개요
CBOW 모델은 word embedding 기법 중 Word2Vec(Word to Vector) 모델로써, 문맥 상에서 단어를 예측할 수 있다는 아이디어를 차용하여 word를 embedding한다. 다음과 같은 문장이 주어졌다고 해보자.
The king ____ the dwarf.
어떻게 위 문장에서 빈칸 안에 들어갈 단어를 예측할 수 있을까?
One-hot encoding
머신러닝으로 컴퓨터가 data를 학습 혹은 처리할 때, 컴퓨터는 오직 numerical data만 있는 그대로 다룰 수 있다. 때문에 컴퓨터에 categorical data를 입력하기 전에 컴퓨터에게 적합한 방법으로 변환시켜주어야 한다. 그 중 one-hot encoding은 가장 기본적인 categorical data 처리 방법으로 총 단어의 갯수만큼의 vector를 만들고 해당 단어의 index를 1, 그 외에는 모두 0으로 만드는 방식이다.
예를 살펴보면 간단하다. "To be or not to be, that is a question."이라는 문장이 주어졌다고 생각해보자. 위 문장의 총 단어의 갯수는 8개이므로 dimension이 8인 vector를 기반으로 one-hot encoding을 시행할 것이다. 여기서 대소문자의 구별은 하지 않으며, 조사도 무의미하지만 포함하였다.
각 단어별 인덱스를 지정하자면, 순서대로 to : 0, be : 1, or : 2, not : 3 ... 으로 표현할 수 있고, 위 문장을 one-hot encoding 방식으로 나타내면
to : [1, 0, 0, 0, 0, 0, 0, 0]
be : [0, 1, 0, 0, 0, 0, 0, 0]
or : [0, 0, 1, 0, 0, 0, 0, 0]
not : [0, 0, 0, 1, 0, 0, 0, 0]
to : [1, 0, 0, 0, 0, 0, 0, 0]
be : [0, 1, 0, 0, 0, 0, 0, 0]
that : [0, 0, 0, 0, 1, 0, 0, 0]
is : [0, 0, 0, 0, 0, 1, 0, 0]
a : [0, 0, 0, 0, 0, 0, 1, 0]
question : [0, 0, 0, 0, 0, 0, 0, 1]
위와 같이 나타낼 수 있다. 다만 위에서 살펴볼 수 있듯이, 이 방식은 너무 sparce하고 따라서 메모리 낭비가 심하다. 이를 해결하기 위해 Word2Vec를 이용해 embedding matrix로 word embedding하는 방식이 생겨났다.
word2vec이 처음 소개된 논문
T. Mickolov, K. Chen, G.Corrado, J. Dean. Efficient Estimation of Word Representations in Vector Space, 2013
https://arxiv.org/pdf/1301.3781.pdf
CBOW model
Word2Vec 모델 중 문맥 상에서 단어를 예측할 수 있다는 점에서 착안한 방식이다.
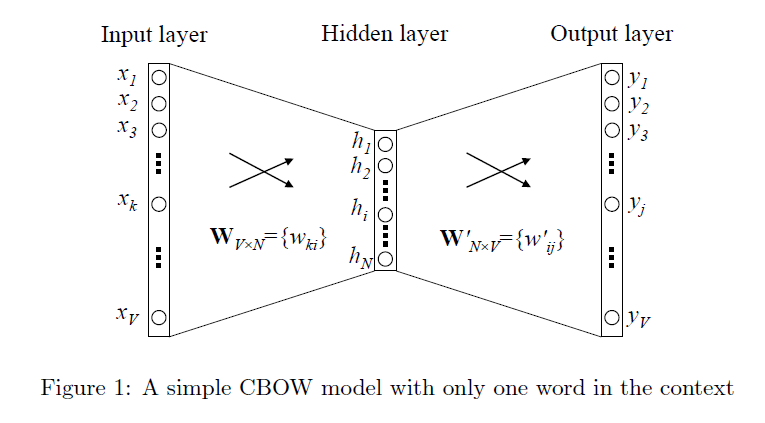
위의 그림은 CBOW model을 나타낸 그림이다. 입력을 다음과 같이 정의하자.
x : V dimension의 input vector
xi : x의 i번째 원소
N : dimension of embedding vector
W : V×N weight(embedding) matrix (from input layer to hidden)
W′ : N×V weight matrix (from hidden to output)
u : vector immediately before activation
y : output vector
Feedforward
CBOW model은 input으로 one-hot encoded vector를 받는다. 그리고 neural network처럼 hidden layer의 벡터 hi는 input vector와 weight matrix의 inner product, WTx로 나타낼 수 있다.
여기서 xi는 벡터 x의 i번째 원소(0 or 1)이며, x에서 인덱스 j가 1이라면 x는 j번째의 단어에 대응함을 의미한다. 위의 예(to be or not to be...)에서 만약 x의 2번째 원소가 1이면(x2=1o.w0) x는 be에 대응한다.
one-hot encoded vector x(xk=1)를 weight matrix W와 곱해주면 W의 k번째 row가 결과로 나온다. hidden layer를 다음과 같은 식으로 표현할 수 있다.
hi=WTx:=vTwIwI:vector representation of the input word
그리고 u를 계산하기 위해 W′를 곱하면,
uj=v′wjThv′wj:j-th column of the matrixW′
라고 나타낼 수 있다.
이제 activation function으로 softmax function을 이용할 것이다. word wI가 input으로 들어왔을 때, output으로 wj가 나올 확률을 다음과 같이 계산할 수 있다.
p(wi∣wI)=yi=∑j=1Vexp(uj)exp(ui)=∑j=1Vexp(v′wjTv′wIT)exp(v′wiTvwIT)
위의 예제에서 "to ____"라는 구문이 주어졌을 때, 직관적으로는 가장 기댓값이 높은 output으로 "be"를 예상할 수 있다. 우리의 목적은 p(be∣to)를 maximizing하는 것이다.
Backpropagation
output to hidden
이제 hidden layer에서 output layer로 가는 weight matrix W′를 back propagation을 이용하여 갱신하여보자.
maxp(wO∣wI) =maxyj∗=maxlogyj∗=uj∗−logΣj′=1Vexp(uj′):=−E
loss function E를 −maxp(wO∣wI)로 설정하여 손실함수 E를 minimizing하려고 한다. Gradient descent method를 이용하여 W′를 갱신할 때,
wij′(new)=wij′(old)−η⋅∂wij′∂E
W′ 값을 갱신함으로써 손실함수 E의 극솟값을 구할 수 있다.
Chain rule을 이용하면
∂wij′∂E∂uj∂E∂wij′∂uj⟹wij′(new)vwj′(new)=∂uj∂E⋅∂wij′∂uj=yj−tj:=ej=hi=wij′(old)−η⋅ej⋅hi=vwj′(old)−η⋅ej⋅h
tj:1 only when the j-th unit is the actual output word
vwI(new)=vwI(old)−η⋅∂WT∂E 