서포트벡터머신
서포트벡터머신의 이해
서포트벡터머신(Support Vector Machine, SVM)은 블라디미르 배프니크(Vladimir Vapnilk)와 그의 동료에 의해 1992년 최초로 정립된 선형과 비선형 분류, 회귀(예측) 및 이상 값 분류에도 사용할 수 있는 패턴인식, 자료분석 등에 활용되는 지도학습 알고리즘이다(인공지능의 2차 암흑기는 서포트벡터머신과 같은 우수한 알고리즘의 등장도 원인이 되었다)
서포트벡터머신의 특징
- 지도학습에서의 과적합(Over Fitting) 회피
- 분류(종속변수 : 범주형), 회귀(종속변수 : 연속형)의 문제 활용
- 인공신경망 대비 사용이 쉬움
- 학습속도가 느리고 해석의 어려움 존재
서포트벡터머신은 최대 마진을 가지는 선형 판별에 기초하며, 속성들 간의 의존성은 고려하지 않는다. 아래 그림처럼 데이터가 사상(관련된)된 공간에서 경계선과 근접한 데이터(Support Vector) 간의 거리가 가장 큰 경계(마진, Margin)를 식별하여 새로운 데이터가 경계 밖, 어느 범주에 속하는지 분류(Classification)한다.
또한 경계와 경계 안의 데이터가 얼마나 많이 사상되는지를 판단하고 경계 밖의 에러 값이 최소가 되도록 정의하여 새로운 데이터를 예측(회귀, Regression)하게 된다. 즉, 서포트벡터머신은 분류와 회귀에 모두 사용할 수 있다.
img) 서포트벡터머신의 이해: 분류 기반

서포트벡터머신에서 데이터가 n차원으로 주어졌을 때 데이터를 n - 1차원의 초평면(하이퍼플레인)으로 분리한다. 2차원의 데이터에서는 초평면은 1차원의 선이 되고, 3차원의 데이터에서는 초평면이 2차원인 면이 된다. 또한 초평면에서 가장 가까운 데이터를 서포트벡터라 하고 서포트벡터끼리 거리를 마진(Margin)이라고 한다. 서포트벡터머신은 집단 사이의 마진이 최대화하는 것을 기준으로 초평면을 학습한다. 이러한 과정이 서포트벡터머신의 최적화 과정이다.
img) 2, 3차원의 초평면 구조
대부분의 머신러닝 지도학습 알고리즘은 학습 데이터 모두를 사용하여 모델을 학습한다. 그런데 서포트벡터머신에서 결정경계를 정의하는 것은 서포트벡터이기 때문에 데이터 포인트 중에서 서포트벡터만 잘 골라내면 나머지 쓸 데 없는 수많은 데이터 포인트들을 무시할 수 있다. 그래서 효율적인 자원 소모가 가능하다.
하드마진과 소프트마진
마진(Margin)은 결정경계와 서포트벡터 사이의 거리를 의미하는데, 이상 값(Outlier)을 얼마나 허용할 것인가에 따라 소프트마진과 하드마진으로 구분할 수 있다. 서포트벡터머신은 데이터 포인트들을 올바르게 분리하면서 마진의 크기를 최대화해야 하는데 이는 결국 이상 값을 잘 다루는 게 중요함을 의미한다.
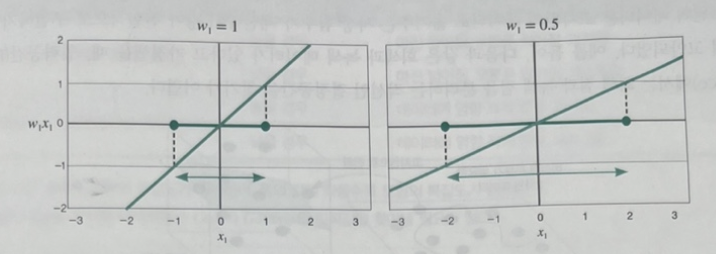
초평면(결정경계, 하이퍼플레인)의 가중치(Weight, 기울기)가 작아질수록 마진의 경계 폭이 커지게 된다. 따라서 결정경계 마진의 폭을 크게 하기 위해서 초평면을 최소화해야 한다.
img) 가중치에 따른 경계 폭
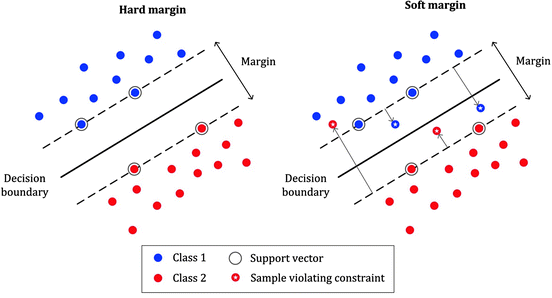
하드마진과 소프트마진 두 기법 모두 분류모델에 사용된다. 하드마진(Hard Margin)은 모든 데이터(양성/음성)가 결정경계의 마진 밖으로 위치하는 가중치(W, 기울기)를 찾는 방법이다. 아래 그림에서 하드마진은 이상 값을 허용하지 않고 기준을 까다롭게 세웠으며, 서포트벡터와 결정경계 사이의 거리가 매우 좁은 것을 알 수 있다(마진이 작아짐). 이는 이상 값이 존재할 경우 민감하게 반응할 수 있다는 의미이며 과적합에 빠질 수 있다.
또한 소프트마진(Soft Margin)은 결정경계 마진 안에 위치하는 데이터의 수를 제한하면서 결정경계 도로의 폭이 최대가 되도록 하는 가중치(W, 기울기)를 찾는 방법이다. 마진 안에 어느 정도 데이터가 포함되도록 여유롭게 기준을 잡았다. 서포트벡터와 결정경계 사이의 거리가 멀어진 것과(마진이 넓어짐), 일부 이상 값이 포함된 것도 확인할 수 있다.
실제 분석을 진행할 때는 지나치게 많은 이상 값의 존재를 허용하지 않는 기울기를 찾는 것이 중요하다. 이상 값 포함이 증가될수록 과소적합에 문제가 발생할 수 있다.
img) 하드마진과 소프트마진
커널 기법
서포트벡터머신은 커널 기법을 이용하여 비선형 분류를 가능하게 한다. 커널 기법(Kernel Method)은 저차원의 데이터를 고차원의 데이터로 옮겨주는 사상 함수가 계산량이 많아 현실적으로 구현하기 어렵기에 고안되었다. 예를 들어, 다음과 같은 파란색과 빨간색 데이터가 있다고 가정했을 때, 입력공간(Input Space)에서는 파란색 점과 빨간색 점을 분리하는 직선인 결정공간을 찾기가 어렵다.
img) 커널트릭
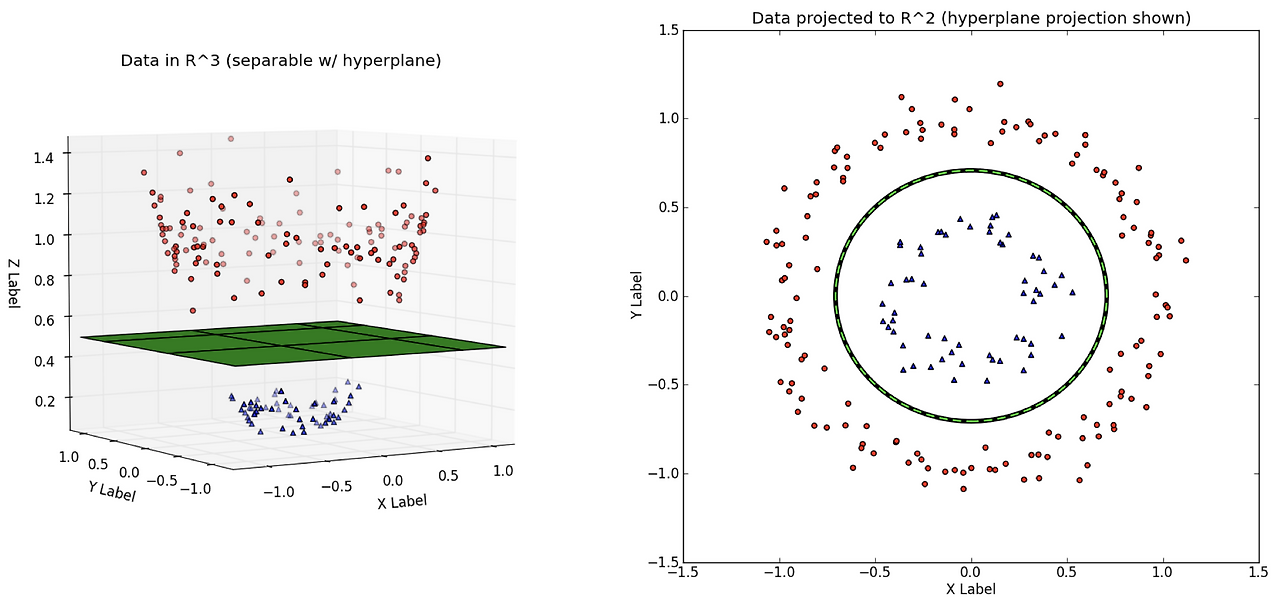
따라서 커널 기법을 사용하면 저차원의 데이터를 고차원으로 변환하여 저차원 데이터의 비선형 분류가 가능하게 된다. 이를 커널트릭(Kernel Trick)이라고도 한다.
참고 : 커널트릭
커널 기법의 한 종류로 벡터의 내적을 계산할 경우 연상량이 많은 사상 함수(Mapping Function)를 사용하지 않고 커널 함수를 정의하여 저차원의 데이터로 직접 계산할 수 있게 해주는 방법
서포트벡터머신과 함께 사용되는 커널의 종류는 다음과 같다.
img) 커널 종류
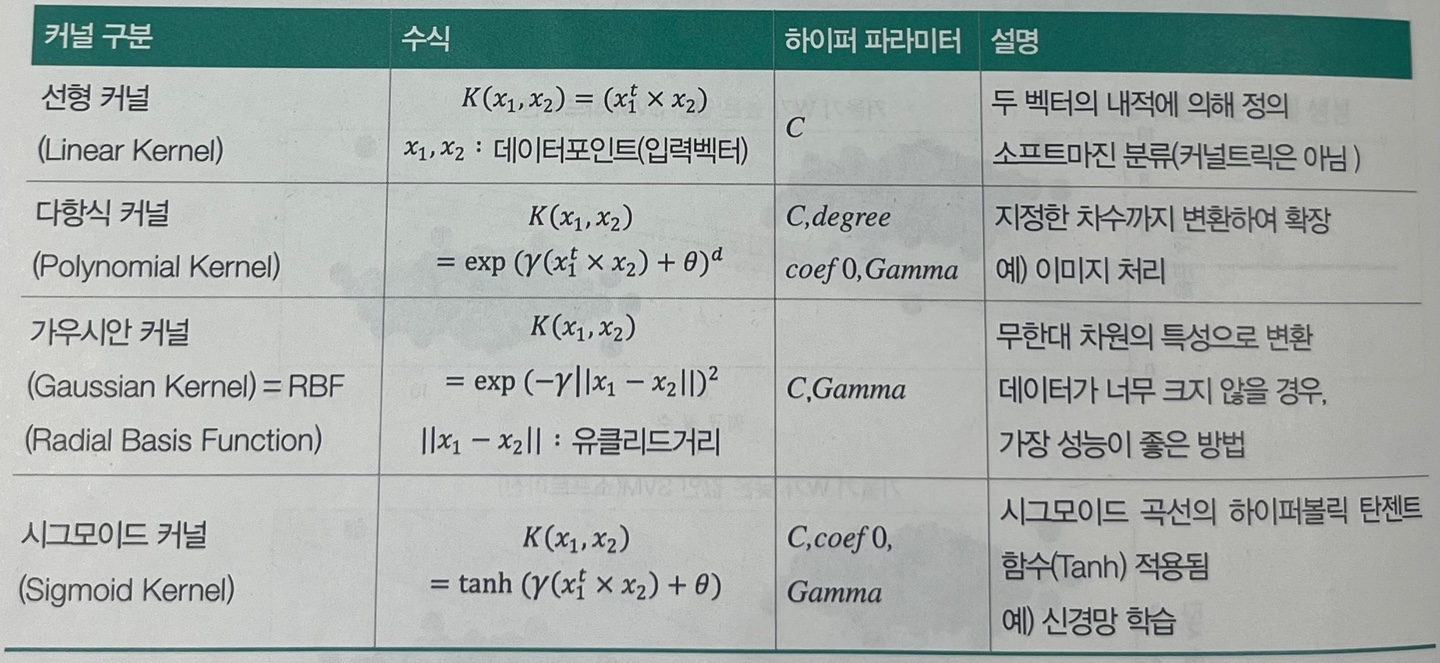
C(Cost): 모델에 규제를 적용하는 값(float)
D(Degree): 다항식의 차수
θ(Theta): coef 0는 모델이 높은 차수와 낮은 차수에 얼마나 영향을 받을 지에 대해 조절
γ(Gamma): 가우시안 커널의 폭을 제어하는 매개변수. 모델이 생성하는 경계가 복잡해지는 정도
참고 : 커널트릭에서 사용하는 하이퍼파라미터 C(Cost), γ(Gamma)
img) 하이퍼파라미터 C(Cost), γ(Gamma)

둘의 값이 클수록 모형의 복잡도가 증가하며, 둘의 값이 작을수록 모형의 복잡도가 감소한다.
모형의 성능을 최적화/극대화하는 Cost와 Gamma의 최적 값을 찾아낼 필요가 있다.
연관분석
연관분석의 이해
연관분석(Association Analysis)은 데이터들에 대한 발생빈도를 기반으로 각 데이터 간의 연관관계를 밝히기 위한 방법이다. 상품을 구매하거나 일련의 사건의 데이터에서 존재하는 항목 간의 연관규칙을 발견하는 과정으로 복잡한 알고리즘 없이도 결과를 도출할 수 있다.
연관분석은 종속변수가 미존재하는 비지도학습의 한 종류이며, 주로 거래 구매항목에 존재하는 품목들 간의 연관성 규칙을 추론할 때 사용하기 때문에 장바구니 분석(Market Basket Analysis)이라고도 한다.
img) 연관분석 장점 및 단점

연관분석 측정지표
데이터들에 대한 발생빈도를 기반으로 각 데이터 간의 연관관계를 밝히기 위한 측정지표로는 지지도, 신뢰도, 향상도가 있다.
img) 연관분석을 위한 3가지 측정지표

- 샘플이 적을 경우 지지도를 통하여 연관관계에 대한 통계적 유의성을 증명하기 어려움
지지도는 전체 거래 중에서 X와 Y가 동시에 판매되는 사건을 의미하기 때문에 빈발항목 집합으로 구분 가능하다. 이때는 모든 경우의 수를 분석하는 것은 현실적 어려움이 있으므로 최소지지도를 설정해 이 값을 기준으로 규칙을 도출한다.
img) 연관분석 사례

참고 : 연관규칙 활용 예시
img) 연관규칙 활용 예시

연관분석은 가능한 모든 경우의 수를 탐색할 경우 계산에 소요되는 시간과 노력이 기하급수적으로 증가하게 된다. 이에 따라 빈발항목을 식별하고 이를 통해 계산의 복잡도를 낮추는 알고리즘으로 선험적 규칙(Apriori Principle)을 사용한다.
선험적 규칙 알고리즘
선험적 규칙(Apriori Algorithm)은 전체 항목(Item)에서 최소 N번의 트랜잭션(사건, 거래)이 일어난 항목 집합들을 발견하는 알고리즘이다(적절한 품목을 세분화하는 과정). 만약 k개의 품목이 존재한다고 했을 때 조합이 가능한 품목 집합은 2^k개가 존재한다. K가 아주 크다면 이 모든 집합 중에 지지도가 높은 집합을 찾아 연관성을 분석하는 것은 현실적으로 불가능할 것이다.
따라서 여러 품목 중 최소지지도보다 큰 집합만을 대상으로 높은 지지도를 갖는 품목 집합을 찾기 위한 알고리즘이 선험적 규칙이다. 즉 비 빈발항목 집합(전체)에서 빈발항목 집합을 도출하게 된다.
img) 선험적 규칙의 이해

빈발항목 집합을 도출하는 과정은 다음과 같다.
img) 선험적 규칙(Apriori) 알고리즘 사례
총 4건의 거래 중 각 거래(TR ID)에 포함된 품목들에 대한 빈발항목 집합 도출 사례
최소지지도: 2
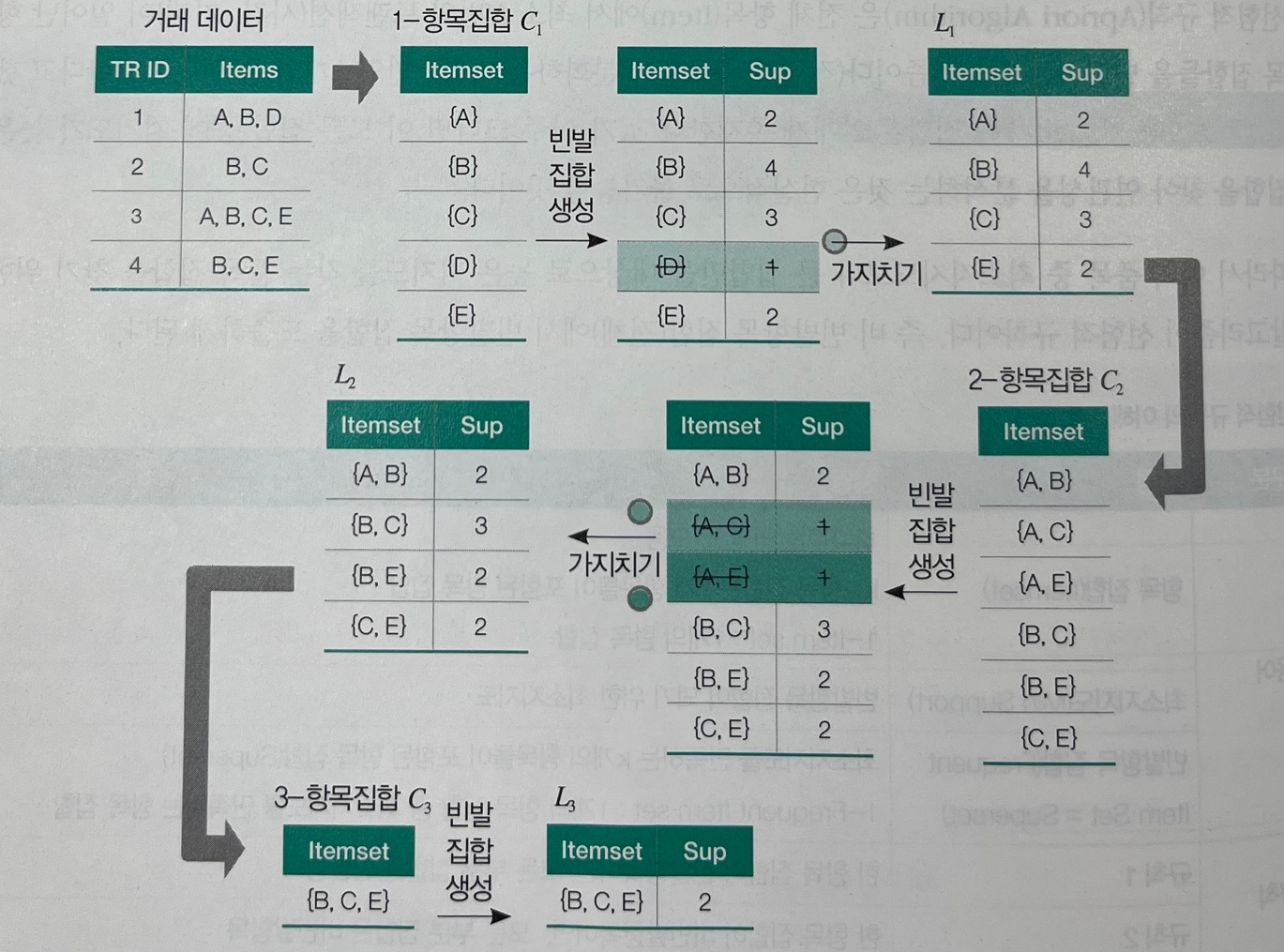
img) 선험적 규칙(Apriori) 알고리즘 사례

빈발패턴성장 알고리즘(FP-Growth)
빈발패턴성장(Frequent Pattern, FP-Growth) 알고리즘은 분석해야 할 데이터가 증가하면서, 선험적 규칙(Apriori) 알고리즘의 연산 속도를 개선한, 트리(Tree) 구조 기반의 연관규칙 알고리즘이다. 알고리즘을 적용하는 순서는 다음과 같다.
img) 빈발패턴성장 알고리즘 도출 과정

빈발패턴성장 알고리즘은 트리(Tree) 구조이기 때문에 선험적 규칙(Apriori)보다 훨씬 빠르며, DB에서 스캔하는 횟수도 줄어든다. 빈발패턴성장 알고리즘은 첫 번째 스캔으로 단일 항목 집단을 만들고, 두 번째 스캔으로 트리 구조를 완성한다. 후보 항목 집합(Itemset)을 생성할 필요없이, 트리(Tree)만 구성하면 되는 장점이 있다.
반면에 대용령 데이터 셋에서 메모리를 효율적으로 사용하지 못한다는 것과 선험적 규칙(Apriori)에 비해 설계가 어렵고, 지지도의 계산은 무조건 빈발패턴트리(FP-Tree)가 만들어져야 가능하다는 단점이 존재한다.
군집분석
군집분석의 이해
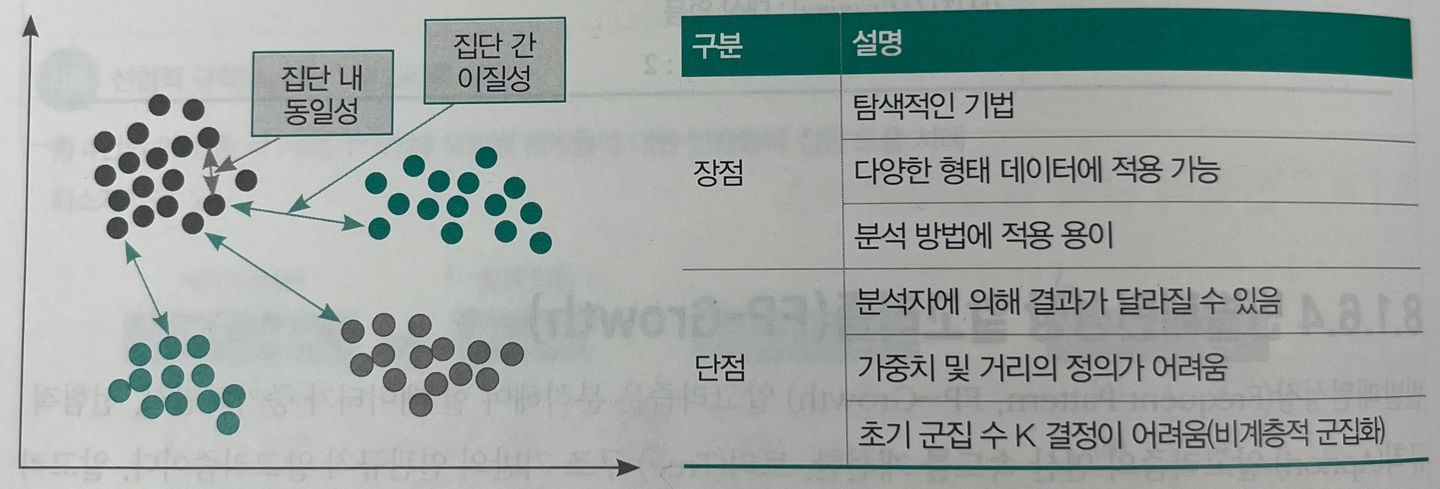
군집분석(Clustering Analysis)은 여러 개체(데이터) 중에서 유사한 속성을 지닌 대상을 몇 개의 집단으로 그룹화한 다음, 각 집단의 성격을 파악함으로써 데이터 전체의 구조에 대해 이해하고자 하는 탐색적 분석 방법이다(비지도학습).
img) 군집분석 집단 간 성질과 장/단점
군집분석의 척도
군집분석은 데이터의 유사한 혹은 동질의 군집(Cluster)화 작업이기 때문에 데이터 간 유사성을 판단해야 한다. 이때 비유사도(Dis-Similarity)와 유사도(Similarity)를 척도로 활용한다.
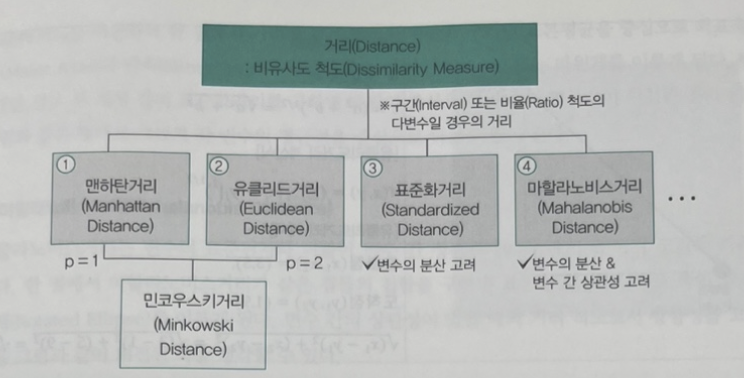
(1) 비유사도 척도(=거리 기반 척도, Distance)
비유사도는 두 데이터(개체)의 다른 정도에 대한 수치적인 척도로 두 대상 사이의 떨어진 정도를 나타내므로 값이 클수록 서로 거리가 멀다는 것을 나타내고(유사하지 않음), 작을수록 거리가 가깝다는 것(유사하다)을 의미한다. 거리(Distance)는 비유사도와 동의어이며, 하한 값은 0, 상한 값은 제한이 없다.
대표적인 비유사도 척도는 다음과 같다.
img) 비유사도 척도의 종류
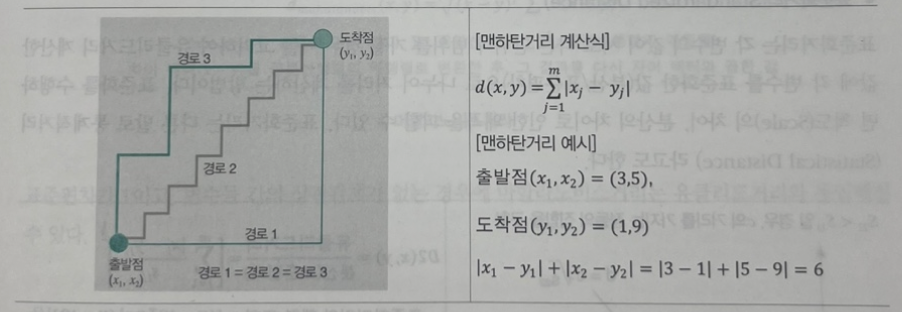
맨하탄거리(Manhattan Distance)
맨하탄거리는 뉴욕의 택시가 출발지에서 도착지까지의 거리를 측정할 때, 가로 블록과 세로 블록의 거리를 절대합으로 계산하는 것을 보고 이름 붙여진 비유사도 척도이다.
물리적인 거리를 생각해보면 택시가 길과 길 사이에 있는 빌딩을 대각선으로 지나갈 수는 없다. 빌딩을 피해 도로를 기반으로 최단 거리를 찾을 수밖에 없기 때문에 두 점의 값(출발지 -> 도착지)에 대한 맨하탄거리는 각 좌표간의 차이를 절대 값으로 계산한다.
img) 맨하탄거리
유클리드거리(Eucildean Distance)
유클리드거리는 두 점을 잇는 가장 짧은 직선거리다. 아래 그림을 예로 들면, x지점에서 y지점으로 날아간다고 했을 때 x와 y지점 사이에 아무리 많은 빌딩이 있더라도 상관없이 최단 직선을 나타낸다.
m차원 유클리드 공간(Eucildean Space)에서 두 점(x1, x2), (y1, y2)의 거리는 피타고라스정리(Pyrhagorean Theorem)에 의해서 아래 그림에서 제시한 공식으로 구할 수 있다.
img) 유클리드거리

민코우스키거리(Minkowski Distance)
민코우스키거리는 맨하탄 거리와 유클리드거리를 한 번에 표현한 거리 척도이다.
img) 민코우스키거리 수식
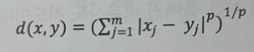
맨하탄거리는 민코우스키거리에서 p = 1이며, 유클리드거리는 p = 2(2-norm Distance)인 경우이다.
표준화거리(Standardized Distance)
표준화거리는 각 변수의 값이 서로 다른 단위나 범위를 가질 경우 이를 고려하여 유클리드거리 계산한 값에 각 변수를 표준화한 값(분산/표준편차)으로 나누어 거리를 계산하는 방법이다. 표준화를 수행하면 척도(Scale)의 차이, 분산의 차이로 인한 왜곡을 피할 수 있다. 표준화거리는 다른 말로 통계적거리(Standardized Distance)라고도 한다.
img) 표준화거리

표준화거리를 이용하여 한 점에서 거리가 같은 점들의 집합을 구하면 표본평균을 중심으로 좌표축에 장축(Major Axis)과 단축(Minor Axis)이 반듯하게 놓인 타원(Ellipse) 또는 타원체를 이루게 된다. 변수가 2개인 경우 두개체 간의 표준화거리를 구하면 타원의 중심은 각 변수의 평균 값이 위치한 곳이 되며, 위 그림과 같은 형태로 그려져 각 변수의 평균점을 중심으로 하는 타원이 된다.
마할라노비스거리(Mahalanobis Distance)
마할라노비스거리는 변수의 표준편차와 더불어 변수 간 상관관계(Correlation)까지 고려한 거리 척도이다. 한 점에서 마할라노비스거리가 같은 점들의 집합을 구하면 표본평균을 중심으로 축이 회전된 타원체(Rotated Ellipse)를 이루게 된다. 변수 간의 상관성이 있을 때 거리 척도로서 방향성을 고려하여 다음 그림과 같이 회전된 축을 생각할 수 있다.
img) 마할라노비스거리

표준편차가 1이고, 변수들 간의 상관관계가 없는 경우에 마할라노비스거리는 유클리드거리와 동일해질 수 있다.
유사도(Similarity)척도
유사도는 두 데이터(개체)의 닮은 정도에 대한 수치적인 척도로 음이 아닌 수, 0과 1사이의 값으로 표현할 수 있는 척도이다. 1에 가까우면 유사함을 의미하고 0에 가까우면 유사하지 않음을 의미한다.
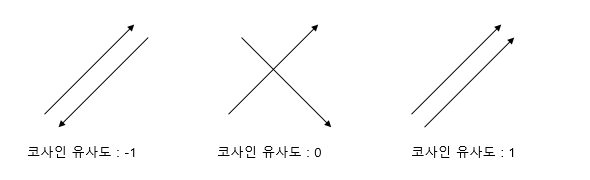
코사인유사도(Cosine Similarity)
코사인유사도는 벡터와 벡터 간의 유사도를 비교할 때 두 벡터 간의 사이각을 구해서 어마나 유사한지를 수치로 나타낸 척도이다. 따라서 벡터 방향이 동일한 방향(0도)를 나타내면 두 벡터는 서로 유사하며, 벡터 방향이 90도 일 때는 두 벡터 간의 관련성이 없고, 벡터 방향이 180도로 표현되면 두 벡터는 반대 관계를 보인다(각도가 0도일 때의 코사인 값은 1이며, 다른 모든 각도의 코사인 값은 1보다 작다).
img) 코사인유사도
코사인유사도를 구하는 식은 아래와 같다.
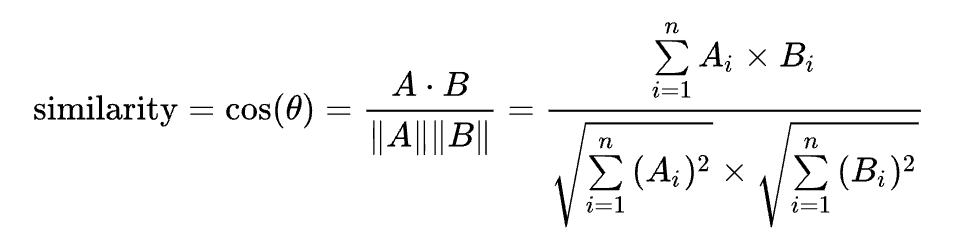
문서 간 유사도를 측정하는 방법 중 유클리드거리 기반의 지표도 있다. 하지만 희소행렬에서 문서와 문서 벡터 간의 크기에 기반한 유사도 지표는 정확도가 떨어진다. 또한 문서가 매우 긴 경우 단어의 빈도 수 또한 많기 때문에 빈도 수에만 기반해서 유사도를 구하는 것은 공정한 비교가 될 수 없다.
예를 들어 A 문서에서 '경제'라는 단어가 5번 나왔고, B 문서에서 '경제'라는 단어가 3번 언급되었다고해서 A 문서가 경제와 더 밀접한 문서라고 볼 수 없다. A 문서의 길이가 B 문서의 길이보다 10배 이상 크다면 오히려 B 문서가 경제와 더 관련이 있다고 판단해야 옳을 것이다. 따라서 문서 간 유사도를 측정할 때는 코사인유사도가 가장 많이 쓰인다.
참고: 코사인거리(Cosine Distance)
변환: 유사도를 비유사도로 변환하거나 그 역으로 변환하여 근접도 척도를 [0,1]과 같은 특정 범위로 적용하기 위해 사용
코사인거리: 코사인 유사도를 코사인거리로 변환하기 위해 1에서 코사인 유사도 값을 빼줌
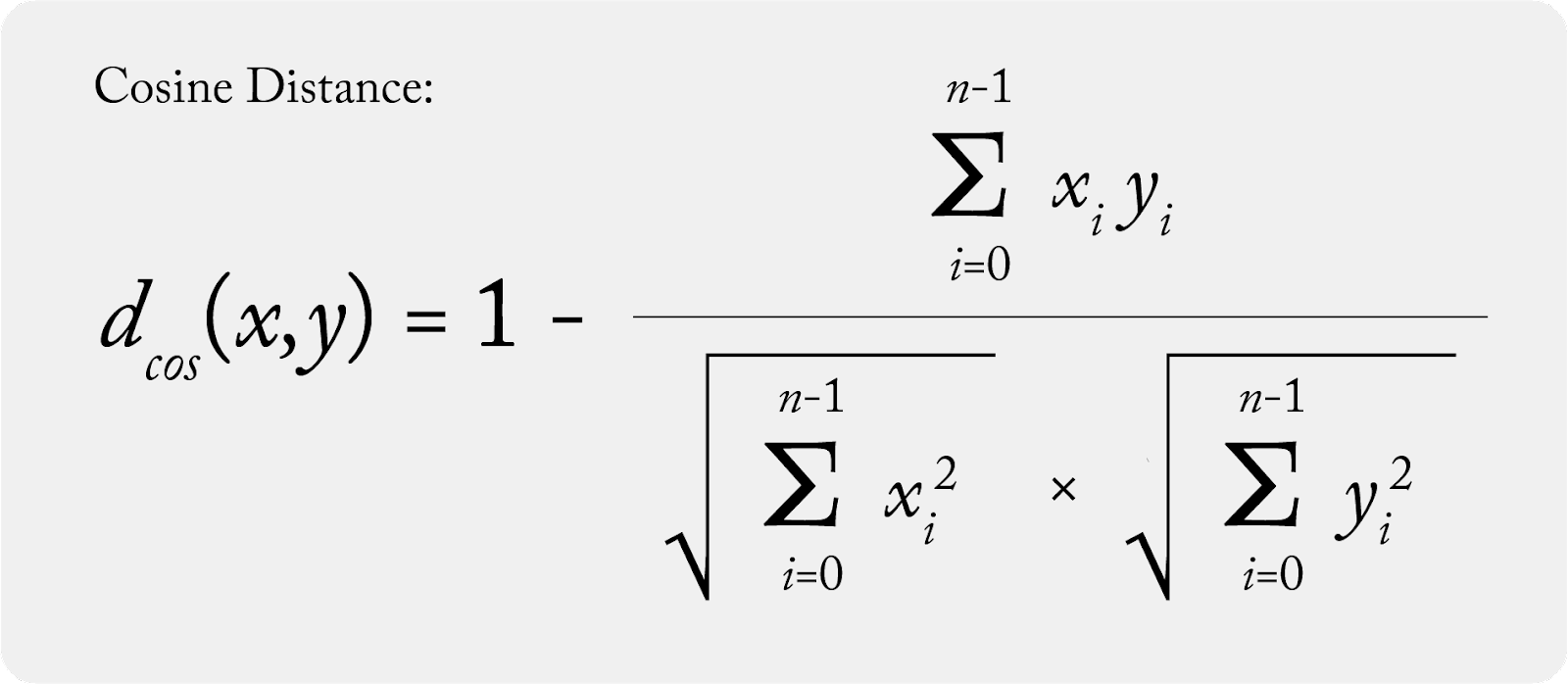
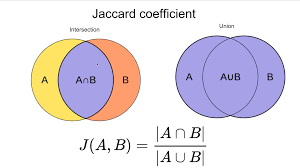
자카드유사도(Jaccard Similarity, 자카드계수)
자카드유사도는 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식 중 하나다.
img) 자카드유사도
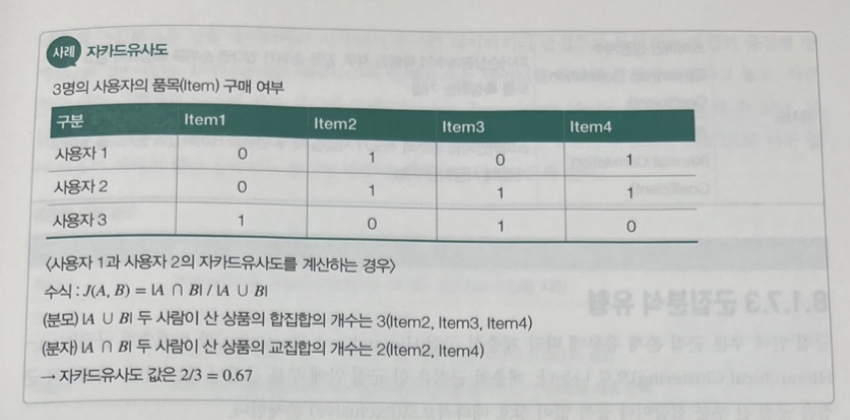
img) 자카드유사도 사례
군집분석 분류로 비유사도와 유사도 기반 외에도 레벤슈타인이나 해밍거리를 포함하는 다차원 변수와 유사도 계수 기반으로 분류하기도 한다.
img) 군집분석 다차원 변수의 유사도 및 유사도계수 기반 분류


