
누락 데이터 확인
데이터를 불러오다 보면 결측치가 늘 생기기 마련이다.
None 값은 '없는' 의미가 아니라 '알 수 없는' 의 의미다. 그래서 알 수 없는 값에 산술 연산을 하게 되면 모든 반환 값은 None으로 반환된다. 왜냐하면 모르는 값에 무엇을 더하고 빼든 알 수 없기 때문이다.
그래서 판다스에서는 결측치 값을 배제하고 기술 통계를 처리한다.
데이터의 정보를 확인해 보는 습관을 들이자. 정보에 비어있는 값이 있는지 확인할 수 있다.
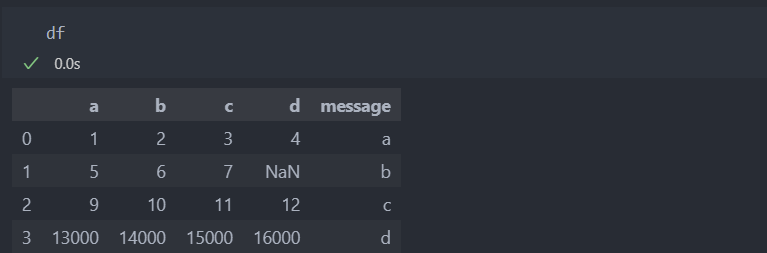
1. 결측치 확인하기: isnull():, notnull() -> 논리 연산으로 반환된다.
isnull(): 결측치가 있으면 True를 반환한다.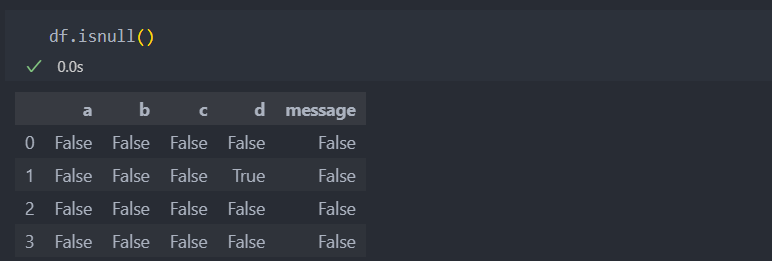
notnull(): 결측치가 없으면 True를 반환한다.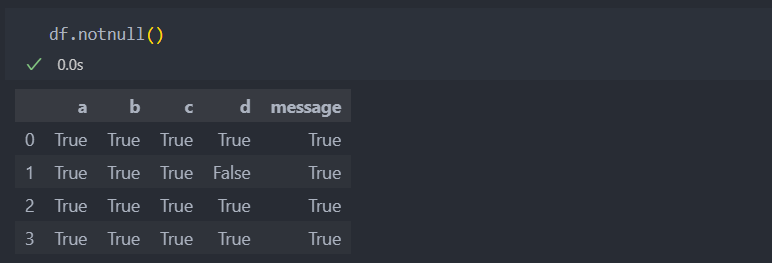
2. 결측치 없애기: dropna()
인자값 'axis'은 없애는 것이 행인지 열인지 설정한다.
데이터를 다루다보면 pandas, numpy의 axis값이 다른데, 판다스는 0의 방향은 인덱스 방향이고 넘파이는 컬럼 방향이다.
기본값(default)은 'axis=0'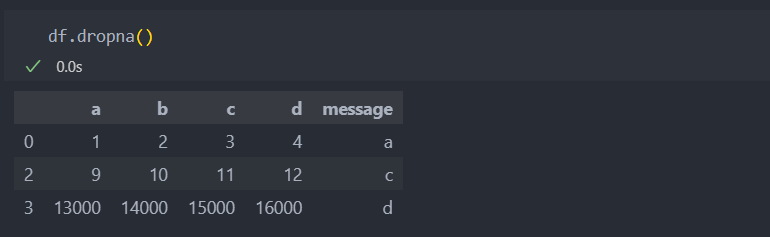
'axis=1'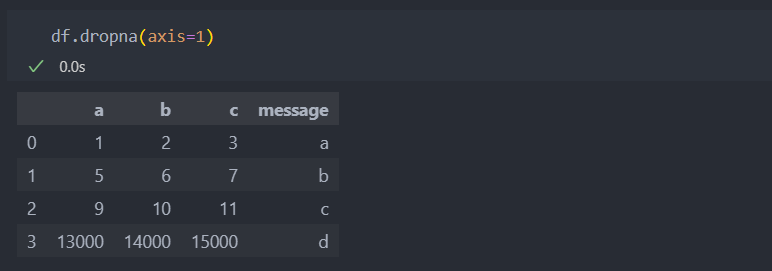
기본적으로 dorpna()는 결측치가 있는 로우나 컬럼을 모두 없애는 것이 기본값(default)이다.
default: dorpna(how='any')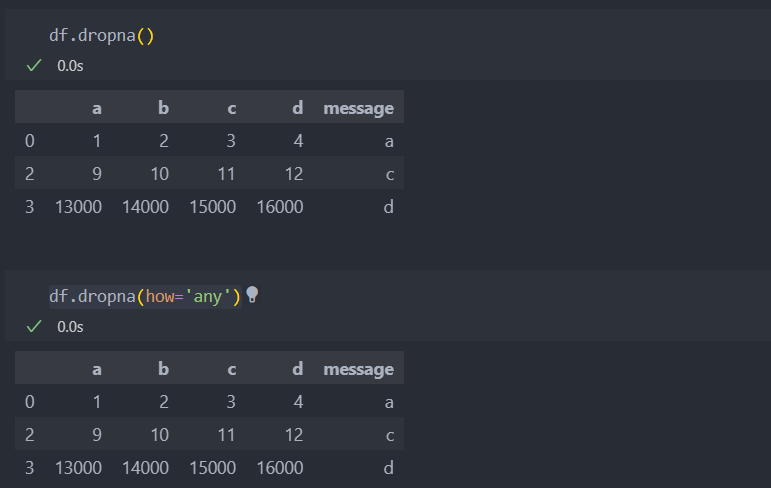
하지만 로우나 컬럼의 값이 모두 결측치일 때만 배제하도록 할 수도 있다.
dropna(how='all') 아래와 같이 하나의 값만 결측이 되었기 때문에 결측치 값이 있는 로우를 그대로 가져온다.
로우나 컬럼 모두가 결측치 값일 때에는 how='all'을 써서 없앨 수 있다. 이 때 로우, 혹은 컬럼의 방향을 보고 설정해야 한다.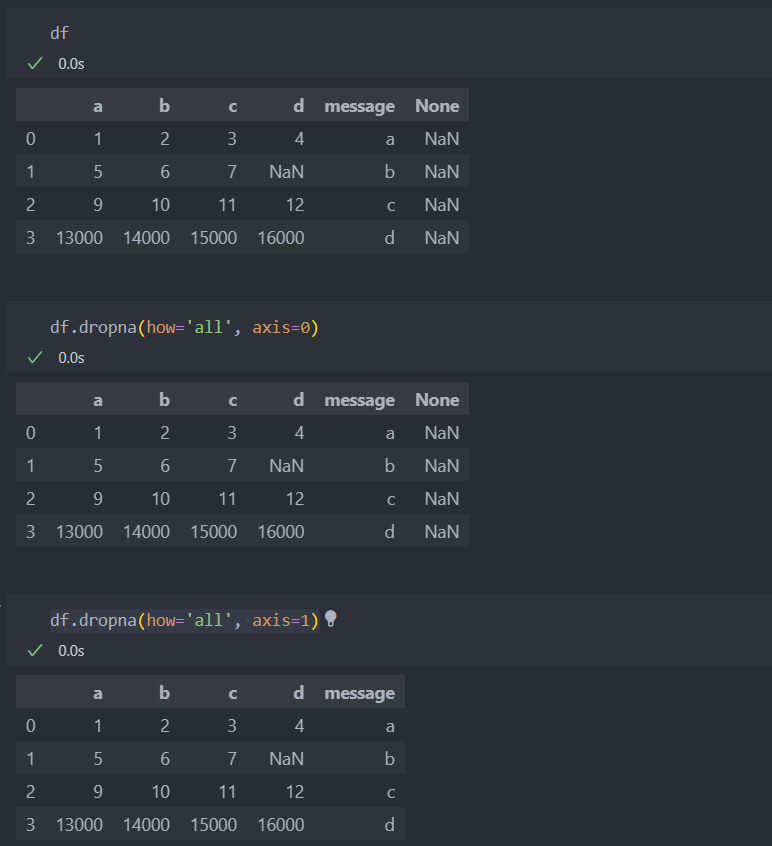
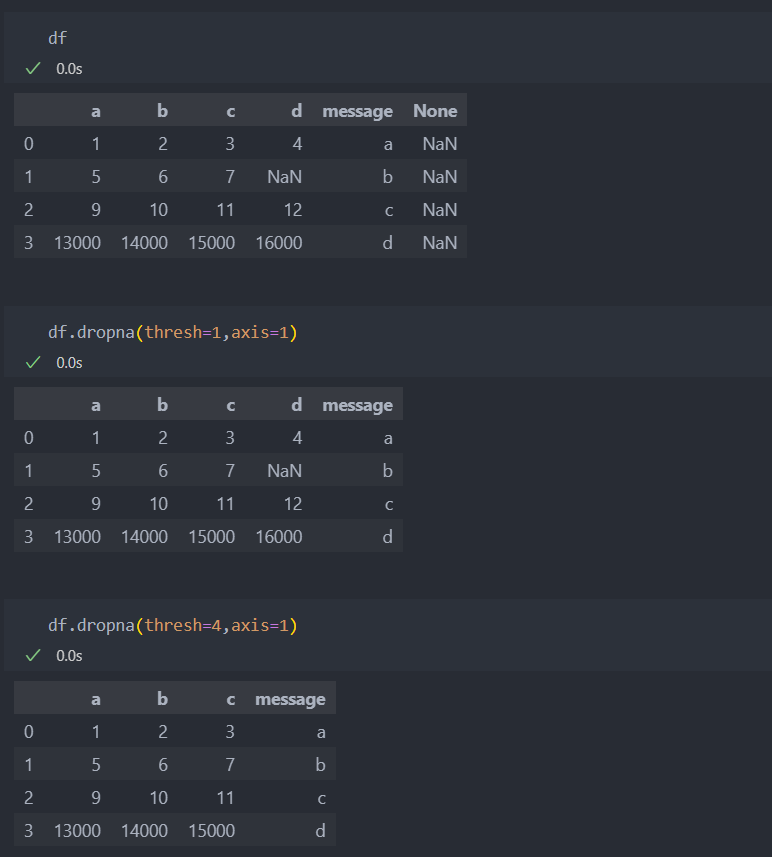
값을 기준으로, 몇 개 이상의 값이 들어간 것만 보고자 할 대는 'thresh=개수'를 넘기면 된다.
df의 값의 로우를 기준으로 봤을 때, 1행은 값이 4개 나머지는 값이 5개가 들어가 있다. 그래서 thresh=5 를 넘기게 된다면 값이 5개 이상 있는 로우의 값만 보고겠다는 의미다. axis를 조절하여 컬럼으로 설정할 수도 있다. 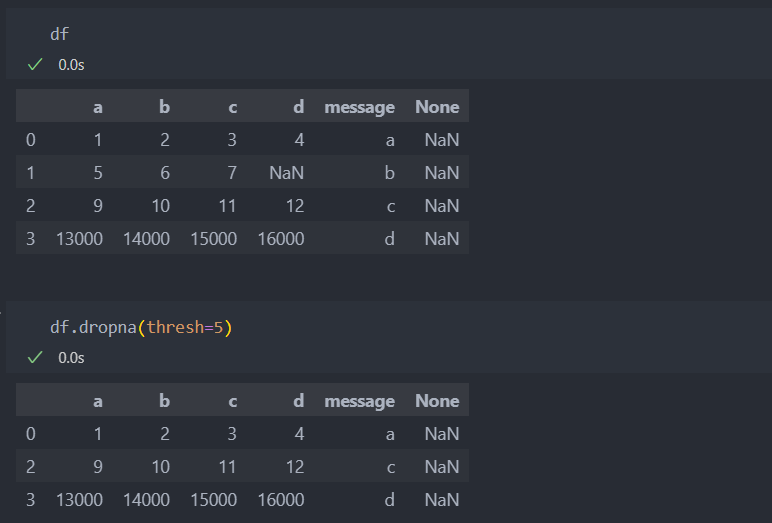
axis=1
3. 결측치 채우기: fillna()
fillna(채워넣을 값) 을 넘기면 결측치에 '채워넣을 값'이 삽입된다.
삽입할 때 판다스는 행과 열을 보고 알맞는 값을 데이터 형을 채워넣는데, 기본값은 float(실수)이다.
아래와 같이 컬럼의 값이 모두 인트로 되어있는 1행d열은 'int'(정수)로 None컬럼은 'float'로 채워진다.

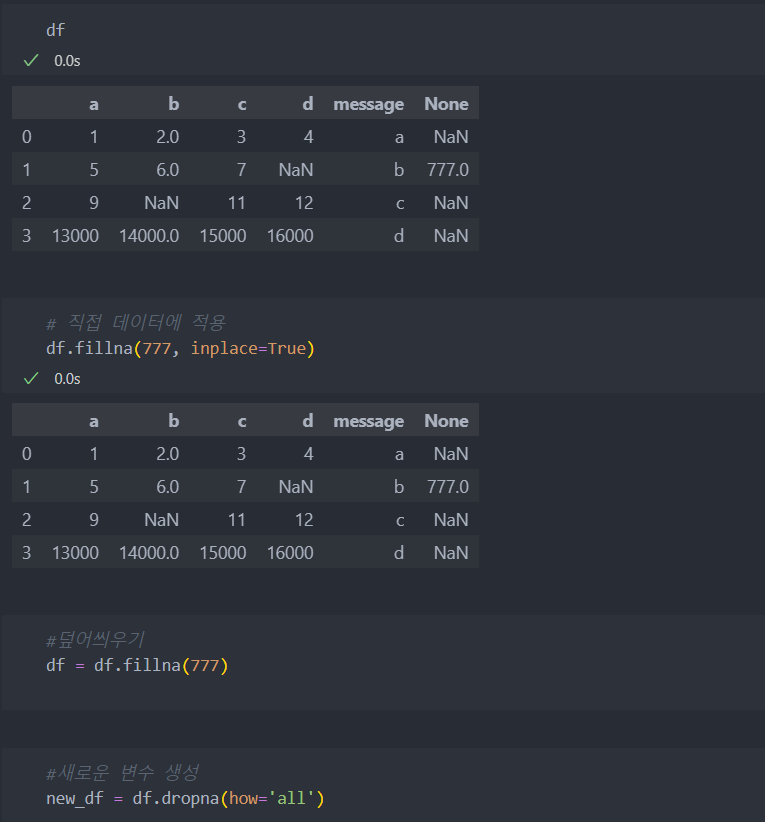
값을 채울 때 어떤 값으로 채워야 할 지 따로 정할 수도 있다.
'method='를 써서
'method='ffill''은 결측치의 앞의 값을 채워넣겠다는 의미다.
여기에서 주의해야 할 점은 method='ffill은 numpy의 산술연산을 채용하기 때문에 axis의 default 방향은 컬럼이다. 그래서 NaN값에 컬럼 'd'의 위 값 4를 가져오며 컬럼 'None'가 그대로인 이유는 위의 값이 NaN이기 때문에 변화가 없다.
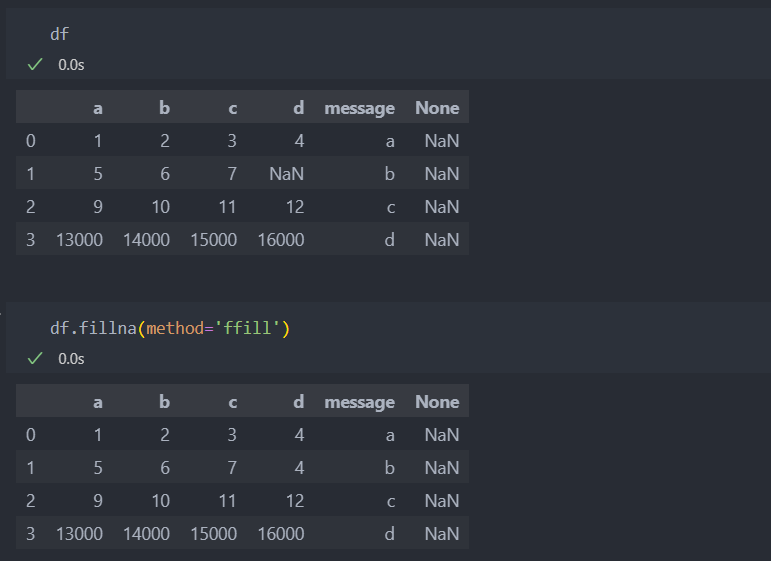
그래서 컬럼을 축으로 값을 가져오려면 'axis=1' 인자를 줘야한다.
'method='bfill''은 결측치의 뒤의 값을 채워넣겠다는 의미다.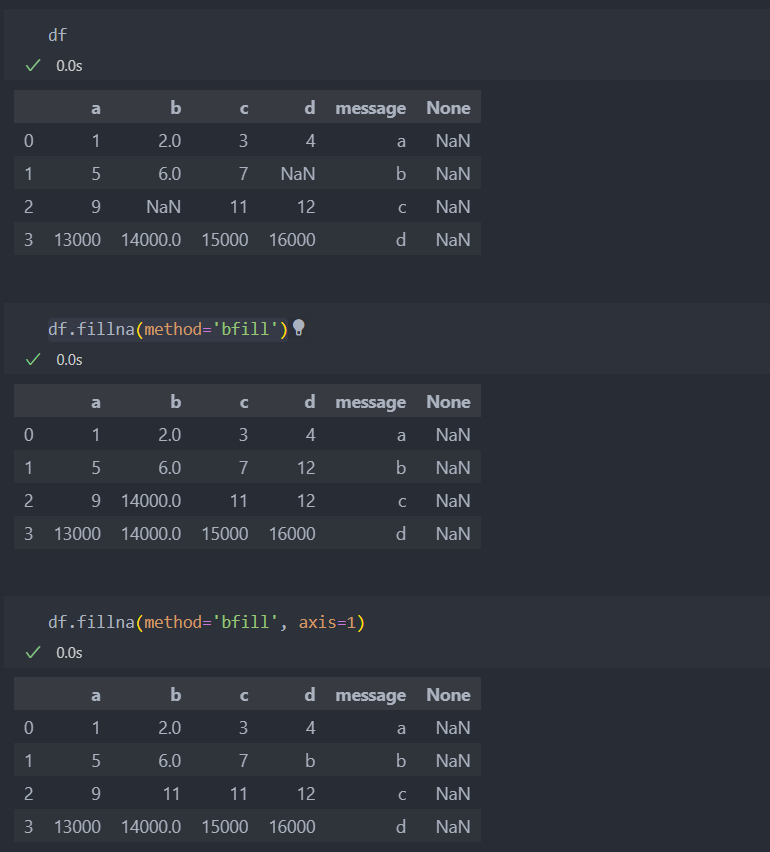
산술 연산도 지원한다.
위에서도 이야기 했지만 산술 연산을 할 때 NaN 값은 배제하고 연산한다.
NaN값을 배제한 각 컬럼의 합을 NaN에 삽입한다.

4. 기타
- 결측치가 삽입된 로우나 컬럼을 삭제할 때는 판다스의 기능을 사용하지만, 결측치를 채워넣는 것은 산술 연산이 필요하기 때문에 넘파이를 채용하기에 axis 방향에 유의해야 한다.
- 결측치를 위해 사용하는 dropna, fillna는 뷰만 재공하고 복사는 발생하지 않는다. 다시 말해 결측치가 포함되어 있는 원래의 데이터는 변하지 않는다는 말이다. 그래서 적용시키기 위해서 inplace=True를 통해 데이터 값을 적용시키거나, 변수를 선언하여 결측치를 변경한 데이터를 새로운 이름의 데이터를 생성하거나, 기존의 데이터 이름을 변수로 선언하여 새롭게 만들어야 한다.
- 다른 파라미터도 제공하니 판다스 홈페이지를 확인해 보자.
