
pivot_table()과 groupby()를 통해 데이터를 집계해보자.
1. pivot_table
피벗 테이블은 데이터에 조건을 줘서 변수들의 통게량을 요약하고 보기 위함이다.
입력 인자들은 다음과 같다.
data: 해당 데이터
index: 행에 들어갈 조건
columns: 열에 들어갈 조건
values: 집계 대상 컬럼 목록
aggfunc: 데이터들을 어떻게 집계할 것인지, 기초 통계 함수를 설정(sum, mean, std ...)
values와 index/columns가 헷갈리지 않게 넣도록 한다.
다음과 같은 데이터를 제품별/쇼핑몰 유형별로 판매금액의 평균값을 구해보자.
index에는 제품을 columns에는 쇼핑몰 유형, values에는 금액을 넣고 통계 함수는 평균을 사용하면 된다.
제품별로 쇼핑몰 유형에서 판매가 되지 않았다면 NaN값도 존재할 것이다.

이번엔 금액과 더불어 수량도 확인해 볼 것인데, 가장 많이 팔린 수량과 금액을 보도록 한다.
그리고 NaN값은 0으로 바꿔주자.
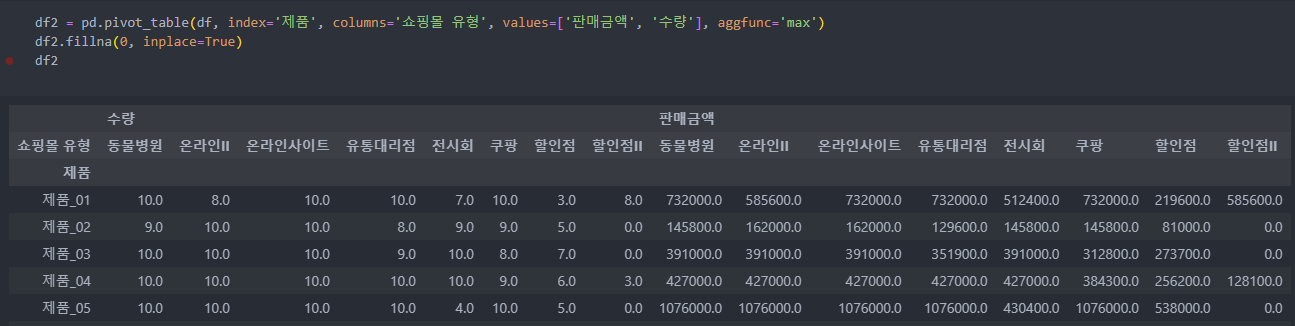
어떤 식으로 데이터를 요약하고 통계를 적용할 것인지 파악하여 도출하면 된다.
추가 : stack & pivot , pivot_table
2. groupby
groupby는 피벗과 비슷하게 조건부 통계량을 계산하기 위해서 사용한다.
분할, 적용, 결합의 단계로 이루어진다.
'groupby(분할할 컬럼)[적용할 컬럼].집계함수'로 이루어져 있다.
주요 인자들은 다음과 같다.
by(생략가능): 분할 기준 컬럼(분할만 해서는 데이터 집계가 되지 않고 적용시킬 컬럼도 지정해 주어야 한다.)
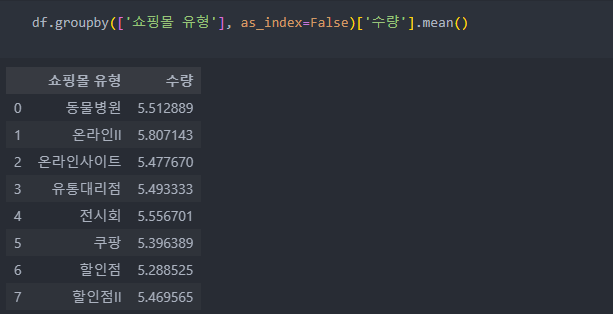
as_index: 분할 할 때 사용한 컬럼을 인덱스로 쓸 것인지(default: as_index=True/True:컬럼이 index 명이 된다.)
as_index=True는 Series 형식으로 반환이 된다.
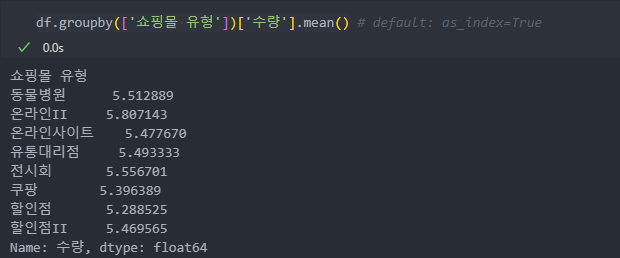
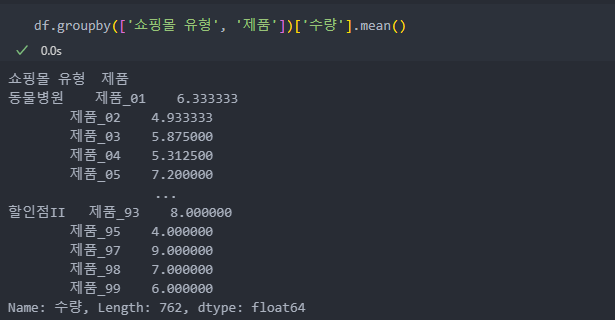
as_index=False로 사용하면 데이터 프레임 형식으로 반환한다.
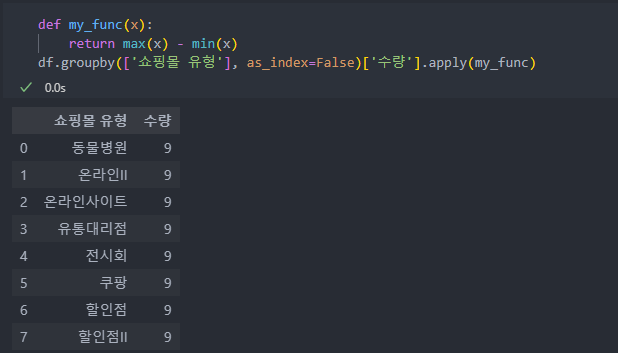
apply()함수를 사용하여 통계 함수를 직접 만들어 적용할 수 있다.
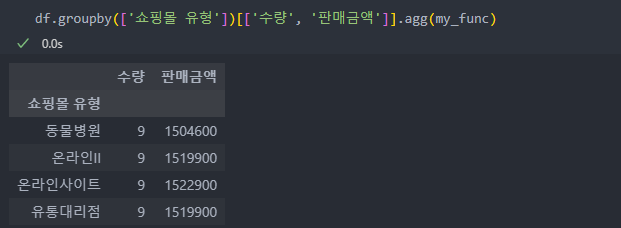
apply()함수는 하나의 '적용할 컬럼' 또는 '집계 함수'만 지원하기에 2개 이상의 '적용할 컬럼'과 '집계 함수'를 쓰려면 agg()함수를 사용.
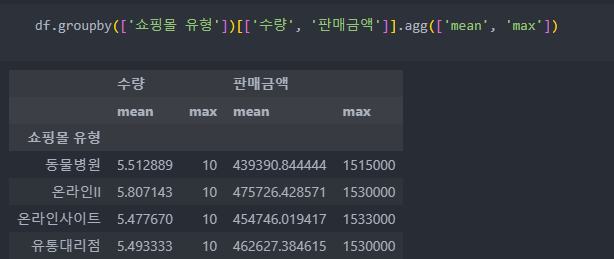
추가 : groupby 연산 & 집계
