() | 확률 |
|---|---|---|
| 2/2 | 1/9 | |
| 1/2 | 1/9 | |
| 1/2 | 1/9 | |
| 1/2 | 1/9 | |
| 0/2 | 1/9 | |
| 0/2 | 1/9 | |
| 1/2 | 1/9 | |
| 0/2 | 1/9 | |
| 0/2 | 1/9 |
이를 이용하여 의 확률분포 즉 표본비율의 표본분포(sampling distribution of sample proportion)를 구하면 다음과 같다.
| 확률 | |
|---|---|
| 0 | 4/9 |
| 1/2 | 4/9 |
| 1 | 1/9 |
위의 의 표본분포를 이용하여 표본비율의 평균과 분산을 계산하면 다음과 같다.
(아래의 식에서 이다.)
일반적으로
