인공지능
인공지능은 컴퓨터가 인간의 지능적인 행동을 모방할 수 있도록 하는 소프트웨어로 인간이 가진 지적 능력의 일부 또는 전체를 인공적으로 구현한 것을 의미한다.
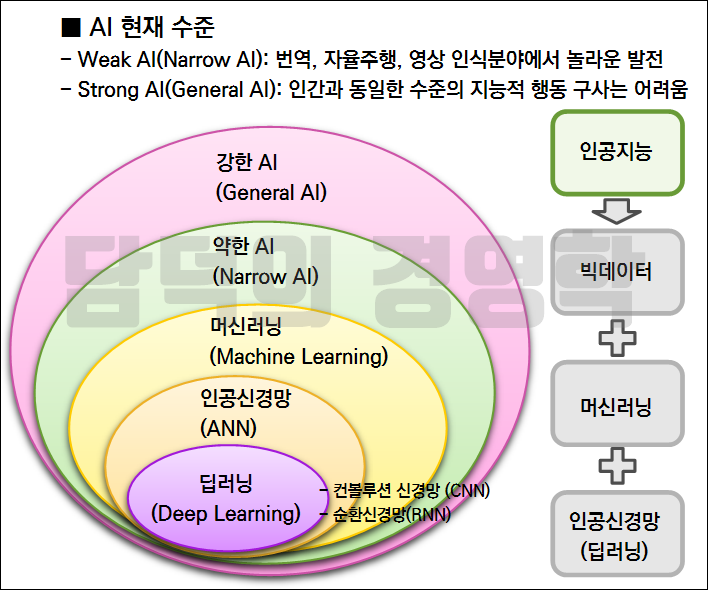
인공지능을 구현하기 위해서 머신러닝(기계학습)을 이용하며, 머신러닝의 인공신경망(Artificial Neural Network)을 기반으로 한 알고리즘이 딥러닝이다. 따라서 인공지능, 머신러닝(Machine Learning), 딥러닝(Deep Learning)은 포함 관계를 가지고 있으며, 인공신경망은 머신러닝의 유형인 지도학습(Supervised Learning)의 종류로 구분할 수 있다.
또한 인공신경망이 XOR연산 불가 문제, 기울기 소멸 문제(Vanishing Gradient)를 거쳐 현재의 딥러닝(Deep Learning, 심층학습)으로 정의되었기 때문에 딥러닝이 더 진보적인 개념을 가지고 있다.
머신러닝의 유형은 모델을 학습시키는 과정에서 정답(클래스, Label)를 알려주느냐 그렇지 않느냐에 따라서 지도학습(Supervised Learning)과 비지도학습(UnSupervised Learning)으로 구분된다.
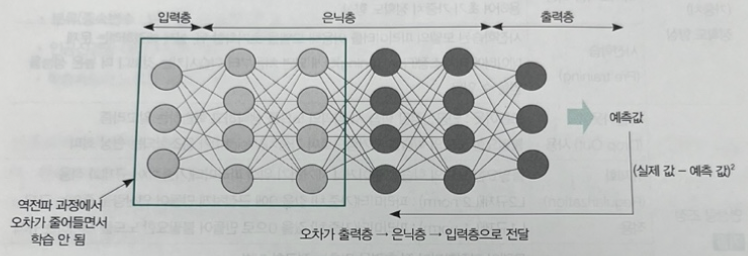
img) 인공신경망 범위
인공신경망의 이해
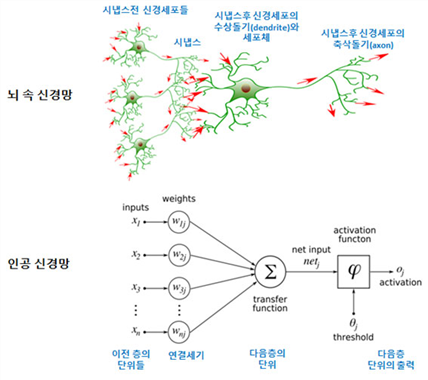
인공신경망(Artificial Neural Network)은 인간 두뇌의 학습 과정을 뉴런과 시냅스의 상호작용을 연산 과정으로 간주하고 이를 재현한 분류(Classification), 예측(Prediction) 모델이다.
인공신경망은 두뇌의 뉴런(신경세포)이 연결된 형태로 모방하여 착안되었으며, 뉴런은 시냅스를 거쳐 수상돌기(Dendrite)로 받아들인 외부의 전달물질을 세포체(Cell body)에 저장하다가 자신의 용량을 넘어서면 축색돌기(Axon)를 통해 외부로 전달물질을 내보낸다고 알려져 있다.
즉, 생물학적인 뉴런이 위의 그림과 같이 다른 여러 개의 뉴런으로부터 입력값을 받아서 세포체에 저장하다가 자신의 용량을 넘어서면 외부로 출력값을 내보내는 것처럼, 인공신경망의 노드(세포체)는 여러 입력값을 받아서 일정 수준이 넘어서면 활성화되어 출력값을 내보낸다. 이 과정에서 시냅스(Synapse)에 의해 뉴런과 뉴런을 연결하여 자극이 전달되게 되는데 이는 인공신경망에서 가중치를 학습함을 의미하게 된다(인공신경망은 데이터로부터 가중치를 학습하는 매커니즘으로 구성된다).
img) 인공신경망
인공신경망의 진화 과정
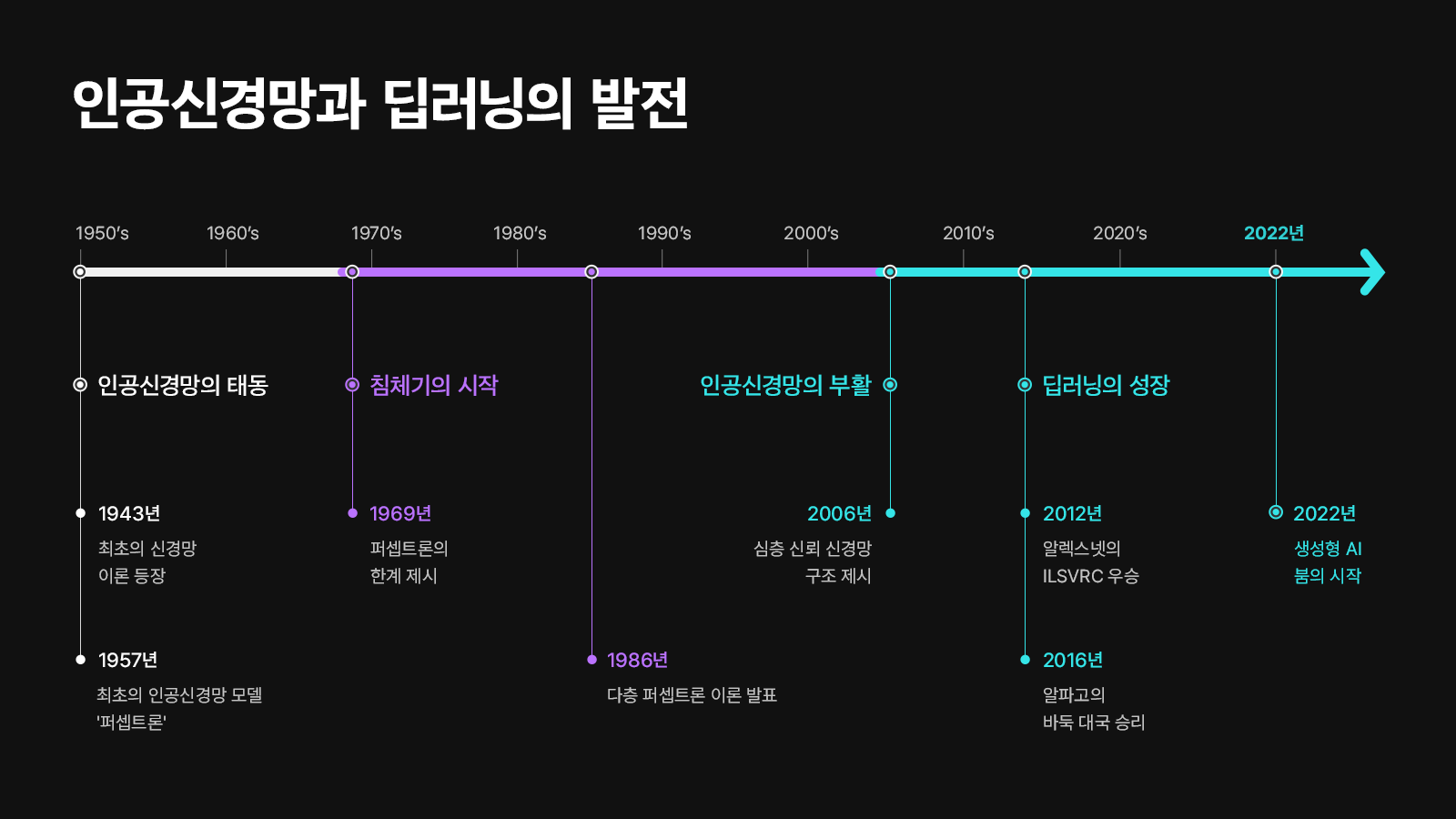
인간의 신경 구조를 기반으로 하는 인공신경망의 개념이 1943년 정립되고, 현재의 딥러닝 시대로 진화해온 과정은 다음 연대표와 같다.
img) 인공신경망의 연대표
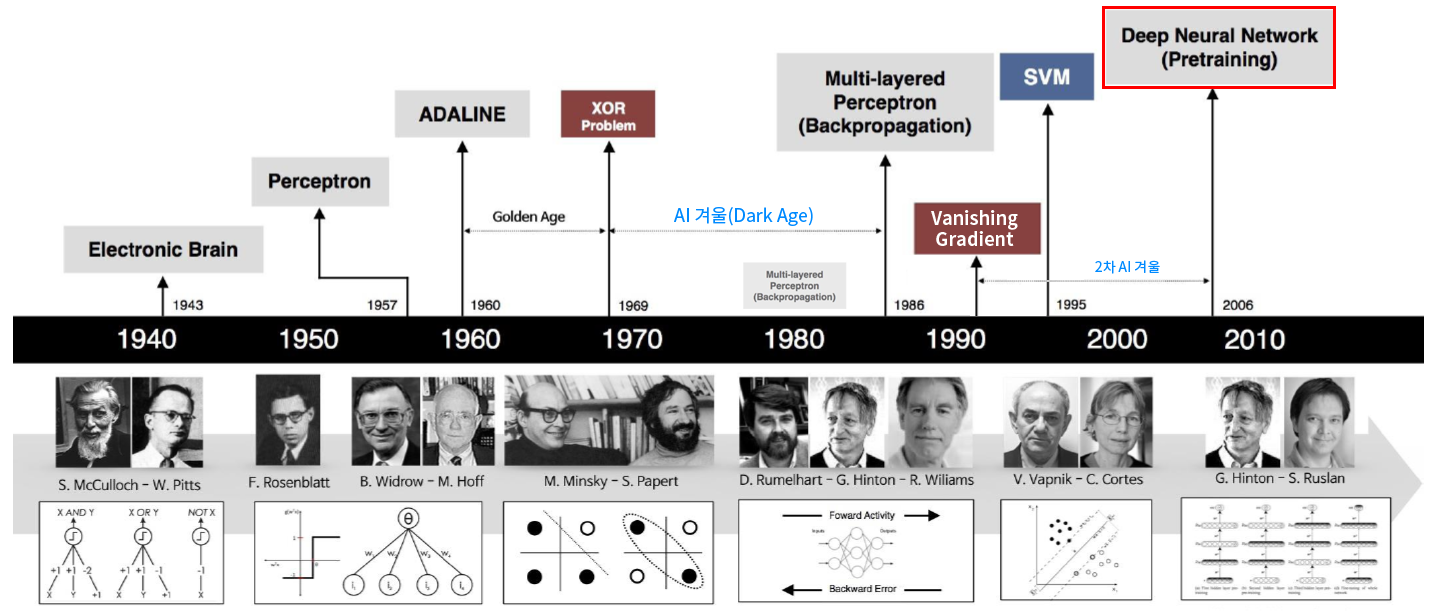
인공지능의 1, 2차 암흑기
1차 암흑기
원인 : 퍼셉트론의 XOR 게이트 연산 불가능한 문제
해결 : 다층퍼셉트론과 역전파 알고리즘의 등장으로 해결(1986)
2차 암흑기
원인 : 기울기 소멸(Vanishing Gradient) 문제, SVM(Support Vector Machine) 등 우수한 알고리즘 등장
해결 : 초기 가중치 정확도 향상, Sigmoid 활성화 함수의 대체(ReLu 활성화 함수), DropOut 적용 등
TLU(Threshold Logic Unit)
1943년 워렌 맥컬록(McCulloch) 월터피츠(Walter Pitts)는 생물학적 신경망 이론을 단순화한 이론을 발표하였는데, 이는 인간의 뇌를 수많은 신경세포가 연결된 디지털 네트워크 모델로 보고 이 신호처리 과정을 모델화하여 표현할 수 있다고 제안했다. 이를 TLU(Threshold Logic Unit)라 한다.
img) 인공신경망 TLU를 AND 논리 연산에 적용한 사례
헵 규칙(Hebb Rule)
헵 규칙은 두 개의 뉴런 A, B가 서로 반복적이고 지속적으로 점화(Firing)하여 어느 한쪽 또는 양쪽 모두에 어떤 변화를 야기한다면 상호 간 점화의 효율(Weight)은 점점 커지게 된다는 이론이다. 헵의 학습 규칙(Hebb Learning Rule)이라고도 한다.
신호 전달 시 반복적 또는 지속적으로 신호가 자극됨에 따라, 뉴런 A에서 뉴런 B로 가는 경로인 시냅스 연결이 강화된다. 이는 TLU(Threshold Logic Unit)에 가중치(Weight)라는 개념이 적용되게 하여, 각 입력에 따라 중요도를 달리 구성할 수 있게 하였다.
img) 헵 규칙의 가중치
위 그림에서 각 두개의 입력변수를 성별(x1)과, 나이(x2)라고 가정하자. 만약 나이 변수가 더 중요한 변수라면, 나이(x2)변수의 가중치(Weight)를 높게 주어(x1 = 0.2, x2 = 0.5) 두 개의 값이 합쳐졌을 때 나이 변수의 영향력을 높일 수 있게 되는 것이다. 헵 규칙은 후에 신경망 모델 학습 규칙의 토대가 되었다.
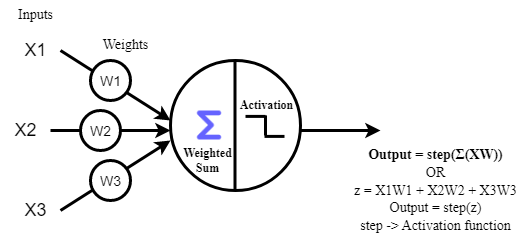
퍼셉트론(Perceptron)과 아달라인(Adaline)
TLU(Threshold Logic Unit) 알고리즘과 헵의 규칙(Hebb Rule)을 결합하여 프랑크 로젠블라트(Frank Rosenblatt, 1957)는 퍼셉트론 즉, 간단한 덧셈과 뺄셈을 하는 이층 구조의 학습 컴퓨터망에 근거한 패턴인식을 위한 알고리즘을 만들었다.
퍼셉트론(Perceptron)은 목표 값(Ideal)을 정하고 현재 계산된 값(Output)이 목표 값과 다르면 그만큼의 오차를 다시 퍼셉트론에 반영하여 오차를 줄여나가는 알고리즘이 적용되었으며, 인간의 신경망과 유사하게 만든 입력층, 출력층으로 구성되어 학습능력을 가진 신경망 모델로 정의되었다.
img) 퍼셉트론 구조
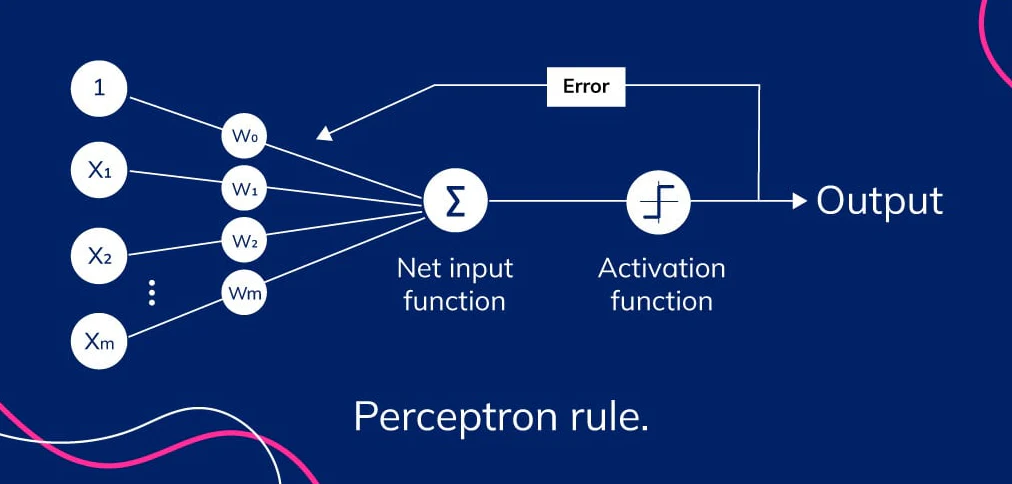
퍼셉트론에서는 활성화 함수(Activation Function)가 순입력 함수의 리턴 값을 임계 값과 비교하여 그 결과에 따라 1 또는 -1을 출력한다. 따라서 퍼셉트론의 가중치 업데이트는 학습 데이터에 대한 활성화 함수(Activation Function)의 리턴 값과 학습 데이터의 실제 결과 값이 같은지 다른지에 따라 이루어지게 된다.
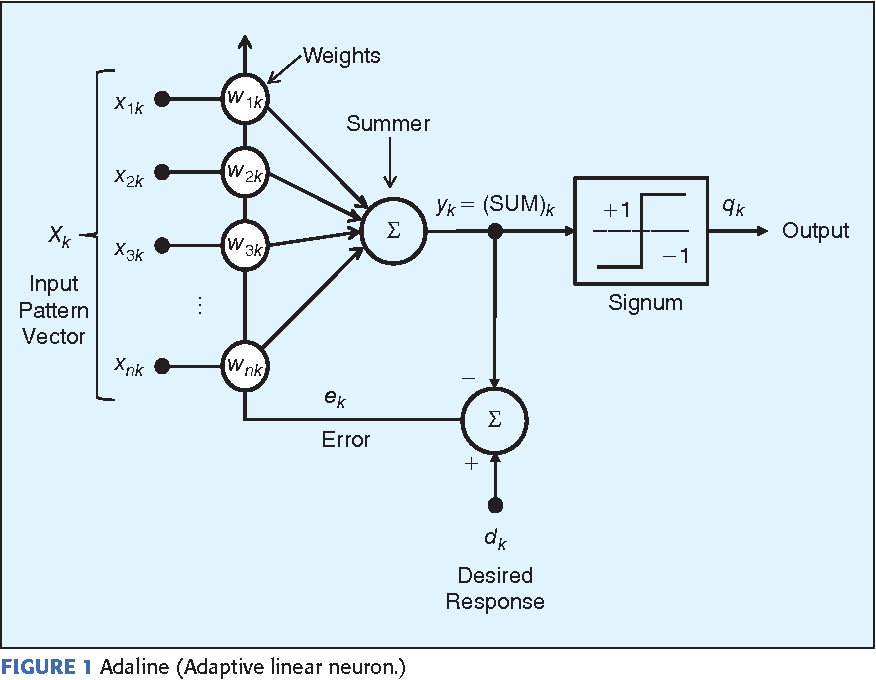
1960년 베나드 윈드로(Benard Windorow)와 테드 호프(Tedd Hoff)은 퍼셉트론의 성능을 개선한 인공신경망 알고리즘인 아달라인(Adaptive Linear Neuron, AdaLine) 논문을 발표한다.
아달라인은 단층신경망에서 적당한 가중치를 알아내기 위해 출력 값을 오차에 비례하게 가중치(Weight)를 조절하는 인공신경망 알고리즘이며, 역전파 알고리즘(Back Propagation)의 기본 이론이 되었다(아달라인은 델타규칙이라고도 한다).
img) 아달라인 구조
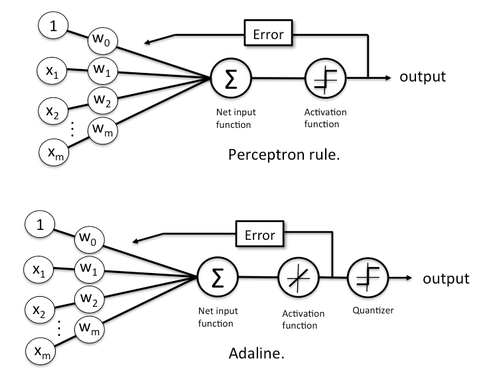
퍼셉트론과 아달라인의 차이점은 가중치(Weight) 업데이트를 위한 활성화 함수(Activation Function)가 다른 것인데, 퍼셉트론이 출력 값인 1 또는 -1을 실제 결과 값과 비교한다면, 아달라인은 신경망의 출력 값과 실제 결과 값을 직접 비교하여 오차가 최소화되도록 하는 손실 함수(Loss Function)를 사용합니다.
순입력 함수의 출력 값과 실제 결과 값의 오차를 손실 함수로 계산하고 손실 함수의 값이 최소가 되도록 최소제곱법을 이용하여 가중치를 조정하게 된다. 이러한 메커니즘은 경사하강법(Gradient Descent), 회귀분석(Regression), 서포트벡터머신(Support Vector Machine) 알고리즘에서 최적의 가중치를 찾기 위해 사용하게 된다.
퍼셉트론(Perceptron)의 한계
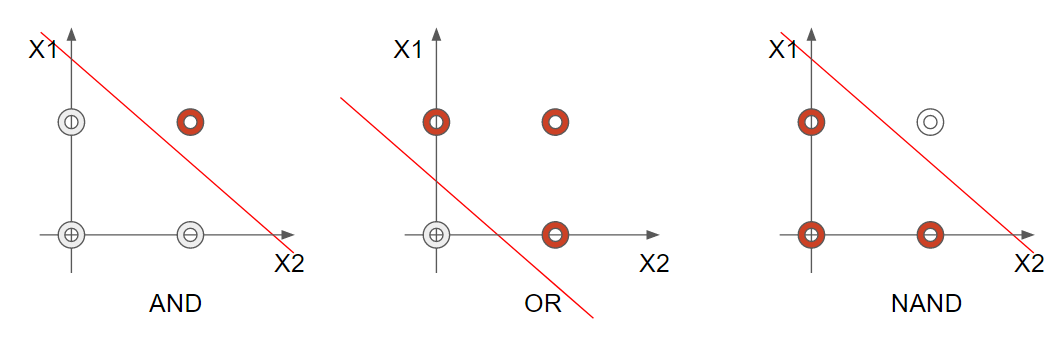
퍼셉트론은 AND, OR, NAND 게이트를 휼륭하게 구분해 냈다. AND 게이트는 2개의 입력 값 중 모두 1인 값만 출력 값이 1이 되므로 아래 그림과 같이 선 하나로 빨간 원(y = 1)과 흰색 원(y = 0)을 구분할 수 있다.
OR 게이트 또한 2개의 입력 값 중 1개만 1이면 출력 값도 1이므로 아래 그림과 같이 선 하나로 빨간 원(y = 1)과 흰색 원(y = 0)을 구분할 수 있다. NAND 게이트 또한 마찬가지이다.
img) 퍼셉트론의 AND, OR, NAND 게이트
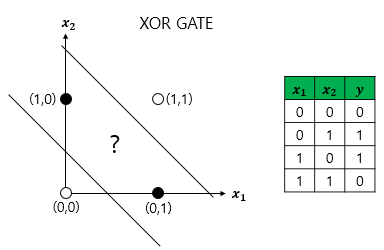
하지만 XOR 게이트의 경우 선 하나로 표현이 가능하지 않다. XOR 게이트는 입력 값이 두 개가 서로 다른 값을 가지고 있을 때만 출력 값이 1이 되고 입력 값 두개가 서로 같은 값을 가지면 출력 값이 0이 되는 게이트이기 때문에 출력 값 0과 1이 대각선에 위치한다.
img) 퍼셉트론의 XOR 게이트
img) 다중퍼셉트론(MLP)
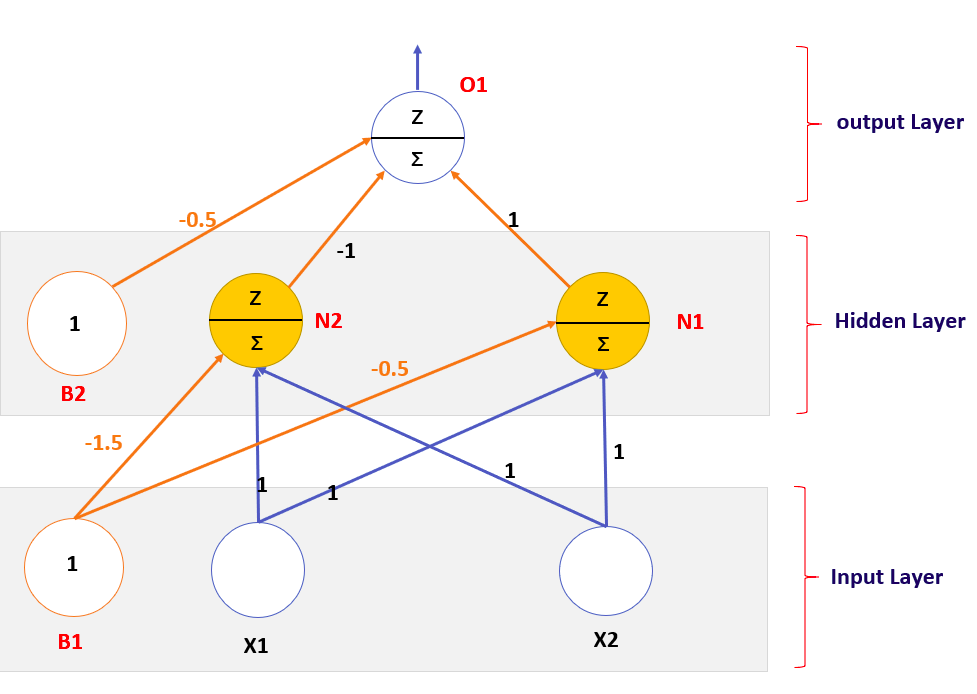
XOR 게이트에서 하얀색 원과 검정 원을 직선 하나로 나누는 것은 불가능하므로 단층퍼셉트론으로는 XOR 게이트를 구현할 수 없다. 따라서 위의 좌측 그림과 같이 적어도 두 개의 선이 필요하다. 즉, 우측 그림의 다층퍼셉트론 모델이 필요하지만 1969년 당시에는 이러한 모델을 학습시킬 방법이 존재하지 않았고, 이는 학계에서 약 20년간 인공신경망을 연구하지 않는 결과(1차 AI 겨울)를 초래하였다.
다층퍼셉트론(Multi Layer Perceptron, MLP)
다층퍼셉트론을 사용하면 여러 개의 선으로 분류하는 효과를 얻을 수 있기 때문에 XOR 게이트의 분류 문제를 해결할 수 있게 된다.
img) 다층퍼셉트론 구조
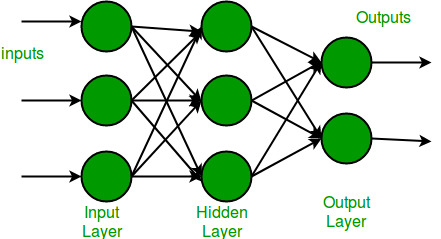
단층퍼셉트론은 입력층과 출력층만 존재하지만, 다층퍼셉트론은 중간에 은닉층(Hidden Layer)이라 불리는 층을 더 추가하였다.
은닉층이 존재할 경우 XOR 게이트는 기존의 AND, NAND, OR 게이트의 조합으로 만들 수 있기 때문에 퍼셉트론에서 층을 추가하면서 만들 수 있다. 이렇게 층을 여러 겹으로 쌓아가면서 선형 분류만으로 풀지 못했던 문제를 비선형적으로 풀 수 있게 된다. 각 층에서 오차는 역전파 알고리즘(Back Propagation)을 통해 업데이트해 나간다.
역전파 알고리즘(Back Propagation)
다층퍼셉트론으로 단순한 XOR 문제를 해결할 수 있었지만, 복잡한 비선형 구조의 XOR 문제는 다층퍼셉트론을 이루는 수많은 퍼셉트론 각각의 가중치(Weight)와 편향(Bias) 값을, 복잡하고 어렵다는 이유로 수정할 방법이 없었다.
이러한 복잡한 비선형 구조의 XOR 문제를 해결하기 위해 1986년 제프리 힌튼 교수는 다층퍼셉트론(MLP) 구조를 이용해 어떤 결과가 예측되었을 때, 그 예측이 틀리다면 은닉층 노드들의 오차를 확인하고 오차가 작아지는 방향으로 역전파(Backward)시켜 가중치와 편향 값을 학습시키는 신경망을 제안하여 이를 해결함을 입증하였다. 이를 역전파 알고리즘이라 한다.
역전파 알고리즘의 의외
- 딥러닝(Deep Learning)의 가중치 학습의 개념 정립
- 속도는 느리지만, 모델의 안정적인 결과를 얻을 수 있는 장점
- 다층퍼셉트론의 은닉층 학습 한계 해결(XOR 문제 해결)
역전파 알고리즘은 순전파와 역전파를 반복적으로 수행하면서 가중치와 편향을 최적화시키며, 수행 절차는 다음과 같다.
img) 역전파 알고리즘 학습절차(1)
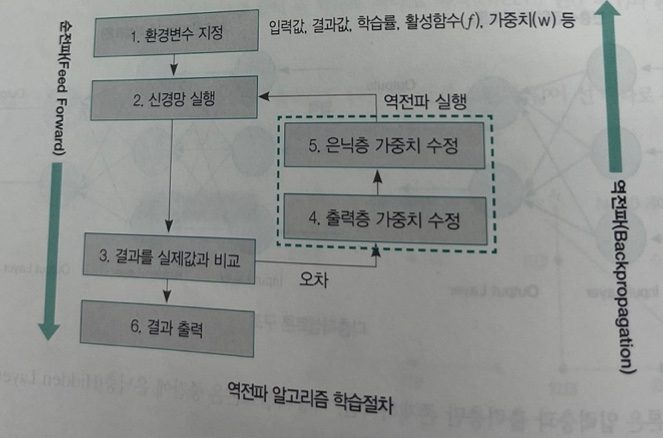
순전파 신경망(FeedForward Neural Network, FNN)은 정보의 흐름이 순환 사이클(Cycle) 없이 입력층, 은닉층, 출력층으로 정보가 전방으로(한 방향으로) 전달되는 인공신경망인데 반해, 역전파 알고리즘은 출력층, 은닉층, 입력층 역순(순전파와 반대로)으로 정보가 전달된다.
img) 역전파 알고리즘 학습절차(2)

결론적으로 역전파 알고리즘은 인공신경망의 가중치와 편향을 손실 함수(Loss Function)와 학습 알고리즘(Learning Algorithm)을 이용하여 최적화시키는 매커니즘을 제시하였다.
손실 함수(Loss Function = 비용 함수, Cost Function)
손실 함수는 지도학습(Supervised Learning)에서 모델(알고리즘)이 예측한 값과 실제 정답의 차이를 비교하기 위한 함수이다.
즉, '학습 중에 알고리즘이 얼마나 잘못 예측하는 정도'를 확인하기 위한 함수로써 파라미터를 최적화(Optimization)하기 위해 손실 점수(Loss Score)를 최소화하는 것이 목적이 된다.
신경망 성능의 "나쁨"을 나타내는 지표로, 현재 모델이 훈련 데이터를 얼마나 잘 처리하지 못하느냐를 나타내는 지표로 사용하게 된다.
img) 지도학습 절차에서의 손실 함수의 위치
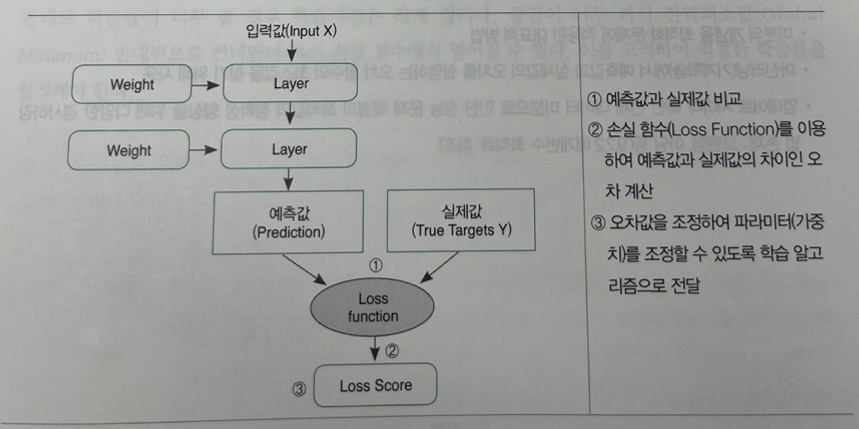
모델 학습 중에 손실 점수(Loss Score)가 커질수록 학습이 잘 안 되고 있다고 해석할 수 있고, 반대로 손실 점수가 작아질수록 학습이 잘 이루어지고 있다고 해석한다. 이처럼, 손실 함수는 모델 학습의 길잡이 역할을 하는 중요한 역할을 담당하게 된다.
참고 : 성능지표와 손실 함수의 차이
성능지표 : 알고리즘의 학습이 끝났을 때 모델의 성능을 평가하기 위한 지표(정확도, F1 점수, 정밀도 등)
손실 함수 : 알고리즘 학습 중에 얼마나 잘 되고 있는지 평가하기 위한 지표
img) 손실 함수의 종류
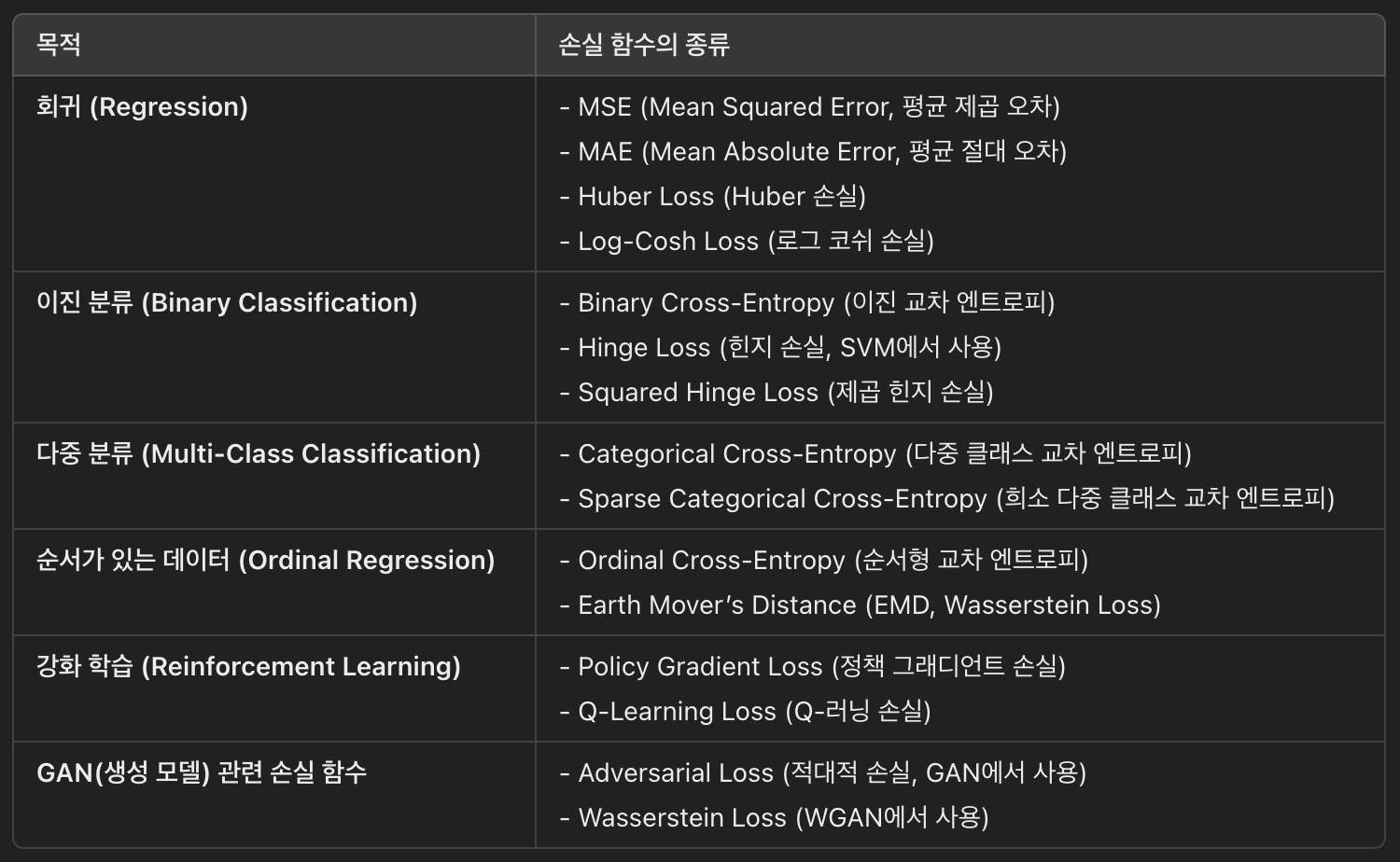
손실 점수를 파라미터(가중치)에 최적화시키기 위한 알고리즘으로 경사하강법 등을 사용하게 된다.
경사하강법(Gradient Descent)
경사하강법은 역전파 알고리즘을 이용하여 기울기가 0이 되는 것을 판단하는 방법으로 손실 점수(Loss Score)를 미분하여 가중치를 최적화시키는 역할을 한다. 손실 점수의 기울기가 0이 된다는 의미는 가중치의 변화가 더 이상 없음을 설명하며, 이는 가중치가 최적화됐음을 뜻한다.
경사하강법의 사전적 의미는 기울기 하강 혹은 기울기 확장으로 풀이할 수 있으며, 손실 함수의 최소 값 위치를 찾기 위해, 손실 함수의 기울기 반대방향으로 학습률만큼 조금씩 이동해 가면서 최적의 파라미터를 찾으려는 알고리즘(오차의 최소 값을 찾기 위해 사용되는 기법)이다.
- 미분의 개념을 최적화 문제에 적용한 대표적 방법
- 머신러닝(기계학습)에서 예측 값과 실제 값의 오차를 설명하는 오차 함수의 최소 값을 찾기 위해 사용
- 업데이트 시마다 매번 전체 데이터 미분으로 인한 성능 문제 해결과 최적 값의 정확성 향상을 위해 다양한 경사하강법 존재 : 모멘텀, 아담 등
img) 경사하강법 원리
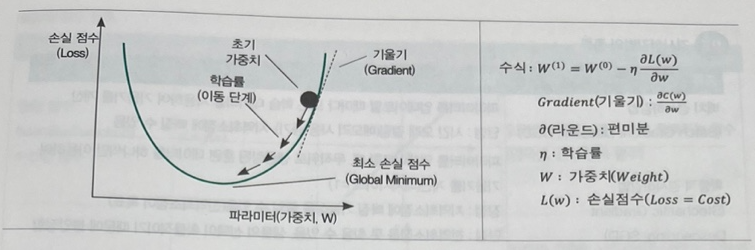
임의의 초기 가중치(W)를 선정하여 손실 점수L(W)를 계산하고 이를 편미분한 기울기를 이동 방향으로, 학습률만큼 이동하게 된다. 이 과정을 반복하면서 손실 함수의 편미분 값이 0이 됐을 때의 가중치(전역최소 값, 최소 손실 점수)가 모델의 최적 파라미터로 확정된다.
img) 경사하강법 매커니즘

모델을 학습할 때 학습률은 경사하강법에서 얼마만큼 경사각을 내려갈 것인지 정하는 하이퍼파라미터이다. 학습률이 작을 경우 최소 손실 점수에 수렴하기 위해 반복해야 하는 값이 많으므로 학습시간이 오래걸리며, 지역최소값(Local Minimum)에 수렴할 수 있다.
반대로 학습률이 너무 클 경우 학습시간은 적게 걸리나, 증감이 너무 커서 전역최소값(Global Minimum) 반대편으로 건너뛰어 최소 손실 점수에서 멀어질 수 있다. 이를 고려하여 적절한 학습률을 설정해야 한다.
img) 경사하강법의 종류
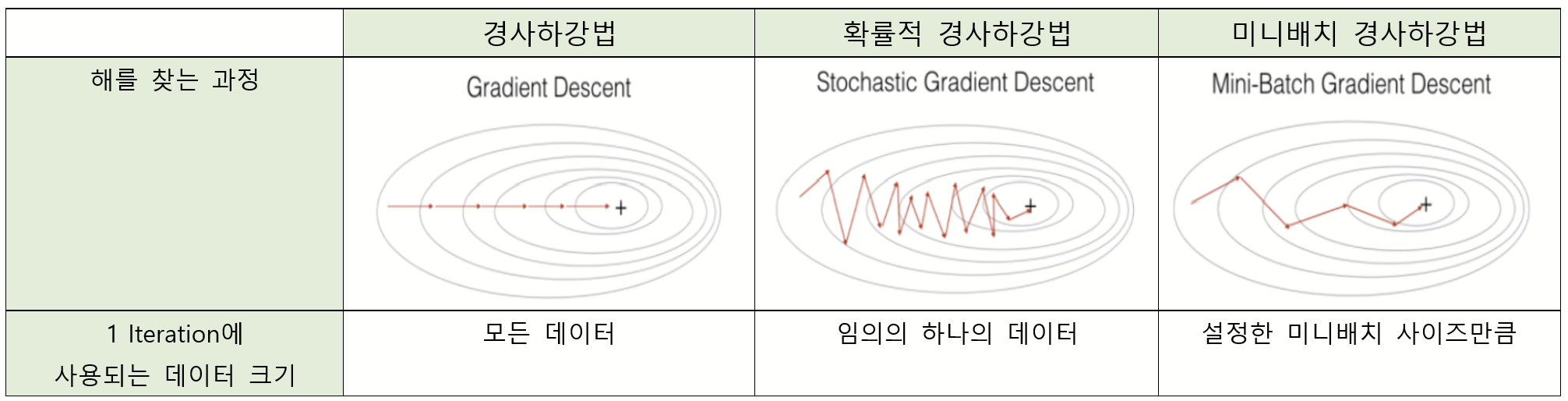
지역최소점(Local Minimum) : 가장 작은 값을 찾았다고 생각되는 가중치
전역최소점(Global Minimum) : 실제 가장 작은 값을 갖는 가중치(목표 파라미터)
인공신경망 활성화 함수(Activation Function)
퍼셉트론(Perceptron)은 입력(Input X)과 가중치(Weight)들의 곱을 모두 더한 뒤 활성화 함수(Activation Function)를 적용해서 그 값이 0보다 크면 1, 0보다 작으면 -1을 출력하는 선형 분류기의 구조였다.
예를 들어, 아래 그림에서처럼 입력 값에 의해 1,000의 값이 계산되었다고 가정했을 때, 입력 값을 100으로 나누는 활성화 함수를 사용하면, 다음 노드로 전달하는 값은 10이 된다.
img) 활성화 함수의 이해
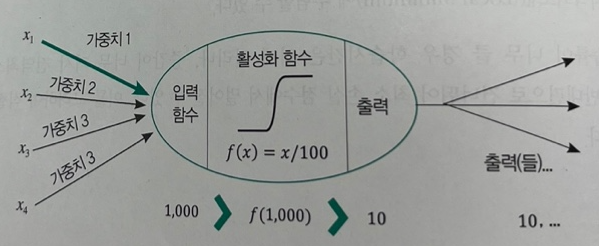
즉, 활성화 함수를 이용하여 입력된 데이터의 가중합을 출력신호로 변환하여, 은닉층의 출력 값을 특정 범위의 실수 값으로 정규화하고 은닉층과 출력층에서 각 출력 값을 제한하기 위해 사용된다.
은닉층의 활성화 함수
은닉층에서 사용되는 활성화 함수는 다음과 같은 종류들이 있다.
img) 활성화 함수 종류

인공신경망 초기의 활성화 함수는 시그모이드 함수(Sigmoid Function)와 하이퍼볼릭탄젠트 함수(Tanh Function)를 사용하였으나, 출력 값이 작은 범위(Sigmoid : 0과 1사이, Tanh : -1과 +1사이)로 제한되는 특징이 있어, 기울기 소멸 문제(Vanishing Gradient)의 원인이 되었다. 이를 해결하기 위해 고안된 활성화 함수가 렐루 함수(ReLU), 파라메트릭 렐루 함수(PReLU)이다.
다차원 배열의 행렬곱 연산
다차원 배열의 계산은 앞서 설명한 가중치의 값을 보다 편하게 하기 위해서 행렬 연산을 이용하는 것이다. 한두 개의 신경망 층은 인간이 계산할 수 있을지 모르겠지만 그 이상의 수많은 차원의 수많은 뉴런층으로 구성된 신경망의 가중치(Weight)를 일일이 계산하는 것은 불가능한 일이다. 이를 쉽게 할 수 있도록 돕는 것이 행렬 연산이다.
img) 다차원 배열의 행렬곱 연산 이미지
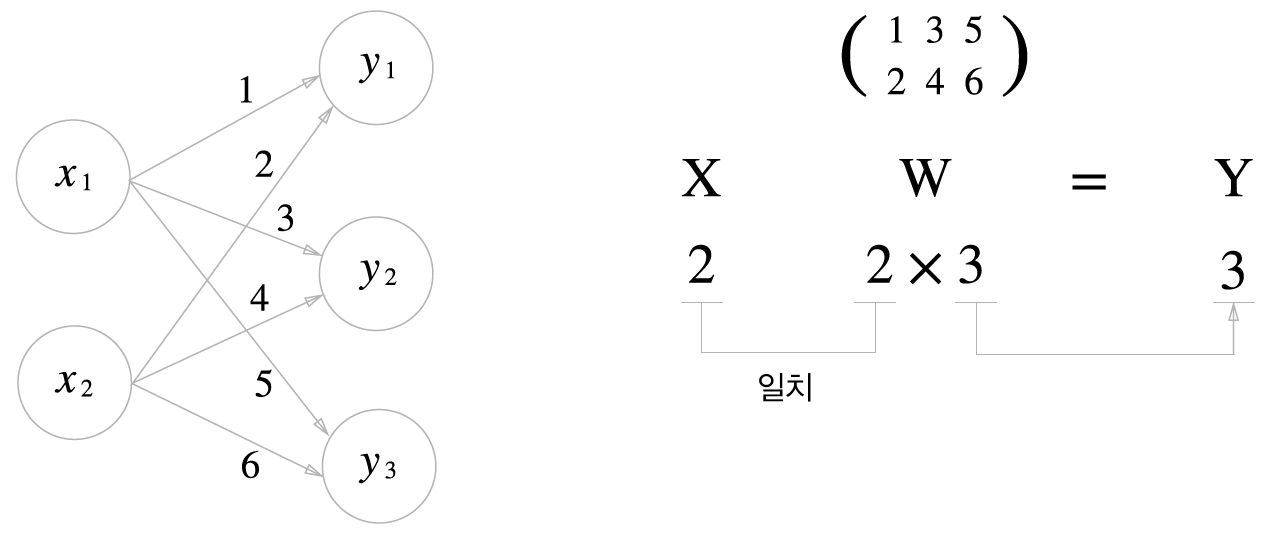
위의 예제 (1 x 2) x (2 x 3)의 행렬곱이다. 안쪽이 2 = 2로 동일하고 결과 값은 1 x 3으로 바깥쪽의 값으로 이루어진 행렬 차원을 보인다. Y의 값들은 활성화 함수를 통해 변환된다.
출력층의 활성화 함수
소프트맥스 함수(Softmax Function)는 출력노드(Output Node)의 출력값을 0~1로 제한하는 활성화 함수이다.
img) Softmax Function

위 사례와 같이 소프트맥스 함수에 의해 1, 2값은 0.46, 0.9값은 0.34, 0.4값은 0.20으로 제한되었으며 출력 값의 합은 1이 됨을 알 수 있다. 최종 출력 값으로 0.46이 가장 높다는 것을 알았기 때문에 이는 곧 정답(1)이 됨을 의미하며, 0.46을 1으로, 0.34와 0.20을 0으로 변환할 수 있는데, 이러한 값으로 변환하는 워드임베딩(Word Embedding) 방식을 원핫인코딩(One Hot Encoding)이라고 한다.
참고 : 워드임베딩(Word Embedding)
- 워드임베딩은 단어 간 유사도 및 중요도 파악을 위해 단어를 저차원의 실수 벡터로 맵핑하여 의미적으로 비슷한 단어를 가깝게 배치하는 수치화 방법이다.
기울기 소멸 문제(Vanishing Gradient Problem) 및 해결 방법
기울기 소멸 문제의 이해
기울기 소멸 문제란 역전파 알고리즘으로 가중치를 수정할 때, 은닉층으로 오차가 거의 전달되지 않는 문제이다. 바꿔 말하면 인공신경망 활성화 함수의 출력 값이 곱해지다 보면 가중치에 따른 결과 값의 기울기가 0이 되어 버려서, 경사하강법을 이용할 수 없게 되는 문제라 정리할 수 있다.
img) 기울기 소멸 문제
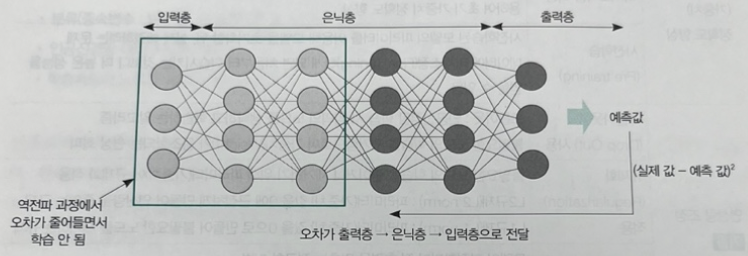
이는 인공지능 2차 암륵기의 주요 원인으로, 많은 연구와 논문이 기각(Reject)되는 상황을 만들었으며, 발생 원인은 다음과 같이 정리할 수 있다.
img) 기울기 소멸 문제의 주요 발생 원인

기울기 소멸 문제 해결 방법
기울기 소멸 문제는 시그모이드 활성화 함수를 렐루(ReLU) 활성화 함수로 변경함으로 발생 가능성을 낮출 수 있으며, 그 외에 적용할 수 있는 방법은 다음과 같다.
img) 기울기 소멸 문제 해결 방법
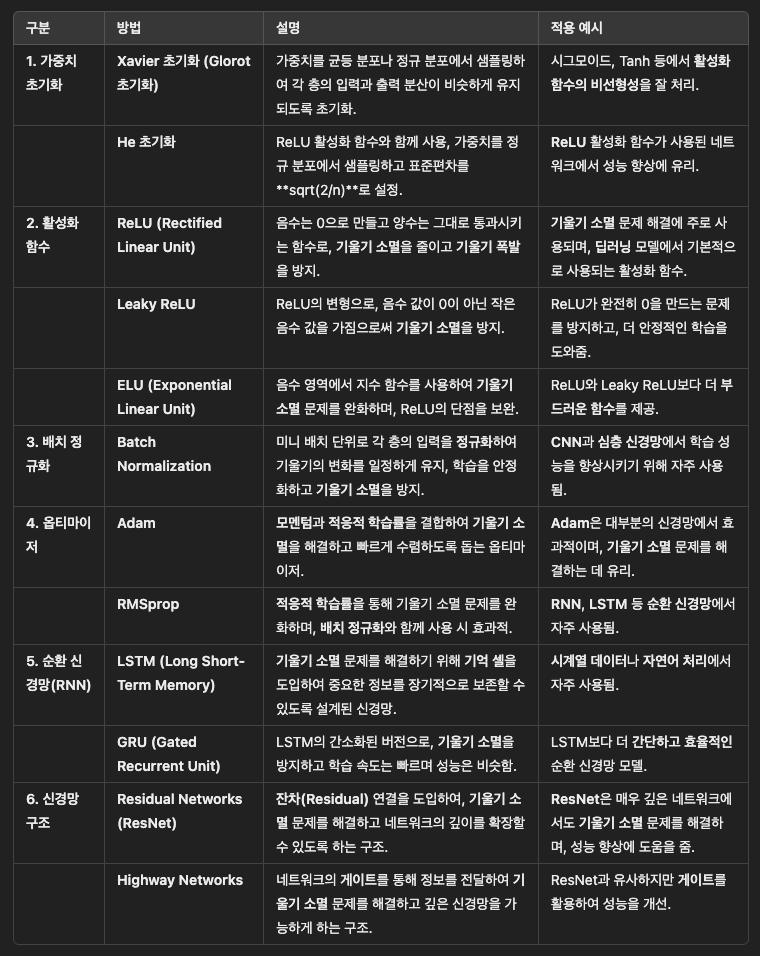
2006년 힌튼(Hinton) 교수서가 기울기 소멸 문제에 대한 해법을 제시하였음에도 불구하고 인공신경망이라는 주제는 학회에서 냉대를 받았다. 그래서 부정적 이미지를 가지고 있던 인공신경망이라는 이름은 심층신경망(Deep Neural Network) 혹은 딥러닝(Deep Learning)으로 다시 태어나게 되었다.
이러한 과정을 거쳐 2016년 알파고(AlphaGo, 알파벳의 구글 딥마인드에서 개발한 바둑 인공지능 프로그램)의 등장이 있었고, 또한 많은 연구들이 활발히 진행되고 있다.
참고 : 기울기 폭주(Gradient Exploding)
- 기울기 폭주 : 기울기가 점차 커져 파라미터(가중치)들이 비정상적으로 큰 값이 되면서 결국 발산되어 파라미터(가중치) 학습이 안 되는 문제점
- 기울기 소멸(Gradient Vanishing)과 학습 효율의 문제점은 유사함
다음 SVM부터 계속.
