[DCAI] 6. Data Curation for LLMs

Large Language Models (LLMs, 대규모 언어 모델)
대규모 언어 모델(Large Language Models, LLMs)은 자연어 처리(NLP) 분야에 혁명을 일으켰다. 대표적인 예로 ChatGPT, GPT-4, LLaMA 등이 있다. 이러한 모델은 시퀀스-투-시퀀스(seq2seq) 아키텍처를 기반으로 하며, 이전의 단어 또는 토큰을 기반으로 다음 단어나 토큰을 예측하도록 훈련된다.
LLM의 주요 목표는 다음과 같은 확률 분포를 모델링하는 것이다:
여기서 는 예측할 토큰이며, 이전 토큰 는 컨텍스트(context)로 사용된다.
LLM의 주요 특성
- 대규모 모델 용량(Large Model Capacity): LLM은 수십억 개의 파라미터를 가지고 있어 복잡한 언어 작업을 높은 정확도로 처리할 수 있다.
- 비지도 사전 학습(Unsupervised Pre-training): 거대한 인터넷 규모의 코퍼스(corpora)에서 라벨이 필요 없는 비지도 방식으로 사전 학습(pre-trained)되며, 이를 통해 언어의 구조를 학습한다.
- 범용성(General-Purpose Utility): LLM은 파인튜닝(fine-tuned)이나 프롬프트를 통해 텍스트 생성부터 질의 응답까지 다양한 작업을 수행할 수 있다.
LLM의 응용 분야(Applications of LLMs)
LLM은 작업별 데이터(task-specific data)의 유무에 따라 다양한 상호작용 방식으로 활용될 수 있다.
Zero-Shot Prompting
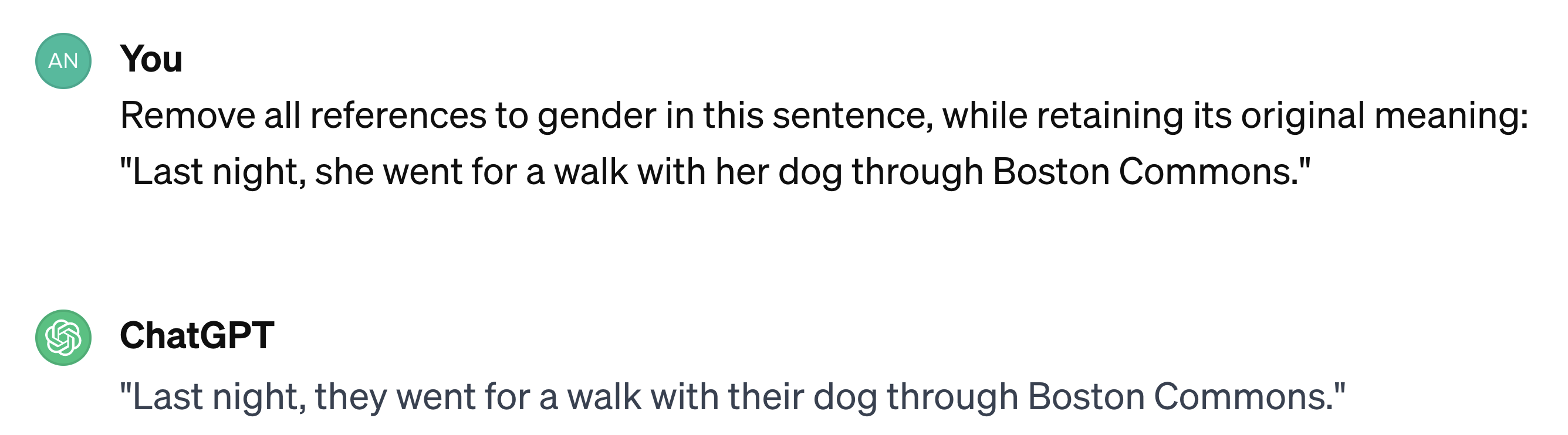
Zero-shot prompting에서는 특정 작업에 대해 별도의 훈련 없이 프롬프트를 활용하여 문제를 해결한다. 모델에게 작업 설명을 제공하고, 사전 학습된 지식을 기반으로 이를 수행하도록 요청한다.
Few-Shot Prompting

Few-shot prompting은 작업과 관련된 소수의 예제를 프롬프트에 포함시킨다. 이는 모델이 몇 가지 라벨이 지정된 예제를 통해 특정 작업을 더 잘 이해하도록 도와주며, 제로샷 프롬핑보다 효과적이다.
LLM 프롬프팅 및 훈련 기법의 비교
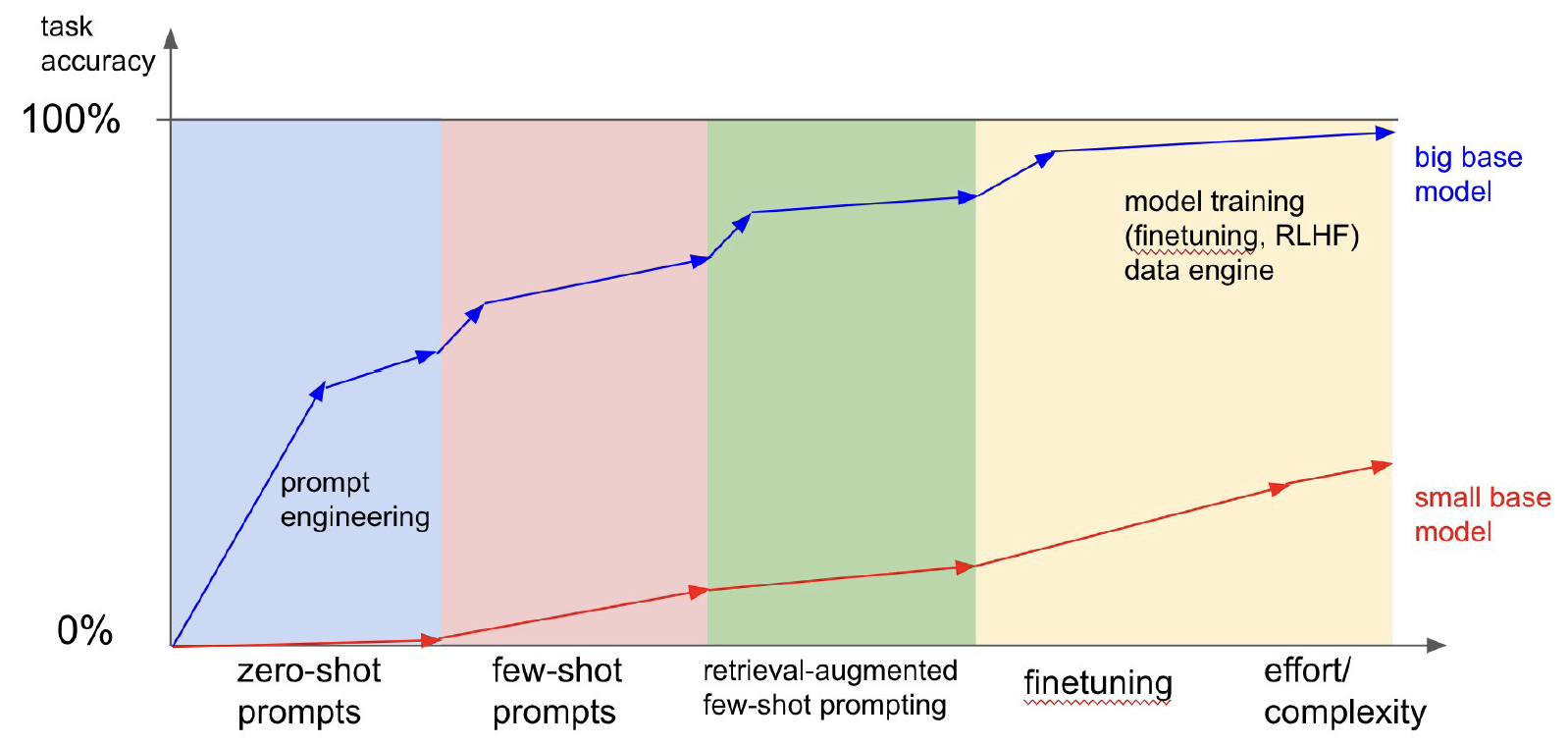
다양한 프롬프팅 및 훈련 기법이 LLM의 활용을 최적화하며, 각기 다른 장점을 제공한다 (Karpathy, 2023):
- Zero-Shot Prompting: 작업별 예제 없이 프롬프트만으로 모델이 응답하도록 한다. 편리하지만 항상 최상의 결과를 제공하는 것은 아니다.
- Few-Shot Prompting: 몇 가지 예제를 제공하여 모델이 작업을 더 정확히 이해하고 관련된 출력을 생성하도록 돕는다.
- Fine-Tuning: 특정 작업(specific task)에 대한 대량의 입력-출력 쌍(input-output pairs)으로 모델을 훈련하여 전문화된 작업에 최적화된 모델을 만든다.
- RAG (Retrieval-Augmented Generation, 검색 증강 생성): 외부 소스로부터 관련 정보를 검색하여 모델의 응답을 향상시켜, 파라미터에 저장된 것 이상의 능력을 확장한다.
이러한 방법들은 모델 커스터마이즈를 위한 다양한 지점을 대표하며, 사용의 편의성과 작업별 정확성 사이의 균형을 이룬다.
LLM for Data Curation
대규모 언어 모델(Large Language Models, LLMs)은 데이터 큐레이션(data curation)을 위한 강력한 도구로, 전통적으로 상당한 수작업이 필요했던 데이터 관리의 여러 측면을 자동화한다.
데이터 큐레이션을 위한 LLM의 주요 장점 (Key Advantages of LLMs for Data Curation)
- 자연어 이해(natural language understanding): LLM은 텍스트 데이터를 처리하고 추론하여 핵심 정보를 효율적으로 추출할 수 있다.
- 커스터마이즈(customization): 프롬프트나 파인튜닝을 통해 최소한의 계산 비용으로 특정 사용 사례에 맞게 조정할 수 있다.
- 확장성(scalability): 대규모로 운영될 수 있어 방대한 데이터셋을 처리하는 데 이상적이다.
- 혁신적인 영향(revolutionary impact): 텍스트 데이터 큐레이션을 체계화하는 능력은 의료부터 금융까지 다양한 산업을 혁신시켰다.
Applications of LLMs in Data Curation
PII(Personally Identifiable Information, 개인 식별 정보) 탐지
데이터 큐레이션에서는 이름, 주소, 신용카드 번호와 같은 개인 식별 정보(PII)가 데이터셋에 포함되지 않도록 보장해야 한다.
전통적인 접근법: 정규식 기반 탐지
이전에는 정규 표현식(regex)을 사용하여 PII를 탐지했다. 이름, 주소, 신용카드 번호와 같은 패턴을 수동으로 열거해야 했으며, scrubadub과 같은 도구가 이를 구현했지만 지속적인 업데이트와 유지보수가 필요했다.
현대적인 접근법: Zero-Shot Prompting을 통한 PII 탐지
LLM을 사용하면 작업별 파인튜닝(task-specific fine-tuning) 없이도 zero-shot prompting을 통해 PII를 탐지할 수 있다. 예를 들어 다음과 같은 프롬프트를 사용할 수 있다:
Prompt for PII Detection(PII 탐지를 위한 프롬프트):
“Consider the following text: "$text"
Please identify whether the above text contains any personally identifiable information. This includes, but is not limited to, PII such as a name, location, or credit card number. Be sure to catch PII not listed here. Explain your reasoning, and end your answer with a final judgement like ‘Output: true’ if the example contains PII, or ‘Output: false’ if the example does not contain PII.”
“다음 텍스트를 고려하십시오: "$text"
위의 텍스트에 개인 식별 정보가 포함되어 있는지 확인하십시오. 여기에는 이름, 위치, 신용카드 번호 등이 포함되지만 이에 국한되지 않습니다. 여기에 나열되지 않은 PII도 잡아내십시오. 추론 과정을 설명하고, 마지막에 ‘Output: true’ 또는 ‘Output: false’로 최종 판단을 제시하십시오.”
이 방법은 프롬프트를 기반으로 LLM의 일반적인 언어 이해 능력(general language understanding capabilities)을 활용하여 민감한 정보를 탐지한다.
맞춤법 검사(Grammar Check)
텍스트 데이터의 문법적 정확성을 보장하는 것은 고품질 데이터셋을 생성하고 잘 구조화된 입력에 의존하는 모델을 훈련하는 데 중요하다.
전통적인 접근법: 수작업으로 설계된 규칙 목록
이전에는 수동으로 큐레이션된 규칙 목록을 사용하여 맞춤법 검사를 수행했다. LanguageTool과 같이 OpenOffice에 통합된 도구들은 미리 정의된 문법 규칙을 활용하여 오류를 잡아냈다.
현대적인 접근법: 파인튜닝(fine-tuning)을 통한 맞춤법 검사
현대적인 접근법은 LLM을 파인튜닝하여 맞춤법 검사를 더 효과적으로 수행한다:
- 데이터셋 생성(dataset creation): 각 문장이 문법적으로 올바른지 여부를 나타내는 부울 판단(boolean judgments)이 포함된 문장 데이터셋을 수집한다.
- 파인튜닝(fine-tuning): : 이 데이터셋으로 LLM을 훈련하여 문법 오류를 더 정확하게 식별할 수 있도록 한다.
이 접근법의 예로는 Warstadt et al. (2018)의 Corpus of Linguistic Acceptability (CoLA)이 있다.
LLM 출력 데이터의 평가
LLM이 생성한 출력의 정확성과 품질을 평가하는 것은 매우 중요하다. 특히 LLM은 환각(hallucinations) 현상을 보일 수 있는데, 이는 사실과 다른 정보나 말이 안 되는 내용을 높은 확신도로 생성하는 것이다.
LLM 출력에서의 일반적인 문제
-
환각(hallucinations): 모델이 국가의 인구와 같은 잘못된 사실이나 세부 정보를 생성할 수 있다.
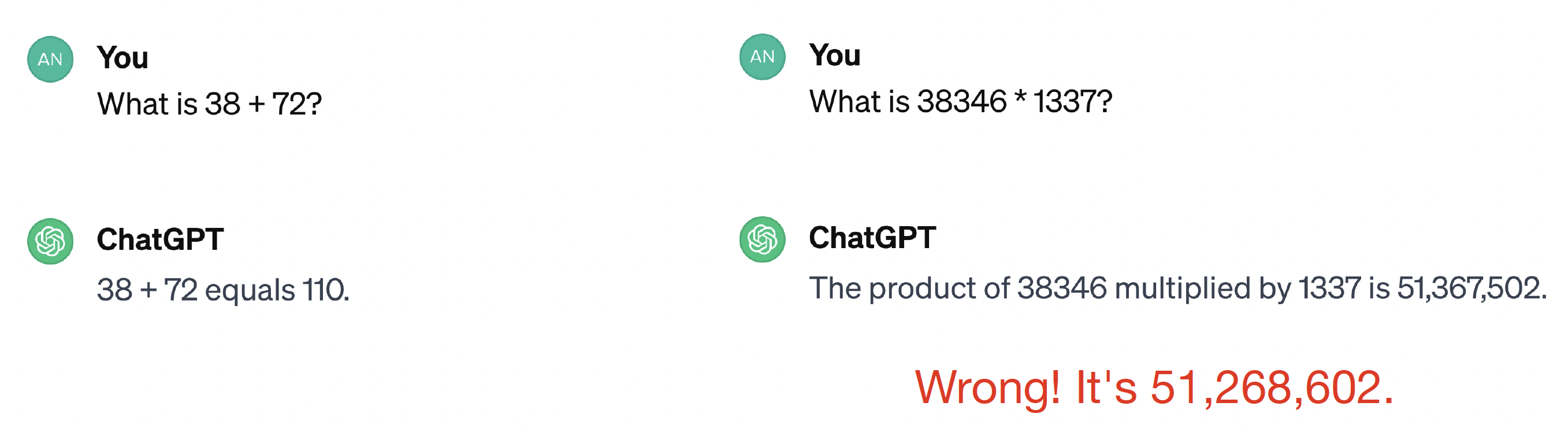
실제로 이 숫자는 정확하지 않지만, 모델은 이를 확신하며 생성한다.
다른 강력한 LLM을 활용한 평가
보다 발전된 LLM을 사용하여 덜 발전된 모델의 출력을 평가하거나 수정하는 접근법이 일반적이다:
- GPT-3.5를 사용하여 GPT-3와 같은 모델의 출력을 평가할 수 있다.
- GPT-4를 활용하여 GPT-3.5의 출력을 평가함으로써 향상된 정확성과 추론 능력을 제공한다.
예시: AlpaGasus의 파인튜닝(fine-tuning)
AlpaGasus는 큐레이션된 데이터셋으로 파인튜닝된 모델로, Alpaca 모델보다 상당히 우수하다. Chen et al. (2023)에 따르면, Alpaca는 52k의 합성 데이터 포인트(synthetic data points)로 훈련되었지만, AlpaGasus는 GPT-3.5로 생성된 9k의 고품질 데이터 포인트(high-quality data points)로 파인튜닝되어 더 나은 성능을 달성했다.
결과는 GPT-4와 인간 평가자 모두에 의해 평가되었으며, 큐레이션된 고품질 데이터로 파인튜닝한 효과를 보여준다.
다른 LLM으로 LLM을 평가할 때의 도전과제(Challenges in Evaluating LLMs with Other LLMs)
더 강력한 모델을 사용한 평가가 효과적일 수 있지만, 몇 가지 도전과제가 있다:
- 순환 의존성(circular dependencies): 평가 모델이 출력 생성 모델과 유사하다면, 새로운 통찰력을 얻지 못하고 동일한 편향이나 오류를 강화할 수 있다.
- “무한 반복” 문제(“Turtles All the Way Down” Problem): 기본 모델이 결함 있는 출력을 생성하면, 더 발전된 LLM이라도 유사한 훈련 데이터나 추론 과정을 공유한다면 모든 오류를 감지하지 못할 수 있다.
LLM의 불확실성 정량화(LLM Uncertainty Quantification)
LLM 출력 평가의 한계를 해결하기 위해, 연구자들은 예측에 대한 모델의 신뢰도(confidence)를 측정하는 불확실성 정량화 방법을 탐구하고 있다.
접근법: 자연어 추론(Natural Language Inference, NLI) 활용
한 가지 방법은 NLI 모델을 사용하여 답변을 비교하고 모순을 감지하는 것이다. NLI 모델은 두 개의 생성된 답변이 모순되는지 평가하여 추가적인 검증 계층(layer of validation)을 제공한다.
예시: 질의 응답에서의 불확실성 정량화
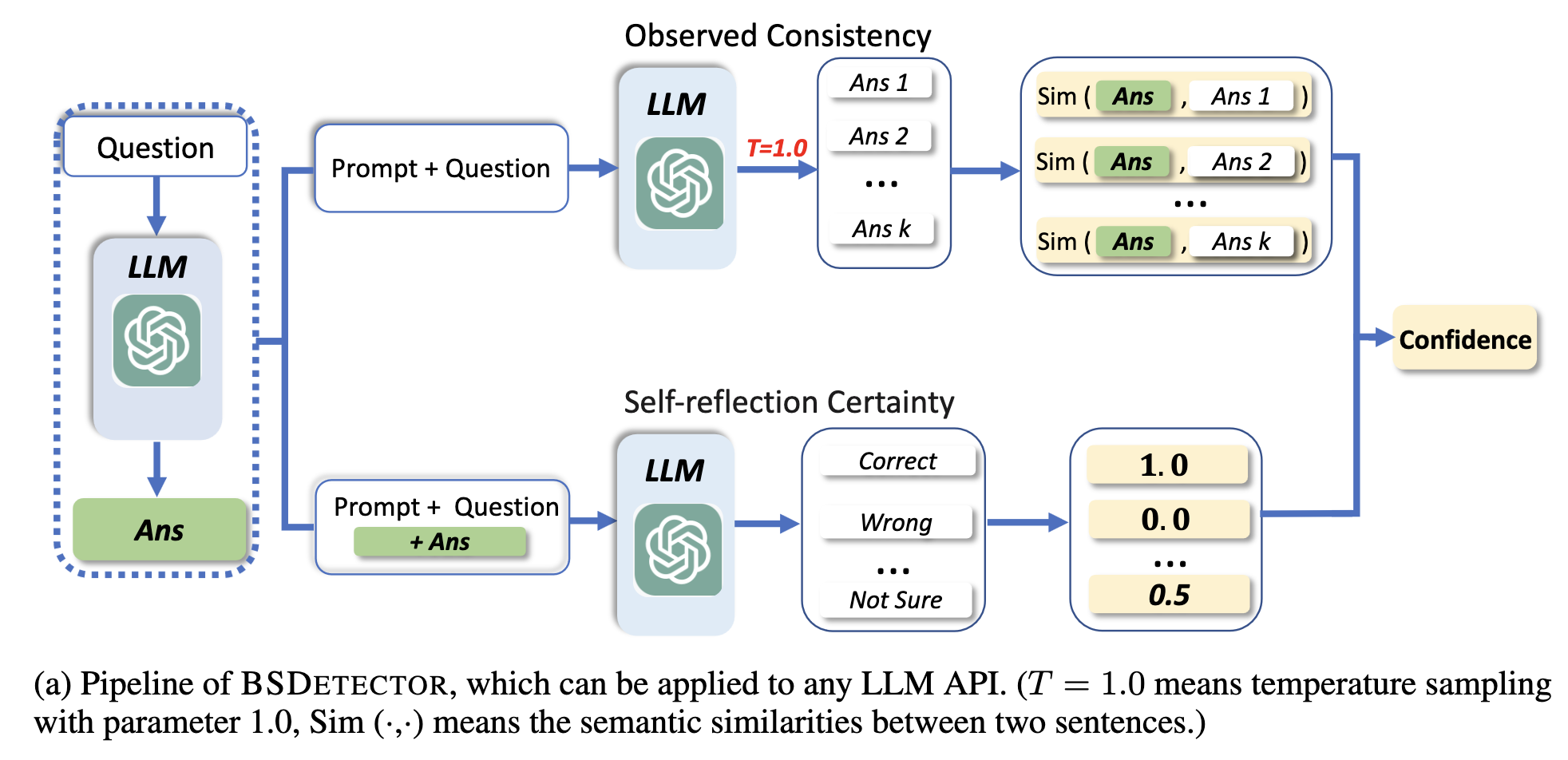
불확실성 정량화는 모델이 제공하는 답변이 신뢰할 수 있는지 판단하는 데 도움이 된다. Chen & Mueller (2023)에 따르면, 이 접근법은 법률이나 의료 분야와 같이 정확하고 정확한 답변이 필수적인 작업에서 중요하다.
신뢰할 수 있는 언어 모델(Trustworthy Language Model, TLM)
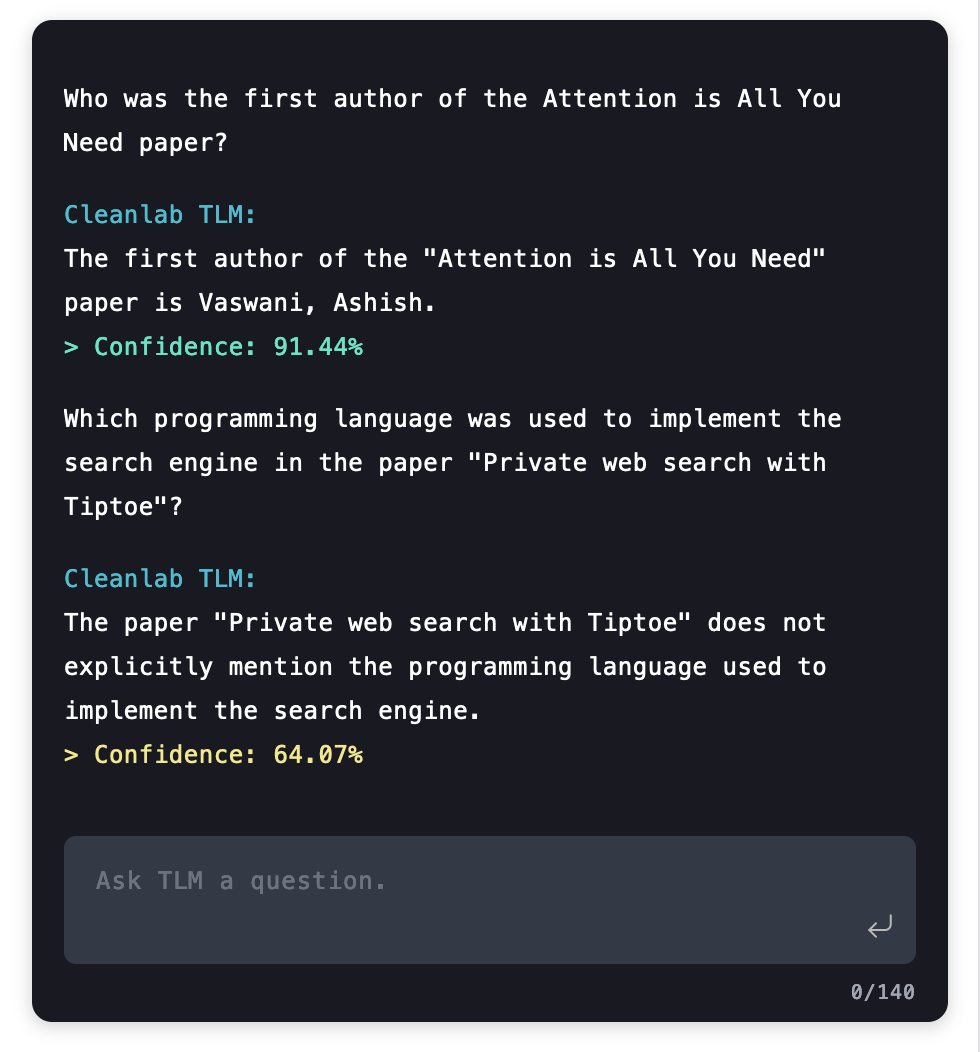
신뢰할 수 있는 언어 모델(Trustworthy Language Model, TLM)은 LLM을 위한 불확실성 정량화에 중점을 둔 구현이다. TLM은 생성된 답변이 모델의 확실성(certainty)이나 불확실성(uncertainty)과 함께 제공되도록 하여 사용자가 모델의 신뢰도(confidence levels)를 기반으로 정보에 입각한 결정을 내릴 수 있도록 한다.
Training Data Curation for LLMs
효과적인 데이터 큐레이션(data curation)은 LLM의 성능 향상에 필수적이다. 훈련에 사용되는 데이터의 품질과 구조는 이들이 다양한 작업에서 일반화하고 수행하는 능력에 직접적인 영향을 미친다.
사전 학습 LLM 기본 모델을 위한 데이터 큐레이션 (Data Curation for Pre-Training LLM Base Models)
비지도 사전 학습 (Unsupervised Pre-Training)
LLM은 일반적으로 비지도 사전 학습(unsupervised pre-training)으로 시작하며, 거대한 라벨 없는 데이터셋에 노출되어 일반적인 언어 패턴을 학습한다. 이 단계에서 모델은 시퀀스(sequences)의 다음 토큰(token)을 예측하여 언어 구조를 익힌다.
도전과제(challenges)
- 코퍼스 품질(corpus quality): 허위 정보(misinformation), 편향(biases) 또는 유해한 콘텐츠(harmful content)가 없는 인터넷 규모의 데이터를 큐레이션하는 것은 어렵다. 모델이 바람직하지 않은 패턴을 내재화하지 않도록 고품질 데이터가 필요하다.
- 비학습의 어려움(unlearning difficulty): LLM이 사전 훈련(pre-training)에서 무언가를 학습하면, 이러한 패턴을 “비학습(unlearn)”하기 어렵기 때문에 처음부터 깨끗하고 대표적인 데이터셋을 사용하는 것이 중요하다.
지도 학습 파인튜닝 (Supervised Fine-Tuning)
비지도 사전 학습은 LLM의 기본적인 언어 이해를 제공하는 반면, 지도 학습 파인튜닝(supervised fine-tuning)은 라벨이 지정된 데이터셋을 사용하여 특정 작업에서 모델의 성능을 개선한다.
RLHF(Reinforcement Learning from Human Feedback, 인간 피드백을 통한 강화 학습)
RLHF는 인간 평가자가 출력을 순위별로 제공하여 모델이 인간의 선호도에 맞도록 훈련하도록 도와주며, 안전성과 해석 가능성을 향상시킨다.
LLM 응용을 위한 데이터 큐레이션 (Data Curation for LLM Applications)
Zero-Shot (프롬프트 엔지니어링)
Zero-shot learning에서는 특정 작업(specific task)에 대해 모델을 파인튜닝(fine-tuned)하지 않고 사용한다. 대신, 프롬프트를 신중하게 설계하여 모델이 유용한 출력을 생성하도록 안내한다. 이 방법은 추가적인 학습 없이도 다양한 작업을 수행할 수 있는 유연성을 제공한다.
Few-Shot (프롬프트 엔지니어링 + 몇 가지 예제)
Few-shot learning은 프롬프트에 소수의 예제를 포함시켜 모델이 작업을 더 잘 이해하도록 돕는 방법이다. 고품질의 예제를 선택하여 작업을 잘 대표하도록 큐레이팅함으로써, 모델의 정확성과 일관성을 향상시킬 수 있다 (Chang & Jia, 2023).
검색 증강 생성 (Retrieval-Augmented Generation, RAG)
RAG는 모델이 생성 과정에서 접근할 수 있는 외부 지식 베이스를 큐레이팅하는 기법이다. 데이터 큐레이션을 통해 지식 베이스가 포괄적이고 최신이며 정확하도록 보장함으로써, 모델의 응답 품질을 향상시킨다. 이는 특히 최신 정보나 전문적인 지식이 필요한 작업에서 유용하다.
지도 학습 파인튜닝 (Supervised Fine-Tuning)*
지도 학습 파인튜닝은 LLM을 특정 작업에 최적화하는 가장 강력한 방법 중 하나이다. 파인튜닝은 LLM을 특정 사용 사례에 맞게 조정하여 작업을 더 효율적으로 처리할 수 있게 한다. 예를 들어, 법률 데이터셋으로 LLM을 파인튜닝하면 법률 텍스트 분석 성능이 향상된다. 이 과정에서는 원본 데이터와 합성 데이터를 모두 큐레이팅하여 모델을 훈련시킨다. 다음과 같은 단계로 진행된다:
- 원본 데이터셋 정리: 데이터셋에서 오류, 편향, 관련 없는 데이터를 제거하여 고품질의 입력을 보장한다.
- 합성 데이터 생성: GPT-4와 같은 강력한 LLM을 사용하여 원본 데이터셋을 모방한 합성 데이터를 생성한다.
- 불량 합성 데이터 필터링: 합성 데이터 중 현실적이지 않은 예제를 식별하기 위해 분류기를 훈련시켜 품질이 낮은 데이터를 걸러낸다.
- 모델 파인튜닝: 정리된 원본 데이터셋과 큐레이팅된 합성 데이터를 결합하여 LLM을 파인튜닝한다.
- 목표(Goal): 특정 작업에 대해 더 작고 저렴한 LLM을 더 큰 LLM의 성능에 맞게 학습
- 더 자세한 내용은 Textbooks Are All You Need (Li et al. 2023) 참고
이와 같이 지도 학습 파인튜닝(supervised fine-tuning)은 특정 도메인이나 작업에 맞는 데이터 큐레이션을 통해 모델의 성능을 극대화하는 데 중요한 역할을 한다.
파운데이션 모델과 함께하는 데이터 큐레이션의 미래(The Future of Data Curation with Foundation Models)
파운데이션 모델은 텍스트, 이미지, 오디오, 비디오를 포함한 다양한 멀티모달 데이터셋으로 훈련된 LLM의 진화된 형태를 대표한다.
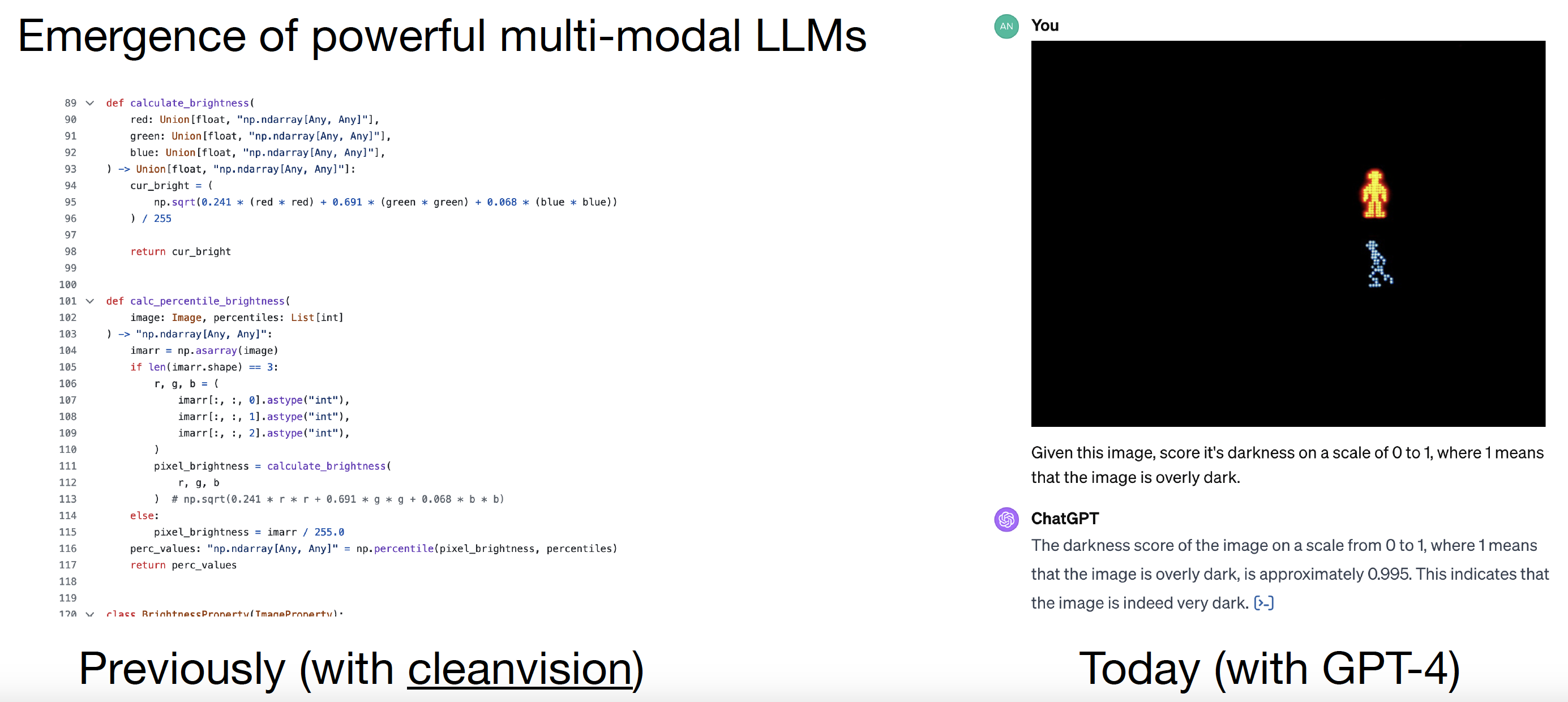
이전의 접근법: CleanVision
이전에는 CleanVision과 같은 도구를 사용하여 텍스트 데이터셋을 정리하고, 노이즈가 있거나 품질이 낮은 데이터를 식별하여 제거했다. 이는 텍스트와 같은 전통적인 모달리티(modalities)에 중점을 두었다.
오늘날의 접근법: GPT-4
GPT-4와 같은 모델의 출현은 특히 멀티모달 작업에서 데이터 큐레이션을 크게 개선했다:
- 멀티모달 데이터 큐레이션(Multi-Modal Data Curation): GPT-4는 이미지, 텍스트, 오디오를 처리할 수 있어 복잡한 멀티모달 데이터셋을 효과적으로 큐레이션할 수 있다.
- 합성 데이터 생성(Synthetic Data Generation): GPT-4는 고품질의 합성 데이터를 생성하여 파인튜닝을 위한 균형 잡힌 포괄적인 데이터셋을 만든다.
- 고급 불확실성 정량화(Advanced Uncertainty Quantification): GPT-4 및 그 파생 모델은 불확실성 정량화를 위한 고급 기술을 구현하여 합성 데이터가 더 높은 신뢰도로 큐레이션되도록 보장한다.
파운데이션 모델과 멀티모달 LLMs의 미래(The Road Ahead: Foundation Models and Multi-Modal LLMs)
데이터 큐레이션의 미래는 여러 데이터 유형을 처리할 수 있는 파운데이션 모델을 지원하는 데 있다:
- 다양하고 높은 품질의 데이터 큐레이션: 모든 모달리티에 걸쳐 데이터가 균형 잡히고 편향되지 않으며 현실 세계의 분포를 대표하도록 보장한다.
- 큐레이션 도구 개선: 멀티모달 데이터를 처리하기 위한 새로운 도구와 프레임워크를 개발하고, 고품질의 합성 데이터 생성을 위해 고급 LLM을 활용한다.
- 모델 편향 감소: 효과적인 큐레이션은 파운데이션 모델의 편향을 완화하는 데 중요한 역할을 하며, 공정하고 윤리적인 출력을 보장한다.
References
- Lecture (ver.2024): https://dcai.csail.mit.edu/2024
- Lecture (ver.2023): https://dcai.csail.mit.edu/2023
- Lab Session (ver.2023): https://github.com/dcai-course
- P.S. 본 포스팅 작성에는 OpenAI의 GPT-4o와 o1-preview가 활용되었습니다
