
오늘의 TIL
- 데이터 분석 함수로 등급 출력하기(NTILE)
- 데이터 분석 함수로 순위의 비율 출력하기(CUME_DIST)
- 데이터 분석 함수로 데이터를 가로로 출력하기(LISTAGG)
- 데이터 분석 함수로 바로 전 행과 다음 행 출력하기(LAG, LEAD)
- row를 column으로 출력하기1 (SUM+DECODE)
- ROW를 COLUMN 으로 출력하기 2(PIVOT)
- COLUMN 을 ROW 로 출력하기(UNPIVOT)
-
DBA는! 공공 데이터들이 데이터베이스 서버에 저장되어 있고 , dba 들을 데이터를 저장, 관리, 백업, 튜닝하는 일을 한다.
-
(뉴스) 출생아수와 학교에 입학한 학생의 수가 서로 일치하지 않는다. 산부인과에서 태어난 출생아수와 나라에 신고한 출생아수가 서로 일치하지 않는다.
서로 다른 공공기관의 DB서버를 DB링크로 연결해주는 일도 DBA
데이터 분석 함수로 등급 출력하기(NTILE)
데이터에 등급을 부여하는 데이터 분석 함수 입니다.
(vs 어제 배운 RANK와 DENSE_RANK는 데이터의 순위를 구하는 함수!)
예제. 이름, 월급, 월급에 대한 등급을 부여 하시오.
(월급에 대한 등급이 4등급으로 나눠서 등급을 부여하시오)
0~25%
25~50%
50~75%
75~100%
select ename, sal, ntile(4) over (order by sal desc) as 등급
from emp;문제 218. 이름, 입사일, 등급을 출력하는데 등급이 먼저 입사한 사원순으로 5등급으로 나누어 출력
select ename, hiredate, ntile(5) over (order by hiredate asc) as 등급 from emp;
문제 219. 위의 결과에서 등급이 2등급만 출력 (from절의 서브쿼리 이용하기)
select ename, hiredate, 등급 from ( select ename, hiredate, ntile(5) over (order by hiredate asc) as 등급 from emp ) where 등급 = 2;
데이터 분석 함수로 순위의 비율 출력하기(CUME_DIST)
특정 데이터의 성적이 상위 몇퍼센트인지를 보고 싶을 때 사용하는 함수 !
예제. 이름, 월급, 월급에 대한 순위, 순위에 대한 비율을 출력하시오
아래와 같이 비율을 출력하는 SQL을 작성하려면, 14를 미리 알고있어야 한다. 그렇지만 회사의 데이터베이스는 지금 이시간에도 데이터가 계속 INSERT되므로, 위와같이 숫자를 쓸 수 없다. (아래는 하드코딩된 것.)
select ename, sal, rank() over (order by sal desc) as 순위, rank() over (order by sal desc) / 14 as 비율 from emp;14 부분에 / COUNT(*) 라고 쓰면 또 에러가 난다.
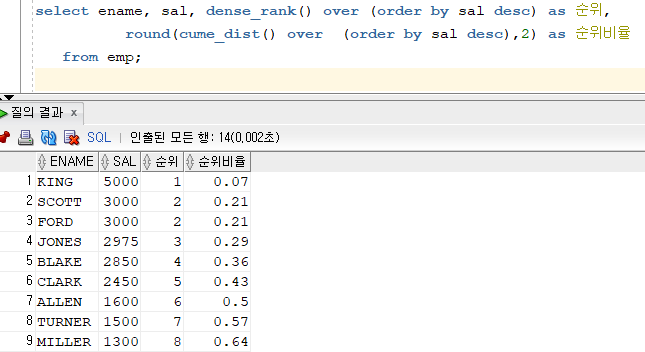
그래서 필요한 데이터 분석 함수가 CUME_DIST이다.select ename, sal, dense_rank() over (order by sal desc) as 순위, cume_dist() over (order by sal desc) as 순위비율 //월급에 대한 순위비율이니까 from emp;
문제 220. 위의 결과를 다시 출력하는데, 순위비율을 출력할 때 소수점 두번째 자리까지 출력되게 반올림하여 출력하시오!
select ename, sal, dense_rank() over (order by sal desc) as 순위, round(cume_dist() over (order by sal desc),2) as 순위비율 from emp;
문제 221. (복습) 직업, 직업별 최대월급을 출력하는데 직업별 최대월급이 높은 것 부터
select job, max(sal) from emp group by job order by 2 desc;
데이터 분석 함수로 데이터를 가로로 출력하기(LISTAGG)
예제. 부서번호, 부서번호별로 해당하는 사원들의 이름을 가로로 출력하시오
SELECT DEPTNO, LISTAGG(ENAME, ',') WITHIN GROUP (ORDER BY SAL DESC) FROM EMP GROUP BY DEPTNO;
- LISTAGG 함수는 다른 분석함수와는 다르게 GROUP BY절이 꼭 필요하다!!
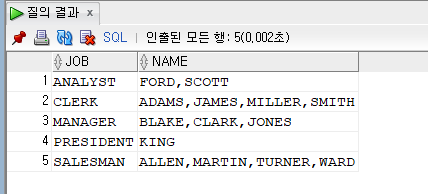
문제 222. 직업, 직업별로 속한 사원들의 이름을 가로로 출력하시오.
select job, listagg(ename, ',') within group (order by ename asc) as name from emp group by job;
abcd순서.
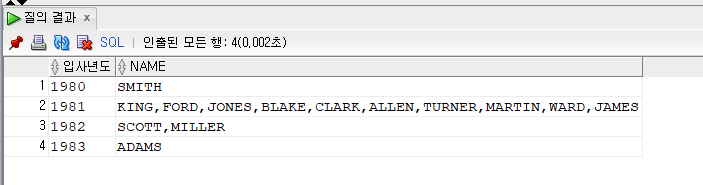
문제 223. 입사한 년도(4자리), 입사한 년도별로 속한 사원들의 이름을 가로로 출력하시오. 정렬은 월급이 높은 사원순으로!!
select to_char(hiredate, 'RRRR') as 입사년도, listagg(ename, ',') within group (order by sal desc) as name from emp group by to_char(hiredate, 'RRRR');
문제 224. 통신사 컬럼의 데이터를 일괄적으로 업데이트를 수행.
update emp17
set telecom = 'sk'
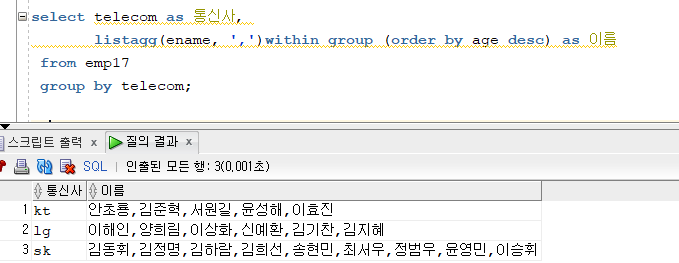
where lower(substr(telecom,1,2)) = 'sk'; // sk, kt, lg 모두 수행해서 업뎃함!문제 225. 통신사, 통신사별로 속한 학생들의 이름을 가로로 출력하는데, 이름이 나이가 높은 순서대로 정렬되게 출력
select telecom as 통신사, listagg(ename, ',')within group (order by age desc) as 이름 from emp17 group by telecom;
문제 226. (미리 내는 점심시간 문제) 실무에서 요청받은 SQL..! 위 데이터 이름 옆에 나이 출력되도록! ex) 윤성해(31), 홍길동(30).....
select telecom as 통신사, listagg(ename || '(' ||age|| ')' , ',')within group (order by age desc) as 이름 from emp17 group by telecom;
데이터 분석 함수로 바로 전 행과 다음 행 출력하기(LAG, LEAD)
예제. 사원번호, 사원이름, 바로 전행의 사원번호, 바로 다음행의 사원번호를 출력하시오.
select empno, ename,
lag(empno,1) over (order by empno asc) as 이전행,
lead(empno, 1) over (order by empno asc) as 다음행
from emp; 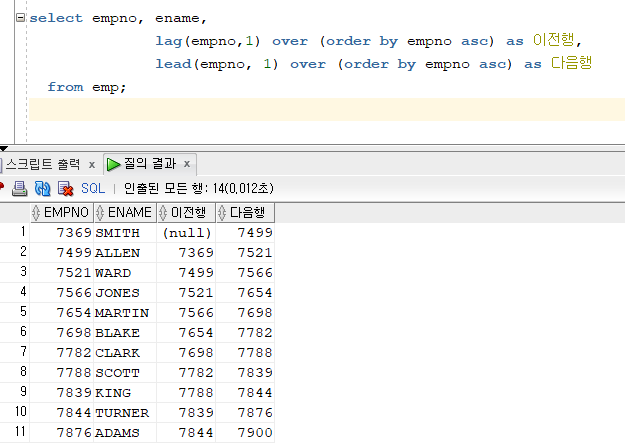
문제 227. 사원이름, 이전행의 사원이름, 다음행의 사원이름을 출력
select ename, lag(ename, 1) over (order by empno asc) as 이전행, // 정렬은 사원번호로 했음 lead(ename, 1) over (order by empno asc) as 다음행 from emp;
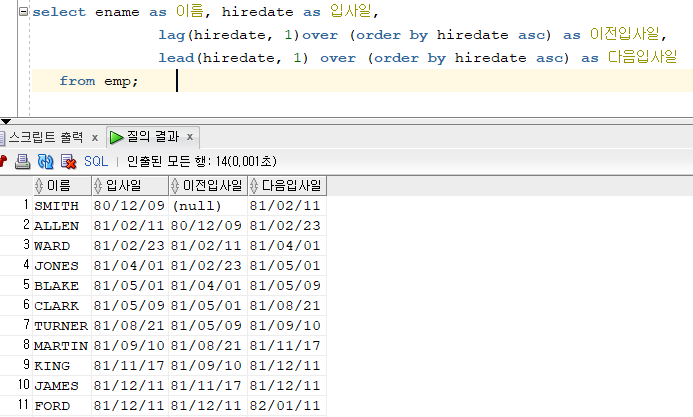
문제 228. (회사 인사팀의 SQL) 이름, 입사일, 바로 전에 입사한 사원의 입사일, 바로 다음에 입사한 사원의 입사일을 출력(정렬은 입사한 사원순으로 정렬)
select ename as 이름, hiredate as 입사일, lag(hiredate, 1)over (order by hiredate asc) as 이전입사일, lead(hiredate, 1) over (order by hiredate asc) as 다음입사일 from emp;
- 얘는 listagg처럼 group by를 쓰지 않아도 된다.
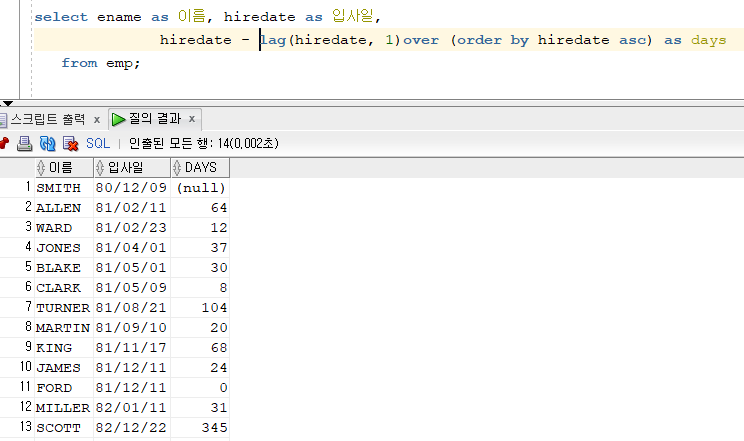
문제 229. 이름, 입사일, 바로전에 입사한 사원과의 간격일을 출력
select ename as 이름, hiredate as 입사일, hiredate - lag(hiredate, 1)over (order by hiredate asc) as days from emp;
- 입사일에서 그 전 입사일을 빼주면 간격을 구할 수 있다.
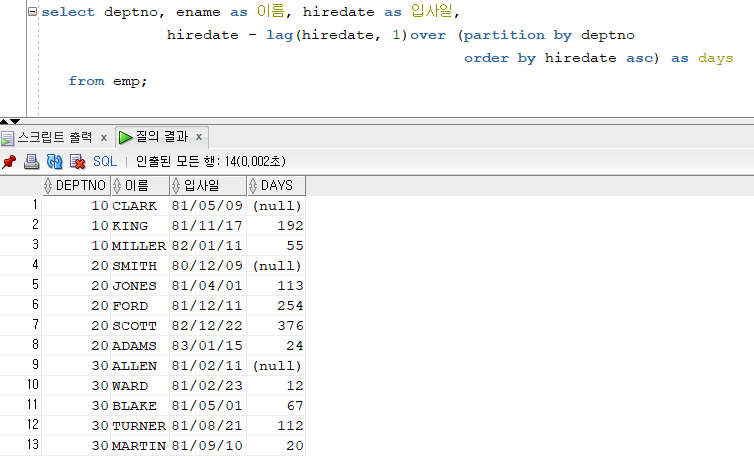
문제 230. 부서번호, 이름, 입사일, 바로전에 입사한 사원과의 간격일을 출력하는데 간격일이 부서번호별로 각각 출력되게 하시오! (partition by 사용)
select deptno, ename as 이름, hiredate as 입사일, hiredate - lag(hiredate, 1)over (partition by deptno order by hiredate asc) as days from emp;
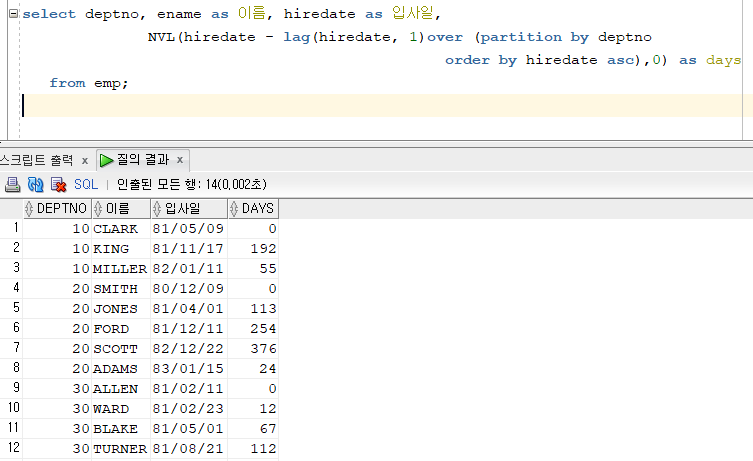
select deptno, ename as 이름, hiredate as 입사일, NVL(hiredate - lag(hiredate, 1)over (partition by deptno order by hiredate asc),0) as days from emp;
NVL사용해서 null값을 0으로 변경
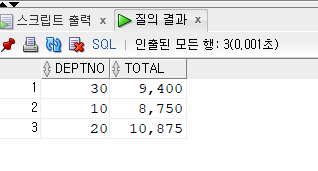
문제 231. (복습) 부서번호, 부서번호별 토탈 월급을 출력하는데 부서번호별 토탈월급을 출력할 때 천단위 표시를 해주기.
select deptno, to_char(sum(sal),'999,999') as total from emp group by deptno;
row를 column으로 출력하기1 (SUM+DECODE)
- 행(row) ---> 컬럼(column) :
SUM + DECODE 또는 PIVOT문 - 컬럼(column) ---> 행(row) :
UNPIVOT문
예제. 부서번호, 부서번호별 토탈월급을 출력하시오.
select deptno, sum(sal) as total
from emp
group by deptno;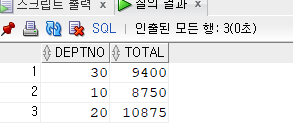
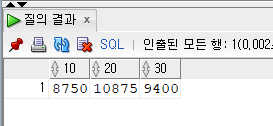
예제2. 위에서 출력되는 행의 데이터가 컬럼이 되어서 다음과 같이 출력되게 하시오
10 20 30 < --- 컬럼명
8750 10875 9400 < --- 데이터문제 232. 부서번호, DECODE를 이용해서 부서번호가 10 이면 월급이 나오게하고, 아니면 0 이 출력되게 하시오
SELECT DEPTNO, DECODE(DEPTNO, 10, SAL, 0) AS "10" FROM EMP;
- 부서번호가 10번이면 월급이 나오고, 10번이 아니라면 0 출력!
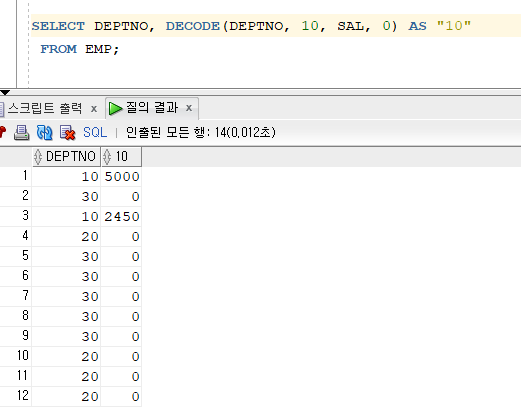
문제 233. 위의 출력되는 결과 옆에 20번과 30번도 함께 출
SELECT sum(DECODE(DEPTNO, 10, SAL, 0)) AS "10", sum(DECODE(DEPTNO, 20, SAL, 0)) AS "20", sum(DECODE(DEPTNO, 30, SAL, 0)) AS "30" FROM EMP;
문제 234. 통신사, 통신사별 평균 나이 출력
select telecom, round(avg(age),0) from emp17 group by telecom;
문제 235. 위 결과를 가로로 출력
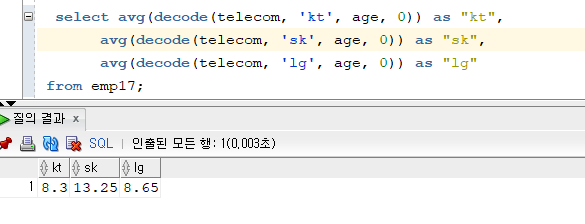
select avg(decode(telecom, 'kt', age, 0)) as "kt", avg(decode(telecom, 'sk', age, 0)) as "sk", avg(decode(telecom, 'lg', age, 0)) as "lg" from emp17;
- 이렇게 0 으로 하면 평균값이 이상하게 나온다. 아까 sum할때는 0으로 했지만 avg는 0을 포함해서 나누는거니까
null로 해야한다. -> 그룹함수는 null값을 무시하니까!select round(avg(decode(telecom, 'kt', age, null)),0) as "kt", round(avg(decode(telecom, 'sk', age, null)),0) as "sk", round(avg(decode(telecom, 'lg', age, null)),0) as "lg" from emp17;
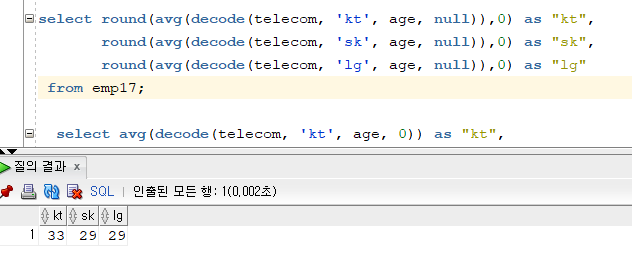
SUM 사용한 첫번째 SQL
select sum(decode(telecom, 'kt', age, null)) as "kt", // NULL 생략가능
sum(decode(telecom, 'sk', age, null)) as "sk",
sum(decode(telecom, 'lg', age, null)) as "lg"
from emp17;SUM 사용한 두번째 SQL
select sum(decode(telecom, 'kt', age, 0)) as "kt",
sum(decode(telecom, 'sk', age, 0)) as "sk",
sum(decode(telecom, 'lg', age, 0)) as "lg"
from emp17;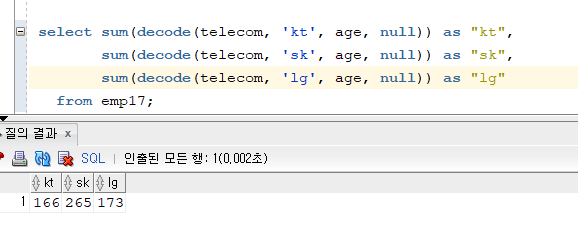
- 그룹함수는 NULL값을 무시하는데, 두번째 SQL은 0이라서 SQL실행될 때 0이 모두 계산이 된다. 그러면 실행속도가 느리니까 위에 NULL로 작성한 코드가 더 빠르다. 결과는 같지만 두번째는 악성 SQL!
문제 236. 직업, 직업별 토탈월급 출력
SELECT JOB, SUM(SAL) FROM EMP GROUP BY JOB;
문제 237. 위 데이터 가로출력
SELECT DEPTNO,SUM(DECODE(JOB, 'ANALYST', SAL )) AS "ANALYST", SUM(DECODE(JOB, 'CLERK', SAL )) AS "CLERK", SUM(DECODE(JOB, 'MANAGER', SAL )) AS "MANAGER", SUM(DECODE(JOB, 'PRISIDENT', SAL )) AS "PRISIDENT", SUM(DECODE(JOB, 'SALESMAN', SAL )) AS "SALESMAN" FROM EMP GROUP BY DEPTNO;create or replace procedure get_data(p_x out sys_refcursor) as l_query varchar2(400) :='select deptno '; begin for x in (select distinct job from emp order by 1) loop l_query := l_query ||replace(', sum(decode(job,''$X'',sal)) as $X ' ,'$X',x.job ); end loop; l_query := l_query ||' from emp group by deptno '; open p_x for l_query; end; / variable x refcursor; exec get_data(:x); print x;
- 아래는 프로시져로 작성한 SQL -> 위 코드는 하드코딩된 코드라서 아래처럼 해준다. (지금 내가할 필요는 없음)
문제 238. (세로출력) 입사한년도(4자리), 년도별 토탈월급 출력
SELECT TO_CHAR(HIREDATE,'RRRR'), SUM(SAL) FROM EMP GROUP BY TO_CHAR(HIREDATE,'RRRR');
문제 239. 위 결과를 가로로 출력
SELECT SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1980',SAL)) AS "1980", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1981',SAL)) AS "1981", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1982',SAL)) AS "1982", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1983',SAL)) AS "1983" FROM EMP;
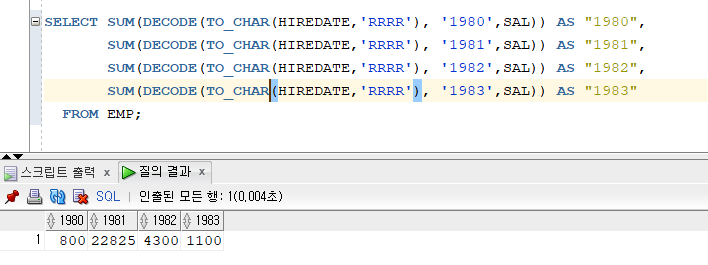
문제 240. 위 결과에서 직업도 앞에 추가하고, 직업별로 그룹바이를 하세요
SELECT JOB, SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1980',SAL)) AS "1980", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1981',SAL)) AS "1981", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1982',SAL)) AS "1982", SUM(DECODE(TO_CHAR(HIREDATE,'RRRR'), '1983',SAL)) AS "1983" FROM EMP GROUP BY JOB;
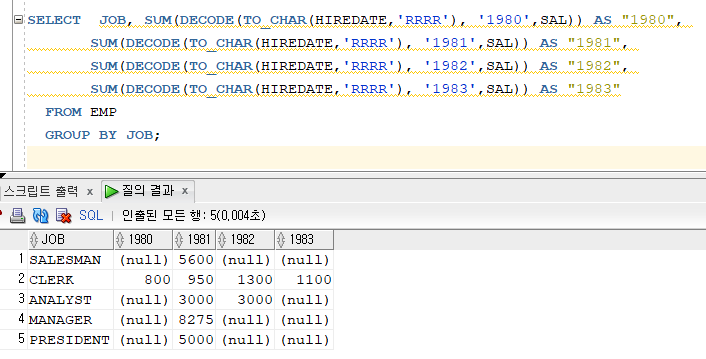
문제 241. (세로출력)통신사, 통신사별 인원수를 출력
SELECT TELECOM, COUNT(*) AS 인원수 FROM EMP17 GROUP BY TELECOM;
문제 242. (가로출력) 우리반 테이블에서 통신사, 통신사별 인원수를 출력하시오!
select sum( decode( telecom , 'kt', 1, null ) ) as "kt", sum( decode( telecom , 'lg', 1, null ) ) as "lg", sum( decode( telecom, 'sk', 1, null ) ) as "sk" from emp17;내가 쓴 코드(아래)
select sum(decode(telecom, 'kt', count(*) )) as "kt", sum(decode(telecom, 'sk', count(*) )) as "sk", sum(decode(telecom, 'lg', count(*) )) as "lg" from emp17 GROUP BY TELECOM;
문제 243. 위의 SQL을 가지고 다음과 같이 결과 출력
select count( decode (telecom, 'sk', empno, null) ) as "sk",
count( decode (telecom, 'lg', empno, null) ) as "lg",
count( decode (telecom, 'kt', empno, null) ) as "kt"
from emp17;select substr(address, 1, 3), count( decode (telecom, 'sk', empno, null) ) as "sk", count( decode (telecom, 'lg', empno, null) ) as "lg", count( decode (telecom, 'kt', empno, null) ) as "kt" from emp17 group by substr(address, 1, 3);
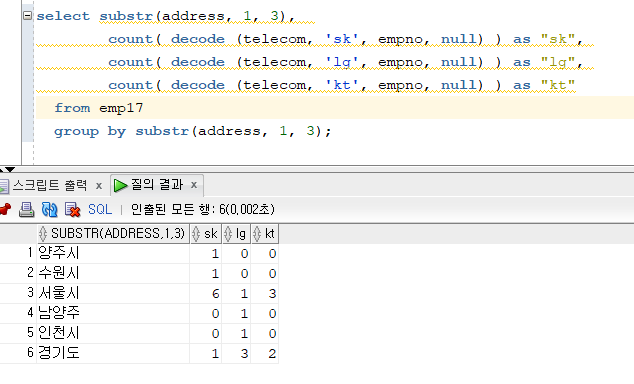
- 위와같이 SQL을 작성하면 너무 하드코딩하게 되므로 조금 더 심플하게 작성하게 하는 데이터 분석 함수를 제공합니다.
ROW를 COLUMN 으로 출력하기 2(PIVOT)
예제. 부서번호, 부서번호별 토탈월급을 가로로 출력하는데 pivot문을 이용하시오!
select *
from ( select deptno, sal from emp) // from + 결과를 보기위해 필요한 컬럼 선택
pivot(sum(sal) for deptno in (10,20,30)); // pivot + 10.20.30번에 대한 부서번호를 더해서 세로로 출력될 것을 가로로 바꾸어 출력된다. 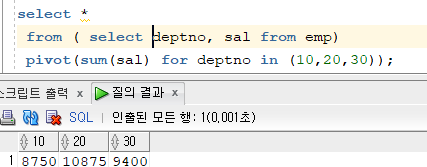
- pivot을 사용하는데 중요한 것은 from에 서브쿼리를 작성해주는 것이다. from 안에 필요한 컬럼만 선택해서 작성한다.
- pivot + 10.20.30번에 대한 부서번호를 더해서 세로로 출력될 것을 가로로 바꾸어 출력된다. 이 때 10,20,30은 테이블 안에 실제 있는 데이터여야한다.
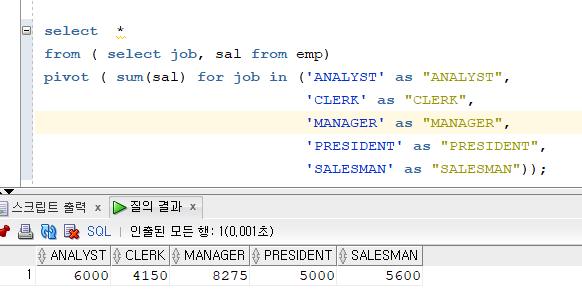
문제 244. 직업, 직업별 토탈월급을 가로로 출력하는데 pivot 문을 사용하기.
select * from ( select job, sal from emp) pivot ( sum(sal) for job in ('ANALYST' as "ANALYST", 'CLERK' as "CLERK", 'MANAGER' as "MANAGER", 'PRESIDENT' as "PRESIDENT", 'SALESMAN' as "SALESMAN"));
- 싱글쿼테이션을 사용하면 컬럼명이 'ALANYST'가 나와서 별칭으로 다시 지정해주었다.
문제 245. 아래의 괄호 안에 넣은 SQL을 작성하시오
select *
from ( select job, sal from emp)
pivot ( sum(sal) for job in (
이 부 분 !
));위의 SQL괄호안에 하드코딩할 리터럴 문자들을 아래의 SQL로 생성하면 쉽게 PIVOT 문을 작성할 수 있다.
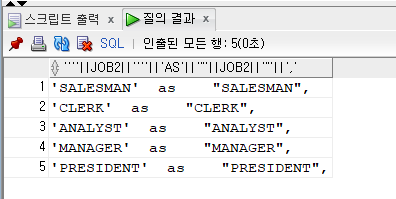
select '''' || job2 || '''' || ' as ' || '"' || job2 || '"' || ',' from (select distinct job as job2 from emp );
- 싱글 4개가 하나로 인식이 된다. 그래서 4개 써줘야함
- 위 코드에서 출력되는 데이터값을 복사해서 쓰면 됨(아래처럼)
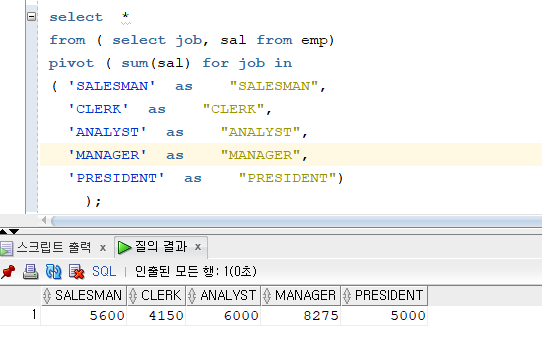
'SALESMAN' as "SALESMAN", 'CLERK' as "CLERK", 'ANALYST' as "ANALYST", 'MANAGER' as "MANAGER", 'PRESIDENT' as "PRESIDENT",select * from ( select job, sal from emp) pivot ( sum(sal) for job in ( 'SALESMAN' as "SALESMAN", 'CLERK' as "CLERK", 'ANALYST' as "ANALYST", 'MANAGER' as "MANAGER", 'PRESIDENT' as "PRESIDENT") );
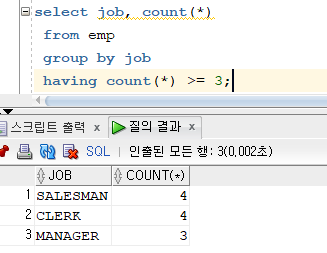
문제 246. (복습) 직업, 직업별 인원수를 출력하는데 직업별 인원수가 3명 이상인것만 출력
select job, count(*) from emp group by job having count(*) >= 3;
COLUMN 을 ROW 로 출력하기(UNPIVOT)
- 준비 데이터
create table order2
( ename varchar2(10),
bicycle number(10),
camera number(10),
notebook number(10) );
insert into order2 values( 'SMITH', 2, 3, 1 );
insert into order2 values( 'ALLEN', 1, 2, 3 );
insert into order2 values( 'KING', 3, 2, 2 );
commit ;문법
select * from order2 unpivot ( 갯수 for 아이템 in ( bicycle, camera, notebook));※ 갯수 와 아이템 한글글씨는 마음대로 작성해도 된다.
in 다음에 괄호안에 컬럼명 쓸때 양쪽에 싱글 쿼테이션 마크를 쓰지 않는다.
문제 247. 위의 문법 SQL의 결과를 담는 ITEM2라는 테이블 생성하기
create table item2 // create table + table명 as // 밑의 SQL의 결과로 테이블 생성 select * from order2 unpivot ( 갯수 for 아이템 in ( bicycle, camera, notebook));
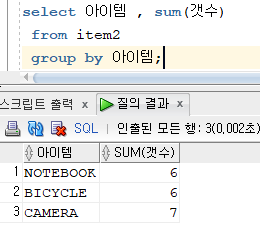
문제 248. item2에서 아이템, 아이템별 건수를 출력
select 아이템 , sum(갯수) from item2 group by 아이템;
unpivot문이 왜 필요할까?
데이터 분석을 위해서 데이터를 구하다 보면, row데이터를 구하는것은 어렵고, 이미 row데이터를 가지고 분석한 결과 테이블을 구할 수 있는 경우가 많다.
혹은 이미 pivoting된 결과 데이터를 있을때 , 나는 pivoting 전 데이터인 raw(날)데이터를 원할 때.
문제
select * from crime_time;에서 살인이 가장 많이 일어나는 시간대를 출력
결과를 F21T24를 뽑고싶다. 그러면 UNPIVOT을 사용해야함!
문제 249. 살인이 가장 많이 발생하는 시간대를 출력하시오.
select * from crime_time
UNPIVOT( 건수 for 시간 in(f0t3,f3t6, f6t6...........여기언제다씀))select * from crime_time
UNPIVOT( 건수 for 시간 in(F0T3
,F3T6
,F6T9
,F9T12
,F12T15
,F15T18
,F18T21
,F21T24))- describe crime_time 를 쓰면 컬럼명 다 나온다
그치만 복사하기 좀 귀찮으니까 옆에 테이블 가서 복사해온다
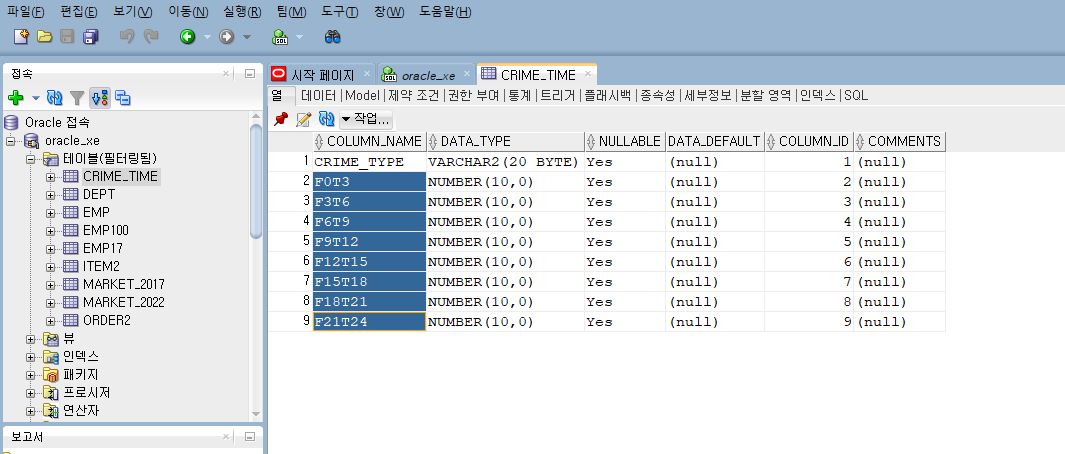
F0T3
F3T6
F6T9
F9T12
F12T15
F15T18
F18T21
F21T24
이 컬럼명 옆에 콤마를 써줘야하는데 나중에 컬럼명이 많은 테이블을 보면 하나하나 붙여주기가 어렵다. -> 노트패드++ 다운받아서alt사용해서 한번에 콤마 붙여줌
문제 250. 살인이 가장 많이 일어나는 시간대와 건수, 순위를 출력하시오
- as 밑에 결과로 출력받는 테이블을 하나 생성한다.
create table crime_time2 as select * from crime_time UNPIVOT( 건수 for 시간 in(F0T3 ,F3T6 ,F6T9 ,F9T12 ,F12T15 ,F15T18 ,F18T21 ,F21T24));
select crime_type, 시간, 건수,dense_rank() over(order by 건수 desc) as 순위 from crime_time2 where crime_type = '살인';
