
pandas 파일 파싱 함수들
1. 불러오기
자주쓰는 함수
read_csv : 데이터 구분자가 쉼표(',')로 된 데이터 파일
read_table : 데이터 구분자가 탭('\t')으로 된 데이터 파일
read_excel : 엑셀파일에서 표 형식의 데이터를 불러온다.
read_html : HTML 문저 내의 모든 테이블 데이터를 불러온다.
read_json : JSON 문자열에서 데이터를 불러온다.
read_pickle : 파이썬 피클 포맷으로 저장된 데이터를 읽어온다.
불러올 때의 몇 가지 옵션
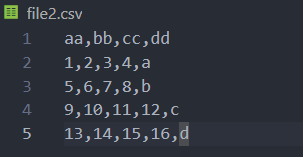
아래와 같이 csv 파일은 쉼표로 구분되어 있는 형식의 파일이다. 이것을 이제 DataFrame로 불러온다.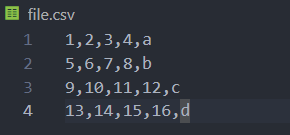
색인 :
일단 간단히 불러오기.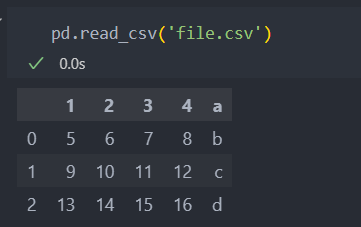
파일이 쉼표가 아닌 다른 기호가 구분자로 들어가 있다면 sep 속성으로 처리할 수 있다.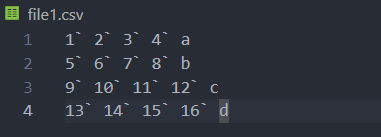
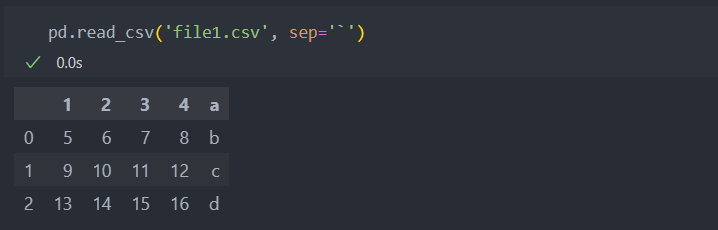
파일을 불러올 때 컬럼이름을 지정할 수 있다.
만약 첫 번째 로우의 컬럼이 하나가 적다면, pandas는 첫 번째 로우가 컬럼명, 로우의 첫번째 자리가 인덱스명으로 작동한다.
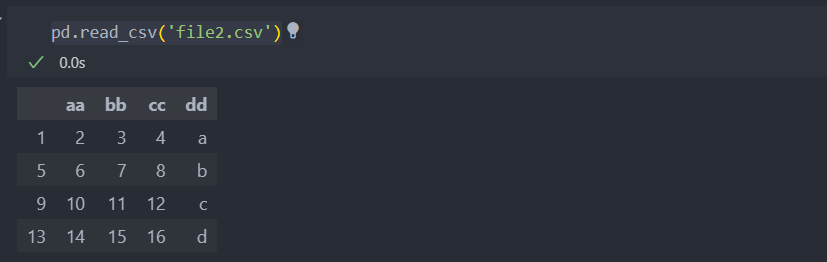
파일의 내용에 값만 들어가 있을 경우 컬럼을 정수 오름차순으로 불러올 수 있다.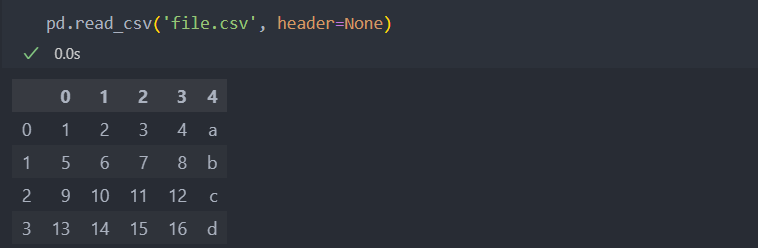
컬럼명을 로우(인덱스) 값으로 하고 싶다면 header에 해당 인덱스를 넘기면 된다.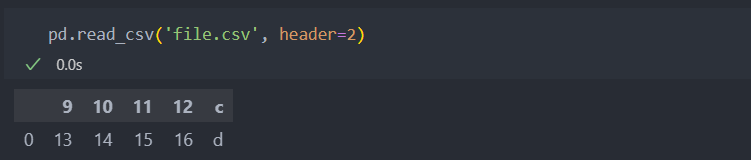
불러올 때 컬럼명을 직접 지정할 수 있다.(인자: names)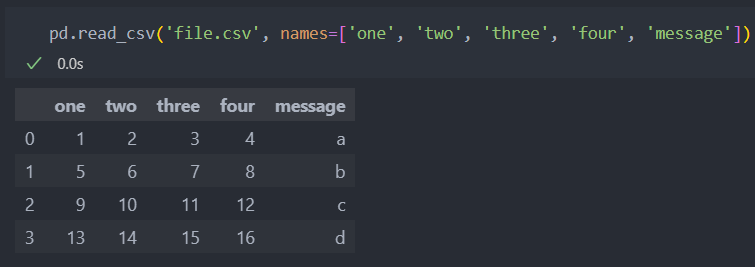
제외하고 싶은 로우를 설정할 수 있다.(skiprows)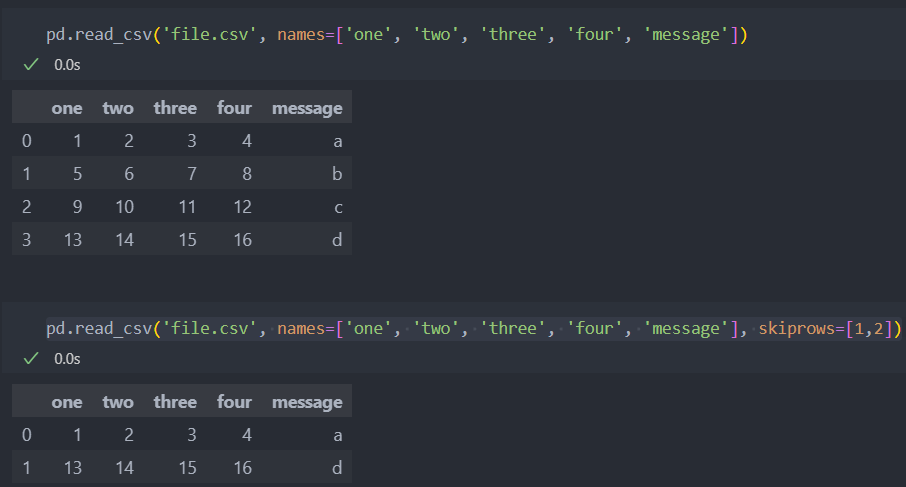
2. 저장하기
불러올 때 read를 썼다면 저장할 때는 to로.
to_csv('저장위치.파일형식')

데이터 굽는 타자기