코드 문제 분석(gamma)
advantage = reward + gamma * np.max(action_prob) - action_prob[action]
loss = loss_fn(torch.tensor([advantage]), torch.tensor([action_prob[action]]))문제 1: advantage가 numpy 스칼라 값이라 requires_grad가 없음
• advantage는 reward, gamma, np.max(action_prob), action_prob[action] 등의 numpy 연산 결과라서 PyTorch의 autograd(자동 미분)에 연결되지 않음.
• 따라서 advantage를 torch.Tensor로 변환해야 함.
문제 2: gamma가 PyTorch 텐서가 아니라면, 미분이 끊길 수 있음
• gamma는 numpy 또는 float 자료형으로 선언되어 있을 가능성이 있음.
• 만약 gamma가 학습 가능한 값이라면 torch.tensor(gamma, requires_grad=True)로 변환해야 함.
해결 방법
- 모든 연산을 PyTorch 텐서에서 수행하도록 변환
- gamma를 텐서로 변환 (필요한 경우 requires_grad=True 설정)
부분 수정 코드
# gamma를 텐서로 변환
gamma = torch.tensor(0.99, dtype=torch.float32, requires_grad=False) # 학습 대상이 아니면 False
# action_prob을 텐서로 변환 (이미 텐서일 경우 생략 가능)
action_prob = policy_net(state) # policy_net(state)는 원래 torch.Tensor여야 함
# advantage 계산을 PyTorch 연산으로 수행
reward_tensor = torch.tensor(reward, dtype=torch.float32) # 보상도 텐서로 변환
advantage = reward_tensor + gamma * torch.max(action_prob) - action_prob[action]
# 손실 계산 (requires_grad=True 유지)
loss = loss_fn(advantage.unsqueeze(0), action_prob[action].unsqueeze(0))하지만 또 다시 오류의 늪... argmax()에서 발생한 문제.
현재 코드 action_prob을 np.argmax()로 처리하는 부분에서 PyTorch 텐서를 numpy 배열로 변환하는 과정 중 오류 발생.
오류 원인
action_prob = policy_net(state).detach().numpy()[0]
action = np.argmax(action_prob)1. policy_net(state)는 PyTorch Tensor이고 requires_grad=True인 상태
• 따라서 .numpy()를 호출하려면 .detach()가 필요함.
• 문제는 .detach()를 했어도 PyTorch 텐서는 기본적으로 2D 텐서(예: [batch_size, action_dim])일 가능성이 있음.
• 그런데 .numpy()[0]으로 1차원 배열로 바꿨을 때, np.argmax()가 axis를 못 찾는 문제가 발생할 수 있음.
2. PyTorch 텐서에서 바로 argmax()를 사용할 수 있음
• numpy로 변환할 필요 없이 바로 PyTorch의 argmax() 사용 가능!
• torch.argmax(action_prob, dim=1)을 쓰면 해결됨.
수정 코드
# action_prob을 PyTorch에서 바로 처리
action_prob = policy_net(state).detach()
# 가장 확률이 높은 행동 선택
action = torch.argmax(action_prob, dim=1).item()코드 오류의 늪(절망편)
근데 코드를 변경할 경우 1D와 2D 텐서 간의 차이를 처리하기 위해 들어갔던 numpy가 필요 없어짐. (numpy를 이용해 스칼라 값을 추출하던 코드 -> pytorch에서 직접 스칼라 값을 추출하는 방식으로 변경.)
loss 텐서가 requires_grad=True 속성을 가지고 있지 않아서 문제 발생. loss.backward()가 호출될 때, 그 텐서가 자동 미분(autograd)을 통해 기울기를 계산하려면, 텐서가 requires_grad=True로 설정되어 있어야 하지만 현재는 없음.
epsilon 값을 활용한 탐험(exploration)과 활용(exploitation) 사이의 균형을 맞추는 부분이 제대로 작동하지 않는 것 같음. 이를 해결하려면 epsilon을 제대로 활성화하고, epsilon-greedy 전략을 적용하여 행동을 선택하는 과정에서 탐험과 활용을 동시에 고려해야 함.
문제 원인
• torch.argmax()는 1D 텐서에서만 직접 작동하므로, 2D 텐서에서의 행동 선택을 위해서는 조금 더 신경을 써야 함.
• argmax()가 반환하는 값은 텐서 형태이므로 스칼라 값으로 변환하는 과정이 필요함.
• loss 텐서는 requires_grad=True로 설정되지 않았기 때문에, backward()를 호출할 때 오류가 발생함.
• 일반적으로, 모델의 출력에서 loss 계산을 할 때 requires_grad=True로 설정된 텐서에서 기울기가 계산되도록 해야 함.
• 현재 코드에서 epsilon 값이 활성화되지 않았거나 사용되지 않는 것 같아, 행동을 무조건적으로 선택하고 있어 탐험이 제대로 이루어지지 않는 문제.
오류 스킵!(내가 볼려고 만든거니까 스킵함 나중에 추가함)
변경 사항 요약
-
log_prob = torch.log(action_prob[action] + 1e-8)
• log(0) 방지! (이전 코드에서 log(0)이 발생할 가능성 있음) -
advantage = reward + gamma * future_reward - action_prob[action].detach()
• detach()를 사용하여 불필요한 gradient 흐름 차단
• torch.max(policy_net(next_state_tensor))가 학습에 영향을 주지 않도록 변경
예상되는 결과
• 보상이 점진적으로 증가할 가능성이 높아짐
• log(0) 문제를 해결해서 NaN 발생 방지
• gamma를 제대로 반영해서 장기적인 보상 고려 가능
최종 완성된 코드
import torch
import torch.nn as nn
import torch.optim as optim
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, action_dim)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
return torch.softmax(self.fc3(x), dim=-1) # 확률 값 반환
class Environment:
def __init__(self):
self.state_dim = 10
self.action_dim = 5
self.current_state = torch.rand(self.state_dim)
self.steps = 0
def reset(self):
self.current_state = torch.rand(self.state_dim)
self.steps = 0
return self.current_state
def step(self, action):
next_state = self.current_state + (action - 2) * 0.1
next_state = torch.clamp(next_state, 0, 1)
reward = 1 - torch.sum((next_state - 0.7) ** 2).item() # 보상 변경 (양수 보상)
self.steps += 1
done = self.steps >= 10
self.current_state = next_state
return next_state, reward, done
env = Environment()
state_dim = env.state_dim
action_dim = env.action_dim
def train_gflownet():
policy_net = PolicyNetwork(state_dim, action_dim)
optimizer = optim.Adam(policy_net.parameters(), lr=1e-3)
epsilon = 0.1
gamma = 0.99
for episode in range(100):
state = env.reset()
total_reward = 0
for _ in range(10):
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action_prob = policy_net(state_tensor).squeeze(0) # [action_dim] 형태
# epsilon-greedy 적용
if torch.rand(1).item() < epsilon:
action = torch.randint(0, action_dim, (1,)).item()
else:
action = torch.argmax(action_prob).item()
next_state, reward, done = env.step(action)
next_state_tensor = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
# log(0) 방지 (안정화)
action_prob_value = action_prob[action] + 1e-8 # 작은 값 더해줌
log_prob = torch.log(action_prob_value)
# Advantage 계산 (TD Target 적용)
with torch.no_grad():
future_reward = torch.max(policy_net(next_state_tensor)).item()
advantage = reward + gamma * future_reward - action_prob[action].detach()
# 정책 손실 (Policy Gradient Loss)
loss = -log_prob * advantage
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
total_reward += reward
if done:
break
print(f"Episode {episode + 1}: Total Reward = {total_reward:.2f}")
train_gflownet()결과 값
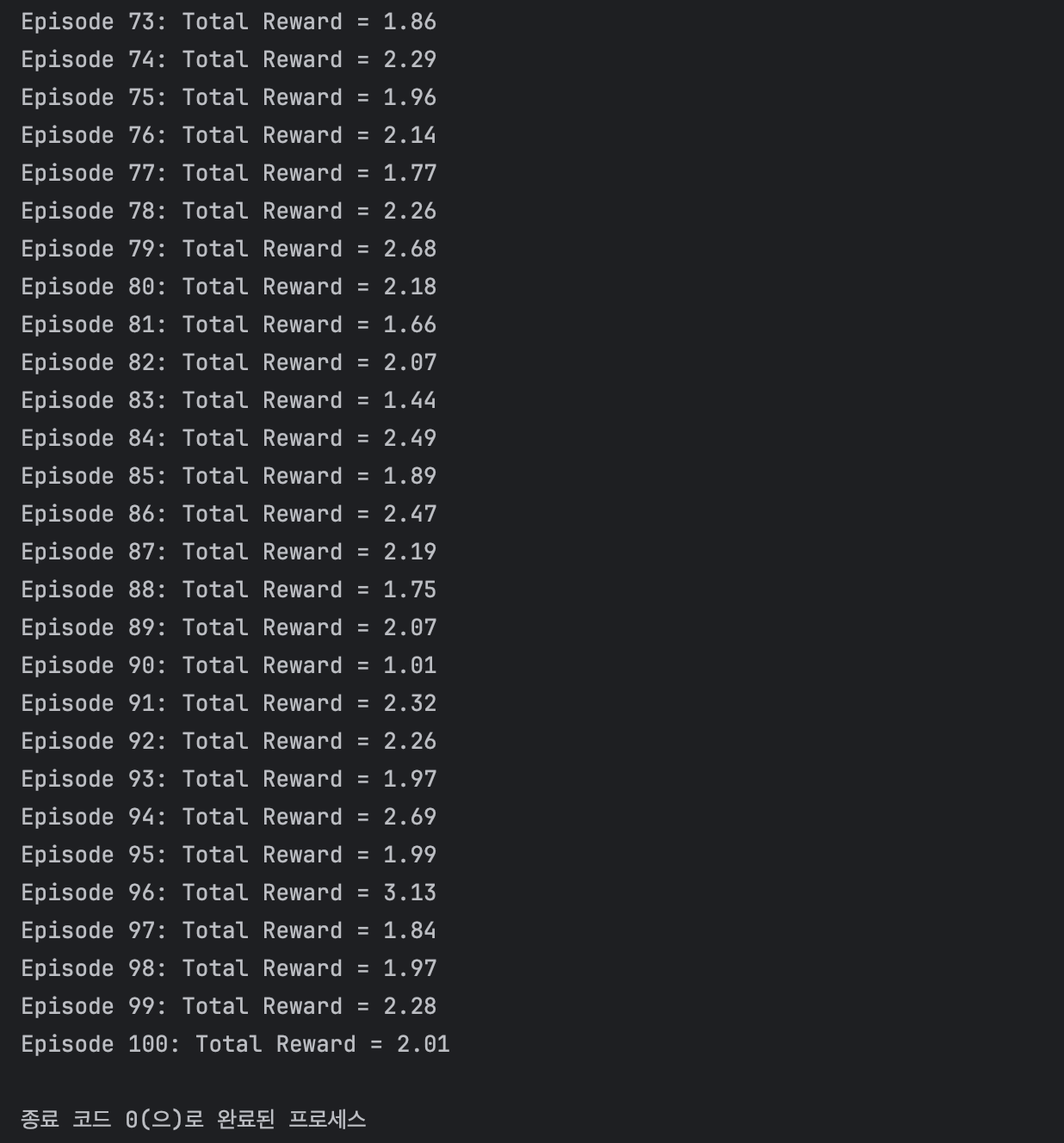
드디어 양수가 나오는 신경망으로 전환시켰다...
