목차
- 평균값 출력하기(AVG)
- 토탈값 출력(SUM)
- 건수 출력하기(COUNT)
- 데이터 분석 함수로 순위 출력하기 1(RANK)
- 데이터 분석 함수로 순위 출력하기(DENSE_RANK)
평균값 출력하기(AVG)
예제. 사원 테이블에서 평균월급을 출력
select ename, avg(sal) from emp
문제 168. 위 결과를 다시 출력하는데, 소수점 이하가 안나오게 출력
select round(avg(sal),0) // select round(avg(sal)) from emp;
문제 169. 우리반 테이블에서 평균나이 출력
select round(avg(age)) from emp17;
문제 170. 사원테이블에서 직업, 직업별 평균월급 출력
select job, round(avg(sal)) from emp group by job;
문제 171. 위 결과 다시 출력하는데 직업별 평균월급이 높은 것부터 출력
select job, round(avg(sal)) from emp group by job order by 2 desc; // order by는 실행도 코딩도 맨 마지막임. 컬럼 별칭, 컬럼순서인 숫자 사용 가능!!
문제 172. 문제 171번을 다시 수행하는데 직업이 SALESMAN은 제외하고 출력
select job, round(avg(sal)) from emp where job != 'SALESMAN' group by job order by 2 desc;
- 실행순서:
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY
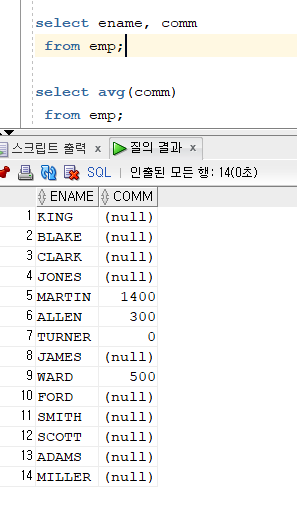
문제 173. 이름, 커미션 출력
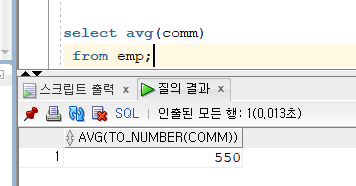
문제 174. 커미션의 평균값 출력
select avg(comm) from emp;
- 그룹함수는 null값을 무시한다!
원래 comm에 null이 많았는데 이거 다 무시하고 계산된것.
문제 175. 위의 결과를 다시 출력하는데 전체 사원수로 나눠져서 평균 커미션이 계산되게 하세요
select avg(nvl(comm,0)) from emp;
(중요)평균값을 출력할 때는, null처리를 어떻게 할지 생각하면서 SQL을 작성해야 한다!!!!
결측치를 어떻게 해야할지 생각 후에 코드짜기! 그냥 AVG쓰면 NULL값이 무시가되니까 출력되는 값이 달라질 수 있다. -> 평균값 구하라고 할때는 소통해서 어떻게 짜면 되는지 말하기!!!!
문제 176. 커미션의 결측치가 몇개가 있는지 확인하시오
SELECT COUNT(*) // ASTERISK ! 모든 컬럼을 다 출력해라! FROM EMP WHERE COMM IS NULL;
- COUNT는
*이랑 짝꿍이다! COUNT(COMM)하면 데이터 0 나온다. 다*로 조회하기!- COUNT를 사용할때는 모든컬럼(*)을 써야 NULL값을 무시하지않고 데이터를 잘 가져올 수 있다. (OCP시험)
문제 177. 부서번호, 부서번호별 평균월급 출력(소수점 이하 안나오게)
- 먼저 월급에 NULL값 있는지 확인후! SQL 작성
SELECT COUNT(*) FROM EMP WHERE SAL IS NULL;SELECT DEPTNO , ROUND(AVG(SAL))
FROM EMP
GROUP BY DEPTNO;
토탈값 출력(SUM)
합계구하는 database의 그룹함수!
예제. 사원테이블의 월급의 토탈값을 출력
select sum(sal)
from emp;문제 178. 직업, 직업별 토탈월급 출력
select job, sum(sal) from emp group by job;
문제 179. 위의 결과를 다시 출력하는데 직업을 A,B,C,D순서대로 정렬해서 출력
select job, sum(sal) from emp group by job order by job; // asc생략!
문제 180. 위의 결과를 다시 출력하는데 직업이 salesman은 제외하고 출력
select job, sum(sal) from emp where job != 'SALESMAN' group by job order by job;
문제 181. 위의 결과(180번)를 다시 출력하는데 직업별 토탈 월급이 5000 이상인것만 출력
select job, sum(sal) from emp where job != 'SALESMAN' and sum(sal) >= 5000 group by job order by job;
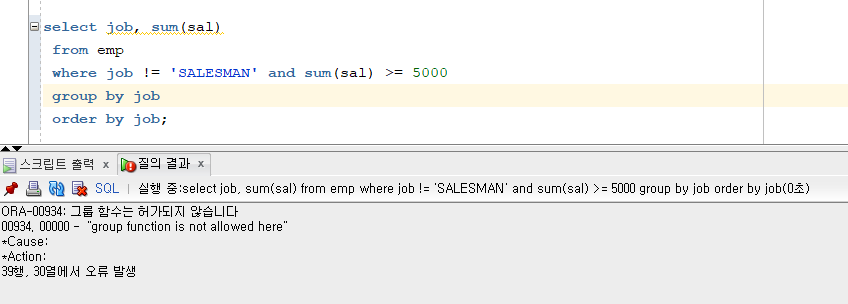
- 그룹함수로 검색조건을 사용할때는 where 절에 사용할 수 없다!
- having절에 사용해야한다!
select job, sum(sal) from emp where job != 'SALESMAN' group by job having sum(sal) >= 5000 order by job;
SELECT 문의 6가지 순서
SELECT-> 보고싶은 컬럼명
FROM-> 테이블명
WHERE-> 검색조건
GROUP BY-> 그룹핑할 컬럼
HAVING-> 그룹함수로 검새고건을 줄때 사용
ORDER BY-> 정렬할 컬럼
- WHERE 뒤에는 일반적인 검색조건이 오고, HAVING 뒤에는 그룹함수로 검색조건을 줄 때 사용!
- 실행순서
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
※ 아래는 HAVING 절에 일반 검색조건, 그룹함수로 검색조건이 온 SQL이다. 이렇게 HAVING절에 일반 검색조건을 쓰면 에러도 없고 데이터 출력은 되어 문제가 없어보이지만, 성능이 느려진다.
또한 INDEX를 사용하지 못하게 된다. JOB != 'SALESMAN'은 WHERE 절에 사용해야한다!
SELECT JOB, SUM(SAL)
FROM EMP
GROUP BY JOB
HAVING SUM(SAL) >= 5000 AND JOB != 'SALESMAN'
ORDER BY JOB;그룹함수란!!!??

문제 182. 이름, 입사일, 입사한 년도(4자리) 출력
SELECT ENAME, HIREDATE ,TO_CHAR(HIREDATE, 'RRRR') FROM EMP;
문제 183. 입사한 년도(4자리) , 입사한 년도별 토탈월급을 출력하는데 입사한 년도를 ASCENDING하게 출력하기
SELECT TO_CHAR(HIREDATE, 'RRRR') AS 입사년 , SUM(SAL) AS 월급합계 FROM EMP GROUP BY TO_CHAR(HIREDATE, 'RRRR') ORDER BY 1 ;
문제 184. 위 183번을 다시 수행하는데, 입사한 년도가 1981, 1982, 1983년만 출력되게 하세요
SELECT TO_CHAR(HIREDATE, 'RRRR') AS 입사년 , SUM(SAL) AS 월급합계 FROM EMP WHERE TO_CHAR(HIREDATE, 'RRRR') IN ('1981','1982','1983') GROUP BY TO_CHAR(HIREDATE, 'RRRR') ORDER BY 1 ;
- 여기서 TO_CHAR로 문자형으로 바뀌었으니까 IN 뒤에 오는 숫자들도
' '붙여서 문자형으로 만들어주자 !!!
문제 185. 184번을 다시 수행하는데, 입사한 년도별 토탈 월급이 4000 이상인것만 출력
SELECT TO_CHAR(HIREDATE, 'RRRR') AS 입사년 , SUM(SAL) AS 월급합계 FROM EMP WHERE TO_CHAR(HIREDATE, 'RRRR') IN ('1981','1982','1983') GROUP BY TO_CHAR(HIREDATE, 'RRRR') HAVING SUM(SAL) >= 4000 ORDER BY 1 ;
문제 186. 우리반 테이블에서 성씨, 성씨별 평균나이 출력
SELECT SUBSTR(ENAME,1,1), ROUND(AVG(AGE)) FROM EMP17 GROUP BY SUBSTR(ENAME,1,1);
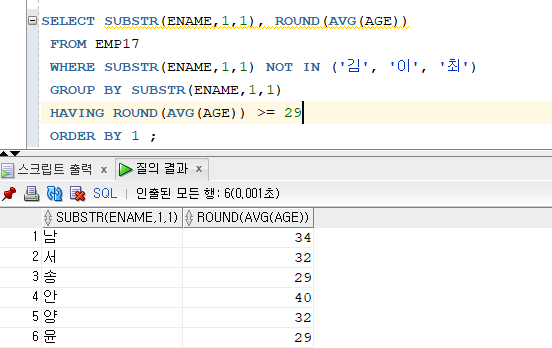
문제 187. 위의 결과를 다시 출력하는데 성씨가 김씨, 이씨, 최씨는 제외하고 출력
SELECT SUBSTR(ENAME,1,1), ROUND(AVG(AGE)) FROM EMP17 WHERE SUBSTR(ENAME,1,1) NOT IN ('김', '이', '최') GROUP BY SUBSTR(ENAME,1,1);
(복습) 기타 비교 연산자 4가지!
NOT의 위치 잘 알아두자.
- (NOT)
BETWEEN ... AND- (NOT)
LIKEIS(NOT)NULL- (NOT)
IN
문제 188. 문제 187번을 다시 수행하는데, 성씨별 평균나이가 29이상만 출력되게 하고 성씨가 ㄱ ㄴ ㄷ ㄹ 순으로 출력
SELECT SUBSTR(ENAME,1,1), ROUND(AVG(AGE)) FROM EMP17 WHERE SUBSTR(ENAME,1,1) NOT IN ('김', '이', '최') GROUP BY SUBSTR(ENAME,1,1) HAVING ROUND(AVG(AGE)) >= 29 ORDER BY 1 ;
건수 출력하기(COUNT)
테이블의 건수를 확인할 때 가장 확실한 방법은 *을 사용하는 것이다.
왜냐! COUNT(COMM) 이런식으로 쓰면 NULL값은 무시가 되어 총 건수가 다르게 출력될 수 있다.
*을 쓰면 NULL값을 무시하지 않아서 가급적 이걸로 출력하자.
select COUNT(enmae) -> COUNT(*)
from emp※ (OCP시험) 다음중 널값의 여부와 관계없이 결과가 잘 카운트 되는 SQL문장은?
1. select count(comm) from emp;
2. select count(mgr) from emp;
3. select count(*) from emp; // 정답!
문제 189. 직업이 salesman 인 사원들의 인원수를 출력하시오
select count(*) from emp where job = 'SALESMAN';
문제 190.직업과 직업별 인원수를 출력
SELECT JOB , COUNT(*) FROM EMP GROUP BY JOB;
문제 191. 위의 결과를 다시 출력하는데 직업별 인원수가 높은 것부터 출력
SELECT JOB , COUNT(*) FROM EMP GROUP BY JOB ORDER BY 2 DESC;
문제 192. 191번을 다시 출력하는데 직업별 인원수가 2명 이상인것만 출력
SELECT JOB , COUNT(*) FROM EMP GROUP BY JOB HAVING COUNT(*) >= 2 ORDER BY 2 DESC;
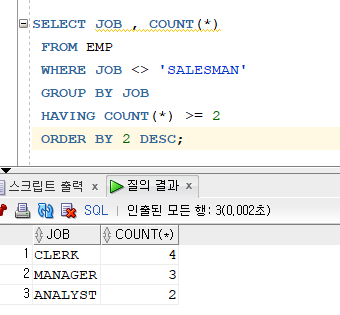
문제 193. 192번을 다시 수행하는데 출력되는 결과에서 직업이 SALESMAN은 제외
SELECT JOB , COUNT(*) FROM EMP WHERE JOB <> 'SALESMAN' GROUP BY JOB HAVING COUNT(*) >= 2 ORDER BY 2 DESC;
문제 194. (ocp시험문제) 사원테이블에 직업의 종류가 몇개가있는지 출력
select count(distinct(job)) from emp;
- 중복되는 직업을 제거하고, count 세기!
문제 195. 어제 만든 서울시 소상공인 데이터인 market_2022 테이블의 전체 건수 출력
select count(*) from market_2022;
문제 196. 서울 강남구에 스타벅스 매장이 몇개가 있는지 출력하기
select count(*) from market_2022 where 상호명 like '스타벅스%' and 시군구명 ='강남구';
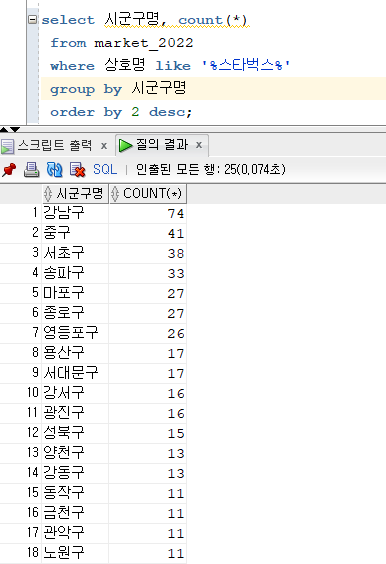
문제 197. 상호명에 스타벅스가 포함되어있는 데이터에서 시군구명, 시군구명별 건수를 출력하는데, 그 건수가 높은 것 부터!
select 시군구명, count(*) from market_2022 where 상호명 like '%스타벅스%' group by 시군구명 order by 2 desc;
문제 198. 위에서 출력되는 결과 중에서 맨 첫번째 행 하나만 출력하시오!
- 이문제는 오라클에서만 사용할 수 있는 특별한 명령어를 사용해야한다.
fetch first 1 row only;
select 시군구명, count(*) from market_2022 where 상호명 like '%스타벅스%' group by 시군구명 order by 2 desc fetch first 1 row only;
order by 컬럼 desc/asc fetch first 숫자 row only;
문제 199. 상호명에 스타벅스를 포함하고 있는 상권업종 소분류명이 무엇인지 조회하기
select * from market_2022 where 상호명 like '%스타벅스';
(목표 해결 문제) 2022년 기준으로 커피 프랜차이즈 가맹점이 가장 많은 브랜드가 어디인지 랭킹 5위까지 출력
데이터 엔지니어 업무..~!
문제 200. 상권업종중분류명이 '카페'인 상호명, 상호명별 건수를 출력하는데 상호명별 건수가 높은것부터 출력
select 상호명, count(*) from market_2022 where 상권업종중분류명 = '커피점/카페' group by 상호명 order by 2 desc;
문제 201. 위 결과를 다시 출력하는데, 상호명이 '카페' 라고 되어있는것은 제외하고 출력
select 상호명, count(*) from market_2022 where 상권업종중분류명 = '커피점/카페' and 상호명 != '카페' group by 상호명 order by 2 desc;
문제 202. 위 SQL을 수정하는데 다음과 같이 수정하세요.
select case when 상호명 like '%스타벅스%' then '스타벅스' else 상호명 end as 상호명, count(*) from market_2022 where 상권업종중분류명 = '커피점/카페' and 상호명 != '카페' group by case when 상호명 like '%스타벅스%' then '스타벅스' else 상호명 end order by 2 desc;
- 스타벅스 어쩌구는 다 스타벅스로 통일되었다.
문제 203. 위 SQL의 case문에 메가엠지씨커피와 투썸플레이스를 추가해서 그룹바이 하세요!
select case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end as 상호명, count(*) from market_2022 where 상권업종중분류명 = '커피점/카페' and 상호명 != '카페' group by case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end order by 2 desc;
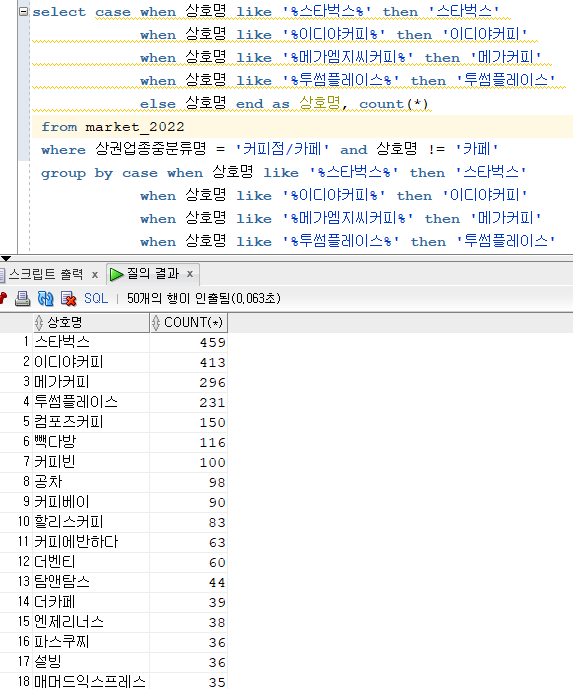
문제 204. 위 데이터 출력을 market_2017 테이블에서 출력하고 , 코로나 이전 데이터 확인
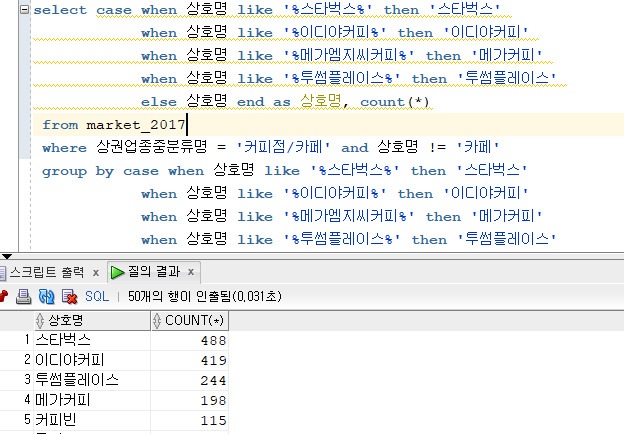
select case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end as 상호명, count(*) from market_2017 where 상권업종중분류명 = '커피점/카페' and 상호명 != '카페' group by case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end order by 2 desc;
데이터 분석 함수로 순위 출력하기 1(RANK)
- datawarehouse 쪽
회사의 데이터베이스 서버의 종류 (2가지)
1. ORTP(OnLine Transaction Processing)서버
ex) 내가 쿠팡에서 현재 활발하게 주문하는 데이터 /
2. DW(Data Warehouse)서버
ex) 주문 이력 데이터
- 오늘 막 실시간으로 ortp에 데이터 들어오다가 dw에 밤 12시에 모두 들어간다.
- 데이터 분석해야해서 다 버리지 않는다.
1.kt / 2. 건강보험 심사 평가원 / 3. 국민의료보험공단 / etc......
데이터분석 하려면 <- 데이터 분석 함수 : 순위, 집계 ...
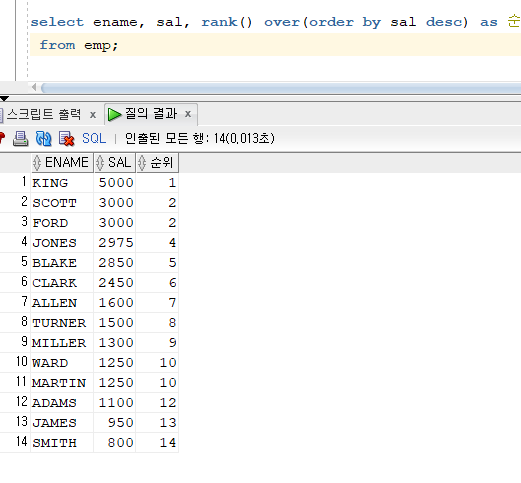
문제 205. 이름, 월급, 월급에대한 순위 출력
select ename, sal, rank() over(order by sal desc) as 순위 -- 순위를 출력하는데, 괄호 안의 내용을 확장해서 from emp;
- 지금 위 SQL은 3등이 안나온다. 이럴 때 DENSE_RANK() 써보자
select ename, sal, dense_rank() over(order by sal desc) as 순위 from emp;
문제 206. 우리반 테이블에서 이름, 나이, 나이에 대한 순위를 출력(RANK로)
SELECT ENAME , AGE, RANK() OVER(order by AGE desc) AS 순위 from emp17;
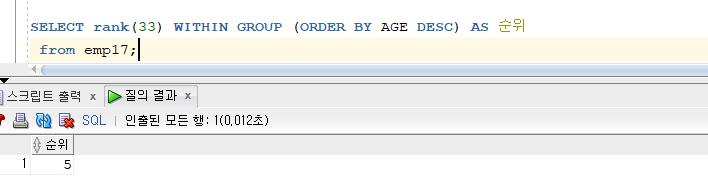
문제 207. 우리반 테이블에서 나이가 33은 순위가 몇위인가?
SELECT rank(33) WITHIN GROUP (ORDER BY AGE DESC) AS 순위 from emp17;
- 문법이 바뀐것을 확인할 수 있다.
- 주로 OVER로 쓰지만 , RANK() 괄호 안에 내용이 들어가면 WITHIN GROUP 으로 바뀐다.
문제 208. 사원 테이블에서 월급이 1250의 순위?
SELECT RANK(1250) WITHIN GROUP (ORDER BY SAL DESC)AS 순위 FROM EMP;
문제 209. 직업, 이름, 월급, 순위를 출력하는데 순위가 직업별로 각각 월급이 높은 순서대로 순위 부여 (GROUP BY가 아니고 PATITION BY)
SELECT JOB, ENAME, SAL, RANK() OVER(PARTITION BY JOB ORDER BY SAL DESC) AS 순위 FROM EMP;
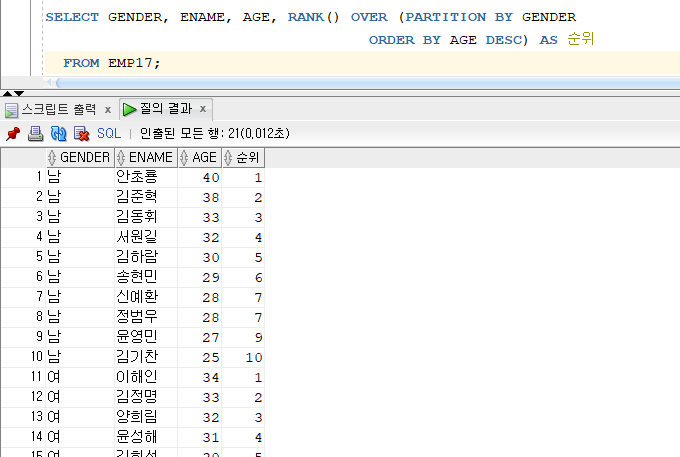
문제 210. 우리반 테이블에서 성별, 이름, 나이, 순위를 출력하는데 순위가 성별별로 각각 나이가 높은 순서대로 순위 부여!
SELECT GENDER, ENAME, AGE, RANK() OVER (PARTITION BY GENDER ORDER BY AGE DESC) AS 순위 FROM EMP17;
데이터 분석 함수로 순위 출력하기(DENSE_RANK)
같은 순위가 여러개 있어도 그 다음 순위로 바로 출력할 수 있게 해주는 데이터 분석 함수 입니다.
- datawarehouse 쪽
스마트폰에서 주문되는 것들이 미들웨어(턱시도)를 거쳐 insert 되면 OLTP 서버에 들어가고, 얘네는 특정 시간이 되면 DW 서버에 모두 들어온다.
DBA는 미들웨어, OLTP, DW 서버를 모두 관리한다. 주문이 안된다? 모두 확인을 해야함
데이터분석가가, 엔지니어 들이 DW쪽에서 예쁘게 테이블을 만들기도 하고 관리를 한다. 근데 INSERT(주문)이 안되는거면 안되니까 큰 문제가 없는지 느린SQL은 없는지 DBA가 총괄을 한다.
OLTP와 DW서버는 성격이 다르다. OLTP는 빨리빨리 해결을 위한? 조회 , INSERT 등..
DW에서는 당장은 필요없지만 무거운 데이터들이 많고 분석이나 이런것들... 하는 SQL이있다.
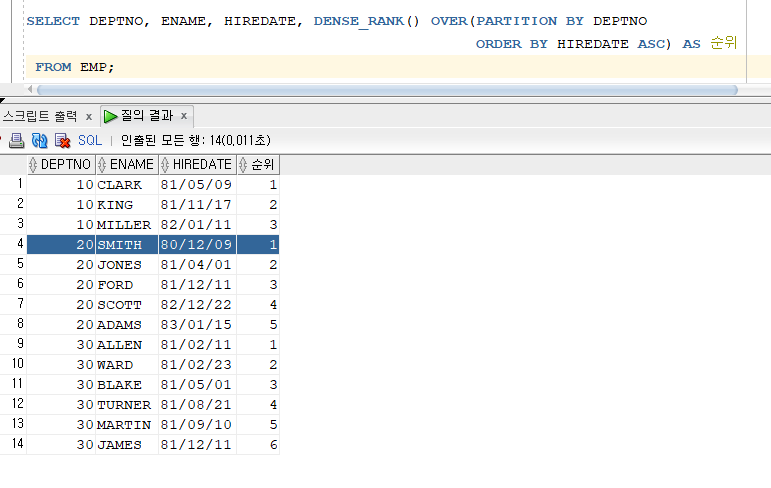
문제 211. 부서번호, 이름, 입사일, 순위를 출력하는데 순위가 부서번호별로 각각 먼저 입사한 사원순으로 순위 부여!
SELECT DEPTNO, ENAME, HIREDATE, DENSE_RANK() OVER(PARTITION BY DEPTNO ORDER BY HIREDATE ASC) AS 순위 FROM EMP;
- 부서번호 별로
PARTITION BY했고 먼저 입사한 사원순으로정렬하여(ORDER BY)순위 보여준다.
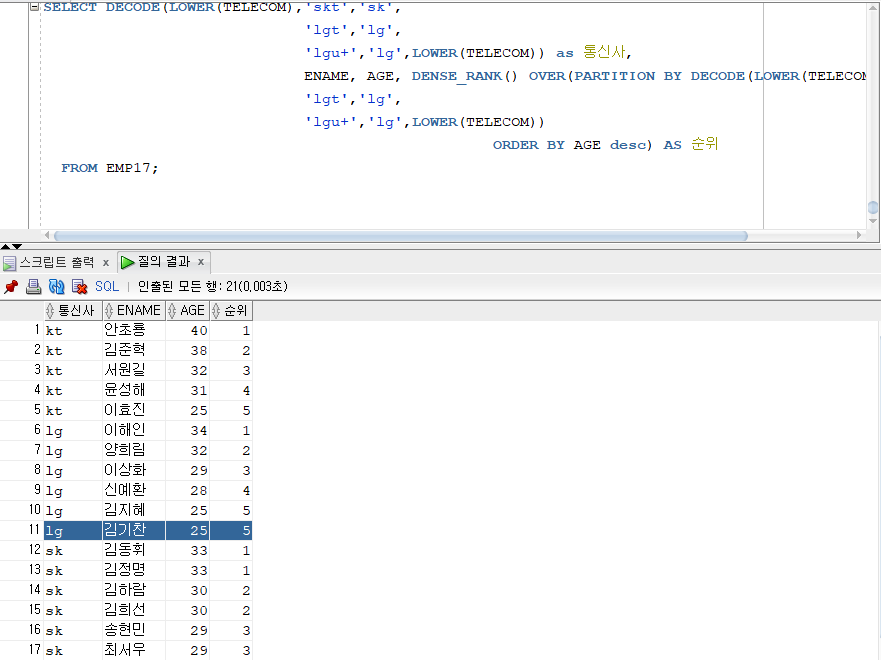
문제 212. 우리반에서 통신사, 이름, 나이, 순위를 출력하는데 순위가 통신사별로 각각 나이가 높은순으로 순위출력
SELECT DECODE(LOWER(TELECOM),'skt','sk', 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) as 통신사, ENAME, AGE, DENSE_RANK() OVER(PARTITION BY DECODE(LOWER(TELECOM),'skt','sk', 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) ORDER BY AGE desc) AS 순위 FROM EMP17;
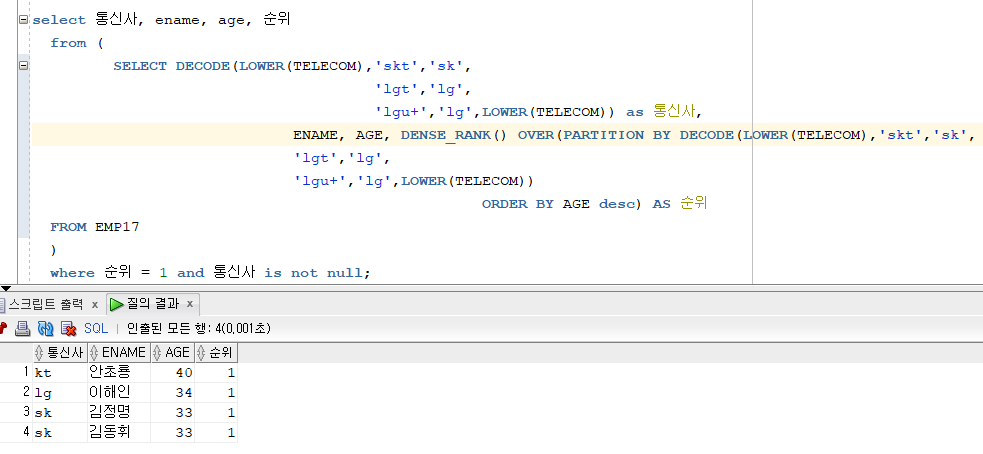
문제 213. 위 결과에서 각 통신사별로 순위가 1등만 나오게 하세요!
※ from 절에 서브쿼리를 사용해야함
SELECT DECODE(LOWER(TELECOM),'skt','sk', 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) as 통신사, ENAME, AGE, DENSE_RANK() OVER(PARTITION BY DECODE(LOWER(TELECOM),'skt','sk', 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) ORDER BY AGE desc) AS 순위 FROM EMP17;여기 from 밑에
where 순위 = 1;이렇게 쓰지 못한다 이유는 순위라는 컬럼이 emp17에 없기때문이고, SQL 실행 순서는 FROM -> WHERE -> SELECT 이니까 select에서 만들어진 별칭 순위는 where절에서 사용하지 못한다.
- 이러한 문제를 해결하려면 from절에 서브쿼리를 사용해야한다.
서브쿼리를 사용하는 방법!
지금 현재 작성한 쿼리문 전체를 from 절로 묶어서, 그 안에 있는 SQL을 제일 먼저 실행되게 만든다. 그러면 실행순서가 FROM절 -> FROM절 안에 실행순서 -> WHERE -> SELECT
select 통신사, ename, age, 순위 // 5번째 from ( // 1번째 SELECT DECODE(LOWER(TELECOM),'skt','sk', // 3번째 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) as 통신사, ENAME, AGE, DENSE_RANK() OVER(PARTITION BY DECODE(LOWER(TELECOM),'skt','sk', 'lgt','lg', 'lgu+','lg',LOWER(TELECOM)) ORDER BY AGE desc) AS 순위 FROM EMP17 // 2번째 ) where 순위 = 1 and 통신사 is not null; // 4번째
- FROM 절의 서브쿼리를 사용해서 괄호안에 SQL이 먼저 수행되게하면, 통신사, 순위라는 컬럼이 컬럼명으로 인식된다. 이렇게 해서 각 통신사별 나이가 제일많은? 1순위 사람만을 출력할 수 있다.
문제 214. 문제 203번의 SQL을 수행해서 결과가 잘 나오는지 확인. -> 잘 나온다!
문제 215. 위의 결과를 다시 출력하는데 상호명, 상호명별 건수, 순위를 출력. 이 순위가 상호명별 건수가 높은 순서대로 순위 부여하기!
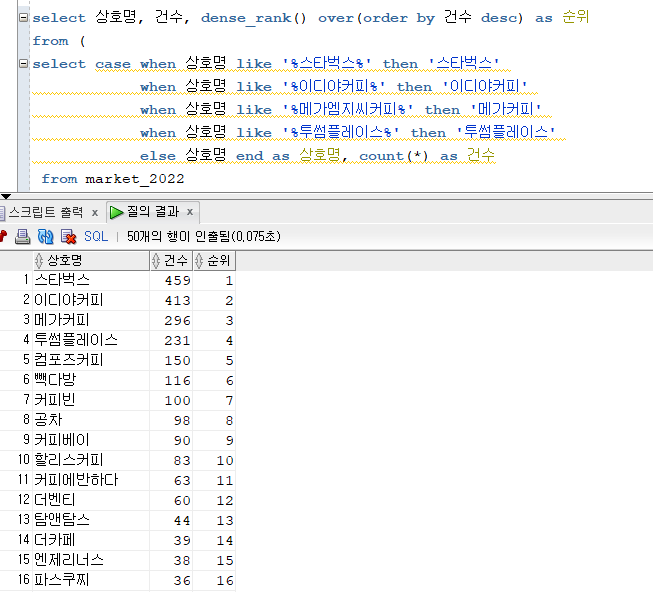
select 상호명, 건수, dense_rank() over(order by 건수 desc) as 순위 from ( select case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end as 상호명, count(*) as 건수 from market_2022 where 상권업종중분류명 = '커피점/카페' and 상호명 != '카페' group by case when 상호명 like '%스타벅스%' then '스타벅스' when 상호명 like '%이디야커피%' then '이디야커피' when 상호명 like '%메가엠지씨커피%' then '메가커피' when 상호명 like '%투썸플레이스%' then '투썸플레이스' else 상호명 end );
- 이렇게 from 절에 서브쿼리를 이용하면 밖쪽의 select절에 from절 안의 별칭명을 사용할 수 있다.
문제 216. market_2022 에서 상호명에 떡볶이가 포함된 상호명과 그 건수를 출력하는데 그 건수가 높은 것 부터 출력
select 상호명, count(*) from market_2022 where 상호명 like '%떡볶이%' group by 상호명 order by 2 desc;
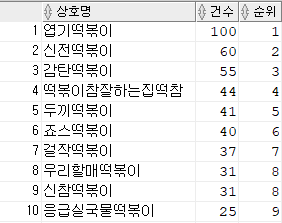
문제 217. (오늘의 마지막 문제..!) 다음과 같이 제대로 결과가 출력될 수 있도록 SQL작성하기!
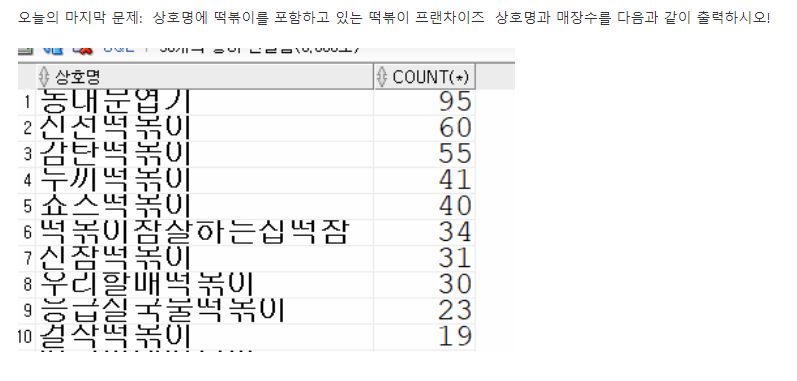
select CASE WHEN 상호명 LIKE '%신전떡볶이%' THEN '신전떡볶이' WHEN 상호명 LIKE '%죠스떡%' THEN '죠스떡볶이' WHEN 상호명 LIKE '%떡참%' THEN '떡볶이참잘하는집떡참' WHEN 상호명 LIKE '%두끼%' THEN '두끼떡볶이' WHEN 상호명 LIKE '%우리할매떡%' THEN '우리할매떡볶이' WHEN 상호명 LIKE '%엽기떡볶이%' THEN '엽기떡볶이' WHEN 상호명 LIKE '%응급실국물떡볶이%' THEN '응급실국물떡볶이' WHEN 상호명 LIKE '%걸작떡볶이%' THEN '걸작떡볶이' WHEN 상호명 LIKE '%떡군이네떡%' THEN '떡군이네떡볶이' WHEN 상호명 LIKE '%감탄떡볶이%' THEN '감탄떡볶이' ELSE 상호명 END AS 상호명, count(*) from market_2022 where 상호명 like '%떡볶이%' group by CASE WHEN 상호명 LIKE '%신전떡볶이%' THEN '신전떡볶이' WHEN 상호명 LIKE '%죠스떡%' THEN '죠스떡볶이' WHEN 상호명 LIKE '%떡참%' THEN '떡볶이참잘하는집떡참' WHEN 상호명 LIKE '%두끼%' THEN '두끼떡볶이' WHEN 상호명 LIKE '%우리할매떡%' THEN '우리할매떡볶이' WHEN 상호명 LIKE '%엽기떡볶이%' THEN '엽기떡볶이' WHEN 상호명 LIKE '%응급실국물떡볶이%' THEN '응급실국물떡볶이' WHEN 상호명 LIKE '%걸작떡볶이%' THEN '걸작떡볶이' WHEN 상호명 LIKE '%떡군이네떡%' THEN '떡군이네떡볶이' WHEN 상호명 LIKE '%감탄떡볶이%' THEN '감탄떡볶이' ELSE 상호명 END order by 2 desc;아래는 서브쿼리로 순위까지 출력한 SQL임.
SELECT 상호명, 건수, DENSE_RANK () OVER(ORDER BY 건수 DESC) AS 순위 FROM ( select CASE WHEN 상호명 LIKE '%신전떡볶이%' THEN '신전떡볶이' WHEN 상호명 LIKE '%죠스떡%' THEN '죠스떡볶이' WHEN 상호명 LIKE '%떡참%' THEN '떡볶이참잘하는집떡참' WHEN 상호명 LIKE '%두끼%' THEN '두끼떡볶이' WHEN 상호명 LIKE '%우리할매떡%' THEN '우리할매떡볶이' WHEN 상호명 LIKE '%엽기떡볶이%' THEN '엽기떡볶이' WHEN 상호명 LIKE '%응급실국물떡볶이%' THEN '응급실국물떡볶이' WHEN 상호명 LIKE '%걸작떡볶이%' THEN '걸작떡볶이' WHEN 상호명 LIKE '%떡군이네떡%' THEN '떡군이네떡볶이' WHEN 상호명 LIKE '%감탄떡볶이%' THEN '감탄떡볶이' ELSE 상호명 END AS 상호명, count(*) AS 건수 from market_2022 where 상호명 like '%떡볶이%' group by CASE WHEN 상호명 LIKE '%신전떡볶이%' THEN '신전떡볶이' WHEN 상호명 LIKE '%죠스떡%' THEN '죠스떡볶이' WHEN 상호명 LIKE '%떡참%' THEN '떡볶이참잘하는집떡참' WHEN 상호명 LIKE '%두끼%' THEN '두끼떡볶이' WHEN 상호명 LIKE '%우리할매떡%' THEN '우리할매떡볶이' WHEN 상호명 LIKE '%엽기떡볶이%' THEN '엽기떡볶이' WHEN 상호명 LIKE '%응급실국물떡볶이%' THEN '응급실국물떡볶이' WHEN 상호명 LIKE '%걸작떡볶이%' THEN '걸작떡볶이' WHEN 상호명 LIKE '%떡군이네떡%' THEN '떡군이네떡볶이' WHEN 상호명 LIKE '%감탄떡볶이%' THEN '감탄떡볶이' ELSE 상호명 END );
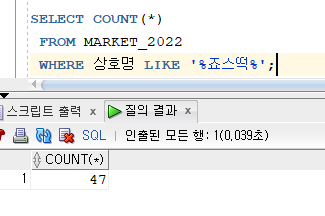
- 근데 죠스떡볶이가 상호명 출력해보면 죠스떡복이 / 죠스떡뽁이 이런것들이 있어서 CASE문에서
WHEN 상호명 LIKE '%죠스떡%' THEN '죠스떡볶이'이렇게 바꾸어줬는데, 상호명 검색을
이렇게 하면 죠스떡볶이가 47개 여야 하는데 where절에서WHERE 상호명 LIKE '%떡볶이%'로 걸어주니까 떡보기 떡뽁이 이런게 걸러져서 나온다.